




 这篇博客详细介绍了如何在PyTorch中训练一个自定义的目标检测模型,特别是针对名为'MASK'的数据集。首先,你需要修改`config.py`文件以适应你的数据集,包括更改数据集路径、类别数等。然后,创建一个新的`mask.py`文件,基于VOC数据集的结构进行修改,以处理你的数据集。接着,注销默认的数据集引用,并在`data`模块的`init.py`中引入你的数据集。在`ssd.py`中,根据需要调整网络配置,尤其是类别数。训练函数`train.py`也进行了相应的修改,包括数据加载、损失计算等。在训练过程中,注意保存模型的频率以及可能出现的问题,如内存不足、损失为`NaN`等。通过这些步骤,你可以成功地训练一个针对自定义数据集的SSD模型。
这篇博客详细介绍了如何在PyTorch中训练一个自定义的目标检测模型,特别是针对名为'MASK'的数据集。首先,你需要修改`config.py`文件以适应你的数据集,包括更改数据集路径、类别数等。然后,创建一个新的`mask.py`文件,基于VOC数据集的结构进行修改,以处理你的数据集。接着,注销默认的数据集引用,并在`data`模块的`init.py`中引入你的数据集。在`ssd.py`中,根据需要调整网络配置,尤其是类别数。训练函数`train.py`也进行了相应的修改,包括数据加载、损失计算等。在训练过程中,注意保存模型的频率以及可能出现的问题,如内存不足、损失为`NaN`等。通过这些步骤,你可以成功地训练一个针对自定义数据集的SSD模型。
前文(创建数据集)
https://blog.youkuaiyun.com/abysswatcher1/article/details/113448508
打开之前下载的ssd-pytorch源代码,进行修改,下图是在VScode中的文件夹目录结构:
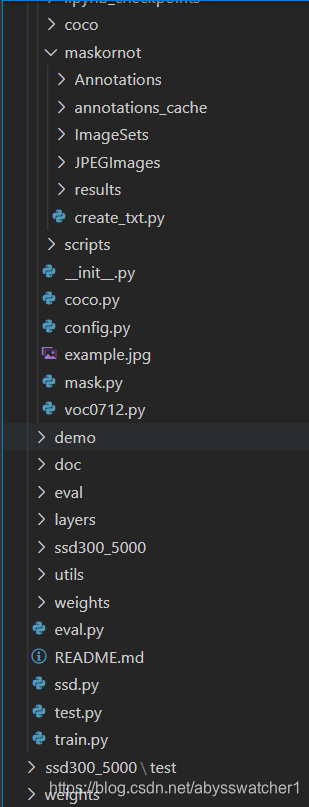 部分细节可能不一样,训练测试之后就会生成了。
部分细节可能不一样,训练测试之后就会生成了。
修改部分
1.读取自己的数据集
之前下载的预训练模型vgg16_reducedfc.pth要放在对应的文件夹下。
在config.py中
# config.py
import os.path
# gets home dir cross platform
#HOME = os.path.expanduser("~")
HOME = os.path.expanduser("C:/Users/25345/Desktop/pytorch_ssd-20200327T152054Z-001/pytorch_ssd/")
#这里要修改为自己的路径,一直到pytorch-ssd文件夹下即可。
# for making bounding boxes pretty
COLORS = ((255, 0, 0, 128), (0, 255, 0, 128), (0, 0, 255, 128),
(0, 255, 255, 128), (255, 0, 255, 128), (255, 255, 0, 128))
MEANS = (104, 117, 123)
mask = {
'num_classes': 3,#数据集类别数量
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,#最大迭代次数
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'MASK',
}
# SSD300 CONFIGS
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
coco = {
'num_classes': 201,
'lr_steps': (280000, 360000, 400000),
'max_iter': 400000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [21, 45, 99, 153, 207, 261],
'max_sizes': [45, 99, 153, 207, 261, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'COCO',
}
mask是新加入的自己的数据集,其中num_classes的值应该为你数据集中的标签种类+1,例如我的数据集中有orange和noorange两类,所以值为3.
在修改HOME路径的过程中,如果你是直接从文件夹中复制的,使用的是 \ ,并且恰好你的用户名以数字开头,这里会把识别为转义符作用在第一个数字上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8042
8042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









