



计算机小白读论文的记录,应该会有很多错误,所以不建议作为参考,欢迎各位大佬指正。
论文链接:[2404.16030] MoDE: CLIP Data Experts via Clustering (arxiv.org)
背景
CLIP简介
mode框架继承了clip的核心思想,所以先简单介绍一下clip。
CLIP(Contrastive Language-Image Pre-training)是由OpenAI在2021年发布的一种多模态预训练神经网络。它的核心思想是使用大量图像和文本的配对数据作为训练集,通过对比学习的方式来预训练一个模型,使其能够理解图像和文本之间的关系。CLIP在零样本学习场景下表现出色,它在不使用ImageNet数据集的任何一张图片进行训练的情况下,最终模型精度能跟一个有监督的训练好的ResNet-50打成平手。
CLIP训练集规模
因为后面有将mode与clip在不同规模上进行对比的实验,所以我们先来了解一下clip的训练集规模。
OpenAI CLIP(原始模型):WIT400M
Open CLIP(CLIP模型的开源实现):LAION-400M和LAION-2B
Mate CLIP(改进了数据集和训练方法):400M和2.5B图像-文本对
MoDE(Mixture of Data Experts)框架继承了CLIP的核心思想,即通过对比学习来训练视觉-语言模型,并在此基础上引入了“数据专家”的概念,通过聚类和模型集成来提高模型的性能和训练效率。
目的
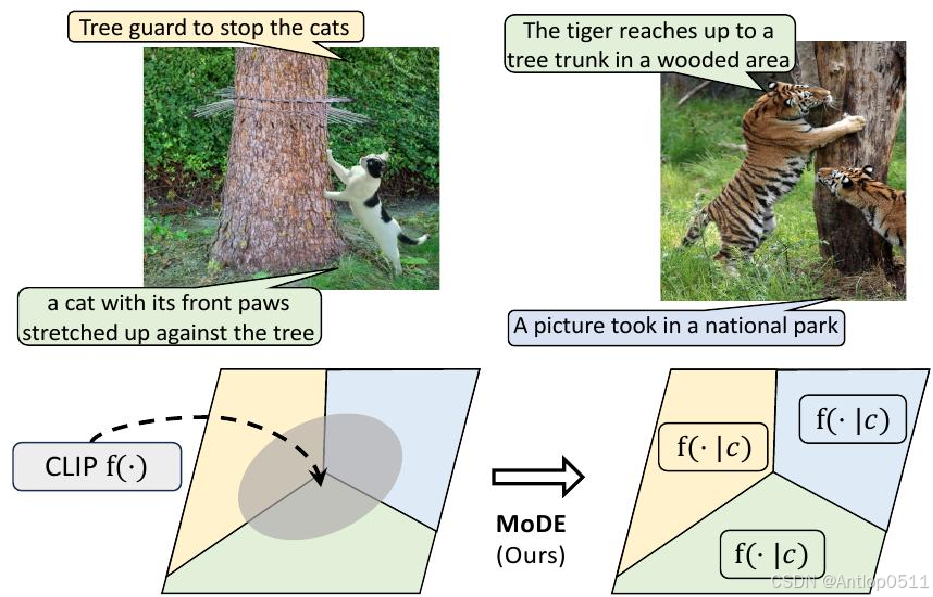
1.首先是为了解决clip预训练中存在的问题,由于配对的文本通常描述有限的视觉内容,因此常见的情况是,两张相似的图像具有截然不同的文本描述,尤其是在充满噪声的网络爬取数据中。当这些图像-文本对在同一个批次中采样时,其他图像的文本会变成假阴性。
以左边这张图猫的图片为例,上面这个描述和下面这个描述都是合理的,但当两张这样的图片在同一个批次中采样的时候,其中一个文本描述会很容易被视为负样本。
2.在训练集中加入难负样本,通常被证实是可以提高模型的性能的。
例如对于下面这两张猫和老虎的图片来说,假如猫的图像文本对是正样本,由于两张图片具有一定的相似性,老虎的图文本对也会容易被认为是正样本,这就是一个难负样本。
Mode框架通过聚类,将假阴性样本分到不同的簇中,并将具有相似语义的样本配对,从而减轻假阴性文本带来的噪声,并增加了同一个簇中难负样本的数量,进而提高模型的表现。(比如将猫的这两个文本描述分到不同的簇中,将猫和老虎的这两个文本描述分到一起)
