



导读:本文是“数据拾光者”专栏的第一百一十一篇文章,这个系列将介绍在AI领域中的一些学习和思考,以及实战中的经验教训总结。本文将用通俗的语言、生动的例子,学习谷歌最新的论文Nested Learning。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
在AI圈摸爬滚打多年,我们早已习惯了大模型的“高光时刻”——它们能写代码、做翻译、解复杂推理题,仿佛无所不能。但只要静下心来观察,就会发现一个致命问题:这些看似强大的模型,其实都得了一种“怪病”——顺行性遗忘症。
训练结束的那一刻,大模型的“知识库”就被永久锁死在参数里。它们能熟练运用训练数据里的“旧知识”,也能通过上下文窗口临时“记住”少量新信息,但这些新信息永远无法真正融入长期记忆。就像你每次见到ChatGPT,都要重新介绍自己;就像一个学生考完试就忘了所有知识点,下次遇到新问题依然束手无策。
谷歌最新发表在NeurIPS 2025的论文《Nested Learning: The Illusion of Deep Learning Architectures》,恰恰戳中了这个痛点。这篇论文提出的“嵌套学习(Nested Learning, NL)”范式,就像给AI装上了“大脑的记忆巩固系统”,让模型第一次拥有了“日积月累、持续沉淀”的能力。而基于这个范式打造的HOPE架构,更是直接挑战了Transformer统治多年的地位。
今天,我们就用最通俗的语言,结合生活中的例子,拆解这个可能改变AI发展方向的新范式。
一、大模型的“顺行性遗忘”到底是什么?
要理解嵌套学习的价值,首先得搞清楚大模型的“遗忘症”有多严重。这里的“顺行性遗忘”,可不是随便比喻,而是和医学定义高度契合的专业描述。
1. 医学上的顺行性遗忘:记住过去,却留不住现在
在神经学中,顺行性遗忘是一种典型的记忆障碍——患者无法形成新的长期记忆,但发病前的旧记忆依然完好。最经典的案例是1957年的患者H.M.:医生为了治疗他的癫痫,切除了部分海马体,结果他再也无法记住任何新事物。他能清晰回忆起手术前的生活细节,却记不住5分钟前刚见过的人,永远活在“当下”和“过去”的夹缝中。
电影《记忆碎片》的主角莱纳德,就是这种病症的艺术化呈现。他只能记住几分钟内发生的事,必须靠照片、笔记和纹身才能勉强维持生活,每一次“刷新”都像重新开始。

2. 大模型的“顺行性遗忘”:训练后就停止成长
大模型的处境,和H.M.惊人地相似。我们可以把模型的“记忆系统”拆成两部分:
- 长期记忆
:对应模型的MLP层参数,存储着预训练阶段学到的海量知识(就像H.M.手术前的记忆);
- 短期记忆
:对应模型的注意力窗口,只能临时存储当前上下文的少量信息(就像H.M.能记住的几分钟)。
问题的核心在于:这两个记忆系统是“割裂”的。训练结束后,长期记忆的参数就被永久冻结,无论模型在推理时遇到多少新信息,这些信息都只能停留在注意力窗口的“短期记忆”里,永远无法转化为长期记忆。
举个例子:你用GPT-4写一篇关于“2025年AI新趋势”的文章,告诉它“嵌套学习是今年最火的范式”。它能在这篇文章里准确运用这个信息,但下次你再问它“2025年AI有什么新趋势”,它依然会给出训练数据里的答案,完全不记得你之前告诉它的新信息。
