



目录
1.机器学习基本介绍
1.1机器学习定义
机器学习(Machine Learning)本质上就是让计算机自己在数据中学习规律,并根据所得到的规律对未来数据进行预测。
机器学习包括如聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等算法。
机器学习的基本思路是模仿人类学习行为的过程,如我们在现实中的新问题一般是通过经验归纳,总结规律,从而预测未来的过程。机器学习的基本过程如下:

1.2机器学习的发展历史
从上世纪50年代的图灵测试提出、塞缪尔开发的西洋跳棋程序,标志着机器学习正式进入发展期。
60年代中到70年代末的发展几乎停滞。
80年代使用神经网络反向传播(BP)算法训练的多参数线性规划(MLP)理念的提出将机器学习带入复兴时期。
90年代提出的“决策树”(ID3算法),再到后来的支持向量机(SVM)算法,将机器学习从知识驱动转变为数据驱动的思路。
21世纪初Hinton提出深度学习(Deep Learning),使得机器学习研究又从低迷进入蓬勃发展期。
从2012年开始,随着算力提升和海量训练样本的支持,深度学习(Deep Learning)成为机器学习研究热点,并带动了产业界的广泛应用。
1.3机器学习分类
按学习模式的不同,可分为监督学习、半监督学习、无监督学习和强化学习。
1.3.1监督学习
监督学习(Supervised Learning)是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。如果分类标签精确度越高,则学习模型准确度越高,预测结果越精确。
监督学习主要用于回归和分类。
常见的监督学习的回归算法有线性回归、回归树、K邻近、Adaboost、神经网络等。
常见的监督学习的分类算法有朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等。
1.3.2半监督学习
半监督学习(Semi-Supervised Learning)是利用少量标注数据和大量无标注数据进行学习的模式。
半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
1.3.3无监督学习
无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程。
无监督学习主要用于关联分析、聚类和降维。
常见的无监督学习算法有稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
1.3.4强化学习
强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,是通过不断试错进行学习的模式。
在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
强化学习常用于机器人避障、棋牌类游戏、广告和推荐等应用场景中。
1.4如何学习机器学习
学习数学基础:了解线性代数、概率论和统计学等数学概念。这些概念在机器学习中非常重要,可以帮助您理解算法和模型背后的原理。
学习编程语言:掌握至少一种常用的编程语言,如Python或R。这些语言在机器学习中广泛使用,具有丰富的机器学习库和工具。
学习机器学习算法:了解常见的机器学习算法,如线性回归、决策树、支持向量机、神经网络等。学习它们的原理、应用和优缺点。
学习机器学习工具和框架:熟悉常用的机器学习工具和框架,如scikit-learn、TensorFlow、PyTorch等。掌握它们的使用方法和基本操作。
