



基于全同态加密的生物特征模板保护隐私保护方法
摘要
生物特征识别的迅速普及引发了人们对生物特征数据(模板)安全性和隐私性的日益关注。生物特征可唯一标识个体,且与密码不同,由于其对每个人都是唯一且固定的,因此无法被撤销或替换。为解决这一问题,已提出多种基于全同态加密的生物特征模板保护方法。然而,这些方法大多(i)计算成本高昂,实际应用不可行;(ii)不支持对实值生物特征特征向量进行无量化操作;(iii)不支持将实值特征向量打包进单个密文;(iv)需要用户多次注册以提升匹配性能。为克服这些局限性,我们提出一种基于全同态加密的生物特征模板保护的隐私保护方法。该方法计算高效、具备实际可行性,支持对实值特征向量进行无量化操作,并支持将实值特征向量打包至单个密文中。此外,所提方法采用单次注册方式完成用户注册。为评估该方法,我们使用了三个面部数据集:LFW、FEI 和佐治亚理工人脸数据集。加密人脸模板(针对 128维 特征向量)占用 32.8 KB 的存储空间,匹配一对加密模板耗时 2.83毫秒。与最先进的技术相比,所提方法在提供高模板安全性的同时,匹配性能提升了 ∼ 3%。
一、引言
术语生物特征识别被定义为基于个体独特的行为和生物特征进行自动识别(ISO/IEC JTC1 SC37)。行为特征(如语音、步态、签名等)以及生理特征(如人脸、虹膜、指纹等)均可用于唯一地识别个人。与密码、PIN码和磁条卡不同,生物特征不会丢失、共享或遗忘[1]。因此,生物特征识别不仅方便,而且可靠且稳健[2][3][4]。正因为如此,生物特征识别正越来越多地应用于消费电子、银行、医疗保健、执法等领域。然而,生物特征识别的广泛应用也引发了人们对生物特征数据安全性和隐私的日益关注。
典型的生物识别系统通过传感器获取用户的生物特征(如人脸、虹膜、指纹、语音、步态等)。所获取的生物特征数据经过处理以提取显著信息(高维特征向量)。在注册阶段,提取的特征向量与其身份标签一起存储在数据库中(作为模板 Tx)。在验证阶段,匹配模块接收两个输入:(i) 存储的模板(Tx) 和 (ii) 查询模板(Ty),并输出一个匹配分数S,用于衡量两个输入生物特征模板之间的相似性。如果匹配分数S大于某个阈值,则认为用户验证成功。
典型的生物识别系统存在许多易受攻击点[4]。最简单的攻击点是生物特征模板数据库。对存储在数据库中未受保护的生物特征模板进行攻击,可能导致:(a)已注册用户的隐私泄露;以及(b)现有认证系统的安全性受损。一些显著的滥用被盗未保护生物特征模板的情况包括:(i)从生物特征模板进行图像重建,以获得对系统的后续未授权访问[5][6][7][8]。此外,这些重建图像(特别是人脸图像)可用于以较高准确率预测已注册用户的年龄、性别、种族等[7],从而导致隐私泄露。(ii)交叉匹配或功能蔓延[9],即将生物特征模板用于非预期目的。例如,被盗的面部模板可用于搜索犯罪人脸模板数据库,或关联个人的健康记录。此外,一旦生物特征模板被泄露,将永久处于泄露状态。与信用卡和密码不同,生物特征无法被撤销和重新发放。因此,生物特征模板保护是亟需解决的最重要问题之一。
一种理想的生物特征模板保护方法应满足以下要求 [10][11][12]
1) 安全性:从受保护模板中重构已注册用户的原始生物特征模板在计算上应该是困难的。
2) 性能:使用生物特征模板保护方法不应降低生物特征系统的识别性能。
3) 可撤销性:应能够方便地撤销被泄露的生物特征模板,并生成新的受保护模板。
4) 多样性:应能够基于同一已注册用户的相同生物特征数据轻松生成不同的受保护模板。