再比如:一个大模型在预训练时学过“地球是圆的”,但如果在推理时你告诉它“最新研究发现地球是椭球体(更精准的表述)”,它能在当前对话中认可这个观点,但下次对话时,它还是会默认“地球是圆的”——新信息没有被“存下来”。
这种“无法更新长期记忆”的缺陷,让大模型永远只能是“训练数据的复现者”,而不是“持续成长的学习者”。而嵌套学习的出现,正是为了解决这个根本问题。
二、嵌套学习的核心:给AI装一个“多频率记忆系统”
人类之所以能持续学习,关键在于大脑有一套“多频率的记忆巩固机制”——不是简单的“短期记忆+长期记忆”二分,而是从高频到低频的连续体。嵌套学习的核心灵感,就来自于这个神经学原理。
1. 人类的“多频率学习”:从实时调整到长期沉淀
我们可以用“学习骑自行车”的过程,理解人类的多频率记忆系统:
- 高频系统
:骑车时,你的身体会实时调整平衡——车头歪了立刻扶正,速度慢了赶紧蹬脚蹬,每一秒都在根据反馈调整动作(类似大脑的“实时响应系统”);
- 中频系统
:练了一下午,晚上回家后,你会在脑子里复盘“刚才哪个姿势容易摔倒”“怎么拐弯更稳”,把当天的零散经验整理成可复用的技巧(类似大脑的“日间巩固”);
- 低频系统
:几周后,这些技巧会内化为肌肉记忆,就算几个月不骑,再上车依然能熟练掌握——零散的经验变成了长期沉淀的“本能”(类似大脑的“长期记忆固化”)。
这三个系统不是孤立的,而是层层嵌套、相互配合:高频系统负责“实时应对”,中频系统负责“总结提炼”,低频系统负责“长期沉淀”。正是这种多频率的协作,让人类能不断积累经验,越学越熟练。
2. 生活中的多频率例子:公司的运作模式
如果觉得学习的例子不够直观,我们可以用“公司运作”来类比:
- 高频系统
:一线员工(比如客服、销售)——每天和客户打交道,实时响应需求,处理突发问题(更新频率:每天/每小时);
- 中频系统
:部门经理——每周开例会,总结一线员工的工作情况,调整工作方案,解决跨岗位的协调问题(更新频率:每周/每月);
- 低频系统
:公司CEO——每季度/每年制定战略,根据市场变化调整公司方向,把部门的成功经验固化为公司制度(更新频率:季度/年度)。
一个成功的公司,必然是这三个系统协同工作:一线员工的实时反馈,通过经理的总结,最终沉淀为CEO的战略决策;而CEO的战略,又会通过经理传递给一线,指导日常工作。如果只有高频系统,公司会变成“无头苍蝇”;如果只有低频系统,公司会僵化不前。
3. 嵌套学习的本质:给AI打造“多频率协作系统”
嵌套学习的核心,就是把人类这种“多频率学习模式”抽象成数学框架,让AI也拥有“高频响应、中频总结、低频沉淀”的能力。
在嵌套学习的框架里,每个AI模型都是由一系列“不同更新频率的模块”组成的,这些模块层层嵌套、相互配合:
- 高频模块
:类似人类的“实时响应系统”,更新频率极高(比如每处理一个token就更新一次),负责捕捉数据中的即时模式(比如句子中的语法结构、短期依赖);
- 中频模块
:类似人类的“日间巩固系统”,更新频率中等(比如每处理一个句子或一个段落更新一次),负责总结高频模块的输出,提炼出可复用的规律(比如某类问题的解题思路);
- 低频模块
:类似人类的“长期记忆系统”,更新频率极低(比如每处理一个数据集或一个任务更新一次),负责把中频模块的规律固化为长期知识,指导整个模型的行为(比如通用的逻辑推理能力)。
