




强化学习常用数据集
在LLM场景下进行强化学习训练的时候,时常会涉及到各种各样的数据集,容易记不住,因此开个帖子记录一下。可采取的分类方法有很多,这里直接按照领域和标签的类型两个层次进行划分。
数学推理数据集
数值标签
GSM8K(2021 OpenAI)
由Openai在2021年提出的,包括约8500个小学数学问题(小学数学词汇水平)。
下载地址:https://huggingface.co/datasets/openai/gsm8k
论文地址:https://arxiv.org/pdf/2110.14168
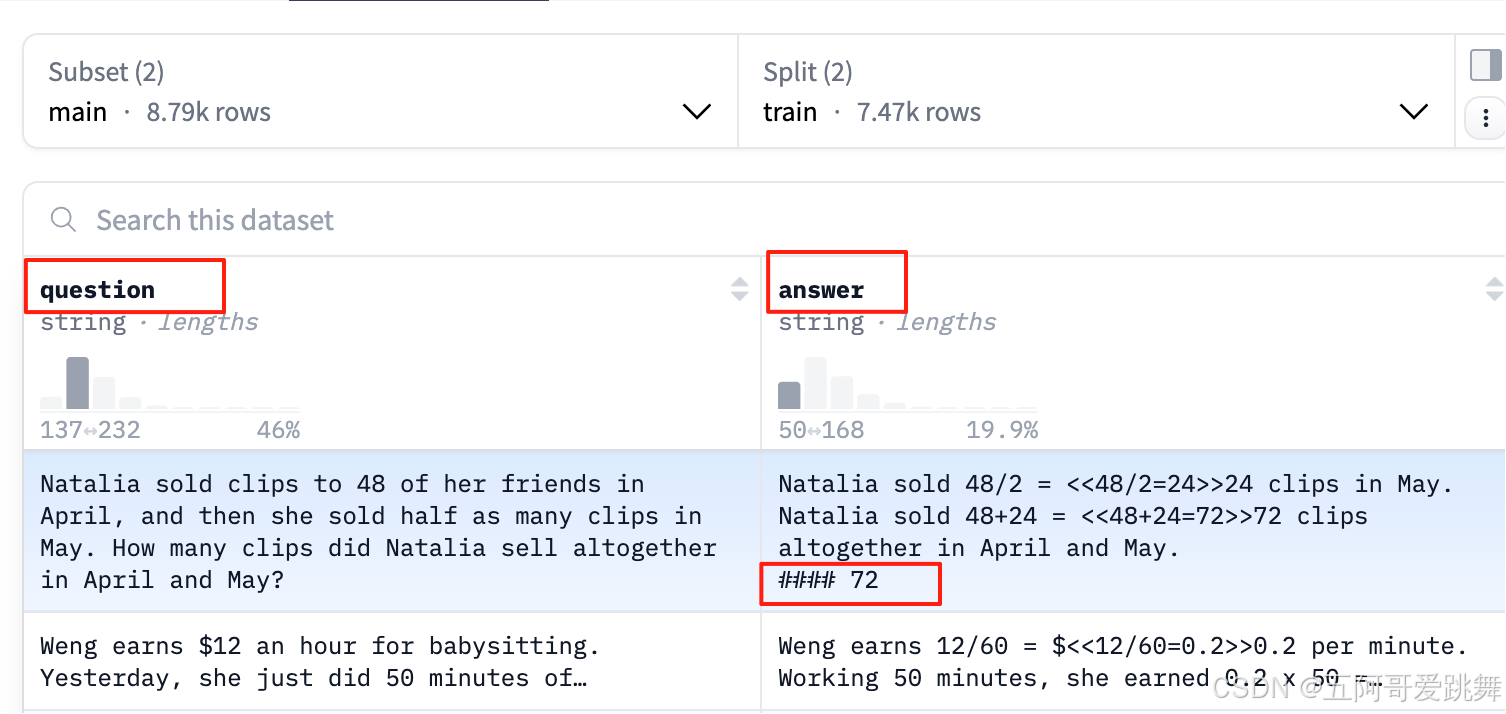
下面是论文中给出的三个例子,其中红色用<<>>扩起来的是对具体计算过程的注释。
最终的final answer是对于问题最终答案结果的注释。

