




LangChain 的链(Chain)
LangChain 的链(Chain)是一种将多个组件(如模型、提示、记忆、工具等)组合在一起的方式,用于实现复杂的任务流程。链可以串联多个步骤,使任务处理更加模块化和可复用。以下是 LangChain 中链的核心概念和常见用法:
常见的Chain类型包括:
- LLMChain —— 最基础的链
- SimpleSequentialChain —— 简单顺序链
- SequentialChain —— 复杂顺序链
- TransformChain —— 纯数据转换链(不调用 LLM)
- RouterChain —— 路由链,根据输入内容自动分发到不同分支
- MapReduceChain —— 映射-归约链,适合处理大规模文本
基础链——LLMChain
LLMChain 是 LangChain 框架中的核心组件,用于将大型语言模型(LLM)与其他模块(如提示模板、记忆系统或输出解析器)串联起来,构建可定制的链式工作流。其核心思想是通过组合不同模块实现复杂任务(如问答、文本生成或数据转换),同时保持灵活性和可扩展性。
核心组件与功能
语言模型(LLM)
支持集成 OpenAI、Anthropic 等第三方模型或本地部署的模型,通过统一接口调用生成文本。
提示模板(PromptTemplate)
定义动态提示的模板,支持变量插值。例如:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("解释{term}的概念:")
链式执行(Chain Execution)
将模型调用与后续处理步骤(如过滤、格式化)结合。典型用法:
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
result = chain.run(term="机器学习")
典型应用场景
问答系统
结合检索器(Retriever)从文档中获取上下文,再通过 LLMChain 生成答案。结构化输出生成
使用输出解析器(Output Parser)将模型返回的自然语言转换为 JSON 或字典格式。多步骤任务
通过 SequentialChain 将多个 LLMChain 连接,例如先生成大纲再撰写文章。高级配置选项
记忆集成