下图中,是否分到同一个簇可以根据颜色来看,相同颜色的会被分到同一个簇
贡献
• 研究了CLIP预训练中的高质量负样本,特别是网络爬取的图像-文本对中的假阴性噪声。
• 提出了通过聚类学习 CLIP 数据专家系统的MoDE框架,且MoDE框架能在推理时自适应地集成数据专家以用于下游任务。
• 通过大量的实验研究表明,MoDE 在零样本迁移基准测试中取得了显著效果,同时训练成本较低。MoDE 可以灵活地纳入新的数据专家,因此有利于持续预训练。
方法
整体框架
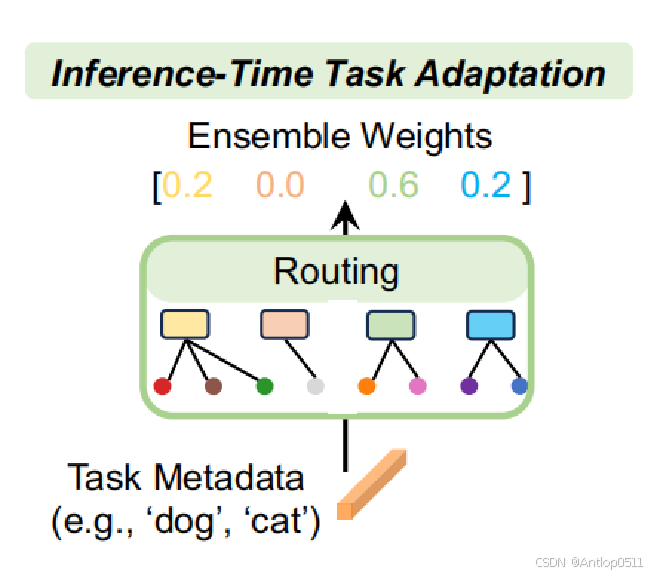
这是MoDE的框架图,总体可以分为左边的数据专家预训练模块和右边的推理时任务适应模块。
首先,将训练数据,也就是图像-文本对,通过两步聚类分成几个不相交的子集;然后,每个聚类都通过对比学习的方式来训练一个模型。这样,每个模型都由一个集群中的训练数据进行专门化,这也是为什么叫做数据专家。当应用于下游任务(例如图像分类)时,任务元数据首先与每个数据集群的质心进行比较,以确定需要激活哪个数据专家。然后使用选定的数据专家来创建图像和类别的嵌入。具有最高集成相似度的类别将作为分类结果输出。
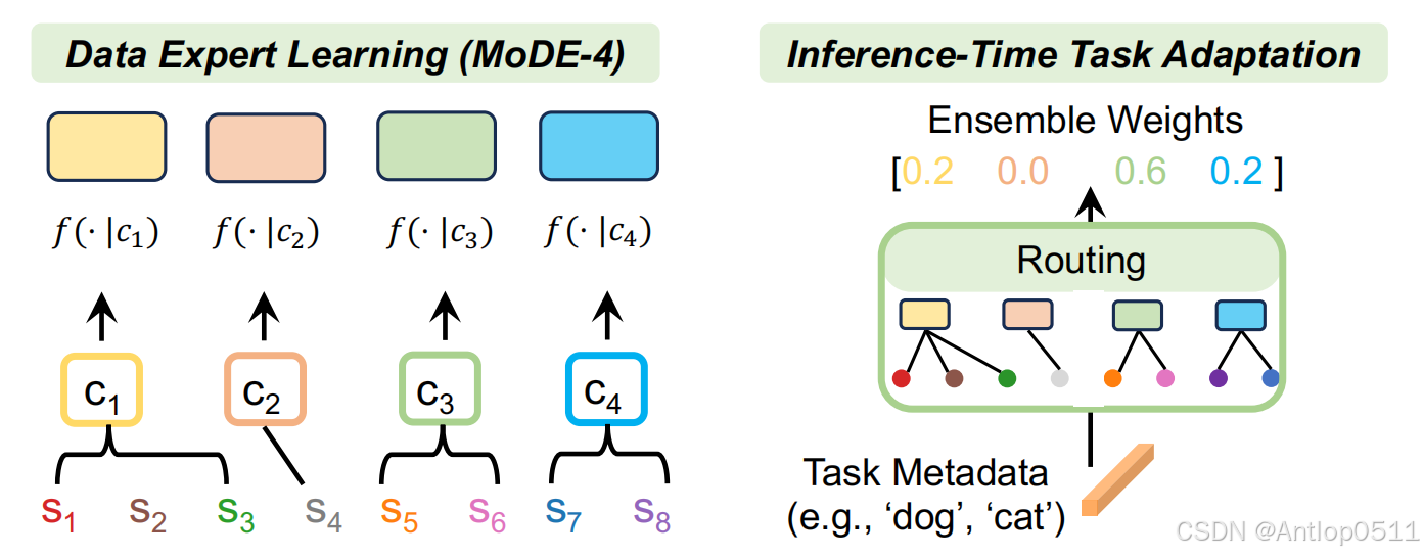
论文原文:
(1) The training data is first clustered into several disjoint subsets by the captions; each cluster is then used to train a model following the standard contrastive learning method.
(2) When applied to downstream tasks, the task metadata are first compared to the centroid of each data cluster to determine which data expert needs to be activated. The class with the highest ensembled similarity is then output as the classification result.