最简单、安全且具有隐私保护性的生物特征模板安全解决方案是对生物特征模板应用密码学哈希函数(类似于密码),并在生物特征模板的密码学哈希上进行匹配。然而,由于生物特征数据中不可避免存在类内变化,即使生物特征数据发生微小变动,也会导致生物特征模板的密码学哈希完全不同,从而造成极差的识别性能。该问题可通过使用支持在加密数据上执行基本算术运算(如加法和/ 或乘法)的同态加密方案来解决。因此,可以使用这些方案对生物特征模板进行加密,并在加密模板上进行匹配。
同态加密方案可分为三类:(i)部分同态加密(PHE)方案——仅允许一种操作(加法或乘法),但对该操作的执行次数无限制;(ii)somewhat同态加密(SWHE)方案——允许有限次数的加法和乘法操作;(iii)全同态加密(FHE)方案——允许无限制地执行加法和乘法操作。
在本研究中,我们提出了一种基于全同态加密的生物特征模板保护的安全且隐私保护方法。该方法采用 Cheon‐Kim‐Kim‐Song(CKKS)全同态加密方案 [13][14]。我们在所有实验中选择人脸作为生物特征模态。在注册阶段,用户通过一次性注册方式进行注册。所提出的方法使用FHE对生物特征模板进行加密,并将加密后的模板存储在数据库中。在验证阶段,匹配模块接收(i)存储的加密模板和(ii)加密查询模板。匹配模块在加密模板上计算余弦相似度分数,从而生成加密的相似度分数。该加密分数被解密后,若超过某一特定阈值,则用户验证成功。该解决方案满足理想模板保护方法的所有要求,即(i)安全性(ii)性能(iii)可撤销性(iv)多样性。此外,所提出的方法还具有隐私保护性,因为它能够抵抗 [5][6][7][8][9]侵犯已注册用户隐私的攻击。由于所有计算均在加密数据上进行,因此全同态加密的生物特征模板无需被解密。
A. 贡献
我们工作的主要贡献总结如下:
(1) 我们提出了一种基于全同态加密的生物特征模板保护隐私保护方法。与[15][16][17],不同,本文所采用的 FHE方案具有以下优势:(a) 支持对浮点数进行运算。(b) 支持将实值特征向量打包到一个密文中。(c) 支持自举。(d) 无需量化方案即可获得最优结果。(e) 参数设置更简单。
(2) 该方法还采用一次性注册用户,其中每个受试者仅使用一张图像进行注册,其余图像用于认证。为了提高匹配性能,对注册用户的单张生物特征图像进行数据增强。
(3) 我们使用3个公共领域人脸数据集,即LFW、FEI和佐治亚理工人脸数据集来评估我们的方法。与最先进的技术相比,所提出的方法将匹配性能提高了 ∼ 3%,同时提供了高模板安全性。加密人脸模板(针对128维特征向量)需要32.8 KB的存储空间。此外,匹配一对加密模板需要2.83毫秒。
B. 相关工作
为了解决生物特征模板保护问题,已提出多种方法。这些方法可分为:(i) 生物特征加密系统;(ii) 基于变换的方法;(iii) 混合方法,结合生物特征加密系统与基于变换的方法;(iv) 基于同态加密的方法。
生物特征加密系统[18][19]要么将密钥(密钥绑定方案)安全地绑定到生物特征模板,要么从生物特征模板生成密钥(密钥生成方案)。基于生物特征加密系统的模板保护方法主要包括模糊承诺方案 [20][21][22][23]和模糊保险箱方案 [24][25]。这些方案使用纠错码来处理生物特征数据中的类内差异,但无法应对较大的类内差异,导致匹配性能较低。此外,生物特征加密系统中使用的纠错码要求生物特征特征向量具有特定格式,例如二进制字符串 [21],或有限范围的整数向量 [24]等。此类量化方法通常容易造成信息丢失,从而导致匹配性能下降。为了克服这一局限性,我们采用支持对浮点数进行计算且无需量化的全同态加密方案。此外,所提出方法中的FHE方案允许将实值特征向量打包到密文中。因此,该方法不仅时间和内存高效,而且提供了更好的匹配性能。
