




需要系统程序源码的小伙伴,可以私信博主获取
基于PyTorch+Seq2Seq+LSTM/GRU+注意力机制的智能聊天系统设计与实现综述
随着人工智能技术的快速发展,智能聊天系统作为人机交互的重要工具,正逐渐渗透到人们的日常生活中。智能聊天系统通过模拟人类的对话行为,为用户提供便捷的信息查询、任务执行和情感交流等服务。为了构建高效、智能的聊天系统,深度学习技术,特别是基于Seq2Seq、LSTM/GRU和注意力机制的模型,成为了当前研究的热点。本文将对基于PyTorch的Seq2Seq模型、LSTM/GRU网络和注意力机制在智能聊天系统中的应用进行综述。
一、Seq2Seq模型在聊天系统中的应用
Seq2Seq模型是一种经典的序列到序列的模型,由编码器和解码器两部分组成。在智能聊天系统中,Seq2Seq模型用于将用户的输入语句转化为系统的响应语句。编码器将用户的输入语句编码成一个固定长度的向量表示,解码器则根据这个向量表示生成系统的响应语句。通过训练Seq2Seq模型,可以使其学习到从输入语句到响应语句的映射关系,从而实现自动的对话生成。
二、LSTM/GRU网络在聊天系统中的应用
LSTM(长短时记忆网络)和GRU(门控循环单元)是两种常用的循环神经网络(RNN)结构,它们能够有效处理序列数据中的长期依赖问题。在智能聊天系统中,LSTM/GRU网络通常作为Seq2Seq模型的编码器和解码器的实现方式。通过引入门控机制,LSTM/GRU网络能够选择性地保留和遗忘序列中的信息,从而更好地捕捉对话中的上下文信息。这使得系统能够更准确地理解用户的意图,并生成更符合语境的响应。
三、注意力机制在聊天系统中的应用
注意力机制是一种模拟人类视觉注意力分配机制的技术,它可以帮助模型在处理序列数据时关注重要的部分。在智能聊天系统中,注意力机制通常用于改进Seq2Seq模型的性能。通过在解码过程中引入注意力机制,模型可以在生成响应时根据输入语句的不同部分分配不同的注意力权重。这样,模型能够更加关注与用户意图相关的关键信息,从而生成更加准确和有针对性的响应。
基于PyTorch的实现方面,PyTorch提供了丰富的工具和库,使得构建和训练基于Seq2Seq、LSTM/GRU和注意力机制的模型变得相对简单和高效。通过利用PyTorch的自动微分功能、GPU加速以及并行计算能力,可以加速模型的训练过程,并提高模型的性能。
四、总结与展望
基于PyTorch的Seq2Seq模型、LSTM/GRU网络和注意力机制在智能聊天系统中展现了强大的应用潜力。通过构建合适的模型结构、选择适当的优化算法和损失函数,以及利用PyTorch提供的强大工具进行模型训练和调优,可以实现高效、智能的聊天系统。然而,当前的研究仍面临一些挑战,如如何进一步提高模型的对话质量、如何处理多轮对话中的上下文信息以及如何实现跨领域的对话生成等。未来,我们将继续深入研究这些问题,探索更多的深度学习技术和方法在智能聊天系统中的应用,以提供更加自然、智能和个性化的对话体验。
部署与技术讲解
环境
python 3.6
pytorch 0.4
其他python库
语料
本项目语料使用了20万句电影对话语料,去除低频词汇、过长句子后剩余约14万句,构建词典大小13000词。 训练此模型,首先在main_train.py中指定你的语料路径。并且,语料格式须满足:每个句子占一行,每两行为一个对话语句对。如:
Nice to meet you.
Nice to meet you, too.
I am sorry.
You are welcome.