聚类
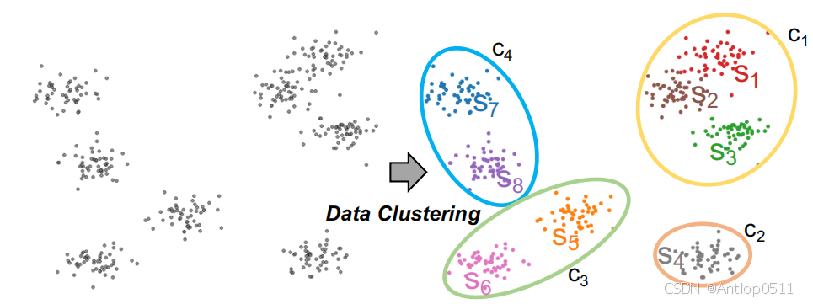
下面进行详细介绍。为了让聚类中心具有代表性,同时数据专家的数量不能过多,MoDE使用了两步聚类。首先对训练数据进行细粒度聚类,得到细粒度聚类中心集合S,再对S进行粗粒度聚类,得到粗粒度聚类中心集合C。
两次聚类使用的都是K-means算法,k-means算法是一种经典的聚类算法,它将数据划分为k个簇,并使得每个数据点与其聚类中心之间的距离之和最小。
在进行第一步聚类的时候,由于训练数据D数量巨大,为了提高聚类的效率,首先对数据集D进行均匀采样得到D’,再在D’上进行细粒度聚类。
用m表示细粒度聚类中心的数量,用n表示粗粒度聚类中心的数量,n远小于m。
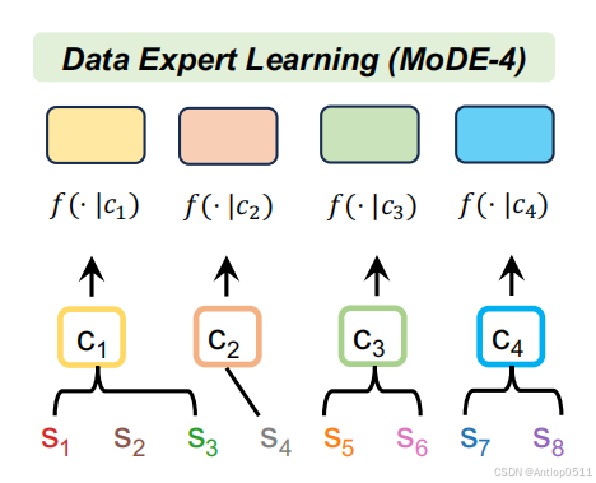
MoDE使用粗粒度聚类中心c作为各个数据专家的条件,Sc表示的是数据专家 f(·|c)对应的细粒度聚类中心的集合,比如下图中Sc1包含了S1,S2,S3,所有数据专家的Sc取并集便是整个细粒度聚类中心集合S。 可以看到下图中,训练数据首先通过聚类得到了一个个细粒度簇Sn,Sn又被聚类得到了粗粒度簇Cn。
Step1: Fine-grained Clustering
S←K-means(D′) D′~D and |D′| ≪ |D| m = |S|
Step 2: Coarse-grained Clustering
C←K-means(S)
c ∈ C is the condition for a data expert,
n = |C| as the number of data experts where n ≪ m,
Sc as set of fine-grained clusters assigned to data expert f(·|c) where S = ∪c∈CSc.