通过 Memory 模块(如 ConversationBufferMemory)保存对话历史,实现上下文感知。回调函数
监控链的执行过程,例如记录中间结果或处理错误。超参数控制
调整temperature或max_tokens等参数控制生成结果的多样性和长度。
示例代码:完整工作流
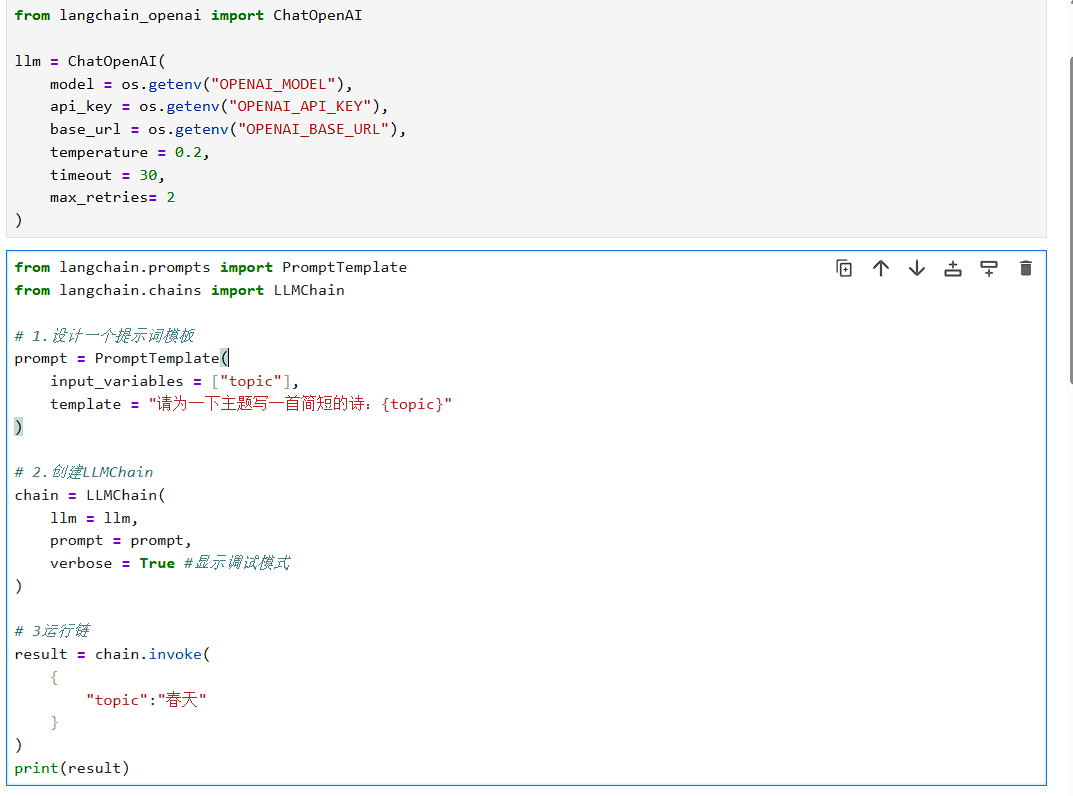
输出示例:

通过模块化设计和链式组合,LLMChain 能够灵活适应从简单文本生成到复杂决策流程的各种需求。
输出解析链(带结构化结果)
输出解析链(Output Parsers)是 LangChain 中用于将模型生成的文本转换为结构化数据(如 JSON、Pydantic 模型等)的工具。
使用 Pydantic 模型解析结构化数据
通过 PydanticOutputParser 可以将模型输出解析为预定义的 Pydantic 模型结构:
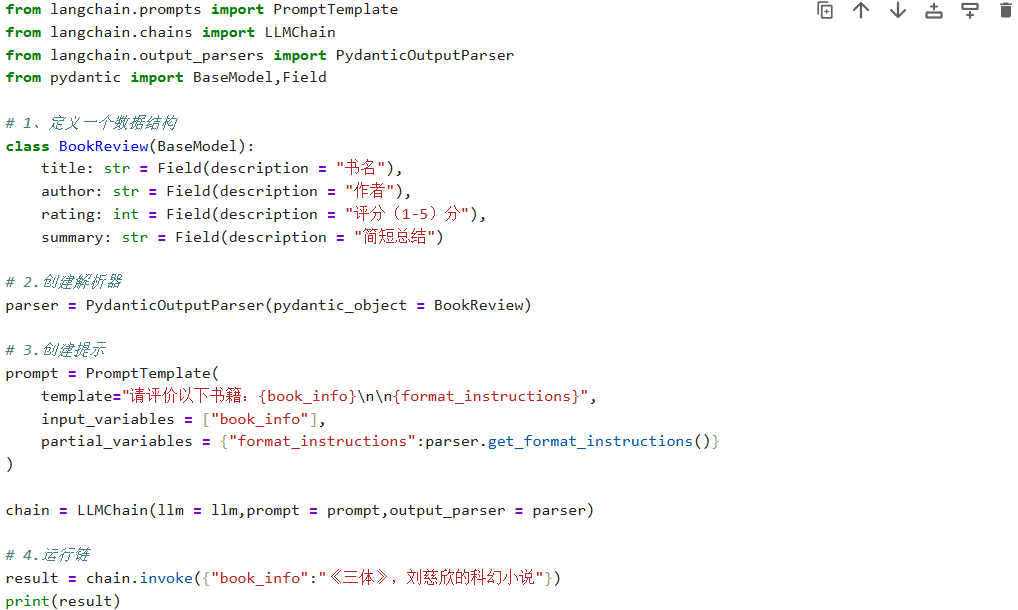
输出结果:

注意:

调用的LLMChain将被弃用,改成下面的方法

使用 JSON 解析器
通过 StructuredOutputParser 生成并解析 JSON 格式结果:
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# 定义输出字段
response_schemas = [
ResponseSchema(name="answer", description="回答内容"),
ResponseSchema(name="source", description="数据来源")
]
# 创建解析器
parser = StructuredOutputParser.from_response_schemas(response_schemas)
# 在提示中加入格式说明
prompt = PromptTemplate(
template="回答问题:{query}\n{format_instructions}",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# 调用模型
input_prompt = prompt.format_prompt(query="法国的首都是什么?")
