







 这篇博客介绍了Python中文件的打开方式,包括读写模式、缓冲和with语句的使用。接着讲解了如何操作Excel和CSV文件,包括读取和写入。还涉及os模块的文件和目录操作,如创建、删除目录,以及datetime模块的date、time和datetime类。此外,文章讨论了Python中的类和对象,包括继承、方法重写、实例属性和类属性。最后提到了正则表达式和HTTP请求的相关知识。
这篇博客介绍了Python中文件的打开方式,包括读写模式、缓冲和with语句的使用。接着讲解了如何操作Excel和CSV文件,包括读取和写入。还涉及os模块的文件和目录操作,如创建、删除目录,以及datetime模块的date、time和datetime类。此外,文章讨论了Python中的类和对象,包括继承、方法重写、实例属性和类属性。最后提到了正则表达式和HTTP请求的相关知识。
参考/引用资料:
Python 3 |菜鸟教程 http://www.runoob.com/python3/python3-tutorial.html
廖雪峰 Python教程 https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
C语言中文网 http://c.biancheng.net/python/function/
mrbean博客 https://www.cnblogs.com/MrLJC/p/3715783.html
苍松博客 https://www.cnblogs.com/tkqasn/p/6001134.html
天道酬勤_FUN https://www.jianshu.com/p/d78982126318
https://blog.youkuaiyun.com/yatere/article/details/6658457
1.file
a.打开文件方式(读写两种方式)
Python使用 open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。默认为文本模式,如果要以二进制模式打开,加上 b 。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
w 只是代表写模式,而 w+ 则代表读写模式,但实际上它们的差别并不大。因为不管是 w 还是 w+ 模式,当使用这两种模式打开指定文件时,open() 函数都会立即清空文件内容,实际上都无法读取文件内容。
下图说明了不同文件打开模式的功能。
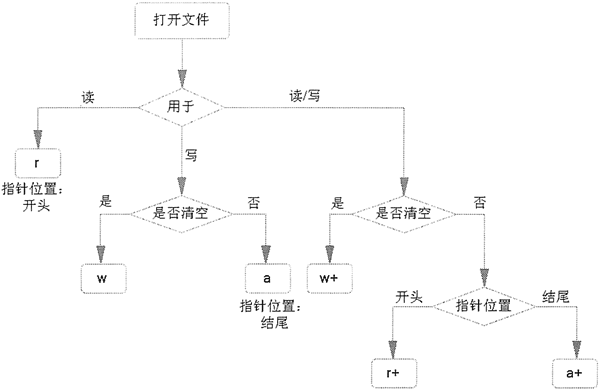
需要指出的是,如果程序使用 r 或 r+ 模式打开文件,则要求被打开的文件本身是存在的。也就是说,使用 r 或 r+ 模式都不能创建文件。但如果使用 w、w+、a、a+ 模式打开文件,则该文件可以是不存在的,open() 函数会自动创建新文件。
b 模式可被迫加到其他模式上,用于代表以二进制的方式来读写文件内容。对于计算机中的文件来说,文本文件只有很少的一部分,大部分文件其实都是二进制文件,包括图片文件、音频文件、视频文件等。
如果使用文本方式来操作二进制文件,则往往无法得到正确的文件内容。道理很简单,比如强行以文本方式打开一个音频文件,则势必会出现乱码。因此,如果程序需要读写文本文件以外的其他文件,则都应该添加 b 模式。
缓冲
众所周知,计算机外设(比如硬盘、网络)的 I/O 速度远远低于访问内存的速度,而程序执行 I/O 时要么将内存中的数据写入外设,要么将外设中的数据读取到内存,如果不使用缓冲,就必须等外设输入或输出一个字节后,内存中的程序才能输出或输入一个字节,这意味着内存中的程序大部分时间都处于等待状态。
内存中程序的读写速度很快,如果不使用缓冲,则程序必须等待外设进行同步读写。打个形象的比喻,就像在一条堵车的马路上开着跑车,必须等前面的车开一点,跑车才能前进一点。
因此,一般建议打开缓冲。在打开缓冲之后,当程序执行输出时,程序会先将数据输出到缓冲区中,而不用等待外设同步输出,当程序把所有数据都输出到缓冲区中之后,程序就可以去干其他事情了,留着缓冲区慢慢同步到外设即可;反过来,当程序执行输入时,程序会先等外设将数据读入缓冲区中,而不用等待外设同步输入。
在使用 open() 函数时,如果其第三个参数是 0(或 False),那么该函数打开的文件就是不带缓冲的;如果其第三个参数是 1(或 True),则该函数打开的文件就是带缓冲的,此时程序执行 I/O 将具有更好的性能。如果其第三个参数是大于 1 的整数,则该整数用于指定缓冲区的大小(单位是字节);如果其第三个参数为任何负数,则代表使用默认的缓冲区大小。
with语句
Python 提供了 with 语句来管理资源关闭。比如可以把打开的文件放在 with 语句中,这样 with 语句就会帮我们自动关闭文件。
with 语句的语法格式如下:
with context expression [as target(s)]:
with 代码块
在上面的语法格式中,context_expression 用于创建可自动关闭的资源。
例如,程序使用 with 语句来读取文件:
import codecs
# 使用with语句打开文件,该语句会负责关闭文件
with codecs.open("readlines_test.py", 'r', 'utf-8', buffering=True) as f:
for line in f:
print(line, end='')
## b.文件对象的操作方法
b.文件对象的操作方法
file 对象:file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 方法 | 描述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。没有返回值。 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。没有返回值。 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.next() | 返回文件下一行。 |
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 读取整行,包括 “\n” 字符。 |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[, whence]) | 设置文件当前位置 |
| file.tell() | 返回文件当前位置。 |
| file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
c.学习对excel及csv文件进行操作
读写excel
读excel表
读excel要用到xlrd模块
#导入模块
import xlrd
#打开Excel文件读取数据
data = xlrd.open_workbook('excel.xls')
table = data.sheets()[0] #通过索引顺序获取
table = data.sheet_by_index(0) #通过索引顺序获取
table = data.sheet_by_name(u'Sheet1') #通过名称获取
#获取整行和整列的值(返回数组)
table.row_values(i)
table.col_values(i)
#获取行数和列数
table.nrows
table.ncols
#获取单元格
table.cell(0,0).value
table.cell(2,3).value
获取cell相当于是给了一个二维数组,比较有用。
写excel表
写excel表要用到xlwt模块
#导入模块
import xlwt
#创建workbook(其实就是excel,后来保存一下就行)
workbook = xlwt.Workbook(encoding = 'ascii')
#创建表
worksheet = workbook.add_sheet('My Worksheet')
#往单元格内写入内容
worksheet.write(0, 0, label = 'Row 0, Column 0 Value')
#保存
workbook.save('Excel_Workbook.xls')
建议用ascii编码,不然可能会有一些诡异的现象。
xlwt可以设置各种样式之类的。官方例子:
1 Examples Generating Excel Documents Using Python’s xlwt
2
3 Here are some simple examples using Python’s xlwt library to dynamically generate Excel documents.
4
5 Please note a useful alternative may be ezodf, which allows you to generate ODS (Open Document Spreadsheet) files for LibreOffice / OpenOffice. You can check them out at:http://packages.python.org/ezodf/index.html
6
7 The Simplest Example
8 import xlwt
9 workbook = xlwt.Workbook(encoding = 'ascii')
10 worksheet = workbook.add_sheet('My Worksheet')
11 worksheet.write(0, 0, label = 'Row 0, Column 0 Value')
12 workbook.save('Excel_Workbook.xls')
13
14 Formatting the Contents of a Cell
15 import xlwt
16 workbook = xlwt.Workbook(encoding = 'ascii')
17 worksheet = workbook.add_sheet('My Worksheet')
18 font = xlwt.Font() # Create the Font
19 font.name = 'Times New Roman'
20 font.bold = True
21 font.underline = True
22 font.italic = True
23 style = xlwt.XFStyle() # Create the Style
24 style.font = font # Apply the Font to the Style
25 worksheet.write(0, 0, label = 'Unformatted value')
26 worksheet.write(1, 0, label = 'Formatted value', style) # Apply the Style to the Cell
27 workbook.save('Excel_Workbook.xls')
28
29 Attributes of the Font Object
30 font.bold = True # May be: True, False
31 font.italic = True # May be: True, False
32 font.struck_out = True # May be: True, False
33 font.underline = xlwt.Font.UNDERLINE_SINGLE # May be: UNDERLINE_NONE, UNDERLINE_SINGLE, UNDERLINE_SINGLE_ACC, UNDERLINE_DOUBLE, UNDERLINE_DOUBLE_ACC
34 font.escapement = xlwt.Font.ESCAPEMENT_SUPERSCRIPT # May be: ESCAPEMENT_NONE, ESCAPEMENT_SUPERSCRIPT, ESCAPEMENT_SUBSCRIPT
35 font.family = xlwt.Font.FAMILY_ROMAN # May be: FAMILY_NONE, FAMILY_ROMAN, FAMILY_SWISS, FAMILY_MODERN, FAMILY_SCRIPT, FAMILY_DECORATIVE
36 font.charset = xlwt.Font.CHARSET_ANSI_LATIN # May be: CHARSET_ANSI_LATIN, CHARSET_SYS_DEFAULT, CHARSET_SYMBOL, CHARSET_APPLE_ROMAN, CHARSET_ANSI_JAP_SHIFT_JIS, CHARSET_ANSI_KOR_HANGUL, CHARSET_ANSI_KOR_JOHAB, CHARSET_ANSI_CHINESE_GBK, CHARSET_ANSI_CHINESE_BIG5, CHARSET_ANSI_GREEK, CHARSET_ANSI_TURKISH, CHARSET_ANSI_VIETNAMESE, CHARSET_ANSI_HEBREW, CHARSET_ANSI_ARABIC, CHARSET_ANSI_BALTIC, CHARSET_ANSI_CYRILLIC, CHARSET_ANSI_THAI, CHARSET_ANSI_LATIN_II, CHARSET_OEM_LATIN_I
37 font.colour_index = ?
38 font.get_biff_record = ?
39 font.height = 0x00C8 # C8 in Hex (in decimal) = 10 points in height.
40 font.name = ?
41 font.outline = ?
42 font.shadow = ?
43
44 Setting the Width of a Cell
45 import xltw
46 workbook = xlwt.Workbook()
47 worksheet = workbook.add_sheet('My Sheet')
48 worksheet.write(0, 0, 'My Cell Contents')
49 worksheet.col(0).width = 3333 # 3333 = 1" (one inch).
50 workbook.save('Excel_Workbook.xls')
51
52 Entering a Date into a Cell
53 import xlwt
54 import datetime
55 workbook = xlwt.Workbook()
56 worksheet = workbook.add_sheet('My Sheet')
57 style = xlwt.XFStyle()
58 style.num_format_str = 'M/D/YY' # Other options: D-MMM-YY, D-MMM, MMM-YY, h:mm, h:mm:ss, h:mm, h:mm:ss, M/D/YY h:mm, mm:ss, [h]:mm:ss, mm:ss.0
59 worksheet.write(0, 0, datetime.datetime.now(), style)
60 workbook.save('Excel_Workbook.xls')
61
62 Adding a Formula to a Cell
63 import xlwt
64 workbook = xlwt.Workbook()
65 worksheet = workbook.add_sheet('My Sheet')
66 worksheet.write(0, 0, 5) # Outputs 5
67 worksheet.write(0, 1, 2) # Outputs 2
68 worksheet.write(1, 0, xlwt.Formula('A1*B1')) # Should output "10" (A1[5] * A2[2])
69 worksheet.write(1, 1, xlwt.Formula('SUM(A1,B1)')) # Should output "7" (A1[5] + A2[2])
70 workbook.save('Excel_Workbook.xls')
71
72 Adding a Hyperlink to a Cell
73 import xlwt
74 workbook = xlwt.Workbook()
75 worksheet = workbook.add_sheet('My Sheet')
76 worksheet.write(0, 0, xlwt.Formula('HYPERLINK("http://www.google.com";"Google")')) # Outputs the text "Google" linking to http://www.google.com
77 workbook.save('Excel_Workbook.xls')
78
79 Merging Columns and Rows
80 import xlwt
81 workbook = xlwt.Workbook()
82 worksheet = workbook.add_sheet('My Sheet')
83 worksheet.write_merge(0, 0, 0, 3, 'First Merge') # Merges row 0's columns 0 through 3.