数据专家训练
Training Data:
每个数据专家的训练数据是这样的:
Ds = {d|s = arg mins∈S(∥ed − es∥ ) and d ∈ D}
Dc =∪s∈Sc Ds
d表示D中的数据,ed是d的嵌入,es是细粒度聚类中心的嵌入,对ed和es求欧几里得范数的平方,然后找最小值,这个公式用于从D中寻找嵌入向量与细粒度聚类中心s最接近的d,从而形成集合Ds。然后将Sc中所有s对应的Ds求并集,得到的Dc便是数据专家 f(·|c)的训练数据。
为了提高训练效率,所有的数据专家都从一个在D上部分训练了的种子clip模型中专门化,然后每个数据专家只在Dc上进行训练。
推理时任务适应
然后是推理时任务适应模块。最后的总输出是各数据专家结果的加权和,p(c|T)表示数据专家 f (·|c) 的归一化权重,T表示任务。
Output:
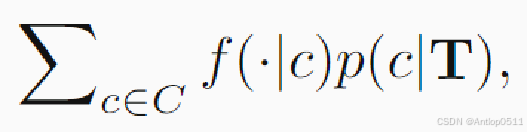
下面介绍权重是如何得到的,分成零样本分类和零样本检索两种情况。
1.Zero-Shot Classification
![]()
A ∈ R|L|×m
λ ∈ R+ is a temperature to sharpen the similarities
![]()
如上。对于零样本分类,L表示类别集合,el表示类别的嵌入,使用指数衰减函数来计算es和el的相似度,其中λ用来控制衰减的速率,得到的实数存放到矩阵A中,矩阵A的行数和列数由类别数量和细粒度聚类中心数量决定,这样就得到了所有类别和细粒度聚类中心之间的相似度。最后,每个数据专家的权重正比于矩阵A中该数据专家对应的细粒度聚类中心和所有类别的相似度的和。这样就实现了让更擅长对这些类别进行分类的数据专家的输出占更大比重的目的。
2.Zero-Shot Retrieval
零样本检索分成文本检索和图像检索。文本检索的任务是用图像从大型语料库Q中检索相关的文本,同样我们使用指数衰减函数求Q和S的相似度并存放到矩阵A中,权重就正比于对应的矩阵元素之和。
论文原文:For text retrieval where each image is used to retrieve a text from a large corpus Q, we leverage Q as metadata to build similarity matrix A ∈ R|Q|×m. Similar to the classification task, the weights for ensembling can be naturally adopted for MoDE:
![]()
对于图像检索,每个输入的文本q单独检索图像,矩阵A中是文本q和S的相似度,我们将文本 q 的检索视为独立的任务 Tq,集成权重如下。
论文原文:For image retrieval where each text q retrieves an image separately, we treat the retrieval by text q as an independent task Tq such that the ensembling weights are then
![]()
实验
训练设置
