




 本文详细介绍如何使用Anaconda或pip安装NLTK自然语言处理库,包括nltk_data下载及配置流程,通过示例代码展示如何利用NLTK进行词法分析,实现简单的聊天机器人功能。
本文详细介绍如何使用Anaconda或pip安装NLTK自然语言处理库,包括nltk_data下载及配置流程,通过示例代码展示如何利用NLTK进行词法分析,实现简单的聊天机器人功能。
nltk_data下载包
链接:https://pan.baidu.com/s/1K2PxZn6_-EULGDwY9YnClg
提取码:u4w2
使用anaconda打开Prompt
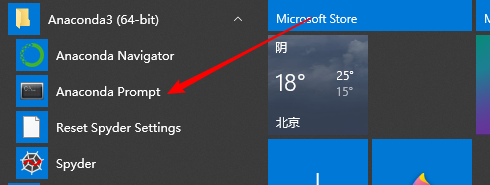
如果没有anaconda可以直接使用win+r打开命令提示符,输入cmd进行命令提示框操作。
anaconda和pip安装应该都可以,我是使用anaconda安装的。
打开命令提示框输入以下代码即可快速下载nltk
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ nltk
下载之后要接着下载nltk_data下载包才能使用nltk,下载包在文章开头有链接
打开创建的环境,输入python
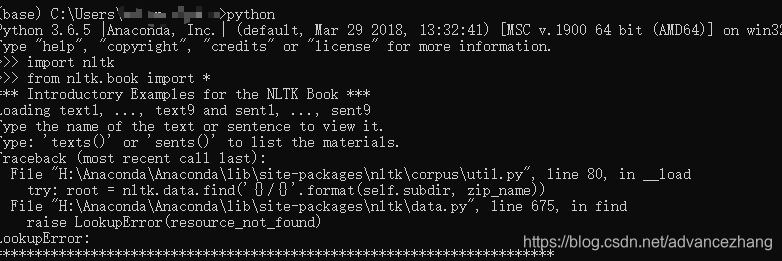
python输入之后再输入下面代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3187
3187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











