







前言
有关 ORCA 的论文介绍不少,但是关于 OCRA 源码介绍的好像是一点没有(包括英文资料)
整体性介绍一下 ORCA,比较粗略,一篇草稿文章(应该还会继续更新加内容,不鸽). 后面应该还会有更多细节文章(不鸽)
Overview
Orca是Pivotal公司基于top-down的Cascades框架实现的的查询优化器,主要用于Pivotal公司的另外两个系统:基于Hadoop的HAWQ和Greenplum。
Repo
原有的目录
https://github.com/greenplum-db/gporca
gp 仓库中的src/backend/gporca
https://github.com/greenplum-db/gpdb
Directory
.
├── cmake
├── concourse
├── data
├── gporca.mk
├── libgpdbcost
├── libgpopt
├── libgpos
├── libnaucrates
├── scripts
└── server
主要源代码都在 libgpopt 中
ORCA的特点:
- 模块化
- 高延展性
- 并发优化:ORCA 内部实现了可以利用多核并发的调度器来进一步提高对复杂语句的优化效率。
- 可验证和测试性
模块化
ORCA 作为一个Service独立运行,任何数据库只要对接好其接口,如下图,都能够利用这个优化器优化Query.
- Query2DXL把parse tree转成DXL(CTranslatorQueryToDXL::TranslateSelectQueryToDXL);
- DXL2Plan把DXL转成可执行的Plan(CTranslatorDXLToPlStmt::GetPlannedStmtFromDXL);
- MD provider把metadata转成DXL(CMDProviderRelcache::GetMDObj);
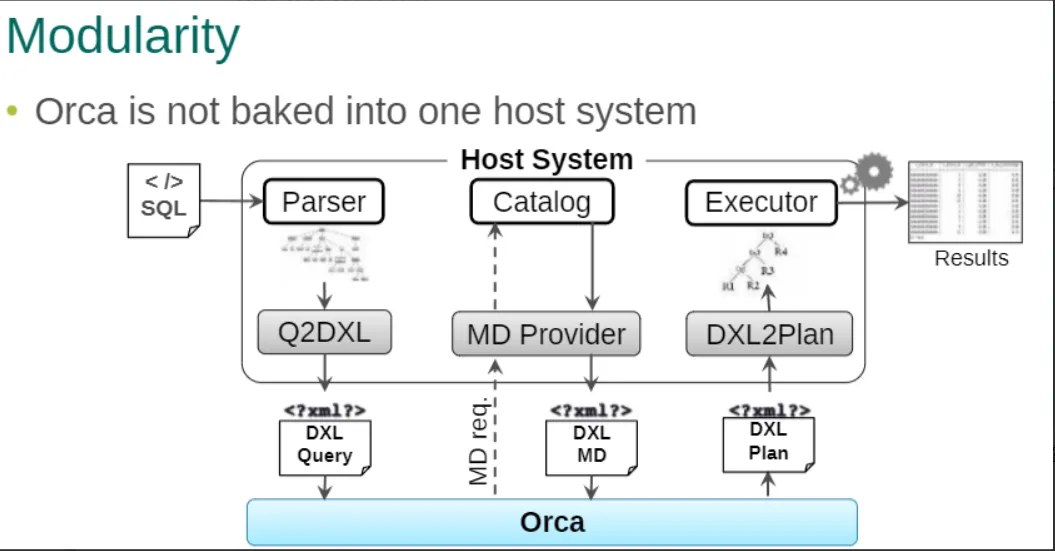
如上图,用户输入的查询语句,优化器输出的执行计划,数据库的元数据及数据分布都通过暴露的 RESTAPI 进行交互,交互语言为 DXL(Data eXchange Language)。
在 libgpopt/src/translate/ 目录下,实现了 DXL ↔ Expression 的转换
├── CTranslatorDXLToExpr.cpp
├── CTranslatorDXLToExprUtils.cpp
├── CTranslatorExprToDXL.cpp
└── CTranslatorExprToDXLUtils.cpp
src/backend/gpopt/translate
├── CCTEListEntry.cpp
├── CContextDXLToPlStmt.cpp
├── CContextQueryToDXL.cpp
├── CMappingColIdVarPlStmt.cpp
├── CMappingElementColIdParamId.cpp
├── CMappingVarColId.cpp
├── CQueryMutators.cpp
├── CTranslatorDXLToPlStmt.cpp
├── CTranslatorDXLToScalar.cpp
├── CTranslatorQueryToDXL.cpp
├── CTranslatorRelcacheToDXL.cpp
├── CTranslatorScalarToDXL.cpp
└── CTranslatorUtils.cpp
高延展性
因为 OCRA 是基于 Cascade 框架, 所以有着 top to down 的明显优势—扩展性。
算子类(libgpopt/src/operators),优化规则(transformation rule,libgpopt/src/xforms),数据类型类都支持扩展。使得 ORCA 可以不断迭代,非常容易加入新的优化规则。
libgpopt/src/operators
├── CExpression.cpp
├── CExpressionFactorizer.cpp
├── CExpressionHandle.cpp
├── CExpressionPreprocessor.cpp
├── CExpressionUtils.cpp
├── CHashedDistributions.cpp
├── CLogical.cpp
├── CLogicalApply.cpp
├── .......