84 font = xlwt.Font() # Create Font
85 font.bold = True # Set font to Bold
86 style = xlwt.XFStyle() # Create Style
87 style.font = font # Add Bold Font to Style
88 worksheet.write_merge(1, 2, 0, 3, 'Second Merge', style) # Merges row 1 through 2's columns 0 through 3.
89 workbook.save('Excel_Workbook.xls')
90
91 Setting the Alignment for the Contents of a Cell
92 import xlwt
93 workbook = xlwt.Workbook()
94 worksheet = workbook.add_sheet('My Sheet')
95 alignment = xlwt.Alignment() # Create Alignment
96 alignment.horz = xlwt.Alignment.HORZ_CENTER # May be: HORZ_GENERAL, HORZ_LEFT, HORZ_CENTER, HORZ_RIGHT, HORZ_FILLED, HORZ_JUSTIFIED, HORZ_CENTER_ACROSS_SEL, HORZ_DISTRIBUTED
97 alignment.vert = xlwt.Alignment.VERT_CENTER # May be: VERT_TOP, VERT_CENTER, VERT_BOTTOM, VERT_JUSTIFIED, VERT_DISTRIBUTED
98 style = xlwt.XFStyle() # Create Style
99 style.alignment = alignment # Add Alignment to Style
100 worksheet.write(0, 0, 'Cell Contents', style)
101 workbook.save('Excel_Workbook.xls')
102
103 Adding Borders to a Cell
104 # Please note: While I was able to find these constants within the source code, on my system (using LibreOffice,) I was only presented with a solid line, varying from thin to thick; no dotted or dashed lines.
105 import xlwt
106 workbook = xlwt.Workbook()
107 worksheet = workbook.add_sheet('My Sheet')
108 borders = xlwt.Borders() # Create Borders
109 borders.left = xlwt.Borders.DASHED # May be: NO_LINE, THIN, MEDIUM, DASHED, DOTTED, THICK, DOUBLE, HAIR, MEDIUM_DASHED, THIN_DASH_DOTTED, MEDIUM_DASH_DOTTED, THIN_DASH_DOT_DOTTED, MEDIUM_DASH_DOT_DOTTED, SLANTED_MEDIUM_DASH_DOTTED, or 0x00 through 0x0D.
110 borders.right = xlwt.Borders.DASHED
111 borders.top = xlwt.Borders.DASHED
112 borders.bottom = xlwt.Borders.DASHED
113 borders.left_colour = 0x40
114 borders.right_colour = 0x40
115 borders.top_colour = 0x40
116 borders.bottom_colour = 0x40
117 style = xlwt.XFStyle() # Create Style
118 style.borders = borders # Add Borders to Style
119 worksheet.write(0, 0, 'Cell Contents', style)
120 workbook.save('Excel_Workbook.xls')
121
122 Setting the Background Color of a Cell
123 import xlwt
124 workbook = xlwt.Workbook()
125 worksheet = workbook.add_sheet('My Sheet')
126 pattern = xlwt.Pattern() # Create the Pattern
127 pattern.pattern = xlwt.Pattern.SOLID_PATTERN # May be: NO_PATTERN, SOLID_PATTERN, or 0x00 through 0x12
128 pattern.pattern_fore_colour = 5 # May be: 8 through 63. 0 = Black, 1 = White, 2 = Red, 3 = Green, 4 = Blue, 5 = Yellow, 6 = Magenta, 7 = Cyan, 16 = Maroon, 17 = Dark Green, 18 = Dark Blue, 19 = Dark Yellow , almost brown), 20 = Dark Magenta, 21 = Teal, 22 = Light Gray, 23 = Dark Gray, the list goes on...
129 style = xlwt.XFStyle() # Create the Pattern
130 style.pattern = pattern # Add Pattern to Style
131 worksheet.write(0, 0, 'Cell Contents', style)
132 workbook.save('Excel_Workbook.xls')
133
134 TODO: Things Left to Document
135 - Panes -- separate views which are always in view
136 - Border Colors (documented above, but not taking effect as it should)
137 - Border Widths (document above, but not working as expected)
138 - Protection
139 - Row Styles
140 - Zoom / Manification
141 - WS Props?
