







 本文深入探讨了ClickHouse查询引擎的迭代模型,分析了其在OLAP查询中的性能困境,如CPU Pipeline的结构危害、数据危害、分支危害以及CPU Cache Misses。此外,文章提到了向量化执行模型(Vectorization)和编译后执行(Compilation)作为优化迭代模型的解决方案,旨在提高查询性能。通过对System R预编译执行和Hyber编译执行的讨论,阐述了编译执行的优势。最后,简要介绍了ClickHouse的查询执行模型,强调了Vectorization和Compilation的结合使用以实现更好的性能优化。
本文深入探讨了ClickHouse查询引擎的迭代模型,分析了其在OLAP查询中的性能困境,如CPU Pipeline的结构危害、数据危害、分支危害以及CPU Cache Misses。此外,文章提到了向量化执行模型(Vectorization)和编译后执行(Compilation)作为优化迭代模型的解决方案,旨在提高查询性能。通过对System R预编译执行和Hyber编译执行的讨论,阐述了编译执行的优势。最后,简要介绍了ClickHouse的查询执行模型,强调了Vectorization和Compilation的结合使用以实现更好的性能优化。
- ClickHouse 源码解析: 综述
- ClickHouse 源码解析: MergeTree Write-Path
- ClickHouse 源码解析: MergeTree Read-Path
- ClickHouse 源码解析: 查询引擎经典理论 (就是这篇)
- ClickHouse 源码解析: 查询引擎实现概述 (待更)
- ClickHouse 源码解析: 查询引擎源码解析 (待更)
- ClickHouse 源码解析: MergeTree Merge Algorithm (待更)
- ClickHouse 源码解析: ReplicatedMergeTree (待更)
- ClickHouse 源码解析: Vector Engine (向量化引擎) (待更)
- ClickHouse 源码解析: IColumn & Data Type (待更)
- ClickHouse 源码解析: Block & Block Streams (待更)
- ClickHouse 源码解析: Replication (副本) (待更)
- ClickHouse 源码解析: Parsers (语法解析) (待更)
- ClickHouse 源码解析: Functions & Aggregate Functions (函数) (待更)
- ClickHouse 源码解析: I/O Formats (待更)
- ClickHouse 源码解析: Server (待更)
- ClickHouse 源码解析: Group By (待更)
- ClickHouse 源码解析: Join (待更)
- ClickHouse 源码解析: Quey Optimization (待更)
- ClickHouse 源码解析: Materialized View (待更)
- ClickHouse 源码解析: Live View (待更)
- ClickHouse 源码解析: Window Functions (待更)
- ClickHouse 源码解析: User Define Function (UDF) (待更)
- ClickHouse 源码解析: Gorilla Codec (待更)
- ClickHouse 源码解析: Arrow Support (待更)
- ClickHouse 源码解析: Dictionay (待更)
由于查询引擎在数据库处于核心地位,我将查询引擎部分分为三个部分:
- 查询引擎经典理论
- 查询引擎实现概述
- 查询引擎源码解析
分别从理论、实现、源码解析三个维度去描述,这里仅介绍 "查询引擎经典理论" 这一部分,剩下两部分将会额外分成两篇内容。
1. 查询引擎架构
《Architecture of a Database System》 给出了普适意义上的 RDBMS 架构:

查询引擎使用存储引擎提供的数据,进行对应的计算,最终响应客户端的查询请求并输出结果。
执行一条SQL查询一般包括三个步骤
- SQL解析, 将 SQL 语句解析为数据库内部 AST
- 查询优化, 选择合适(性能、成本、时延稳定性等考虑因素)的查询执行方案