下方是预训练的一些设置。在聚类的时候使用的是预训练语言模型SimCSE来提取所有文本的嵌入,作者通过嵌入类型消融实验与其他模型和其他嵌入类型进行了比较,验证了使用simcse提取文本嵌入来进行聚类的效果最好。细粒度聚类中心m的数量设为1024,这是作者统计了细粒度聚类中心数量和准确率的关系,并作者衡量了训练成本和收益后选择的结果。超参数遵循了openaAI clip的超参数。预训练使用了4亿图像文本对进行32次迭代。使用了三种尺度的视觉transfomer作为图像编码器,B是base表示一个基础版本的模型,L是large表示一个更复杂的模型,数字表示的是模型使用的图像块大小,比如32代表32×32像素。选择了32次迭代中的第27次的meta clip作为种子模型。在评估方面,数据集是从mate clip中收集的,并分别在四亿和25亿两个尺度上进行了训练和评估。
聚类设置:We use the pre-trained language model SimCSE to extract the embeddings for all captions;We set the number of fine-grained clusters m = 1024.
超参数设置: We follow OpenAI CLIP’s hyper-parameters
训练规模:train on the same budget of 12.8B image-caption pairs (32 epochs of 400M), with a global batch size of 32,768
训练尺度:ViT-B/32,ViT-B/16 and ViT-L/14
种子模型:we start from a partially trained (27th out of 32 epoches) MetaCLIP as the seed model and all data experts share the same seed model
评估数据集:datasets collected in MetaCLIP
两个评估尺度:400M (similar to the scale in OpenAI CLIP), and 2.5B
零样本图像分类
这是在四亿样本上训练后得到的零样本分类准确率。分成这三个尺度,每个尺度都有三种clip和两种mode,-2和-4表示数据专家的数量。每一列表示在不同数据集上的结果,还有一个平均准确率。可以看到mode-2的平均准确率在三个尺度上都超过了clip,并且mode-4的准确率要更进一步。
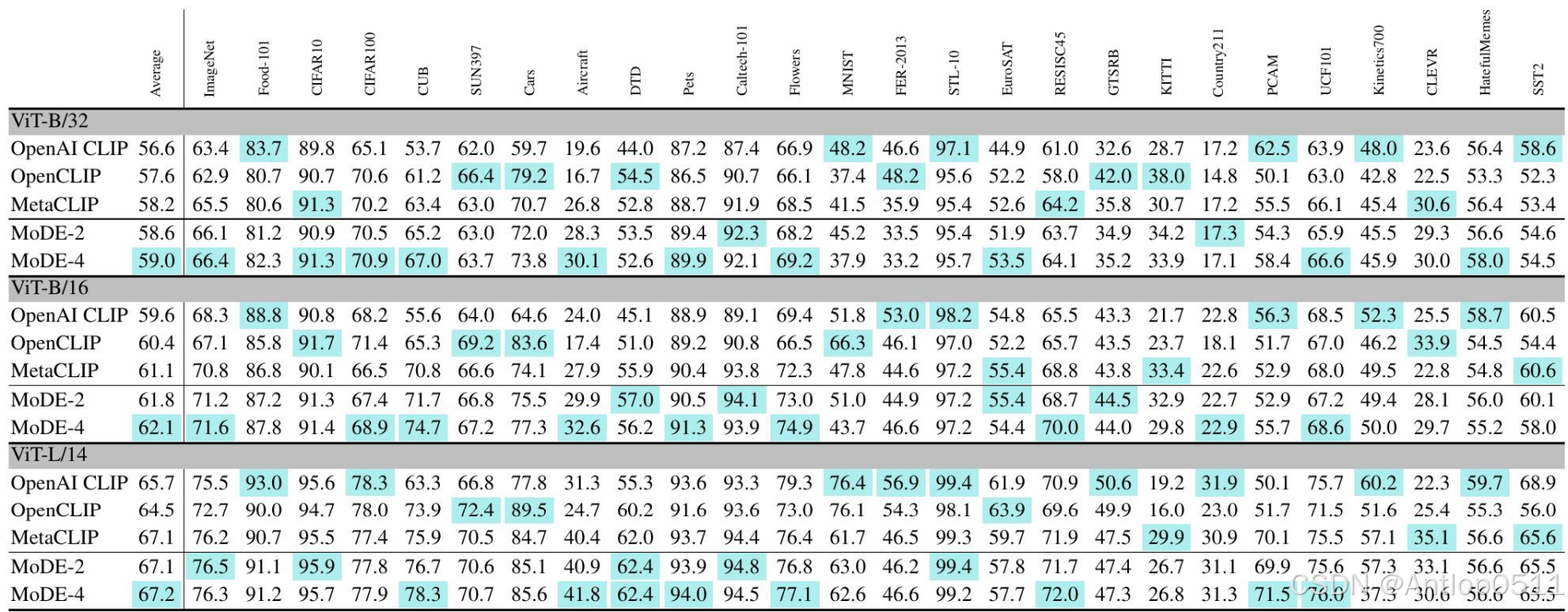
Table 1. Performance on CLIP benchmark by models trained on 400M image-caption pairs. MoDE-2 and MoDE-4 consistently outperform the MetaCLIP Baseline and MoDE-4 achieves the best score on average.
这是在十亿级的样本上训练的模型,这里面就没有openai clip的数据了,因为openai clip只有四亿级别的。可以看到mode的准确率同样超过了clip。
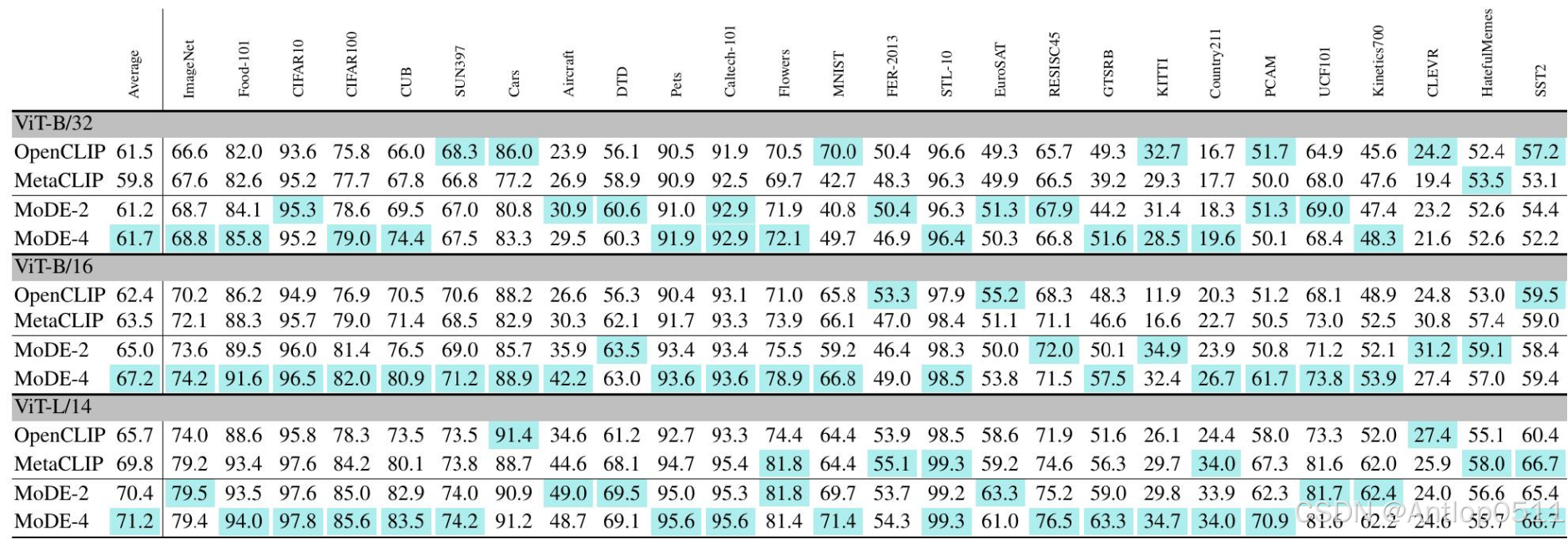
Table 2. Performance on CLIP benchmark by models trained on billion-scale dataset. MoDE-2 and MoDE-4 consistently outperform the MetaCLIP Baseline and MoDE-4 achieves the best score on average.