142 Source Code for reference available at: https://secure.simplistix.co.uk/svn/xlwt/trunk/xlwt/
读写csv
CSV,全称为Comma-Separated Values,它以逗号分隔值,其文件以纯文本形式存储表格数据,该文件是一个字符序列,可以由任意数目的记录组成,每条记录有字段组成,字段间分隔符是逗号或制表符,相当于结构化的纯文本形式,它比Excel文件更简洁,用来存储数据比较方便
读取csv文件
使用python I/O方法进行读取时即是新建一个List 列表然后按照先行后列的顺序(类似C语言中的二维数组)将数据存进空的List对象中,
读取出的数据一般为字符类型,如果是数字需要人为转换为数字
以行为单位读取数据
列之间以半角逗号或制表符为分隔,一般为半角逗号
一般为每行开头不空格,第一行是属性列,数据列之间以间隔符为间隔无空格,行之间无空行。
行之间无空行十分重要,如果有空行或者数据集中行末有空格,读取数据时一般会出错,引发[list index out of range]错误。
方式一:生成字典形式
使用DictReader逐行读取csv文件
返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的列标题
# 逐行读取csv文件
with open(filename,'r',encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
if row['media_name']=='hello':
print(row)
lines.append(row)
方式二:逐行读取
使用Reader逐行读取CSV文件,Reader为一个阅读器
我们调用csv.reader(),并将前面存储的文件对象作为实参传递给它,从而创建一个与该文件相关联的阅读亲返回一个(reader)对象,就可以从其中解析出csv的内容,以行为单位
import csv
with open('file.csv','r',encoding=“utf-8”) as csvfile:
reader = csv.reader(csvfile)
rows = [row for row in reader]
注意:参数“r”,为读取状态,若为“rb”,则表示读取二进制文件;若为“rt”,则为读取文本模式
方式三:读取某一列
with open(filename,encoding="utf-8") as f:
reader = csv.reader(f)
header_row = next(reader)
datas = []
for row in reader:
print(row[2])
方式四:获取每个元素的索引及其值
with open(filename,encoding="utf-8") as f:
reader = csv.reader(f)
header_row = next(reader)
for index,column_header in enumerate(header_row):
print(index,column_header)
写入csv
#输出数据写入CSV文件
import csv
data = [
("Mike", "male", 24),
("Lee", "male", 26),
("Joy", "female", 22)
]
#Python3.4以后的新方式,解决空行问题
with open('d://write.csv', 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
for list in data:
print(list)
csv_writer.writerow(list)
2.os模块
Python内置的os模块也可以直接调用操作系统提供的接口函数。
操作文件和目录的函数一部分放在os模块中,一部分放在os.path模块中。
查看、创建和删除目录
# 查看当前目录的绝对路径:
>>> os.path.abspath('.')
'/Users/michael'
# 在某个目录下创建一个新目录,首先把新目录的完整路径表示出来:
>>> os.path.join('/Users/michael', 'testdir')
'/Users/michael/testdir'
# 然后创建一个目录:
>>> os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
>>> os.rmdir('/Users/michael/testdir')
把两个路径合成一个时,不要直接拼字符串,而要通过os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。在Linux/Unix/Mac下,os.path.join()返回这样的字符串:
part-1/part-2
而Windows下会返回这样的字符串:
part-1\part-2
同样的道理,要拆分路径时,也不要直接去拆字符串,而要通过os.path.split()函数,这样可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名:
>>> os.path.split('/Users/michael/testdir/file.txt')
('/Users/michael/testdir', 'file.txt')’
os.path.splitext()可以直接让你得到文件扩展名,很多时候非常方便:
>>> os.path.splitext('/path/to/file.txt')
('/path/to/file', '.txt')
这些合并、拆分路径的函数并不要求目录和文件要真实存在,它们只对字符串进行操作。
文件操作函数
假定当前目录下有一个test.txt文件:
# 对文件重命名:
>>> os.rename('test.txt', 'test.py')
# 删掉文件:
>>> os.remove('test.py')
但是复制文件的函数居然在os模块中不存在!原因是复制文件并非由操作系统提供的系统调用。理论上讲,我们通过上一节的读写文件可以完成文件复制,只不过要多写很多代码。
幸运的是shutil模块提供了copyfile()的函数,你还可以在shutil模块中找到很多实用函数,它们可以看做是os模块的补充。
过滤文件
利用Python的特性来过滤文件。比如我们要列出当前目录下的所有目录,只需要一行代码:
>>> [x for x in os.listdir('.') if os.path.isdir(x)]
['.lein', '.local', '.m2', '.npm', '.ssh', '.Trash', '.vim', 'Applications', 'Desktop', ...]
要列出所有的.py文件,也只需一行代码:
>>> [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
['apis.py', 'config.py', 'models.py', 'pymonitor.py', 'test_db.py', 'urls.py', 'wsgiapp.py']
os模块与目录相关的函数
与目录相关的函数如下:
os.getcwd():获取当前目录。
os.chdir(path):改变当前目录。
os.fchdir(fd):通过文件描述利改变当前目录。该函数与上一个函数的功能基本相似,只是该函数以文件描述符作为参数来代表目录。
下面程序测试了与目录相关的函数的用法:
import os
# 获取当前目录
print(os.getcwd()) # G:\publish\codes\12.7
# 改变当前目录
os.chdir('../12.6')
# 再次获取当前目录
print(os.getcwd()) # G:\publish\codes\12.6
上面程序示范了使用 getcwd() 来获取当前目录,也示范了使用 chdir() 来改变当前目录。
os.chroot(path):改变当前进程的根目录。
os.listdir(path):返回 path 对应目录下的所有文件和子目录。
os.mkdir(path[, mode]):创建 path 对应的目录,其中 mode 用于指定该目录的权限。
该 mode参数代表一个 UNIX 风格的权限,比如 0o777 代表所有者可读/可写/可执行、
组用户可读/可写/可执行、其他用户可读/可写/可执行。
os.makedirs(path[, mode]):其作用类似于 mkdir(),但该函数的功能更加强大,它可以边归创建目录。
比如要创建 abc/xyz/wawa 目录,如果在当前目录下没有 abc 目录,那么使用 mkdir() 函数就会报错,
而使用 makedirs() 函数则会先创建 abc,然后在其中创建 xyz 子目录,最后在 xyz 子目录下创建 wawa 子目录。
如下程序示范了如何创建目录:
mport os
path = 'my_dir'
# 直接在当前目录下创建目录
os.mkdir(path, 0o755)