libgpopt/src/xforms
├── CDecorrelator.cpp
├── CJoinOrder.cpp
├── CJoinOrderMinCard.cpp
├── CSubqueryHandler.cpp
├── CXform.cpp
├── CXformCTEAnchor2Sequence.cpp
├── CXformDifference2LeftAntiSemiJoin.cpp
├── CXformDynamicIndexGet2DynamicIndexScan.cpp
├── .......
以添加 CXformSplitGbAgg 这条规则为例
分别添加
- 头文件 libgpopt/include/gpopt/xforms
- cpp文件 orca/libgpopt/src/xforms
定义 Transformation 的 Trigger
- Pattern
- Pre-Condition Check
Pattern
GPOS_NEW(pmp)
CExpression
(
pmp,
// logical aggregate operator
GPOS_NEW(pmp) CLogicalGbAgg(pmp),
// relational child
GPOS_NEW(pmp) CExpression(pmp, GPOS_NEW(pmp) CPatternLeaf(pmp)),
// scalar project list
GPOS_NEW(pmp) CExpression(pmp, GPOS_NEW(pmp) CPatternTree(pmp))
)); Pre-Condition Check
添加一些常识规则(Common sense rules),例如不要在逻辑运算符上触发同一规则避免无限递归
// Compatibility function for splitting aggregates
virtual
BOOL FCompatible(CXform::EXformId exfid)
{
return (CXform::ExfSplitGbAgg != exfid);
}
添加 The Actual Transformation,编写具体的逻辑
void Transform
(
CXformContext *pxfctxt,
CXformResult *pxfres,
CExpression *pexpr
)
const; 注册规则,Register Transformation
void CXformFactory::Instantiate()
{
….
Add(GPOS_NEW(m_pmp) CXformSplitGbAgg(m_pmp));
….
} 并发优化
ORCA为了实现并发优化,实现了一个复杂的optimization job调度器。
每个优化路径的多个阶段拆分成了不同的job; job放入到queue中; 多线程从queue中消费job; job之间维护前后依赖关系,没有依赖关系可以并行;
最开始 list 会加入 CJobGroupOptimization 作为根parent节点,然后递归触发之后的 job push 进 list。进行 top-down 的递归遍历优化优化,PjParent(parent job)会先进入 list 中(CSyncList<SJobLink> m_listjlWaiting) 。子job没有执行完之前,PjParent 会一直 wait;

可验证和测试性
ORCA 具有极强的可验证性和可测试性,同时构建了一批测试和验证工具。
由于 ORCA 是一个 standalone 的 service,也大幅度简化了优化器的测试,只需要通过 DXL 输入 mock(假数据)数据,就可以进行优化并输出执行结果。非常容易复现,调试问题。
测试 ORCA,只需要通过 DXL 来 mock 一个测试环境,让 ORCA 给出相应的优化结果即可,甚至都不用启动数据库就能进行测试。