零样本检索
这是对零样本检索的评估,在coco和flicker30k两个数据集上进行了评价,左边是文本检索的召回率,右边是图像检索的召回率。可以看到在B/16尺度上mode-4取得了所有的最佳结果,在B/32尺度上mode也有不错的表现,mode在coco数据集上取得了所有的最佳结果。
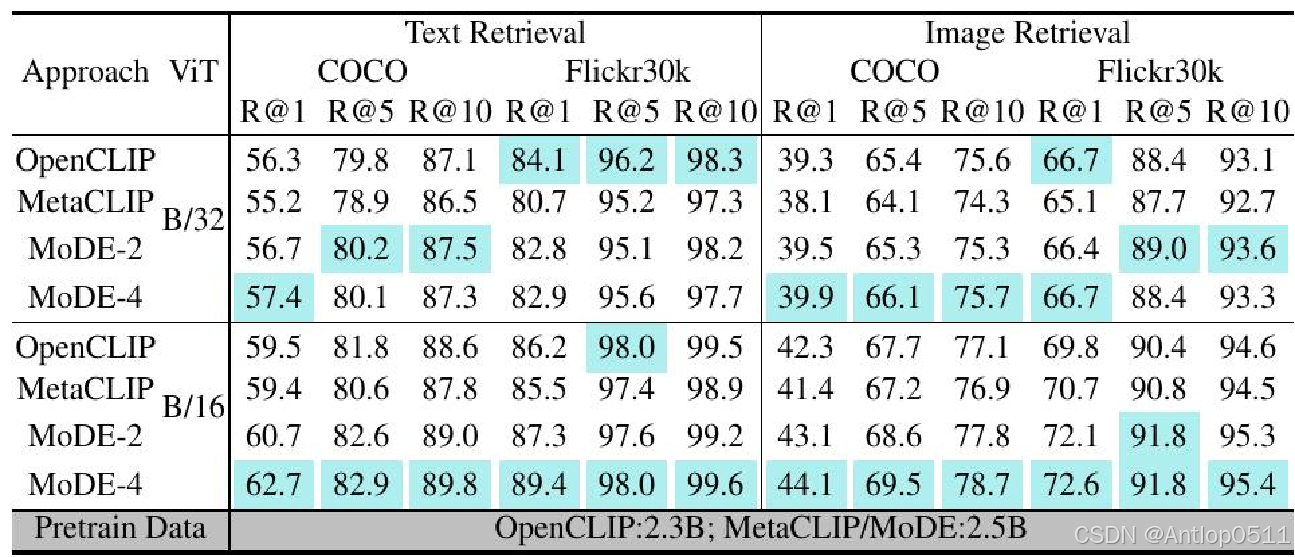
Table 4. Zero-shot Retrieval. Entries in blue are the best ones. Results by model trained on 400M pairs and by ViT-L/14 can be found in the Suppl.
消融实验
Effectiveness of Clustering
接下来是消融实验。这是对聚类有效性进行的研究。Full-2没有进行聚类,Random-2是将训练数据随机分成了两个子集,可以看到准确率是不如进行了完整的两步聚类的mode的。
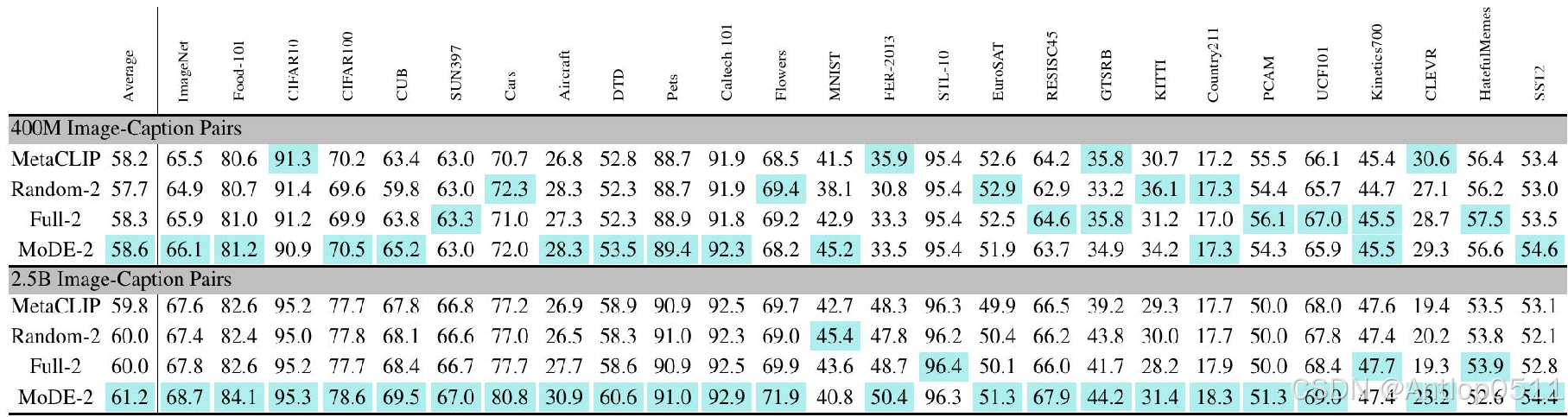
Table 5. Ablation Study for performance gain via Clustering by VIT-B/32.
