







grep
my @odd_numbers = grep {$_ % 2} 1..1000;上面一行代码即得到 500 个奇数。它是怎样工作的呢?grep 第一个参数是一个块,其中$_依次为列表中的每一个值,返回 一个 Boolean(true/false)值。剩下的参数是相应的列表。
grep 会首先计算表达式的值,这和 foreach 循环一致。如果块中最后 一个表达式的返回值为 true,则这个元素会被返回。 当 grep 运行时,$_会被设为列表中的值,一个接一个。
map 对列表项进行变换
map 操作和 grep 非常类似,因为它们有相同类型的参数:一个使用$_的块,以及一列需要处理的元素。
它们处理的方式也 是类似的,首先根据列表中的元素对块的值进行判断,每一次$_被赋予新的列表中的值。但使用块中最后一个表达式的值 的方法是不同的:不是返回一个 Boolean 值,而是最终值作为返回的结果◆。任何的 grep 或 map 语句均可以用 foreach 循 环重新书写,每一次将结果元素放入一个临时数组中。但短的方式通常更有效以及方便。由于 map 或 grep 的结果是列表, 因此它可以直接传递给另一个函数。因此我们可以将格式化后的货币数字打印出来,这些值是被缩进的:
my @data = (4.75, 1.5, 2, 1234, 6.9456, 12345678.9, 29.95);
print “The money numbers are:\n”,
map {sprintf(“%25s\n”, &big_money($_))} @datastat
my ($dev, $ino, $mode, $nlink, $uid, $gid, $rdev, $size, $atime, $mtime, $ctime, $blksize, $blockes) = stat($filename);
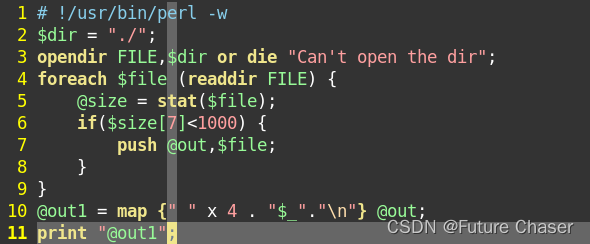
选取文件容量小于1000字节的文件,并转换列表中的字符串,在每个列表元素之前放置4个空格并且在之后放置换行符。最后输出结果列表。

















 7285
7285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