ORCA源码中除了包括 UT可以直接进行测试,还包括一系列 minidump 文件,用这个可以直接mock一个真正的查询进行 regression test。
./server/gporca_test -d ../data/dxl/minidump/TVFRandom.mdp (minidump 是一个 XML 文件,其中包含计划查询所需的所有输入,包括有关所有表、数据类型和使用的函数的信息以及统计信息。它还包含生成的计划。它可以通过 GPDB 运行 query 生成。)
Architecture
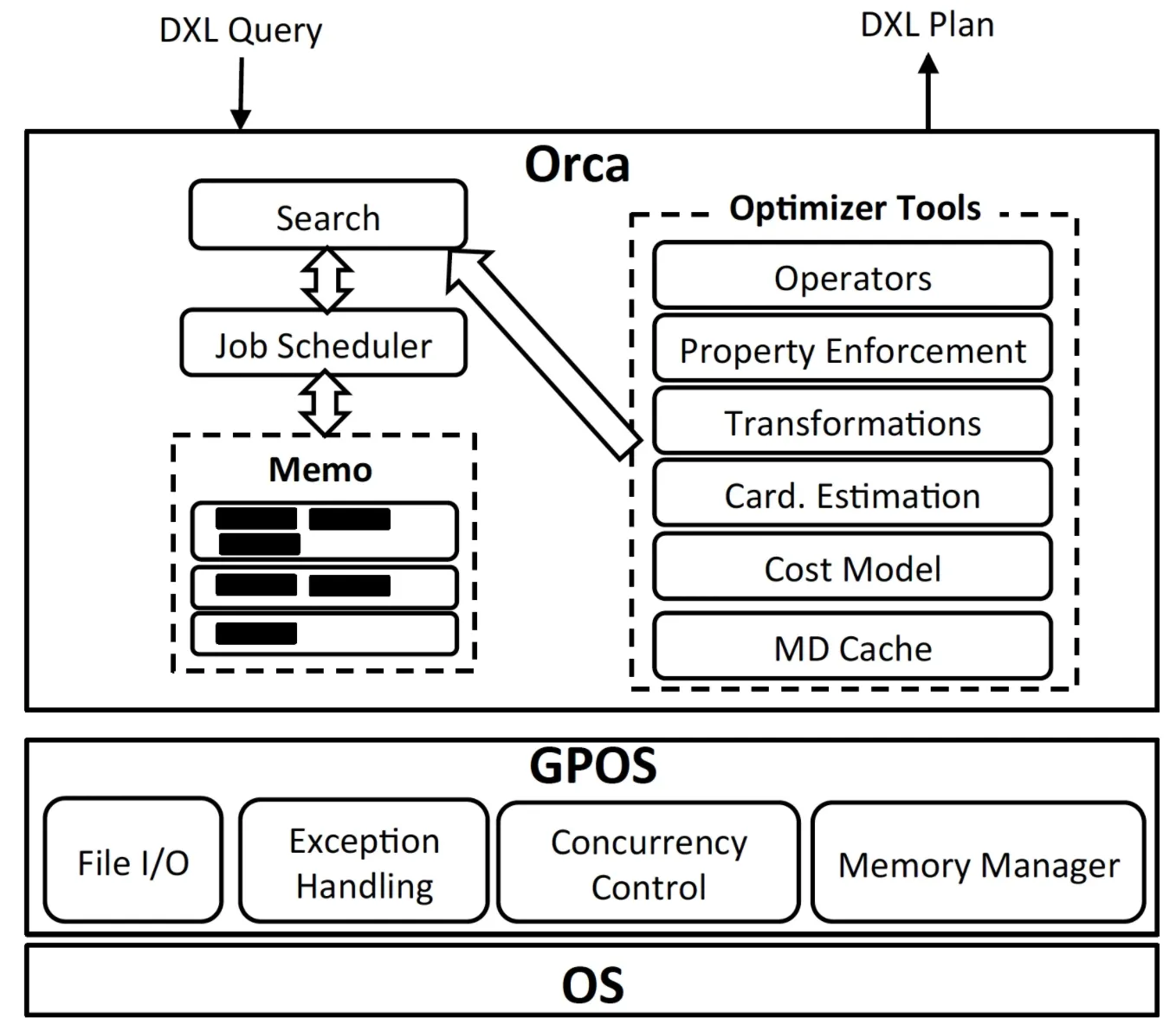
ORCA 内部的架构,如果对于 Cascade 框架有了解的,还是相对比较好理解的,基本一致。
Memo
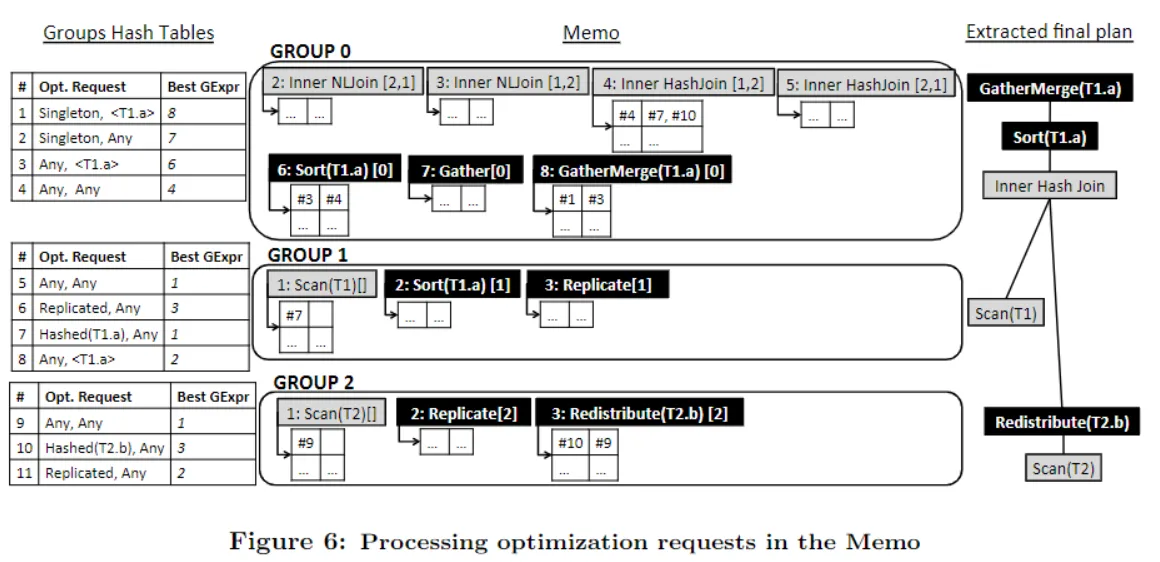
Cascades中的概念,是整个搜索空间的全局容器,代表逻辑等价类Group,表达式 Expr,都包含在其中,内部指针,共用共同结构来实现高效的结构重用,减少内存开销。
- Memo内部由一系列group组成;
- 一个Group代表一个逻辑等价表达式
- 里面会有若干逻辑等价子表达式 group expression
- eg: Group: [ABCD] 包含 A[BCD] B[ACD] C.... 其中的[ABCD]为Group, A[BCD] 为 GroupExpression
class Memo{
// memory pool
CMemoryPool *m_mp;
// id counter for groups
ULONG m_aul;
// root group
CGroup *m_pgroupRoot;
// number of groups
ULONG_PTR m_ulpGrps;
// tree map of member group expressions
MemoTreeMap *m_pmemotmap;
// list of groups
CSyncList<CGroup> m_listGroups;
// hashtable of all group expressions
CSyncHashtable<CGroupExpression, // entry
CGroupExpression>
}
Search & Job scheduler
具体的算法流程和执行优化的任务调度,和Cascades的paper一样,它把优化任务拆分为subtask。
但是不一样的是,ORCA也是分阶段的优化
搜索分为3个阶段:
- exploration;
- implementation;
- optimization;
而不是Cascades的交错优化。
Scheduler内有一个 m_listjlWaiting,Scheduler::run() 会不断循环从里面取得job,并且递归执行。
Job 有若干种类型,其中一些类型为父子关系。
enum EJobType
{
EjtTest = 0,
EjtGroupOptimization,
EjtGroupImplementation,
EjtGroupExploration,
EjtGroupExpressionOptimization,
EjtGroupExpressionImplementation,
EjtGroupExpressionExploration,
EjtTransformation,
EjtInvalid,
EjtSentinel = EjtInvalid
}; Scheduler 最开始会加入 EjtGroupOptimization job,这是所有 job 的祖先,然后由 ExecuteJobs 按照依赖关系,不停进行递归驱动。
以下是 libgpopt/src/search 目录下文件
├── CBinding.cpp
├── CGroup.cpp
├── CGroupExpression.cpp
├── CGroupProxy.cpp
├── CJob.cpp
├── CJobFactory.cpp
├── CJobGroup.cpp