output = model(input_prompt.to_string())
# 解析为字典
result_dict = parser.parse(output)
print(result_dict) # 输出:{'answer': '巴黎', 'source': '常识'}
自定义解析逻辑
通过继承 BaseOutputParser 实现完全自定义解析:
from langchain.schema import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser):
def parse(self, text: str):
return text.strip().split(", ")
parser = CommaSeparatedListOutputParser()
result = parser.parse("苹果, 香蕉, 橙子")
print(result) # 输出:['苹果', '香蕉', '橙子']
处理解析错误
使用 OutputFixingParser 自动修复格式错误的输出:
from langchain.output_parsers import OutputFixingParser
fix_parser = OutputFixingParser.from_llm(parser=parser, llm=OpenAI())
broken_output = "名字:李四 年龄:40" # 缺少JSON格式
fixed_result = fix_parser.parse(broken_output)
关键参数说明
- format_instructions:自动生成的格式提示文本,需包含在提示模板中
- partial_variables:允许在模板中预填充部分变量
- temperature=0:建议设置为0以保证输出稳定性
- ResponseSchema:需明确定义每个字段的名称和描述
通过组合这些组件,可以构建鲁棒的输出解析流程,将非结构化文本转换为可直接程序处理的结构化数据。
简单顺序链(SimpleSequentialChain)
在实际应用中,许多复杂任务需要分解为多个相互关联的步骤依次执行。例如,要生成一个完整的故事,可能需要先拟定故事大纲,再根据大纲展开具体内容。👉 SimpleSequentialChain就如同思维上的接力赛:它将多个子任务连接成一个线性工作流,前一个链的输出会自动成为下一个链的输入,实现多步任务的自动化执行。
from langchain.chains import SimpleSequentialChain
# 第一个节点:生成大纲
outline_prompt = PromptTemplate(
input_variables=["theme"],
template="请为以下主题写一个故事大纲:{theme}"
)
outline_chain = LLMChain(llm=llm, prompt=outline_prompt)
# 第二个节点:写故事
story_prompt = PromptTemplate(
input_variables=["outline"],
template="根据以下大纲写一个故事:{outline}"
story_chain = LLMChain(llm=llm, prompt=story_prompt)
# 顺序链
sequential_chain = SimpleSequentialChain(
chains=[outline_chain, story_chain], # 先大纲然后写故事
verbose=True
)
result = sequential_chain.run("人工智能与人类的友谊")
print(result)
核心机制讲解
- 链式执行 :第一个链(outline_chain)接收初始输入(如主题)并生成故事大纲;第二个链(story_chain)自动将该大纲作为输入,生成完整故事。
- 自动化传递 :SimpleSequentialChain 自动管理中间结果的传递,无需手动截取、解析和传递上一个步骤的输出。
- 透明化流程 :设置 verbose=True可在控制台查看每个步骤的输入和输出,方便调试与优化。
👉 SimpleSequentialChain 非常适用于多阶段生成式任务 ,例如:
- 内容创作 :先生成提纲,再撰写文章或报告
- 代码开发 :先设计模块或接口,再实现具体代码
- 数据分析 :先进行数据筛选,再执行分析或可视化
通过将复杂任务分解为有序步骤,SimpleSequentialChain 既能提升输出质量,又能增强生成过程的可控性和可解释性。
复杂顺序链(SequentialChain)
当任务逻辑更为复杂,涉及多个输入与输出,且步骤间需要灵活传递不同变量时,SequentialChain 便成为理想的选择。*** 👉我们可以将其比作一个高度协调的“智能流水线”:它能够接收多种原材料(输入),经由多个专业工位(子链)分步处理,最终产出多种成品(输出)。
from langchain.chains import SequentialChain
# 链1:市场分析
analysis_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(
input_variables=["product_idea"],
template="分析以下产品的市场需求:{product_idea}"