但是,在观察实际数据的时候如下:
其中对于计算过程的注释没问题,用:<<>>
对于最终答案的注释,在实际的数据集中:用`#### `后的内容表示
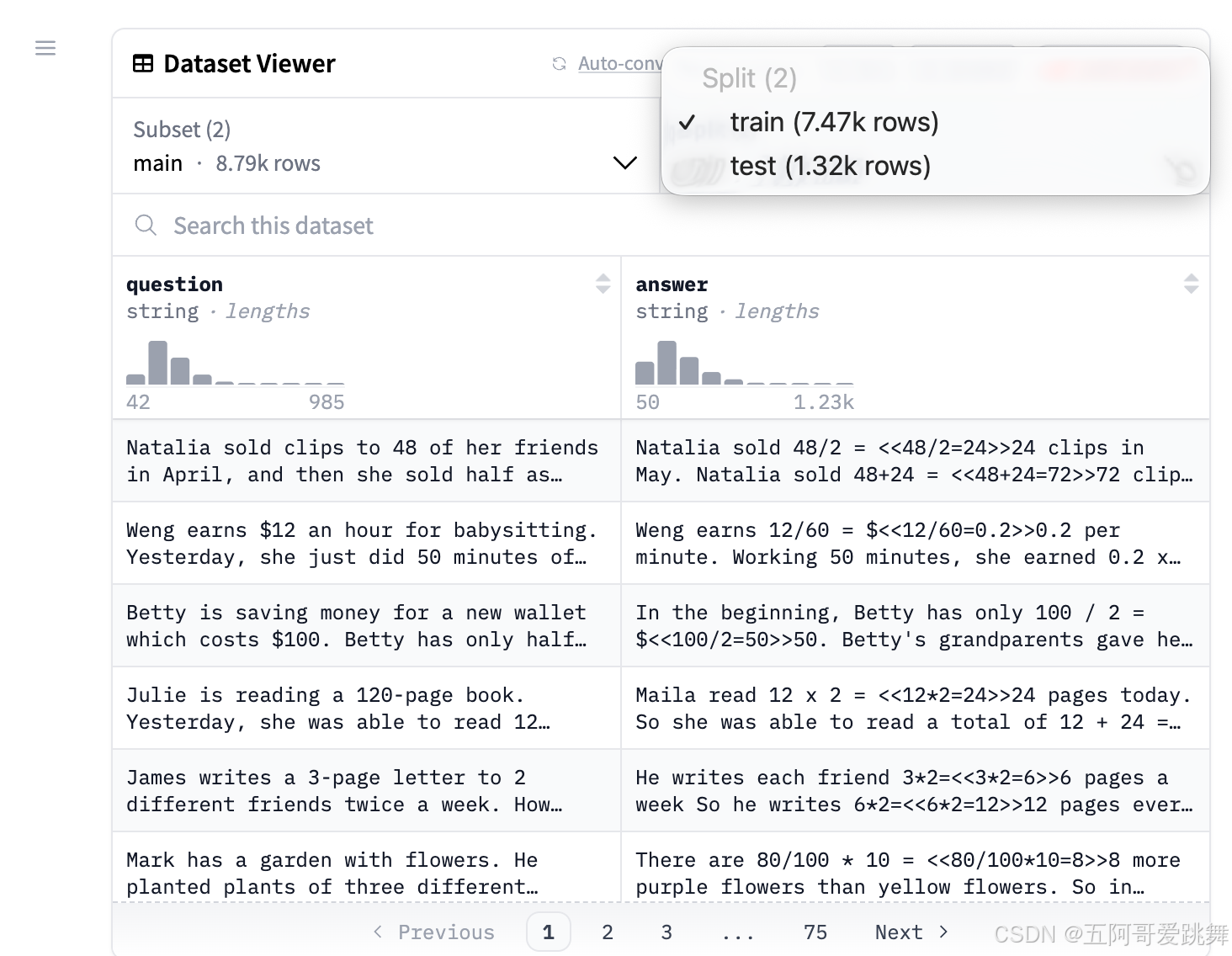
样本的数量和划分如下:
训练样本:7.47K(7473)
测试样本:1.32K(1319)
参考 qwen中对 GSM8K的答案提取方案:
https://github.com/QwenLM/Qwen/blob/main/eval/evaluate_gsm8k.py


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