├── CJobGroupExploration.cpp
├── CJobGroupExpression.cpp
├── CJobGroupExpressionExploration.cpp
├── CJobGroupExpressionImplementation.cpp
├── CJobGroupExpressionOptimization.cpp
├── CJobGroupImplementation.cpp
├── CJobGroupOptimization.cpp
├── CJobQueue.cpp
├── CJobTest.cpp
├── CJobTransformation.cpp
├── CMemo.cpp
├── CScheduler.cpp
├── CSchedulerContext.cpp
└── CSearchStage.cpp
Transformations
搜索空间的扩展是通过应用transformation规则:
- 逻辑规则:(A, B) -> (B, A)
- 物理规则:Join(A, B) -> HashJoin (A, B)
规则可能会产生新的group加入到Memo中,或者新的group expr加入到相同的group中。 每个规则都可以通过配置关闭。
Property enforcement
roperty的描述是规范且可扩展的,可以具有不同类型,paper中列举了3类:
- logical:output column;
- physical:sort order,distribution;
- scalar:join condition中引用到的column;
在opt阶段,每个operator都可以向子节点发射property的要求。子节点在经历完opt阶段后,可能自身能满足父节点发送过来的prop要求(indexscan能提供sort属性),也可能满足不了,此时需要加入一个enforcer,已满足请求的prop
Metadata Cache
Metadata Cache缓存在Orca侧,metadata通过version number来判断是否失效,这样下次再获取meta时可以先验证version信息,如果已过期再获取新数据,避免过多大量信息交互
Process
- Pre-Process Input Logical Expression – Apply heuristics like pushing selects down etc.
- Exploration (via Transforms) – Generate all equivalent logical plans
- Statistic Derivation: histograms
- Implementation (via Transforms) – Generate all physical implementation for all logical operators
- Optimization – Enforce distribution and ordering requirements and pick the cheapest
Pre-Process
libgpopt/include/gpopt/operators/CExpressionPreprocessor.h
优化器入口:COptimizer::PdxlnOptimize() 会调用
CQueryContext *pqc = CQueryContext::PqcGenerate(mp, pexprTranslated, pdrgpul, pdrgpmdname, true /*fDeriveStats*/);
生成 CQueryContext pqc. pqc构造函数里会进行preprocess
// (1) remove unused CTE anchors
// (2.a) remove intermediate superfluous limit
// (2.b) remove intermediate superfluous distinct