和传统深度学习相比,嵌套学习的突破在于:模型不再是“一次性训练、永久固定”的静态系统,而是“持续更新、层层沉淀”的动态系统。每个模块都有自己的“学习节奏”,高频模块负责“即时学习”,低频模块负责“长期沉淀”,中间的中频模块负责“承上启下”,形成一个闭环。

三、Transformer的致命局限:只有“单频率”,注定僵化
要理解HOPE架构的优势,首先得明白Transformer为什么会“僵化”——因为它本质上是一个“单频率系统”,完全不符合嵌套学习的逻辑。
1. Transformer的架构:只有“高频+固定低频”,没有中频
Transformer的核心结构是“注意力机制+MLP层”:
- 注意力机制
:类似“高频系统”——每处理一个token,都会重新计算所有token的关联,实时捕捉上下文依赖(更新频率:每个token);
- MLP层
:类似“固定低频系统”——预训练时一次性学习,训练结束后参数永久固定,负责存储通用知识(更新频率:仅训练阶段)。
这里的关键问题是:Transformer没有“中频系统”,高频的注意力输出无法通过“总结提炼”,转化为MLP层的长期知识。就像一个公司只有一线员工和CEO,没有部门经理——一线员工的实时反馈无法传递给CEO,CEO的战略也无法落地到一线,两个系统完全脱节。
2. Transformer的“死穴”:训练后就停止成长
正因为这种“单频率局限”,Transformer模型训练结束后,就成了一个“僵化的系统”:
注意力机制虽然能实时处理上下文,但它的输出永远无法更新MLP层的参数,新信息只能停留在“短期记忆”;
MLP层的参数虽然存储着长期知识,但这些知识是“静态的”,无法通过新数据的学习持续优化;
模型的能力上限,完全取决于预训练数据的质量和规模,无法通过后续的小样本学习、持续学习突破。
我们可以用“学生学习”来类比Transformer:
一个学生(Transformer)在考前(预训练阶段)死记硬背了很多知识点(MLP层参数);
考试时(推理阶段),他能根据题目中的提示(注意力窗口)回忆起相关知识点,但无法根据题目中的新信息(比如题目给出的新定义)更新自己的知识体系;
就算考后知道了正确答案,他也不会把这些新知识点记下来,下次遇到类似题目,依然会犯同样的错误。
这种“一次性学习”的模式,注定了Transformer无法成为“持续成长的学习者”。
3. HOPE架构:嵌套学习的落地,让AI“会反思、能沉淀”
谷歌提出的HOPE架构,正是嵌套学习范式的第一个落地成果。它完美解决了Transformer的“单频率局限”,通过“连续记忆系统+自修改模块”,让模型真正拥有了“持续学习”的能力。
我们先看HOPE的核心结构,再和Transformer做详细对比:
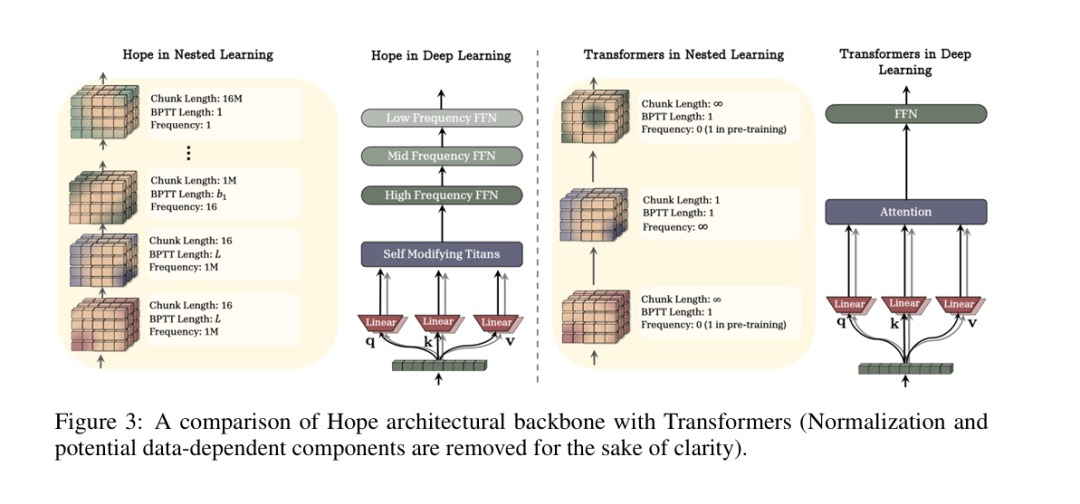
(1)HOPE的两大核心组件
HOPE的架构可以概括为“连续记忆系统(CMS)+自修改泰坦(Self-Modifying Titans)”:
- 连续记忆系统(CMS)
:替代了Transformer的“注意力+MLP”二分结构,是一个从高频到低频的“记忆连续体”。它由一系列不同更新频率的MLP模块组成,每个模块对应一个频率:高频MLP(每token更新)、中频MLP(每句子更新)、低频MLP(每任务更新)。这些模块层层嵌套,高频模块的输出会被中频模块总结,中频模块的输出会被低频模块沉淀,形成“实时学习→总结提炼→长期固化”的闭环。