Clustering Strategy
这是对聚类策略进行的研究。OneStep-2是只进行了单步聚类,CoarseCluster-2是使用粗粒度聚类中心来确定集成权重,同样准确率是不如完整的模型的。
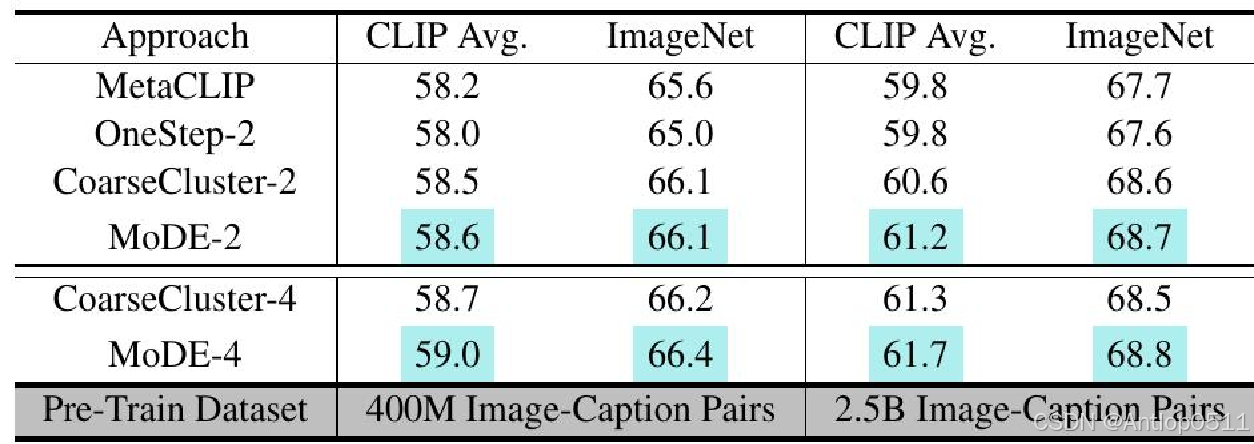
Table 6. Ablation study for Clustering Strategy by ViT-B/32.
MoDE-n
这是对数据专家数量进行的研究。
横轴是数据专家的数量,纵轴是准确率,可以看到准确率是随着数据专家的数量增加而提高的。要注意这里选择的基线是B/16的mate clip,而图中的点是B/32的mode,也就是说mode使用了更小的成本得到了更大的收益,而B/32的mate clip在这里,被同尺度的mode完全超越了。
increase the number of data experts
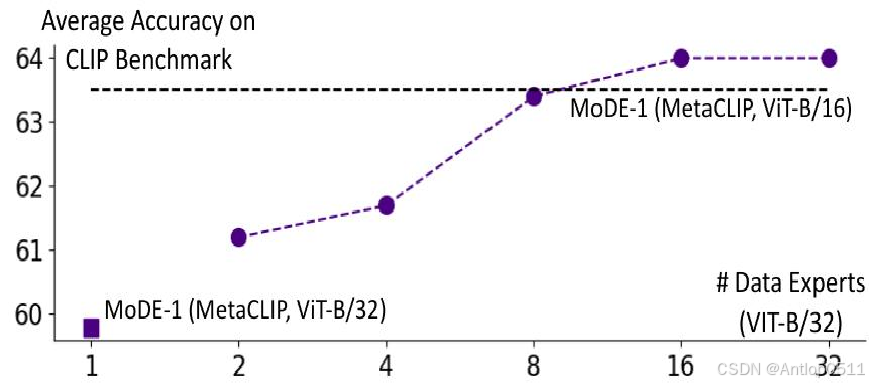
Figure 3. Average accuracy CLIP benchmark with increased number of data expert models in MoDE (Pretrain set: 2.5B pairs).