预处理
删除过长句子
删除包括低频词汇的句子
句子小写,标点分离
生成字典,训练语句对
模型
基于sequence to sequence模型,项目分别实现了LSTM和GRU的模型构建,并实现了注意力机制。通过main_train.py指定相关参数选择使用LSTM或GRU,以及是否使用注意力机制。 本项目中训练的模型结构如下所示:
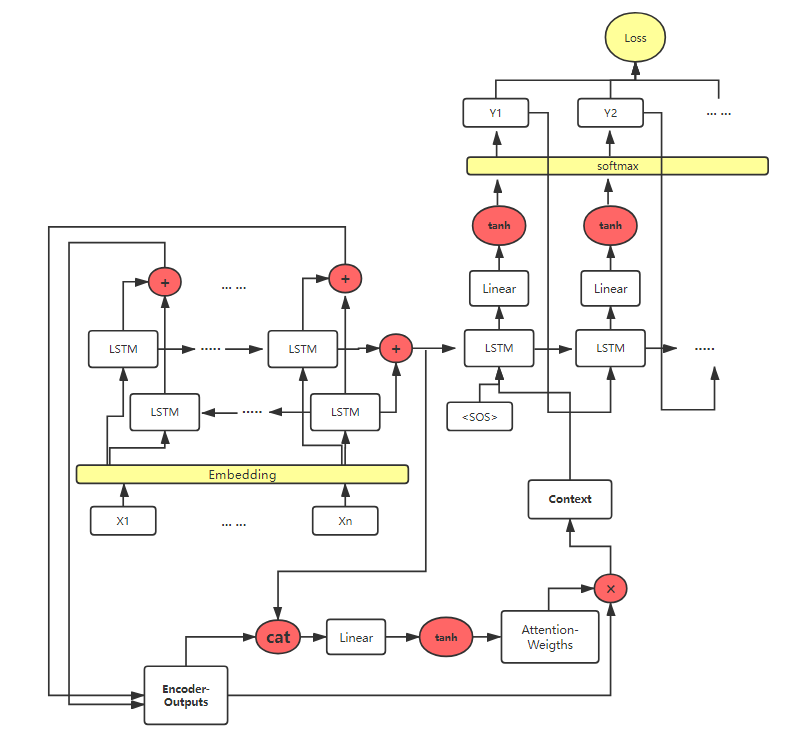 Encoder采用4层双向LSTM,Decoder采用4层LSTM
Encoder采用4层双向LSTM,Decoder采用4层LSTM
采用注意力机制
隐藏层维度为512
batch_size = 128
学习率初始为0.001,训练过程中衰减至0.0001
采用Adam梯度下降
损失函数采用交叉熵损失(cross-entropy loss)
训练
执行python main_train.py以训练模型。相关参数解释如下:
corpus:语料路径
batch_size
n_iteration:迭代次数
learning_rate:学习率
n_layers:层数
hidden_size:隐藏层维度
print_every:每多少次打印损失
save_every:每多少次保存模型
load_pretrain:与训练模型路径
voc:词典
pairs:训练语句对
bidirectional:是否双向
dropout:dropout失活概率
use_ATTN:是否使用注意力机制
rnn_type:单元类型,‘LSTM’或’GRU’
测试
执行python main_test.py执行测试。指定模型路径后,即可进行对话。'q’终止。
模型部分源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 使用CUDA
USE_CUDA = torch.cuda.is_available()
device = torch.device("cuda" if USE_CUDA else "cpu")
# Attention机制
class AttentionModel(nn.Module):
def __init__(self,hidden_size):
super(AttentionModel,self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(self.hidden_size*2,self.hidden_size)
self.v = nn.Parameter(torch.FloatTensor(1,self.hidden_size))
# encoder_outputs是Encoder的输出,last_output是Decoder的上一步输出,以此为根据计算权重
def forward(self,encoder_outputs,rnn_hidden):
# 根据注意力机制,Encoder的seq_len,即encoder_seq_len,就是注意力权重的维度
# 再加上batch_size
encoder_seq_len = encoder_outputs.size(0)
batch_size = rnn_hidden.size(1)
energy = torch.zeros(batch_size,encoder_seq_len)
energy = energy.to(device)
# 计算
for b in range(batch_size):
for i in  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8004
8004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