实践项目:通过实践项目来应用所学的知识。选择一些小型的机器学习项目,从数据收集和预处理到模型训练和评估,逐步提升自己的实践能力。
学习资源:利用在线教程、课程、书籍和开放资源来学习机器学习。有很多免费和付费的学习资源可供选择,如Coursera、Kaggle、GitHub上的机器学习项目等。
参与机器学习社区:加入机器学习社区,与其他学习者和专业人士交流经验和学习资源。参与讨论、阅读博客、参加线下活动等,扩展自己的学习网络。
持续学习和实践:机器学习是一个不断发展的领域,保持学习的态度并持续实践非常重要。跟随最新的研究成果、参与竞赛和项目,不断提升自己的技能。
记住,机器学习是一个广阔的领域,需要不断的学习和实践才能掌握。持续投入时间和精力,逐步积累经验和知识,便会逐渐掌握机器学习的技能。
1.5机器学习的应用场合
机器学习的应用场景非常广泛,几乎涵盖了各个行业和领域。以下是一些常见的机器学习应用场景的示例:
-
自然语言处理(NLP)
自然语言处理是人工智能中的重要领域之一,涉及计算机与人类自然语言的交互。NLP技术可以实现语音识别、文本分析、情感分析等任务,为智能客服、聊天机器人、语音助手等提供支持。
-
医疗诊断与影像分析
机器学习在医疗领域有着广泛的应用,包括医疗图像分析、疾病预测、药物发现等。深度学习模型在医疗影像诊断中的表现引人注目。
-
金融风险管理
机器学习在金融领域的应用越来越重要,尤其是在风险管理方面。模型可以分析大量的金融数据,预测市场波动性、信用风险等。
-
预测与推荐系统
机器学习在预测和推荐系统中也有广泛的应用,如销售预测、个性化推荐等。协同过滤和基于内容的推荐是常用的技术。
-
制造业和物联网
物联网(IoT)在制造业中的应用越来越广泛,机器学习可用于处理和分析传感器数据,实现设备预测性维护和质量控制。
-
能源管理与环境保护
机器学习可以帮助优化能源管理,减少能源浪费,提高能源利用效率。通过分析大量的能源数据,识别优化的机会。
-
决策支持与智能分析
机器学习在决策支持系统中的应用也十分重要,可以帮助分析大量数据,辅助决策制定。基于数据的决策可以更加准确和有据可依。
-
图像识别与计算机视觉
图像识别和计算机视觉是另一个重要的机器学习应用领域,它使计算机能够理解和解释图像。深度学习模型如卷积神经网络(CNN)在图像分类、目标检测等任务中取得了突破性进展。
1.6机器学习趋势分析
机器学习正真开始研究和发展应该从80年代开始,深度神经网络(Deep Neural Network)、强化学习(Reinforcement Learning)、卷积神经网络(Convolutional Neural Network)、循环神经网络(Recurrent Neural Network)、生成模型(Generative Model)、图像分类(Image Classification)、支持向量机(Support Vector Machine)、迁移学习(Transfer Learning)、主动学习(Active Learning)、特征提取(Feature Extraction)是机器学习的热点研究。
以深度神经网络、强化学习为代表的深度学习相关的技术研究热度上升很快,近几年仍然是研究热点。
1.7机器学习项目开发步骤
有5个基本步骤用于执行机器学习任务:
-
收集数据:无论是来自excel,access,文本文件等的原始数据,这一步(收集过去的数据)构成了未来学习的基础。相关数据的种类,密度和数量越多,机器的学习前景就越好。
-
准备数据:任何分析过程都会依赖于使用的数据质量如何。人们需要花时间确定数据质量,然后采取措施解决诸如缺失的数据和异常值的处理等问题。探索性分析可能是一种详细研究数据细微差别的方法,从而使数据的质量迅速提高。