基于变换的方法使用变换函数将生物特征模板转换到新的域。这些方法可分为(i)加盐和(ii)不可逆变换 [11]。基于加盐的方法以用户特定密码(或密钥)和生物特征模板作为输入。每位注册用户使用不同的密码(或密钥),可确保变换后的模板具有较高的类间差异,从而增强模板的可区分性。常见的基于加盐的方法 [26][27] 使用随机投影将生物特征特征向量变换到另一个域。然而,加盐方法中使用的变换在很大程度上是可逆的,其安全性依赖于用户特定密码或密钥。与加盐不同,不可逆变换使用一种不可逆的变换函数,无需任何用户特定密码或密钥,将生物特征模板变换到新的域。常见的不可逆变换包括 [4][28][29]。但是,这些方法在匹配性能和安全性之间表现出权衡。相比之下,我们使用基于全同态加密的方法,该方法能够在对加密数据进行计算的同时,不对匹配性能产生任何影响。
混合方法结合了生物特征密码系统和基于变换的方法。较早的混合方法(如[10][30])表现出较低的匹配性能。较新的方法[31][32][33][34]使用卷积神经网络(CNN)来学习将生物特征特征向量映射到随机生成的二进制码的鲁棒方式。这些二进制码的密码学哈希代表了受保护的模板。然而,在这些方法中,深度CNN(在注册阶段训练)以未受保护的形式存储在服务器上,使其容易受到攻击。相比之下,所提出的方法存储加密的生物特征模板,并且所有计算(如匹配一对加密模板)都在加密域中进行。
同态加密方法对生物特征模板进行加密。加密后的模板存储在数据库中。在验证过程中,匹配模块计算加密存储模板与加密查询模板之间的相似度分数。因此,所有计算都在加密数据上进行。Upmanyu等人[35]使用部分同态加密(PHE)方案进行生物特征验证。但是,由于客户端与服务器数据库之间需要多轮通信来计算匹配分数,该方法存在较大的通信开销和计算复杂度。Barni等人 [36][37]使用PHE方案基于指形码模板进行指纹识别。该方法对查询模板进行加密,但未对数据库中存储的模板进行加密,因此无法保障生物特征模板的安全性。Cheon等人[38]使用somewhat同态加密(SWHE)方案在加密域内对二值虹膜模板进行匹配。然而,该方法仅适用于二进制比特串,不适用于实值模板。Troncoso‐Pastoriza等人[39]使用全同态加密(FHE)进行人脸识别验证。然而,[39]计算成本较高,因为加密模板大小为380兆字节,且计算两个加密模板之间的相似度分数耗时约100秒。Boddeti[40]采用计算效率较高的Fan‐Vercauteren [17] FHE方案进行人脸匹配,以克服上述局限性。然而,[17]不支持将实值特征向量打包到一个密文中。为了支持打包,该方法通过量化将实值特征向量编码为整数,精度为2位小数。在本研究中,我们使用的FHE方案不同于 [17],,能够直接支持将实值特征向量打包至密文,而无需特定的量化方案。此外,与[40],不同,本文提出的方法采用一次性注册方式。
II. 方法
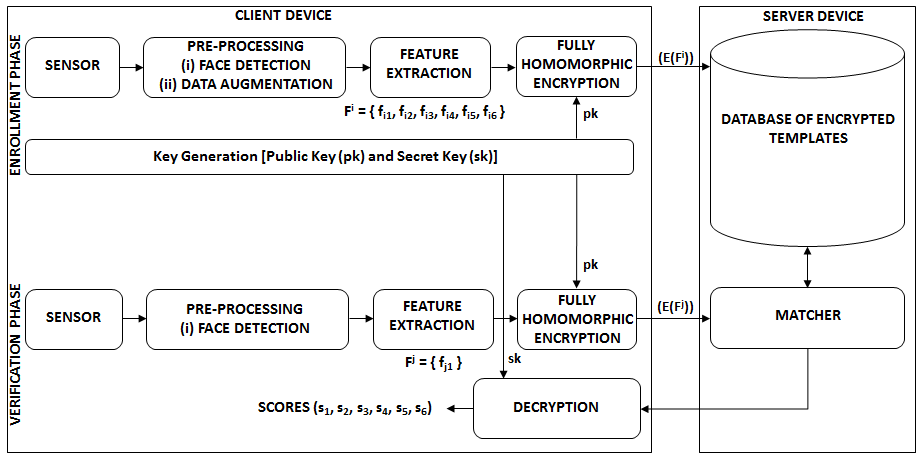
在本节中,我们将描述所提出的用于生物特征模板保护的全同态加密(FHE)方法的各个组成部分。如图1所示。
A. 传感器
传感器捕捉用户的面部图像。在单次注册中,仅使用用户的一张人脸图像进行注册,其余图像用于验证。
B. 预处理
(i) 人脸检测 :传感器获取的每张图像都会经过人脸检测算法[41]以检测图像中的人脸。检测到的人脸将被调整为160×160大小的图像并保存。