// (3) trim unnecessary existential subqueries
// (4) collapse cascaded union / union all
// (5) remove superfluous outer references from the order spec in limits, grouping columns in GbAgg, and
// (6) remove superfluous equality
// (7) simplify quantified subqueries
// (8) do preliminary unnesting of scalar subqueries
// (9) unnest AND/OR/NOT predicates
// (9.5) ensure predicates are array IN or NOT IN where applicable
// (10) infer predicates from constraints
// (11) eliminate self comparisons
// (12) remove duplicate AND/OR children
// (13) factorize common expressions
// (14) infer filters out of components of disjunctive filters
// (15) pre-process window functions
// (16) eliminate unused computed columns
// (17) normalize expression
// (18) transform outer join into inner join whenever possible
// (19) collapse cascaded inner and left outer joins
// (20) after transforming outer joins to inner joins, we may be able to generate more predicates from constraints
// (21) eliminate empty subtrees
// (22) collapse cascade of projects
// (23) insert dummy project when the scalar subquery is under a project and returns an outer reference
// (24) reorder the children of scalar cmp operator to ensure that left child is scalar ident and right child is scalar const
// (25) rewrite IN subquery to EXIST subquery with a predicate
// (26) normalize expression again
Reference
- https://github.com/greenplum-db/gporca
- https://15721.courses.cs.cmu.edu/spring2016/papers/p337-soliman.pdf
- https://www.youtube.com/watch?v=sJU3BXFr4Dc
- https://www.infoq.cn/article/5o16ehoz5zk6fzpsjpt2
- https://zhuanlan.zhihu.com/p/37



















 7727
7727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