-
练模型:此步骤涉及以模型的形式选择适当的算法和数据表示。清理后的数据分为两部分 - 训练和测试(比例视前提确定); 第一部分(训练数据)用于开发模型。第二部分(测试数据)用作参考依据。
-
评估模型:为了测试准确性,使用数据的第二部分(保持/测试数据)。此步骤根据结果确定算法选择的精度。检查模型准确性的更好测试是查看其在模型构建期间根本未使用的数据的性能。
-
提高性能:此步骤可能涉及选择完全不同的模型或引入更多变量来提高效率。这就是为什么需要花费大量时间进行数据收集和准备的原因。
2.scikit-learn
2.1scikit-learn的介绍
-
Python语言机器学习工具
-
Scikit-learn包括许多智能的机器学习算法的实现
-
Scikit-learn文档完善,容易上手,丰富的API接口函数
-
Scikit-learn官网:scikit-learn: machine learning in Python — scikit-learn 1.5.2 documentation
-
Scikit-learn中文文档:sklearn
2.2scikit-learn安装
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
2.3scikit-learn包含的内容
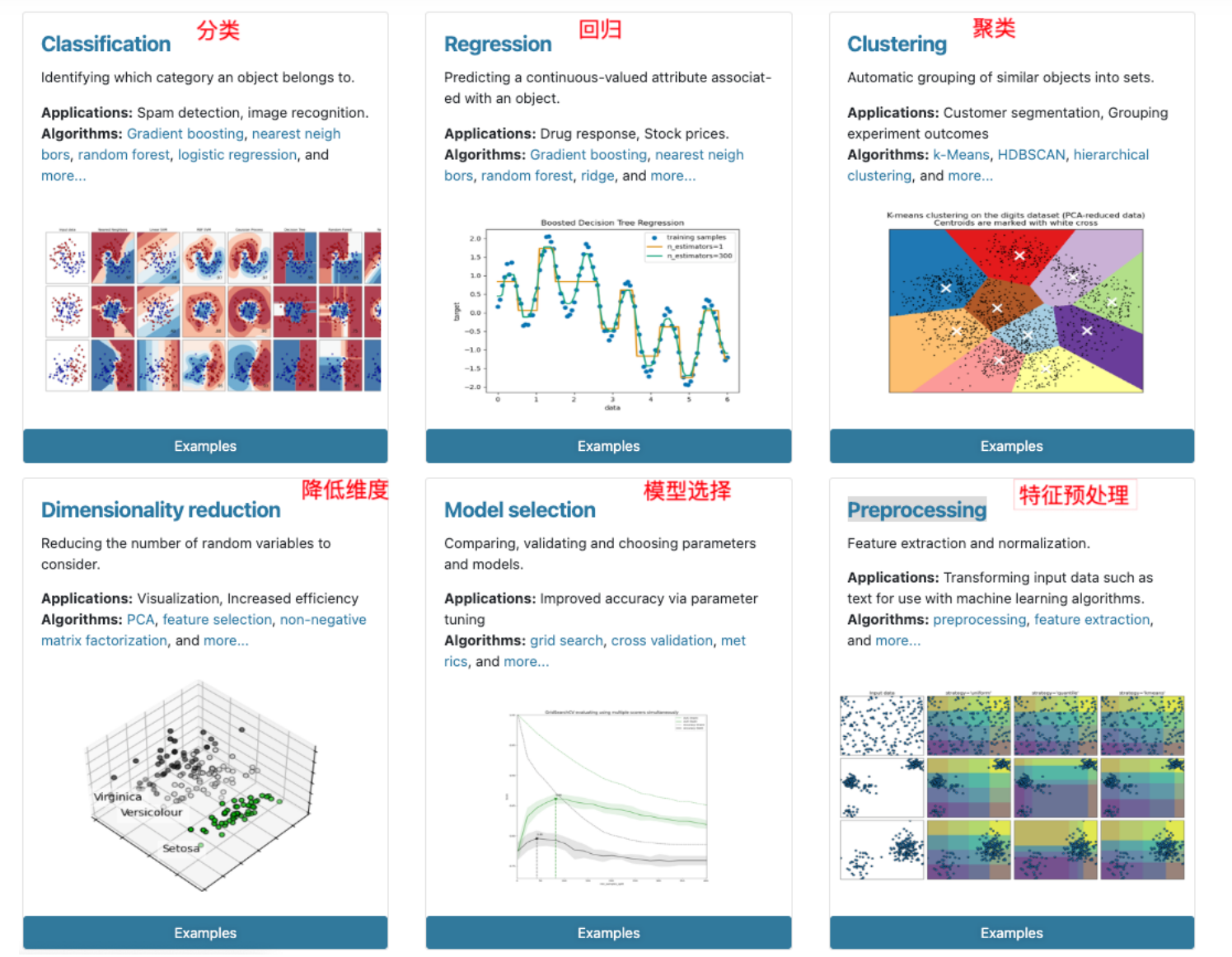
3.数据集
3.1sklearn数据集的属性
| data | 数据的特征值 |
| feature_names | 特征描述 |
| target | 目标,分类索引 |
| target_names | 目标描述,分类名组成的列表 |
| DESCR | 数据集的描述 |
| filename | 下载到本地保存后的文件名 |
# 加载数据集:鸢尾花
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data, '\n')
print(iris.feature_names, '\n')
print(iris.target, '\n')
print(iris.target_names, '\n')
print(iris.DESCR, '\n')
print(iris.filename, '\n')3.2sklearn玩具数据集
3.2.1klearn玩具数据集介绍
数据量小,数据在sklearn库的本地。
| load_iris() | 加载并返回鸢尾花数据集(分类) |
| load_diabetes() | 加载并返回糖尿病数据集(回归) |
| load_digits() | 加载并返回手写数字(0 到 9)的 8x8 像素图像(分类) |
| load_linnerud() | 加载并返回物理锻炼数据集 |
| load_wine() | 加载并返回葡萄酒数据集(分类) |
| load_breast_cancer() | 加载并返回乳腺癌数据集(分类) |
3.2.2klearn加载玩具数据集
示例1:鸢尾花数据
鸢尾花数据集介绍
特征:
花萼长 sepal length
花萼宽sepal width
花瓣长 petal length
花瓣宽 petal width
三分类:
0-Setosa山鸢尾
1-Versicolour变色鸢尾
2-Virginica维吉尼亚鸢尾
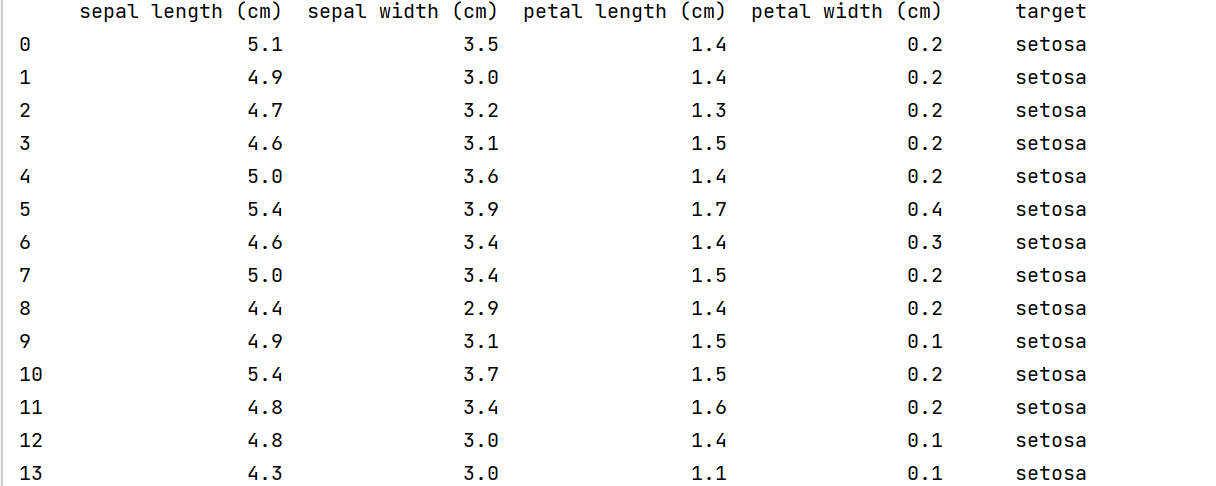
使用pandas把特征和目标一起显示出来