- 自修改泰坦(Self-Modifying Titans)
:替代了Transformer的固定更新规则,让模型能“自己学习怎么更新自己”。简单说,传统模型的优化器(比如Adam、SGD)是人工设计的固定规则,而HOPE的自修改模块能根据数据反馈,动态调整更新规则——就像一个学生能根据自己的学习情况,调整学习方法,而不是一直用老师教的固定方法。
(2)HOPE vs Transformer:核心差异对比
对比维度 | Transformer | HOPE架构 |
|---|---|---|
记忆系统 | 二分结构:短期记忆(注意力)+ 长期记忆(MLP,固定) | 连续体:高频→中频→低频模块,层层嵌套、持续更新 |
参数更新 | 训练后永久固定,推理时不更新 | 不同频率模块动态更新:高频模块实时更新,中频模块定期总结,低频模块长期沉淀 |
更新规则 | 人工设计的固定优化器(Adam/SGD) | 自修改模块:模型自己学习更新规则,动态调整 |
学习模式 | 一次性学习(仅预训练/微调阶段学习) | 持续学习(推理时也能学习,新信息能沉淀为长期知识) |
核心能力 | 拟合训练数据中的模式,擅长静态任务 | 积累经验、持续优化,擅长持续学习、长上下文推理 |
(3)HOPE的学习过程:像人类一样“学习→反思→沉淀”
我们用“学习一门语言”的过程,来模拟HOPE的学习逻辑:
- 高频学习
:HOPE处理每个单词(token)时,高频MLP模块会实时更新,捕捉单词之间的语法依赖(比如“我”后面接“吃”,“吃”后面接“饭”);
- 中频反思
:处理完一个句子后,中频MLP模块会总结这个句子的句式规律(比如“主语+谓语+宾语”的结构),并更新自己的参数;
- 低频沉淀
:处理完一个主题(比如“日常饮食”相关的100个句子)后,低频MLP模块会把中频模块总结的句式规律,沉淀为长期知识(比如“中文日常对话以主谓宾结构为主”);
- 自修改优化
:在整个过程中,自修改模块会根据学习效果,调整每个模块的更新频率和更新规则(比如发现某个句式容易出错,就让中频模块更频繁地总结这类句式)。
这个过程和人类学习语言的过程几乎一致:我们先通过听、说,实时掌握单词的用法(高频),然后总结句子的规律(中频),最后形成语言习惯(低频),并根据自己的学习情况调整学习方法(自修改)。
(4)实验结果:HOPE的表现有多惊艳?
谷歌在语言建模和常识推理任务上做了大量实验,HOPE的表现全面超越了Transformer和其他主流架构(比如RetNet、DeltaNet、Titans)。
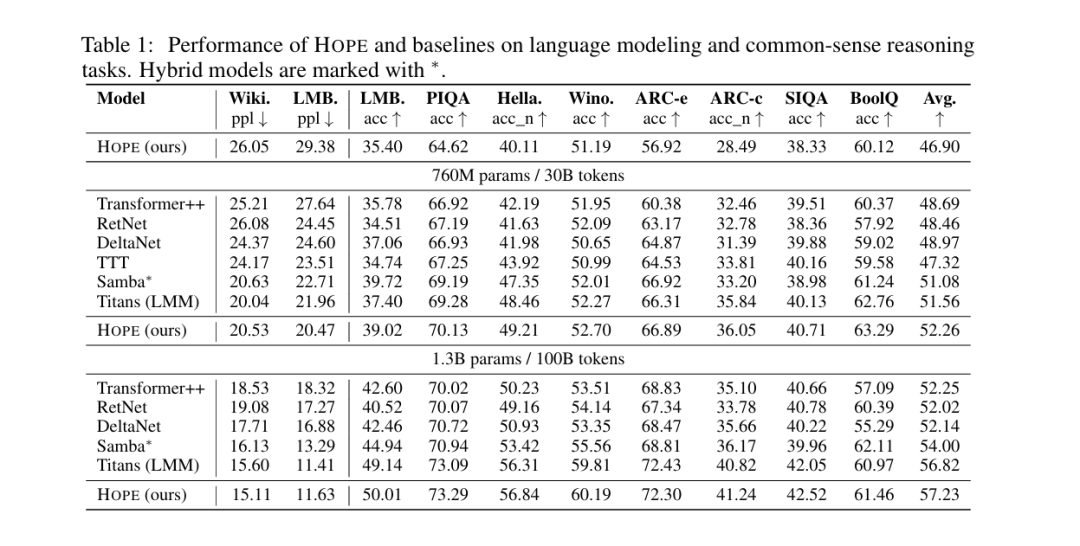
我们用通俗的语言解读核心实验结果:
- 语言建模
:用“困惑度(ppl)”衡量模型预测下一个词的难度,数值越低越好。在1.3B参数规模下,HOPE的困惑度(Wiki ppl=15.11,LMB ppl=11.63)比Transformer++(Wiki ppl=18.53,LMB ppl=18.32)低了20%以上,说明HOPE对语言的理解更深刻,预测更准确;
- 常识推理