path = "abc/xyz/wawa"
# 递归创建目录
os.makedirs(path, 0o755)
正如从上面代码所看到的,直接在当前目录下创建 mydir 子目录,因此可以使用 mkdir() 函数创建;需要程序递归创建 abc/xyz/wawa 目录,因此使用 makedirs() 函数。
os.rmdir(path):删除 path 对应的空目录。如果目录非空,则抛出一个 OSError 异常。程序可以先用 os.remove() 函数删除文件。
os.removedirs(path):边归删除目录。其功能类似于 rmdir(),但该函数可以递归删除 abc/xyz/wawa 目录,它会从 wawa 子目录开始删除,然后删除 xyz 子目录,最后删除 abc 目录。
如下程序示范了如何删除目录:
import os
path = 'my_dir'
# 直接删除当前目录下的子目录
os.rmdir(path)
path = "abc/xyz/wawa"
# 递归删除子目录
os.removedirs(path)
上面程序中第 5 行代码使用 rmdir() 函数删除当前目录下的 my_dir 子目录,该函数不会执行递归删除;第 8 行代码使用
removedirs() 函数删除 abc/xyz/wawa 目录,该函数会执行递归删除,它会先删除 wawa 子目录,然后删除 xyz 子目录,最后才删除 abc 目录。
os.rename(src, dst):重命名文件或目录,将 src 重名为 dst。
os.renames(old, new):对文件或目录进行递归重命名。其功能类似于 rename(),但该函数可以递归重命名 abc/xyz/wawa 目录,
它会从 wawa 子目录开始重命名,然后重命名 xyz 子目录,最后重命名 abc 目录。
如下程序示范了如何重命名目录:
import os
path = 'my_dir'
# 直接重命名当前目录下的子目录
os.rename(path, 'your_dir')
path = "abc/xyz/wawa"
# 递归重命名子目录
os.renames(path, 'foo/bar/haha')
上面程序中第 5 行代码直接重命名当前目录下的 my_dir 子目录,程序会将该子目录重命名为 your_dir;第 8 行代码则执行递归重命名,程序会将 wawa 重命名为 haba,将 xyz 重命名为 bar,将 abc 重命名为 foo。
3.datetime模块
datatime模块重新封装了time模块,提供更多接口,提供的类有:date,time,datetime,timedelta,tzinfo。
date类
datetime.date(year, month, day)
静态方法和字段
date.max、date.min:date对象所能表示的最大、最小日期;
date.resolution:date对象表示日期的最小单位。这里是天。
date.today():返回一个表示当前本地日期的date对象;
date.fromtimestamp(timestamp):根据给定的时间戮,返回一个date对象;
from datetime import *
import time
print 'date.max:', date.max
print 'date.min:', date.min
print 'date.today():', date.today()
print 'date.fromtimestamp():', date.fromtimestamp(time.time())
#Output======================
# date.max: 9999-12-31
# date.min: 0001-01-01
# date.today(): 2016-10-26
# date.fromtimestamp(): 2016-10-26
方法和属性
d1 = date(2011,06,03)#date对象
d1.year、date.month、date.day:年、月、日;
d1.replace(year, month, day):生成一个新的日期对象,用参数指定的年,月,日代替原有对象中的属性。(原有对象仍保持不变)
d1.timetuple():返回日期对应的time.struct_time对象;
d1.weekday():返回weekday,如果是星期一,返回0;如果是星期2,返回1,以此类推;
d1.isoweekday():返回weekday,如果是星期一,返回1;如果是星期2,返回2,以此类推;
d1.isocalendar():返回格式如(year,month,day)的元组;
d1.isoformat():返回格式如'YYYY-MM-DD’的字符串;
d1.strftime(fmt):和time模块format相同。
from datetime import *
now = date(2016, 10, 26)
tomorrow = now.replace(day = 27)
print 'now:', now, ', tomorrow:', tomorrow
print 'timetuple():', now.timetuple()
print 'weekday():', now.weekday()
print 'isoweekday():', now.isoweekday()
print 'isocalendar():', now.isocalendar()
print 'isoformat():', now.isoformat()
print 'strftime():', now.strftime("%Y-%m-%d")
#Output========================
# now: 2016-10-26 , tomorrow: 2016-10-27
# timetuple(): time.struct_time(tm_year=2016, tm_mon=10, tm_mday=26, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=2, tm_yday=300, tm_isdst=-1)
# weekday(): 2
# isoweekday(): 3
# isocalendar(): (2016, 43, 3)
# isoformat(): 2016-10-26
# strftime(): 2016-10-26
time类
datetime.time(hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] )
静态方法和字段
time.min、time.max:time类所能表示的最小、最大时间。其中,time.min = time(0, 0, 0, 0), time.max = time(23, 59, 59, 999999);
time.resolution:时间的最小单位,这里是1微秒;
方法和属性
t1 = datetime.time(10,23,15)#time对象
t1.hour、t1.minute、t1.second、t1.microsecond:时、分、秒、微秒;
t1.tzinfo:时区信息;
t1.replace([ hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] ] ):创建一个新的时间对象,用参数指定的时、分、秒、微秒代替原有对象中的属性(原有对象仍保持不变);
t1.isoformat():返回型如"HH:MM:SS"格式的字符串表示;
t1.strftime(fmt):同time模块中的format;
from datetime import *
tm = time(23, 46, 10)
print 'tm:', tm
print 'hour: %d, minute: %d, second: %d, microsecond: %d' % (tm.hour, tm.minute, tm.second, tm.microsecond)
tm1 = tm.replace(hour=20)
print 'tm1:', tm1
print 'isoformat():', tm.isoformat()
print 'strftime()', tm.strftime("%X")
#Output==============================================
# tm: 23:46:10
# hour: 23, minute: 46, second: 10, microsecond: 0
# tm1: 20:46:10
# isoformat(): 23:46:10
# strftime() 23:46:10
datetime类
datetime相当于date和time结合起来。
datetime.datetime (year, month, day[ , hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] ] )
静态方法和字段