from sklearn.datasets import load_iris
iris = load_iris()
iris_df = pd.DataFrame(
data=iris.data,
columns=iris.feature_names
)
iris_df['target'] = [iris.target_names[i] for i in iris.target]
# 设置Pandas显示选项以完整打印DataFrame
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', None)
print(iris_df)
# 取出某一样本
print(iris_df.iloc[80])
3.3sklearn现实世界数据集
3.3.1sklearn现实世界数据集介绍
数据量大,数据只能通过网络获取
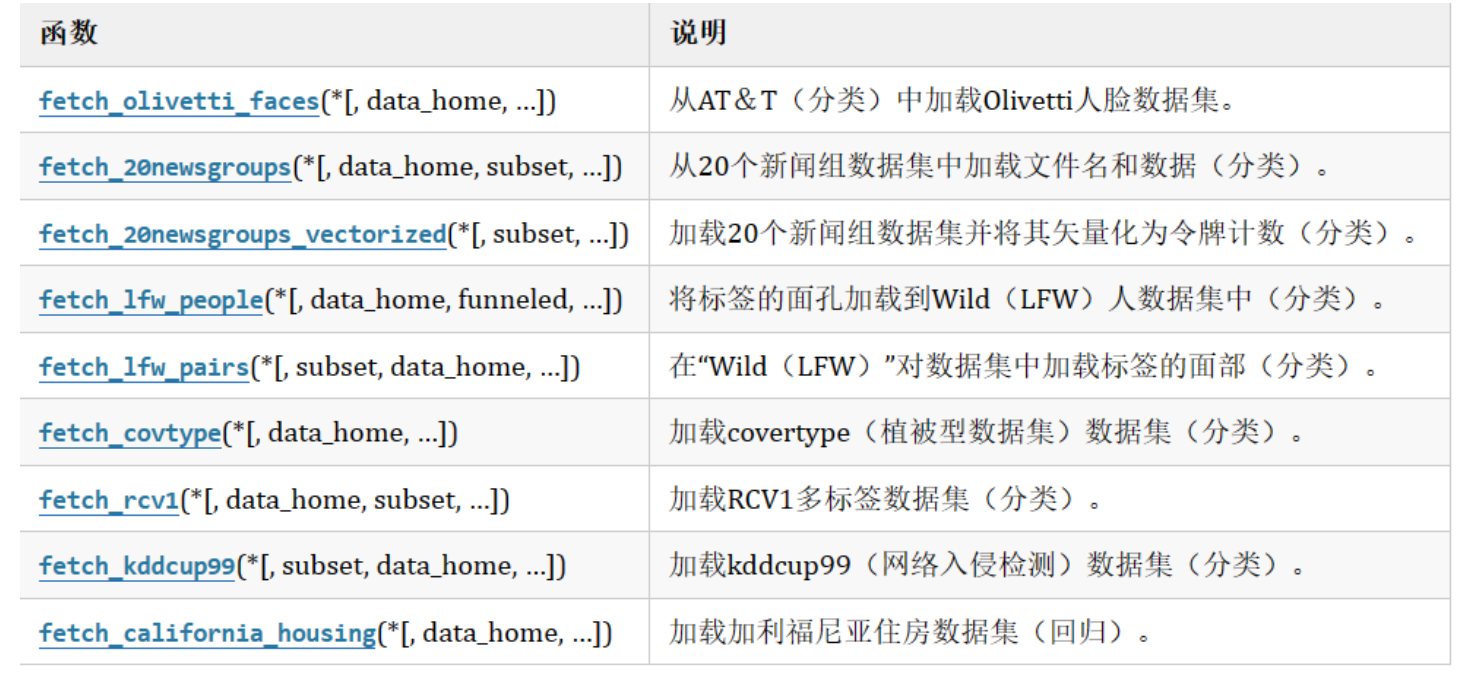
3.3.2sklearn获取现实世界数据集
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
import numpy as np
info = fetch_california_housing(data_home='./src')
x_train, x_test, y_train, y_test = train_test_split(info.data, info.target, train_size=0.8, random_state=4)
print(x_train[0:5])4.本地csv数据
4.1创建csv文件
方式1:打开计事本,输入如下数据,数据之间使用英文下的逗号, 保存文件后把后缀名改为csv
, milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
方式2:创建excel 文件, 填写数据,以csv为后缀保存文件
4.2pandas加载csv
使用pandas的read_csv(“文件路径”)函数可以加载csv文件,得到的结果为数据的DataFrame形式
5数据集的划分
5.1API
sklearn.model_selection.train_test_split(*arrays,**options)
参数:
- *array
这里用于接收1到多个"列表、numpy数组、稀疏矩阵或padas中的DataFrame"。
- **options, 重要的关键字参数有:
test_size 值为0.0到1.0的小数,表示划分后测试集占的比例
random_state 值为任意整数,表示随机种子,使用相同的随机种子对相同的数据集多次划分结果是相同的。否则多半不同
返回:
返回值为列表list, 列表长度与形参array接收到的参数数量相关联, 形参array接收到的是什么类型,list中对应被划分出来的两部分就是什么类型
5.2示例
5.2.1列表数据集划分
因为随机种子都使用了相同的整数,所以划分的划分的情况是相同的。
from sklearn.model_selection import train_test_split
lt1 = [1, 2, 3, 4, 5]
lt2 = ['a', 'c', 'd', 'e', 'f']
# 测试集占样本总数test_size
X_train, X_test = train_test_split(lt2, test_size=0.2)
print(X_train, '\t', X_test)