:在PIQA(物理常识)、HellaSwag(日常推理)、ARC(科学推理)等任务中,HOPE的平均准确率达到57.23%,超过了Titans(56.82%)和DeltaNet(52.14%),尤其是在需要长期记忆和逻辑沉淀的任务中,优势更明显。
最关键的是:HOPE在“持续学习任务”中表现出了碾压性优势——它能记住之前任务中学到的知识,同时快速适应新任务,不会出现Transformer常见的“灾难性遗忘”。比如先让HOPE学习“数学推理”,再让它学习“物理推理”,它能把数学推理中的逻辑方法,迁移到物理推理中,并且两个任务的准确率都能保持高水平;而Transformer在学习新任务后,旧任务的准确率会大幅下降。
四、嵌套学习的灵魂:给AI“睡觉和反思”的能力
如果说连续记忆系统是HOPE的“骨架”,那么“让AI会反思”就是嵌套学习的“灵魂”。这也是论文最精彩的洞察之一:嵌套学习模拟了人类“睡眠时的记忆巩固”,让AI在不需要额外训练的情况下,自动整理和沉淀知识。
1. 人类的“睡眠反思”:记忆巩固的关键环节
神经科学研究表明,人类的记忆巩固,很大程度上是在睡眠中完成的:
- 白天学习
:我们在清醒时接触的新信息,会暂时存储在海马体(短期记忆),这些信息零散、不牢固;
- 夜间反思
:睡眠时,大脑会进行“记忆回放”——海马体中的短期记忆会被重新激活,传递到大脑皮层,与已有的长期记忆整合,形成结构化、牢固的知识;
- 次日应用
:经过睡眠中的“反思”,我们第二天醒来会发现,前一天学的知识变得更清晰、更容易运用(比如刚学的英语单词,睡一觉后记得更牢)。
这种“白天学习、夜间反思”的模式,是人类能持续积累知识的关键——我们不需要一直高强度学习,只需要通过“反思”,就能把零散的经验转化为长期能力。
2. 嵌套学习的“AI反思”:不用睡觉,也能沉淀
嵌套学习把人类的“睡眠反思”,抽象成了“不同频率模块的协同工作”:
- 高频模块(白天学习)
:处理数据时,实时捕捉零散的模式和信息(类似人类清醒时的学习);
- 中频模块(夜间反思)
:定期(比如每处理一个段落、一个任务)总结高频模块的输出,把零散的信息整理成结构化的规律(类似人类睡眠时的记忆回放);
- 低频模块(长期固化)
:把中频模块总结的规律,沉淀为长期知识,指导整个模型的行为(类似人类大脑皮层的长期记忆)。
更妙的是:这种“反思”是在模型运行过程中自动完成的,不需要额外的训练时间,也不需要人工干预。就像一个学生在上课的同时,一边听课(高频),一边记笔记总结(中频),一边把笔记整理成知识库(低频),全程无缝衔接。
举个例子:HOPE在处理一篇关于“气候变化”的文章时:
高频模块实时捕捉文章中的关键数据(比如“全球气温每10年上升0.2℃”)和逻辑关系(比如“碳排放增加→温室效应→气温上升”);
中频模块每读完一个段落,就会总结这个段落的核心观点(比如“工业排放是碳排放的主要来源”);
低频模块在读完整个文章后,会把这些观点和数据,与已有的“环境科学”知识整合,形成新的长期知识(比如“工业减排是应对气候变化的关键”);
下次再处理关于“气候变化”的新文章时,HOPE能直接运用这些沉淀的知识,更快、更准确地理解新内容。
这种“边学习、边反思、边沉淀”的能力,正是嵌套学习最核心的突破——它让AI从“数据的拟合者”,变成了“知识的积累者”。