datetime.today():返回一个表示当前本地时间的datetime对象;
datetime.now([tz]):返回一个表示当前本地时间的datetime对象,如果提供了参数tz,则获取tz参数所指时区的本地时间;
datetime.utcnow():返回一个当前utc时间的datetime对象;#格林威治时间
datetime.fromtimestamp(timestamp[, tz]):根据时间戮创建一个datetime对象,参数tz指定时区信息;
datetime.utcfromtimestamp(timestamp):根据时间戮创建一个datetime对象;
datetime.combine(date, time):根据date和time,创建一个datetime对象;
datetime.strptime(date_string, format):将格式字符串转换为datetime对象;
from datetime import *
import time
print 'datetime.max:', datetime.max
print 'datetime.min:', datetime.min
print 'datetime.resolution:', datetime.resolution
print 'today():', datetime.today()
print 'now():', datetime.now()
print 'utcnow():', datetime.utcnow()
print 'fromtimestamp(tmstmp):', datetime.fromtimestamp(time.time())
print 'utcfromtimestamp(tmstmp):', datetime.utcfromtimestamp(time.time())
#output======================
# datetime.max: 9999-12-31 23:59:59.999999
# datetime.min: 0001-01-01 00:00:00
# datetime.resolution: 0:00:00.000001
# today(): 2016-10-26 23:12:51.307000
# now(): 2016-10-26 23:12:51.307000
# utcnow(): 2016-10-26 15:12:51.307000
# fromtimestamp(tmstmp): 2016-10-26 23:12:51.307000
# utcfromtimestamp(tmstmp): 2016-10-26 15:12:51.307000
方法和属性
dt=datetime.now()#datetime对象
dt.year、month、day、hour、minute、second、microsecond、tzinfo:
dt.date():获取date对象;
dt.time():获取time对象;
dt. replace ([ year[ , month[ , day[ , hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] ] ] ] ]):
dt. timetuple ()
dt. utctimetuple ()
dt. toordinal ()
dt. weekday ()
dt. isocalendar ()
dt. isoformat ([ sep] )
dt. ctime ():返回一个日期时间的C格式字符串,等效于time.ctime(time.mktime(dt.timetuple()));
dt. strftime (format)
timedelta类,时间加减
使用timedelta可以很方便的在日期上做天days,小时hour,分钟,秒,毫秒,微妙的时间计算,如果要计算月份则需要另外的办法。
#coding:utf-8
from datetime import *
dt = datetime.now()
#日期减一天
dt1 = dt + timedelta(days=-1)#昨天
dt2 = dt - timedelta(days=1)#昨天
dt3 = dt + timedelta(days=1)#明天
delta_obj = dt3-dt
print type(delta_obj),delta_obj#<type 'datetime.timedelta'> 1 day, 0:00:00
print delta_obj.days ,delta_obj.total_seconds()#1 86400.0
tzinfo时区类
#! /usr/bin/python
# coding=utf-8
from datetime import datetime, tzinfo,timedelta
"""
tzinfo是关于时区信息的类
tzinfo是一个抽象类,所以不能直接被实例化
"""
class UTC(tzinfo):
"""UTC"""
def __init__(self,offset = 0):
self._offset = offset
def utcoffset(self, dt):
return timedelta(hours=self._offset)
def tzname(self, dt):
return "UTC +%s" % self._offset
def dst(self, dt):
return timedelta(hours=self._offset)
#北京时间
beijing = datetime(2011,11,11,0,0,0,tzinfo = UTC(8))
print "beijing time:",beijing
#曼谷时间
bangkok = datetime(2011,11,11,0,0,0,tzinfo = UTC(7))
print "bangkok time",bangkok
#北京时间转成曼谷时间
print "beijing-time to bangkok-time:",beijing.astimezone(UTC(7))
#计算时间差时也会考虑时区的问题
timespan = beijing - bangkok
print "时差:",timespan
#Output==================
# beijing time: 2011-11-11 00:00:00+08:00
# bangkok time 2011-11-11 00:00:00+07:00
# beijing-time to bangkok-time: 2011-11-10 23:00:00+07:00
# 时差: -1 day, 23:00:00
4.类和对象
面向对象技术简介
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
和其它编程语言相比,Python 在尽可能不增加新的语法和语义的情况下加入了类机制。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
Python 支持面向对象的三大特征:封装、继承和多态,子类继承父类同样可以继承到父类的变量和方法。
类的定义
Python 定义类的简单语法如下:
class 类名:
执行语句...
零个到多个类变量...
零个到多个方法...
类名只要是一个合法的标识符即可,但这仅仅满足的是 Python 的语法要求:如果从程序的可读性方面来看,Python 的类名必须是由一个或多个有意义的单词连缀而成的,每个单词首字母大写,其他字母全部小写,单词与单词之间不要使用任何分隔符。
类中各成员之间的定义顺序没有任何影响,各成员之间可以相互调用。
Python 类所包含的最重要的两个成员就是变量和方法,其中类变量属于类本身,用于定义该类本身所包含的状态数据:而实例变量则属于该类的对象,用于定义对象所包含的状态数据:方法则用于定义该类的对象的行为或功能实现。
在类中定义的方法默认是实例方法,定义实例方法的方法与定义函数的方法基本相同,只是实例方法的第一个参数会被绑定到方法的调用者(该类的实例),因此实例方法至少应该定义一个参数,该参数通常会被命名为 self。
在实例方法中有一个特别的方法:__init __,这个方法被称为构造方法。构造方法用于构造该类的对象,Python 通过调用构造方法返回该类的对象(无须使用 new)。
构造方法是一个类创建对象的根本途径,因此 Python 还提供了一个功能:如果开发者没有为该类定义任何构造方法,那么 Python 会自动为该类定义一个只包含一个 self 参数的默认的构造方法。
class Person :
'这是一个学习Python定义的一个Person类'
# 下面定义了一个类变量
hair = 'black'
def __init__(self, name = 'Charlie', age=8):
# 下面为Person对象增加2个实例变量
self.name = name
self.age = age
# 下面定义了一个say方法
def say(self, content):
print(content)