Training Priority of Data Experts
此图研究的是数据专家的异步训练,我们对数据专家的训练顺序进行了优先级排序,范围越大的数据专家优先级越高,因为它包括的细粒度聚类中心的多样性更高。横轴表示的是数据专家逐渐参与进来的过程,以mode-32这条紫色的线为例,当第二个数据专家参与进来时准确率有显著提升,后来折线逐渐平缓,可以证明排序的有效性。因为mode可以异步训练,当计算资源不足以训练一个完整的mode时,可以优先训练一部分数据专家。
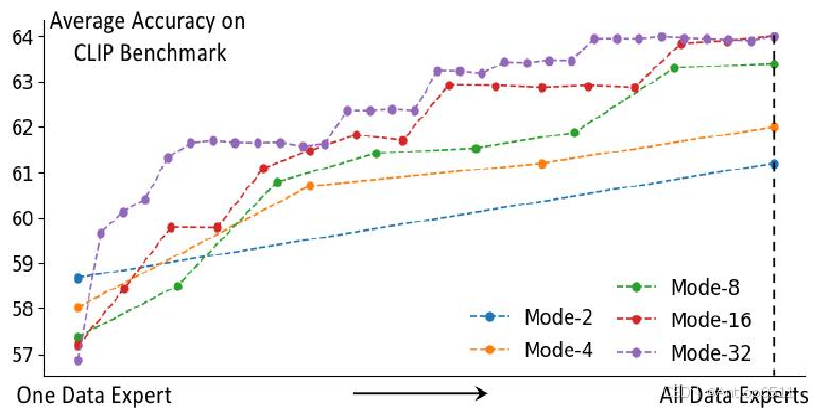
Figure 6. CLIP benchmark accuracy by MoDE-n when the data experts based on ViT-B/32 are developed in order and added to the system progressively. The pre-train set contains 2.5B pairs.
成本收益分析
最后是mode和clip的一个训练成本和收益的比较,不同颜色代表不同模型,圆圈直径代表模型的大小,横轴是训练用的时间,可以看出来紫色的mode规模小,训练时间少,且准确率高。
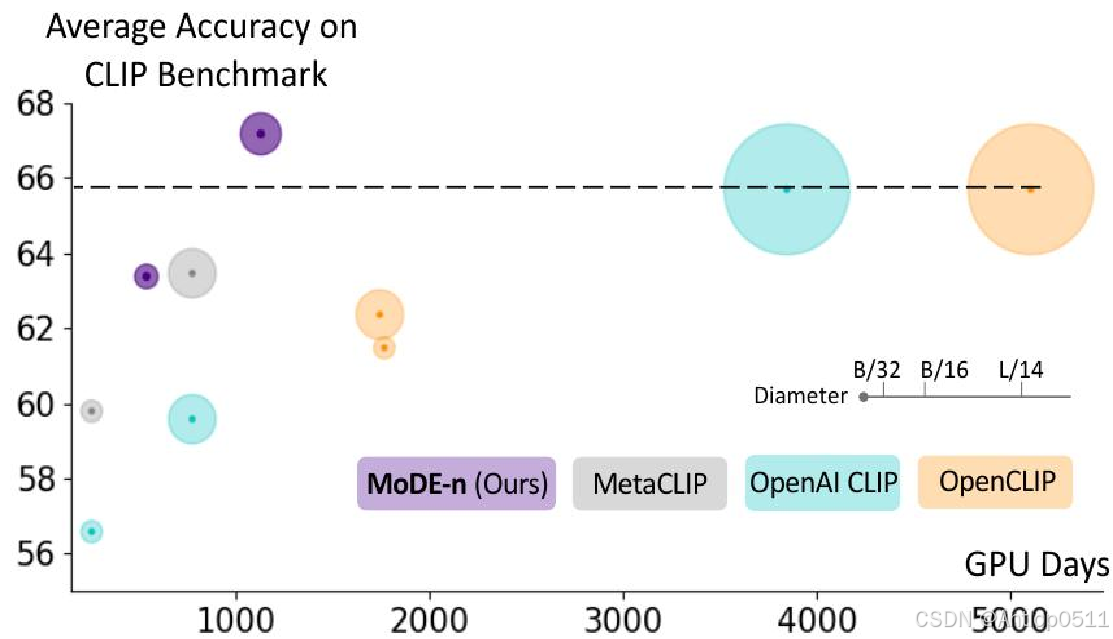
Figure 4. Summary of average accuracy on CLIP benchmark and pretraining cost (GPU-Hours). The diameter is proportional to the model size, different approaches are color-coded.
结论
·CLIP 的成功取决于负样本的质量。由于网络爬取的样本对中存在假阴性噪声,会影响训练效果,因此在大规模数据上扩展 CLIP 在训练效率和计算瓶颈方面带来了独特的挑战。
·为此,我们提出了数据专家混合模型 (MoDE) 来异步训练一组数据专家。每个专家模型都针对一组细粒度聚类进行训练,其中每个聚类中的数据具有连贯的语义,并且所有数据专家都单独进行训练。
·在推理过程中,根据每个任务的要求选择性地集成输出,并通过任务元数据与细粒度聚类中心之间的相关性进行建模。 ·实证表明,MoDE 在标准基准测试中显著优于 OpenCLIP 和 OpenAI CLIP,训练成本不到 30%。我们计划在未来将 MoDE 适应生成模型。

















 2477
2477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