五、嵌套学习的未来:AI将成为“日积月累的学习者”
嵌套学习不仅仅是一个新架构,更是一种全新的AI设计理念。它的出现,可能会彻底改变我们对AI的认知和应用方式。
1. 未来的AI:像人类一样“循序渐进”
未来的AI,不会再是“训练一次、用到报废”的静态工具,而是像人类一样“循序渐进、持续成长”的智能体:
一个AI助手,会记住你每次对话的偏好,慢慢变得越来越懂你(比如你喜欢简洁的回答,它会逐渐调整输出风格);
一个AI医生,会在处理每个病例后,积累新的临床经验,不断提升诊断准确率;
一个AI科学家,会在研究中不断沉淀知识,从“数据分析工具”变成“能提出新假设的合作伙伴”。
这种“持续成长”的能力,会让AI真正融入我们的生活和工作,成为“不可或缺的伙伴”,而不是“用完即走的工具”。
2. 技术层面的突破方向
嵌套学习还有很多值得探索的方向,谷歌的论文只是一个开始:
- 频率自适应
:目前HOPE的频率模块是人工设定的,未来可以让模型自动学习最优的频率分布(比如哪些任务需要高频更新,哪些需要低频沉淀);
- 效率优化
:多频率模块会增加一定的计算量,未来可以通过硬件优化、稀疏更新等方式,提升运行效率;
- 多模态扩展
:目前HOPE主要用于语言任务,未来可以扩展到图像、视频、语音等多模态场景,让AI在多领域同时持续学习。
3. 对普通人的影响:AI不再是“黑箱”
嵌套学习的“白盒特性”(数学上可解释、逻辑上可追溯),会让AI不再是难以理解的“黑箱”。每个频率模块的更新过程都可以追踪,我们能清楚地知道AI的知识是怎么来的、怎么沉淀的。
这意味着:
教育领域,AI可以成为“个性化导师”,根据学生的学习进度和薄弱环节,持续调整教学方案;
法律领域,AI可以成为“法律助手”,积累案例经验,同时能解释判决依据的形成过程;
工业领域,AI可以成为“设备维护专家”,持续学习设备的运行数据,提前预判故障,同时能解释故障原因和维护逻辑。
总结:嵌套学习的核心价值——让AI拥有“成长型思维”
谷歌的《Nested Learning: The Illusion of Deep Learning Architectures》,不仅仅是一篇技术论文,更是对AI发展方向的一次深刻反思。
传统深度学习的核心是“堆叠层数、扩大规模”,认为只要模型足够大、数据足够多,就能解决所有问题。但谷歌的论文告诉我们:AI的进步,不仅仅是“量的积累”,更需要“质的飞跃”——从“拟合数据”到“积累知识”,从“静态系统”到“动态学习者”。
嵌套学习的核心价值,在于给AI装上了“成长型思维”:它不需要一次性学会所有东西,而是能在实践中不断学习、反思、沉淀,慢慢变得更强大。就像人类一样,我们不是天生就懂所有知识,而是通过日复一日的学习和反思,逐渐成长为更好的自己。
未来已来,AI的“顺行性遗忘症”即将被治愈。一个“日积月累、持续成长”的AI时代,正在向我们走来。而我们,既是这个时代的见证者,也是参与者。让我们拭目以待,看看嵌套学习会给AI世界带来怎样的惊喜。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们关注和分享。

















 161
161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