上面的 Person 类代码定义了一个构造方法,该构造方法只是方法名比较特殊:init,该方法的第一个参数同样是 self,被绑定到构造方法初始化的对象。
self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
对于在类体中定义的实例方法,Python 会自动绑定方法的第一个参数(通常建议将该参数命名为 self),第一个参数总是指向调用该方法的对象。根据第一个参数出现位置的不同,第一个参数所绑定的对象略有区别:
- 在构造方法中引用该构造方法正在初始化的对象。
- 在普通实例方法中引用调用该方法的对象。
由于实例方法(包括构造方法)的第一个 self 参数会自动绑定,因此程序在调用普通实例方法、构造方法时不需要为第一个参数传值。
与函数类似的是,Python 也允许为类定义说明文档,该文档同样被放在类声明之后、类体之前,如上面程序中第二行的字符串所示。
在定义类之后,接下来即可使用该类了。Python 的类大致有如下作用:
- 定义变量;
- 创建对象;
- 派生子类;
创建对象
如下代码示范了调用 Person 类的构造方法:
# 调用Person类的构造方法,返回一个Person对象
# 将该Person对象赋给p变量
p = Person()
创建对象之后,接下来即可使用该对象了。Python 的对象大致有如下作用:
- 操作对象的实例变量(包括访问实例变量的值、添加实例变量、删除实例变量)。
- 调用对象的方法。
对象访问方法或变量的语法是:对象.变量|方法(参数)。在这种方式中,对象是主调者,用于访问该对象的变量或方法。
Python对象动态添加变量和方法
由于 Python 是动态语言,因此程序完全可以为 p 对象动态增加实例变量只要为它的新变量赋值即可;也可以动态删除实例变量(使用 del 语句即可删除)。例如如下代码:
# 为p对象增加一个skills实例变量
p.skills = ['programming', 'swimming']
print(p.skills)
# 删除p对象的name实例变量
del p.name
# 再次访问p的name实例变量
print(p.name) # AttributeError
上面程序先为 p 对象动态增加了一个 skills 实例变量,即只要对 p 对象的 skills 实例变量赋值就是新增一个实例变量。接下来程序中调用 del 删除了 p 对象的 name 实例变量,当程序再次访问 print(p.name) 时就会导致 AttributeError 错误,并提示:‘Person’ object has no attribute ‘name’。
Python也允许为对象动态增加方法。
但需要说明的是,为 p 对象动态增加的方法,Python 不会自动将调用者自动绑定到第一个参数(即使将第一个参数命名为 self 也没用)。例如如下代码:
# 先定义一个函数
def info(self):
print("---info函数---", self)
# 使用info对p的foo方法赋值(动态绑定方法)
p.foo = info
# Python不会自动将调用者绑定到第一个参数,
# 因此程序需要手动将调用者绑定为第一个参数
p.foo(p) # ①
# 使用lambda表达式为p对象的bar方法赋值(动态绑定方法)
p.bar = lambda self: print('--lambda表达式--', self)
p.bar(p) # ②
上面的第 5 行和第 11 行代码分别使用函数、lambda 表达式为 p 对象动态增加了方法,但对于动态增加的方法,Python 不会自动将方法调用者绑定到它们的第一个参数,因此程序必须手动为第一个参数传入参数值,如上面程序中 ① 号、② 号代码所示。
如果希望动态增加的方法也能自动绑定到第一个参数,则可借助于 types 模块下的 MethodType 进行包装。例如如下代码:
def intro_func(self, content):
print("我是一个人,信息为:%s" % content)
# 导入MethodType
from types import MethodType
# 使用MethodType对intro_func进行包装,将该函数的第一个参数绑定为p
p.intro = MethodType(intro_func, p)
# 第一个参数已经绑定了,无需传入
p.intro("生活在别处")
正如从上面代码所看到的,通过 MethodType 包装 intr_func 函数之后(包装时指定了将该函数的第一个参数绑定为 p),为 p 对象动态增加的 intro() 方法的第一个参数己经绑定,因此程序通过 p 调用 intro() 方法时无须传入第一个参数,就像定义类时己经定义了 intro() 方法一样。
使用类调用实例方法时,Python 不会自动为第一个参数绑定调用者。实际上也没法自动绑定,因此实例方法的调用者是类本身,而不是对象。
如果程序依然希望使用类来调用实例方法,则必须手动为方法的第一个参数传入参数值。
class User:
def walk (self):
print(self, '正在慢慢地走')
u = User()
# 显式为方法的第一个参数绑定参数值
User.walk(u)
u.walk() #和上一句作用一样
# 显式为方法的第一个参数绑定fkit字符串参数值
User.walk('fkit')
#如果按上面方式进行绑定,那么 'fkit' 字符串就会被传给 walk() 方法的第一个参数 self。
#fkit 正在慢慢地走
实例属性和类属性
实例属性属于各个实例所有,互不干扰;
类属性属于类所有,所有实例共享一个属性;
不要对实例属性和类属性使用相同的名字,否则将产生难以发现的错误。
>>> class Student(object):
... name = 'Student'
...
>>> s = Student() # 创建实例s
>>> print(s.name) # 打印name属性,因为实例并没有name属性,所以会继续查找class的name属性
Student
>>> print(Student.name) # 打印类的name属性
Student
>>> s.name = 'Michael' # 给实例绑定name属性
>>> print(s.name) # 由于实例属性优先级比类属性高,因此,它会屏蔽掉类的name属性
Michael
>>> print(Student.name) # 但是类属性并未消失,用Student.name仍然可以访问
Student
>>> del s.name # 如果删除实例的name属性
>>> print(s.name) # 再次调用s.name,由于实例的name属性没有找到,类的name属性就显示出来了
Student
封装
Python 并没有提供类似于其他语言的 private 等修饰符,因此 Python 并不能真正支持隐藏。为了隐藏类中的成员,Python 玩了一个小技巧:只要将 Python 类的成员命名为以双下画线开头的,Python 就会把它们隐藏起来。
需要配合数据描述符协议函数Property()。它的标准定义是:
property(fget=None,fset=None,fdel=None,doc=None)
前面3个参数都是未绑定的方法,所以它们事实上可以是任意的类成员函数
property()函数前面三个参数分别对应于数据描述符的中的__get__,set,__del__方法,所以它们之间会有一个内部的与数据描述符的映射。
class C(object):
def __init__(self):
self._x = None
def getx(self):
print ("get x")
return self._x
def setx(self, value):
print ("set x")
self._x = value
def delx(self):
print ("del x")
del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")
如果要使用property函数,首先定义class的时候必须是object的子类。通过property的定义,当获取成员x的值时,就会调用getx函数,当给成员x赋值时,就会调用setx函数,当删除x时,就会调用delx函数。使用属性的好处就是因为在调用函数,可以做一些检查。如果没有严格的要求,直接使用实例属性可能更方便。
>>> t=C()
>>> t.x
get x
>>> print (t.x)
get x
None
>>> t.x='en'
set x
>>> print (t.x)
get x
en
>>> del t.x
del x
>>> print (t.x)
get x
继承
继承是面向对象的三大特征之一,也是实现软件复用的重要手段。Python 的继承是多继承机制,即一个子类可以同时有多个直接父类。
Python 子类继承父类的语法是在定义子类时,将多个父类放在子类之后的圆括号里。语法格式如下:
class Subclass (SuperClass1, SuperClass2, ...)