),
output_key="analysis"
)
# 链2:开发计划
plan_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(
input_variables=["product_idea", "analysis"],
template="基于 {product_idea} 和 {analysis} 制定开发计划"
),
output_key="plan"
)
# 链3:成本估算
cost_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(
input_variables=["plan"],
template="根据 {plan} 估算成本"
),
output_key="cost"
)
# SequentialChain
sequential_chain = SequentialChain(
chains=[analysis_chain, plan_chain, cost_chain],
input_variables=["product_idea"],
output_variables=["analysis", "plan", "cost"],
verbose=True
)
result = sequential_chain.invoke({"product_idea": "AI 健康管理应用"})
print(result)
核心机制讲解
- 多输入多输出 :与 SimpleSequentialChain不同,SequentialChain允许指定多个 input_variables和 output_variables,每个子链都可以通过 output_key命名其输出,供后续链使用。
- 灵活的变量传递 :后续链可以自由选择使用前面任何一个链的输出(或初始输入)作为其输入变量,只需在 prompt 的 input_variables中声明即可。
- 结构化结果 :最终返回的是一个字典(dictionary),可以通过 result["market_analysis"]、result["dev_plan"]等方式直接获取每个步骤的结构化输出,极大方便了后续的程序化处理。
👉 SequentialChain就像一位高级项目协调员 ,它能够:
- 分解复杂任务 :将诸如产品规划、市场调研、文章撰写等复杂任务拆解为多个逻辑步骤。
- 协调信息流转 :自动管理中间信息,确保每个步骤都能获取所需的上游结果。
- 提供全面产出 :最终输出每个关键步骤的结果,形成一个完整的报告或方案,非常适合需要多角度分析或内容生成的自动化场景。
转换链(TransformChain)
LangChain的工作流并不总是需要调用大语言模型。在某些场景中,我们可能只需要对文本进行预处理、清洗或格式化,例如去除多余空格、提取关键信息、正则匹配替换等。这时,TransformChain便提供了轻量且高效的解决方案。
👉你可以将TransformChain看作一个灵活的“文本加工站”:它接收原始文本(输入),通过自定义的处理函数进行转换,并将加工后的结果(输出)传递给下游任务或其他链使用。
from langchain.chains import TransformChain
import re
from typing import Dict
def clean_text(inputs: Dict[str, str]) -> Dict[str, str]:
text = inputs["text"]
cleaned = re.sub(r'\s+', ' ', text.strip()) # 去掉多余空格
return {"cleaned_text": cleaned}
transform_chain = TransformChain(
input_variables=["text"],
output_variables=["cleaned_text"],
transform=clean_text
)
result = transform_chain.invoke({"text": "这是 一个 测试 文本"})
print(result["cleaned_text"])
核心机制讲解
- 纯函数处理 :TransformChain 的核心是一个自定义的 transform函数,它接收一个包含输入变量的字典,返回一个包含输出变量的字典。整个过程不调用LLM ,完全在本地执行。
- 声明式输入输出 :通过 input_variables和 output_variables明确指定链需要哪些输入以及会产生哪些输出,便于集成到更大的链式工作流中。
- 灵活的处理逻辑 :你可以在 transform函数中实现任何文本处理逻辑,例如:
- 正则表达式匹配与替换
- 文本标准化与格式化
- 关键词提取或过滤
- 简单的编码转换或长度裁剪
常见应用场景
TransformChain 非常适合在调用 LLM 前进行数据预处理,或在拿到 LLM 输出后进行结果后处理,例如:
- 数据清洗 :去除用户输入或日志文本中的多余空格、特殊字符、敏感信息等。
- 格式标准化 :将不同格式的日期、数字或代码片段统一为指定格式。
- 信息提取 :使用正则表达式从原始文本中快速提取结构化字段(如电话号码、邮箱),再交由LLM进一步处理。
- 结果后处理 :对 LLM 生成的文本进行格式化、截断或添加前后缀。