- 执行查询, 按照优化后的查询计划执行查询
如下图所示:

那为什么要分成这三个阶段呢 ?以我个人观点:
- SQL 是一种 DSL 语言,要去执行势必要先进行语义解析,而这部分是可复用的,因此SQL解析独立出来作为一个模块
- SQL 既然是一种 DSL 语言,要执行就需要有执行环境。就像 Java 语言有 Java 虚拟机,Python 有 Python 解释器,SQL 也需要有 SQL 执行环境,在一些SQL数据库实现中,SQL解析和执行分属于不同进程,因此执行也会独立出来作为一个模块
- 因为 SQL 语句有多种写法可以表达相同的语义,同一个查询有多种语义相同的执行方式(例如使用不同的索引,不同的JOIN顺序),具体选择哪个执行方式效率更高呢?这些优化的方式有可复用的部分,并且业界发现这一部分的实现复杂度极高,因此这一部分独立开来作为一个模块而非合并在查询执行中
在这里,我们聚焦于 “执行查询(Query Excution)” 这一方面,因为在 ClickHouse 的实现中:
- SQL 解析是完全按照 ClickHouse 的 SQL 语法手工打造的,这部分并非 ClickHouse 的核心
- 查询优化在ClickHouse的地位,相比于传统关系型数据库明显较低,因为 ClickHouse 更聚焦于简单的聚合查询,而不是复杂的多表 JOIN 查君。
- 执行引擎则是向量化执行引擎,辅以简单的 JIT 运行时代码生成,是 ClickHouse 之所以性能出众,比较核心的部分
2. 迭代模型 (Iterator Model)
说起数据库查询执行模型,就绕不开迭代模型。
迭代模型又称为火山模型(Volcano),或者说 Pipeline 模型,几乎应用于所有90年代之后的现代数据库实现中。
迭代模型的特点是:
- 每个 SQL 算子(如 SeqScan / Hash Join / Group by),都实现了一个 Next() 方法,用来返回一个 Tuple,或者是 null (当没有新的数据时)。而将这些 SQL 算子组合起来
- 每个算子可以有 N 个子算子提供 input
- 通过实现 Loop 不断重复调用 Next() 及调用子节点的 Next(),便可以不断驱动查询的一步步执行,直到最终查询完成
看起来,就像是这样:
class iterator {
iterator &inputs[];
void init();
tuple next();
void close();
}迭代模型有一些非常好的优点:
- 简单,容易实现,每个 SQL 算子都只需实现 Next() 接口及初始化 (Init) 和销毁收尾的代码 (Close)
- 灵活程度高,只需要简单组合这些算子即可完成各种复杂的查询
- I/O 友好,读到数据后,马上就能参与后续的计算和输出
以下面的 SQL 查询为例:
SELECT R.id, S.cdate
FROM R JOIN S
ON R.id = S.id
WHERE S.value > 100
从上图中,我们可以得到以下认知:
- 将SQL算子按照树形结构,组织为无环组合,进行查询
- 每个算子都会实现一个 Next() 算子
- Next() 算子每次仅返回一个 Tuple (可以近似理解为一行数据)
- 对于 Hash Join 来说,情况复杂一些,需要先对左侧的算子重复调用 Next() 构建 HashTable 后,才能每次调用右侧算子 Next() 可以输出一个 Tuple
- 对于类似 Hash Join / Group By 这种,不能进去一个 Tuple 出来一个 Tuple 的算子,称之为 Pipeline-Breaker,而在 Spark 中,Pipeline-Breaker 算子通常会造成需要拆分出新的 Job Stage
而迭代模型的执行过程,可以简要示例如下:

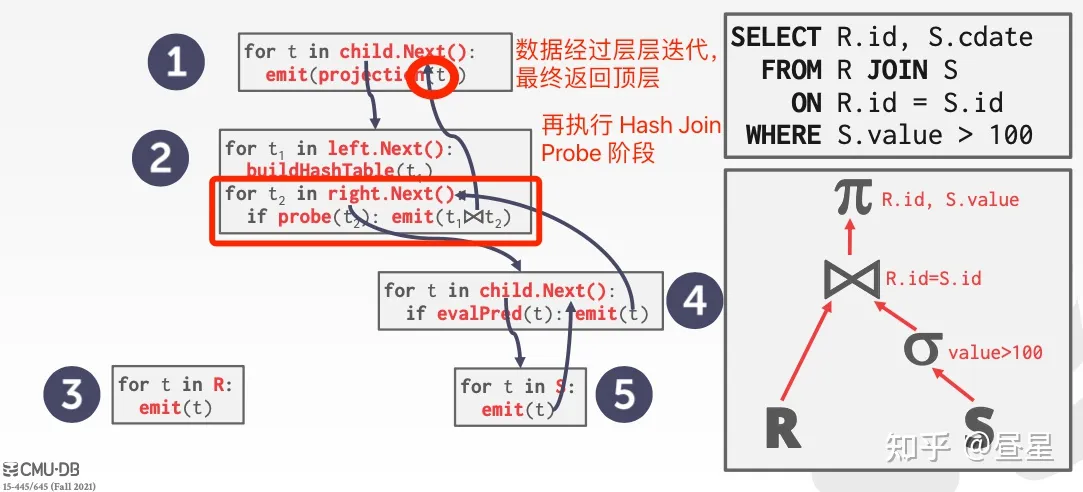
从上图中,我们可以得到以下认知:
- 迭代模型从最上层的算子调用 Next() 开始驱动
- 从上到下的 Next() 调用,可以理解为查询的控制流
- 从下到上的 Next() Tuple 传递,可以理解为查询的数据流
- 从观感上看,感觉像是顶层算子,不断的 Pull 子节点的算子,这种自上而下的迭代模型执行方式又称为 Pull-based query engine。