X_train, X_test, y_train, _y_test = train_test_split(lt1, lt2, test_size=0.2)
print(X_train, '\t', X_test)
# 训练集和测试集占比相加:train_size+test_size<=1
X_train, X_test, y_train, _y_test = train_test_split(lt1, lt2, train_size=0.5,test_size=0.2)
print(X_train, '\t', X_test)
# 随机种子random_state
X_train, X_test, y_train, _y_test = train_test_split(lt1, lt2, train_size=0.5,random_state=4)
print(X_train, '\t', X_test)5.2.2ndarray数据集划分
划分前和划分后的数据类型是相同的
lt = [1, 2, 3, 4, 5]
arr = np.array(["a", "b", "c", "d", "e"])
x_train, x_test, y_train, y_test = train_test_split(lt, arr, test_size=0.4, random_state=22)
print(x_train, '\t', x_test, '\t', y_train, '\t', y_test)
print(type(x_train), '\t', type(x_test), '\t', type(y_train), '\t', '\t', type(y_test))5.2.3二维数组数据集划分
train_test_split只划分第一维度,第二维度保持不变
data1 = np.arange(1, 10, 1)
data1.shape = (3, 3)
print(data1, '\n')
X_train, X_test = train_test_split(data1, test_size=0.4, random_state=22)
print(X_train, '\t', X_test, '\n')
# 不打乱顺序
X_train, X_test = train_test_split(data1, test_size=0.4, random_state=22, shuffle=False)
print(X_train, '\t', X_test)5.2.4DataFrame数据集划分
可以划分DataFrame, 划分后的两部分还是DataFrame
data1 = np.arange(1, 16, 1)
data1.shape = (5, 3)
data1 = pd.DataFrame(data1, index=[1, 2, 3, 4, 5], columns=["one", "two", "three"])
print(data1)
a, b = train_test_split(data1, test_size=0.4, random_state=9)
print("\n", a)
print("\n", b)
5.2.5字典数据集划分
可以划分非稀疏矩阵
DictVectorizer用于将字典列表转换为特征向量。这个转换器主要用于处理类别数据和数值数据的混合型数据集
(1)对于类别特征DictVectorizer 会为每个不同的类别创建一个新的二进制特征,如果原始数据中的某个样本具有该类别,则对应的二进制特征值为1,否则为0。
(2)对于数值特征保持不变,直接作为特征的一部分