👉 它的最大优势在于轻量与可控 ,能够高效、可靠地完成那些不需要AI参与的确定性文本操作任务,是构建健壮、高效AI流水线的重要工具。
路由链
在实际应用中,用户的提问往往涉及多个领域:可能是数学计算、编程问题,也可能是一般知识问答。如果所有问题都使用同一个Prompt进行处理,不仅效果难以保障,也浪费计算资源。
RouterChain的作用就是根据输入内容自动判断问题类型,并将其路由(分配)到最合适的专家链(ExpertChain)上进行处理** 。你可以将其想象为一个“智能调度中心”或“多路分配器”:先识别问题意图,再定向到对应的专业处理流程。
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
# 定义不同的专门链
math_template = """你是一个数学专家。请解决以下数学问题:
{input}
请提供详细的解题步骤。"""
programming_template = """你是一个编程专家。请帮助解决以下编程问题:
{input}
请提供代码示例和详细解释。"""
general_template = """请回答以下问题:
{input}
请提供准确和有用的信息。"""
# 定义路由的候选 Prompt
prompt_infos = [
{
"name": "math",
"description": "适合回答数学相关的问题,例如算术、代数、几何",
"prompt_template": math_template,
},
{
"name": "programming",
"description": "适合回答编程相关的问题,包括Python、算法、调试",
"prompt_template": programming_template,
},
{
"name": "general",
"description": "适合回答一般常识性问题",
"prompt_template": general_template,
},
]
# 创建目标链(destination chains)
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt = PromptTemplate(template=p_info["prompt_template"], input_variables=["input"])
destination_chains[name] = LLMChain(llm=llm, prompt=prompt)
# 默认链(如果没有匹配到任何类别)
default_prompt = PromptTemplate(template=general_template, input_variables=["input"])
default_chain = LLMChain(llm=llm, prompt=default_prompt)
# 创建路由提示
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations="\n".join(destinations))
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser()
)
# 创建路由链
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# 将 RouterChain 与目标链组合成 MultiPromptChain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True
)
# 测试不同问题
test_questions = [
"计算 2x + 3 = 7 中 x 的值",
"如何在 Python 中实现快速排序算法?",
"中国的首都是哪里?"
]
for question in test_questions:
print(f"\n❓ 用户问题: {question}")
result = chain.run(question)
print(f"🤖 回答: {result}")
运行效果与机制
- 数学问题 (如"计算2x+3=7中x的值")会被自动路由到math链,获得详细的数学推导和解题步骤。
- 编程问题 (如"如何在Python中实现快速排序算法?")会被路由到programming链,得到包含代码示例和解释的专业回答。
- 一般性问题 (如"中国的首都是哪里?")会被路由到general链,获得简洁准确的通用回答。
- 无法识别的问题 会自动fallback到默认链处理,确保系统鲁棒性。
🚀 核心优势与应用价值
RouterChain 通过智能路由机制实现了专业化与自动化的统一:
- 精准化处理 :根据不同问题类型自动选择最合适的专家 Prompt,显著提升回答质量和准确性
- 极强的可扩展性 :可以轻松添加新的处理分支(如添加"法律问题 → 法律专家"、"医疗咨询 → 医疗专家"等)
- 资源优化 :避免为简单问题调用复杂模型,提高响应效率并降低计算成本
- 架构清晰 :通过路由机制实现关注点分离,使系统更易于维护和迭代
典型应用场景
智能客服系统、多领域问答机器人、内容分类与处理管道、自动化工作流分配等。
通过 RouterChain,您可以构建真正理解用户意图的智能分发系统,让每个问题都能找到最合适的解答者。

















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