再举一个更真实一点的例子,Postgresql 的迭代模型实现。Postgresql 的源码中,有一段对于其迭代模型实现方式的一段非常简洁清晰的描述, Postgresql: src/backend/executor/execProcnode.c
首先我们可以看到 execProcnode.c 文件头的注释完美表达了迭代模型的基础概念。
* execProcnode.c
* contains dispatch functions which call the appropriate "initialize",
* "get a tuple", and "cleanup" routines for the given node type.
* If the node has children, then it will presumably call ExecInitNode,
* ExecProcNode, or ExecEndNode on its subnodes and do the appropriate
* processing.- ExecInitNode, 算子初始化
- ExecProcNode, 返回一个 Tuple
- ExecEndNode, 算子生命周期结束时的收尾处理
- 如果有子节点,将会根据算子逻辑需要去调用子算子的 ExecInitNode/ExecProcNode/ExecEndNode
接着,execProcnode.c注释中,有一个举例 (也可跳过,后面会简要解释一下)
* EXAMPLE
* Suppose we want the age of the manager of the shoe department and
* the number of employees in that department. So we have the query:
*
* select DEPT.no_emps, EMP.age
* from DEPT, EMP
* where EMP.name = DEPT.mgr and
* DEPT.name = "shoe"
*
* Suppose the planner gives us the following plan:
*
* Nest Loop (DEPT.mgr = EMP.name)
* / \
* / \
* Seq Scan Seq Scan
* DEPT EMP
* (name = "shoe")
*
* ExecutorStart() is called first.
* It calls InitPlan() which calls ExecInitNode() on
* the root of the plan -- the nest loop node.
*
* * ExecInitNode() notices that it is looking at a nest loop and
* as the code below demonstrates, it calls ExecInitNestLoop().
* Eventually this calls ExecInitNode() on the right and left subplans
* and so forth until the entire plan is initialized. The result
* of ExecInitNode() is a plan state tree built with the same structure
* as the underlying plan tree.
*
* * Then when ExecutorRun() is called, it calls ExecutePlan() which calls
* ExecProcNode() repeatedly on the top node of the plan state tree.
* Each time this happens, ExecProcNode() will end up calling
* ExecNestLoop(), which calls ExecProcNode() on its subplans.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