from sklearn.feature_extraction import DictVectorizer
data = [{'city': '成都', 'age': 30, 'temperature': 20},
{'city': '重庆', 'age': 33, 'temperature': 60},
{'city': '北京', 'age': 42, 'temperature': 80},
{'city': '上海', 'age': 22, 'temperature': 70},
{'city': '成都', 'age': 72, 'temperature': 40},
]
# 转为稀疏矩阵
transfer = DictVectorizer(sparse=True)
date_new = transfer.fit_transform(data)
print(date_new,'\n')
print(date_new.toarray(),'\n')
X_train, X_test = sklearn.model_selection.train_test_split(date_new, train_size=0.8)
print(X_train, '\n')
print(X_test, '\n')
X_train, X_test = sklearn.model_selection.train_test_split(date_new.toarray(), train_size=0.8)
print(X_train, '\n')
print(X_test, '\n')5.2.6sklearn玩具数据划分
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
news = load_digits()
X_train, X_test, y_train, y_test = train_test_split(news.data, news.target, train_size=0.8, random_state=4)
print(type(X_train))
print(type(X_test))
print(len(X_train))
print(len(X_test))
print(type(y_train))
print(type(y_test))
print(y_train.shape)
print(y_test.shape)5.2.7sklearn现实世界数据划分
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
import numpy as np
info = fetch_california_housing(data_home='./src')
X_train, X_test, y_train, y_test = train_test_split(info.data, info.target, train_size=0.8, random_state=4)
print(type(X_train))
print(type(X_test))
print(len(X_train))
print(len(X_test))
print(type(y_train))
print(type(y_test))
print(y_train.shape)
print(y_test.shape)

















 2226
2226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









