




 本文详细介绍了二分查找算法的基本概念、特点及其实现过程。二分查找是一种高效的搜索算法,适用于有序且无重复元素的列表,通过不断将查找区间对半分割来快速定位目标元素。文章还分析了算法的优缺点,以及在实际应用中的表现。
本文详细介绍了二分查找算法的基本概念、特点及其实现过程。二分查找是一种高效的搜索算法,适用于有序且无重复元素的列表,通过不断将查找区间对半分割来快速定位目标元素。文章还分析了算法的优缺点,以及在实际应用中的表现。
python:二分查找
1、什么是二分查找?
所谓二分查找就是在一个有序并且无重复的列表中,对该列表的元素进行查找。假如我的列表是升序排列(即从小到大),那么查找的方式就为:将所有元素对半切开查找,也就是说从中间开始查找。如果中间的这个元素大于目标元素,则往前挨个查找,因为前边的是小的,那如果小于目标元素,则往后挨个查找,因为后边的都是大的。
2、特点
(1)必须针对于有序列表
(2)该列表必须无重复
(3)按下标索引查找
3、算法源码
def find(mylist,targer):
"""
:param mylist: 有序并且无重复的列表
:param targer: 目标数字
:return: 返回找到的元素
"""
# 先拿出索引,left表示第一个索引,right表示最后一个索引
left ,right = 0, len(mylist)-1
# 查找的范围为索引范围内
while left <= right:
# 每次都获取中间位置的索引
index = (left + right) // 2
# 通过索引获得元素
result = mylist[index]
# 如果相等
if result == targer:
# 那么将返回这个元素
return result
# 如果所找到的元素小于目标数字
elif result < targer:
# 那么从0开始的索引就+1,这里我们不能在最后+1,因为很可能出现索引超出界限的异常
left += 1
# 如果所找到的元素大于目标数字,则最后的索引-1。如果从索引为0的开始减的话,那么元素右-1嘛?很明显没有
else:
right -= 1
# 如果到最后查找完,没有在列表中找见,则返回None
return None
if __name__ == '__main__':
# 使用列表推导式创建列表
mylist = [i for i in range(50)]
# 目标数字
target = 36
# 调用函数并返回一个值
result = find(mylist,target)
# 输出该值
print(result)
4、分析图
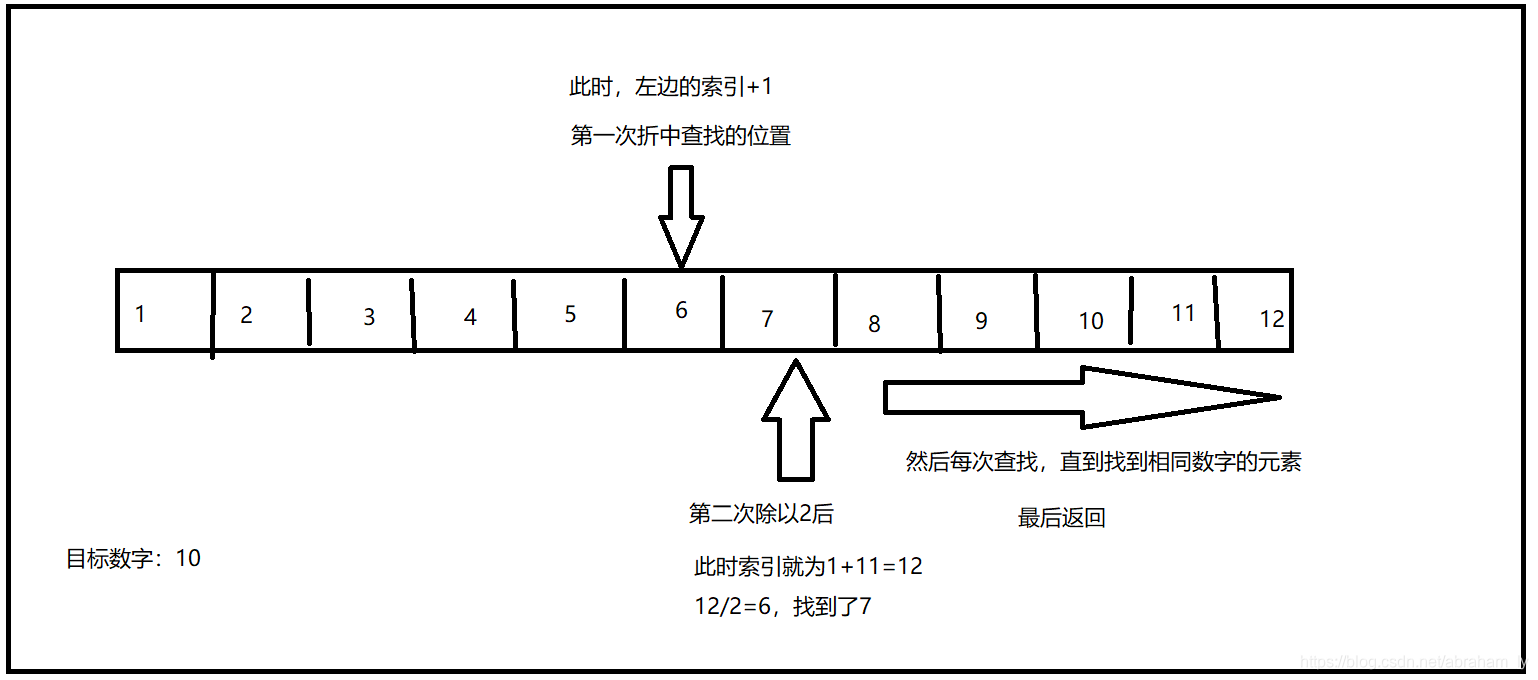
5、总结
从理论上讲,二分查找法比顺序查找效率能稍微高出一半,但对于靠前的元素,比如1、2那么它这个效率就没有顺序查找的效率高,并且二分查找有一个缺点,就是每次与目标数字不匹配,那么都要+1,此时就出现了奇偶数的问题。比如偶数字10// 2 = 5,那么就是找到下标索引为5的元素,但是如果是奇数 11 // 2 =5,此时就出现了除不尽的问题,那么也就是说如果遇到奇数它有在循环里白循环了一次,所以循环的次数就多了,这就是二分法的缺点所在。
以上均为自己在学习和实践过程中做出的总结,发现该算法程序与书中的说明不吻合,有很大的出入,所以特地摘出来与大家分享,如果本篇文章有描述不正确的地方,还请给位码友速速指出,谢谢!


















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