(ii) 数据增强 :在注册阶段,仅使用用户的一张人脸图像进行注册。为了提高匹配性能,我们对该用户的一张人脸图像进行数据增强,以生成更多的人脸图像。我们使用Keras图像数据生成器API,通过缩放、水平翻转、重新缩放、旋转和改变剪切角等操作,生成5张增强后的人脸图像。对于每张大小为x×x的增强人脸图像,我们提取所有可能的大小为y×y的裁剪图像,其中y< x。这样总共得到 6×(x‐ y+1)×(x‐y+1)张增强后的人脸图像。x的值为160,y选择为158。在注册阶段,每个用户仅使用一张图像(一次性注册)进行注册。对该图像进行人脸检测。检测到的人脸被调整为 160×160图像并保存。如上所述,对这个 160×160检测到的人脸图像执行数据增强。为了提高所提出方法的时间和空间效率,我们从增强后的人脸图像中随机选择6张图像用于注册。在验证阶段,传感器获取的图像会经过人脸检测以输出一个 160×160检测到的人脸图像。然而,在验证阶段不进行数据增强。
C. 特征向量提取
我们使用预训练的FaceNet模型[42]进行特征向量提取。该预训练的FaceNet模型在MS‐Celeb‐1M数据集 [43]上进行训练。FaceNet模型的输入为 160×160人脸图像,输出为一个128维的实值特征向量。
归一化表示 :输出的特征向量使用单位向量归一化进行归一化处理。此后,归一化后的特征向量简称为特征向量。这些特征向量在加密域中用于余弦相似度计算,如II‐F节所述。
注册期间,从用户的增强图像中随机选择6张图像(如II‐B节所述)。因此,在注册期间,对于任意用户(例如i th),使用六个128维特征向量(fi1 ,fi2 ,fi3 ,fi4 ,fi5 ,fi6 )。在验证期间,对于任何声称的身份(例如 j th),仅有一个128维特征向量(f j 1 ),因为未执行数据增强(如II‐B节所述)。
D. 全同态加密(FHE)
同态加密允许我们对数据进行加密,并在无需将加密数据解密为明文或访问用于解密的私钥的情况下对加密数据进行计算。这使得用户可以使用全同态加密(FHE)对数据进行加密,并将其发送给另一方进行计算,而不会泄露其输入数据的隐私。首个全同态加密(FHE)方案由盖内特提出[44],,但它存在许多固有的挑战,限制了其在实际应用中的实用性。自那以后,出现了许多全同态加密方案[14][15][16][17]。在HEAAN中实现的CKKS方案 [14]是最具代表性的FHE方案,因其易于使用、对浮点运算的高效支持以及对高效打包和自举的支持而著称。
我们简要描述作为CKKS FHE方案安全基础的带误差环学习问题( RLWE)。
1) 带误差环学习(RLWE) :所有运算均在环 R 和模 q 下进行。对于整数 N 和q,令 R= Z[x]/(x N + 1) 和 Rq = R/qR。设 χ 为定义在 Rq 上的误差分布。对于给定多项式 s ∈ R q ,我们定义带误差环学习(RLWE)分布 RLWE q ,χ,s 如下:
RLWE q ,χ,s =(b, a) ∈ R 2 q : a ← U(Rq) , e ← χ, b= a.s+ e
这里 U(Rq) 表示在 R q 上的均匀分布。带误差环学习问题(RLWE)是区分 R 2 q 中的均匀分布与RLWE分布。
2) CKKS-HEAAN : 设 R= Z[x]/(x N + 1) 和 RQ =Z Q [x]/(x N + 1),其中 Q和 N均为2的幂。该方案中使用的分布如下:
• 对于实数 σ> 0, DG(σ2) 是指在 ZN中的分布,其每个分量均来自方差为 σ2的离散高斯分布
设 HWT(h)表示{−1, 0, 1}N中汉明重量为 h的向量集合,其中 h为某个整数。