#类定义部分
从上面的语法格式来看,定义子类的语法非常简单,只需在原来的类定义后增加圆括号,井在圆括号中添加多个父类,即可表明该子类继承了这些父类。
如果在定义一个 Python 类时并未显式指定这个类的直接父类,则这个类默认继承 object 类。因此,object 类是所有类的父类,要么是其直接父类,要么是其间接父类。
实现继承的类被称为子类,被继承的类被称为父类(也被称为基类、超类)。父类和子类的关系,是一般和特殊的关系。例如水果和苹果的关系,苹果继承了水果,苹果是水果的子类,则苹果是一种特殊的水果。
由于子类是一种特殊的父类,因此父类包含的范围总比子类包含的范围要大,所以可以认为父类是大类,而子类是小类。
从实际意义上看,子类是对父类的扩展,子类是一种特殊的父类。从这个意义上看,使用继承来描述子类和父类的关系是错误的,用扩展更恰当。因此,这样的说法更加准确:Apple 类扩展了 Fruit 类。
Python 虽然在语法上明确支持多继承,但通常推荐如果不是很有必要,则尽量不要使用多继承,而是使用单继承,这样可以保证编程思路更清晰,而且可以避免很多麻烦。
当一个子类有多个直接父类时,该子类会继承得到所有父类的方法,这一点在前面示例中己经做了示范。现在的问题是,如果多个父类中包含了同名的方法,此时会发生什么呢?此时排在前面的父类中的方法会“遮蔽”排在后面的父类中的同名方法。
方法重写Override
子类包含与父类同名的方法的现象被称为方法重写(Override),也被称为方法覆盖。可以说子类重写了父类的方法,也可以说子类覆盖了父类的方法。
如果在子类中调用重写之后的方法,Python 总是会执行子类重写的方法,不会执行父类中被重写的方法。如果需要在子类中调用父类中被重写的实例方法,那该怎么办呢?
别忘了,Python 类相当于类空间,因此 Python 类中的方法本质上相当于类空间内的函数。所以,即使是实例方法,Python 也允许通过类名调用。区别在于:在通过类名调用实例方法时,Python 不会为实例方法的第一个参数 self 自动绑定参数值,而是需要程序显式绑定第一个参数 self。这种机制被称为未绑定方法。
通过使用未绑定方法即可在子类中再次调用父类中被重写的方法。例如如下程序:
class BaseClass:
def foo (self):
print('父类中定义的foo方法')
class SubClass(BaseClass):
# 重写父类的foo方法
def foo (self):
print('子类重写父类中的foo方法')
def bar (self):
print('执行bar方法')
# 直接执行foo方法,将会调用子类重写之后的foo()方法
self.foo()
# 使用类名调用实例方法(未绑定方法)调用父类被重写的方法
BaseClass.foo(self)
sc = SubClass()
sc.bar()
上面程序中 SubClass 继承了 BaseClass 类,并重写了父类的 foo() 方法。接下来程序在 SubClass 类中定义了 bar() 方法,该方法的第 11 行代码直接通过 self 调用 foo() 方法,Python 将会执行子类重写之后的 foo() 方法;第 13 行代码通过未绑定方法显式调用 BaseClass 中的 foo 实例方法,井显式为第一个参数 self 绑定参数值,这就实现了调用父类中被重写的方法。
Python 要求:如果子类重写了父类的构造方法,那么子类的构造方法必须调用父类的构造方法。
子类的构造方法调用父类的构造方法有两种方式:
- 使用未绑定方法,这种方式很容易理解。因为构造方法也是实例方法,当然可以通过这种方式来调用。
- 使用 super() 函数调用父类的构造方法。
类的实例方法、静态方法和类方法区别及其应用场景
python 类语法中有三种方法,实例方法,静态方法,类方法。
实例方法
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:实例对象和类对象都可以调用。
静态方法
定义:使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:实例对象和类对象都可以调用。
实例方法
简而言之,实例方法就是类的实例能够使用的方法。
普通实例方法,第一个参数需要是self,它表示一个具体的实例本身。
如果用了staticmethod,那么就可以无视这个self,而将这个方法当成一个普通的函数使用。
而对于classmethod,它的第一个参数不是self,是cls,它表示这个类本身。
5.正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
基本概念参见 菜鸟教程 http://www.runoob.com/regexp/regexp-tutorial.html
6.re模块
Python 的re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 描述
group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 描述
group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0)
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:
re.compile(pattern[, flags])
参数:
pattern : 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和' # '后面的注释
当匹配成功时返回一个 Match 对象,其中:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:
findall(string[, pos[, endpos]])
参数:
string 待匹配的字符串。
pos 可选参数,指定字符串的起始位置,默认为 0。
endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
参数:
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
参数:
pattern 匹配的正则表达式
string 要匹配的字符串。
maxsplit 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’\t’,等价于 \t )匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}“不能匹配"Bob"中的"o”,但能匹配"foooood"中的所有o。"o{1,}“等价于"o+”。"o{0,}“则等价于"o*”。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a | b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (…), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#…) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 … 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \n, \t, | 等。 匹配一个换行符。匹配一个制表符, 等 |
| \1…\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
7.http请求
使用第三方库–requests
Requests 是用python语言编写的第三方库,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,完全满足 HTTP 测试需求,多用于接口测试,为了日后应用至工作中我便开始了学习
参考出处:https://www.jianshu.com/p/d78982126318
Request库方法介绍
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑一下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE |

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