• ZO(ρ) 是在 {−1, 0, 1} 中的分布,对于某些实数 0 ≤ ρ ≤ 1,每个分量分别为1 或 −1 的概率是 ρ/2,为0 的概率是1 − ρ。
密文位于多项式环 R2 Q 中,而私钥则从 HWT(h) 中随机选取。注意, Q 和 N 由目标电路的深度和安全性参数 λ 共同决定。
• 参数 给定整数 L 和安全性参数 λ,设置 Q= P= 2L,选择一个2的幂次整数 M,一个整数 h,以及一个实数 ρ>0,用于具有 λ 位安全性的RLWE问题。
• 私钥样本 S(x) ← HWT(h) 并令 sk=(1, s(x)) 为私钥。
• 公钥 样本 a(x) ← R Q ,以及 e(x) ← DG(σ 2 )。令 pk=(b(x) a(x)) ∈ R 2 Q 为公钥,其中b(x) =− a(x)s(x) +e(x)(mod Q)。
• 加密 要加密消息 m,需计算一个整数多项式 m(x) =encode( m,pBits)。对 v(x) 进行采样,使其服从 ←ZO (0.5),并采样 e 0 , e 1 ← DG(σ 2 )。返回 (b(x) a(x))=v(x)。pk+(m(x) + e 0( x) e 1( x))mod Q。 pBits 是缩放因子,用于在加密过程中将浮点数转换为定点数以进行算术运算。此处 e 0 和e1 是与密文相关的噪声项,每次加密时均随机采样。
• 解密 对于形式为 c 的给定密文 = (b(x) a(x)),计算 m(x)=b( x)+ a(x).s(x)mod Ql 对于 Ql= 2l。返回一个向量 m= decode(m(x) pBits)。
方法 encode() 和 decode() 分别用于将消息(数字)转换为明文的复数形式以及逆向转换。
FHE方案允许对密文执行加法、乘法等操作。然而,由于每个密文固有的噪声,即 e0和 e1,我们只能执行有限次数的操作。这是因为每次密文加法都会使底层的噪声项相加,而每次乘法都会使底层的噪声项相乘。这意味着噪声在加法操作中呈线性增长,而在乘法操作中呈指数增长。
设 c1和 c2分别为加密消息 m1和m2的密文。则密文上的加法和乘法运算如下进行:
• add(c1, c2) 返回 c3=(b1(x)+b2(x) a1(x)+a 2(x) ∈R2 Ql 。注意,此处 c3 是 m1+ m2 的 加密。
• Mult(c1, c2) 计算 c3=(d0, d1, d2)=(b1(x)b2(x) ,a1(x)b2(x)+ a2( c3=) b1(x) a1(x)a2(x)) ∈ R3 Ql 。 c3 通过使用 密钥 将一个三部分的 密文 (d0, d1, d2) 转换为两部分的 密文 (b3(x) a3(x))。注意,此处 c3 是 m1 ◦ m2 的 加密。两个 密文 的 缩放因子 在 密文 乘法 过程中也会相乘,并且可以通过 rescale 操作进行控制。
为了解决噪声问题,采用自举技术,该技术使我们能够降低噪声以支持更多操作。如果计算是固定的,则可以将密文的噪声预算设置为刚好满足计算需求。这种同态加密模式称为 leveled HE。
E. 密钥生成
用于全同态加密的密钥(公钥(pk)和私钥(sk))通过设置以下参数生成:
1) 单个密文中打包的数据点数量,用n表示。
2) 多项式模数,用N表示。
3) 计算精度位数,用log p(pBits)表示。
4) 完成计算所需的噪声预算位数,用logQ表示。
根据输入大小(即数据集中的值或数据点数量),我们可以确定打包所需的最小槽数(表示为n)。n的值应为2的幂,因此将其设置为大于或等于输入大小的最小2的幂。为了将多个输入(例如m)批量打包到单个查询中,则需满足 n ≥ m×(单个输入的大小),并四舍五入到最近的 2的幂。多项式模数至少应为 2×n。log p定义了浮点算术计算的精度,通常对于大多数应用而言,取值在20至 30之间已足够。log Q定义了噪声预算,这对应于对密文所需执行的操作次数(特别是乘法操作)。用于计算余弦相似度,我们只需要一次乘法,因此logQ可以设置为大约120的很低值。现在,参数已定义,我们可以生成密钥。
在注册阶段,为每个注册的用户生成密钥对(公钥 (pk),私钥(sk))。公钥用于在注册和验证阶段加密特征向量。
在验证阶段,使用待验证用户的私钥来解密匹配器通过计算两个加密的人脸模板之间的相似度分数生成的匹配分数。
加密API用于加密128维特征向量。但是,同态加密会增加内存需求,因为密文空间远大于明文空间。因此,对每个输入特征向量的每个元素进行加密并不是一个可行方案,因为它将消耗大量内存。为解决此问题,全同态加密方案支持将多个元素打包到单个密文中。与仅支持整数元素打包的同态加密算法[15][16][17]不同,本工作所采用的FHE方法支持在无需量化方案的情况下将浮点数元素打包到单个密文中。此外,我们还可以将多个特征向量打包到单个密文中。
在注册阶段,使用被注册用户的公钥来加密该用户的128维特征向量。在注册时,每个用户经过数据增强后共有六幅图像(如II‐B中所述),因此在注册阶段每个用户有六个128维特征向量。这六个特征向量使用该用户的公钥进行加密,输出为一个打包密文。
在验证阶段,使用待验证用户的公钥对用户的128维特征向量进行加密。该128维特征向量被复制六次,得到一个大小为 6 × 128的向量。该向量被加密后形成用于用户认证的查询。
F. 匹配器
匹配器计算加密的存储生物特征模板与加密的探测模板之间的余弦相似度。加密模板由打包密文表示。在打包密文的情况下,所有底层明文元素上的操作以单指令多数 据 (SIMD) 的方式进行。然而,打包不允许我们访问单个元素。例如,我们有两个向量[a,b,c]和[1,2,3]。将这两个向量分别打包进其对应的密文后,无法访问向量中的各个元素(如a,b,c,1,2,3)。但是,可以在这些打包密文上执行乘法和加法等操作。
计算两个打包密文(对应于两个128维归一化特征向量)之间的相似度分数包含128次乘法和128次加法。在加密域中的匹配是在已注册用户的打包密文(表示对应于六个单位归一化特征向量的六个加密模板)与待验证用户的打包密文(表示一个加密模板)之间进行的。因此,匹配模块输出对应于一次验证尝试的六个加密相似度分数的向量。
G. 解密
匹配模块生成的六个加密相似度分数的向量使用待验证用户的私钥sk进行解密。该操作在用户端的客户端设备上的可信执行环境(TEE)内完成,因为用户不希望直接共享其私钥。TEE 提供了一种在隔离区(即安全计算区域)内使用用户私钥解密结果的方法,然后发布结果。如果六个分数(s1,s2,s3,s4,s5,s6)中有s个高于某一阈值,则认为该用户验证成功,其中s可根据具体应用决定。
III. 实验
在本节中,我们描述了用于评估我们工作的 人脸数据集 、 评估指标 和 实验参数 :
A. 设置
实验是在一台配备有2.4 GHz主频的英特尔至强 Gold处理器、64GB内存和32核的服务器上进行的。全同态加密库的所有参数均配置为至少提供80位安全性。
B. 数据集
我们在实验中使用了以下公共领域人脸数据集:
1) 野生标注人脸(LFW)[45] 数据集包含5749个受试者的13233张图像。在5749个受试者中,1680个受试者有2张或更多图像,其余4069个受试者仅有1张图像。这些图像表现出姿态、光照和表情的变化。在单次注册中,我们为每个受试者随机选择一张图像用于注册,其余图像用于认证。
2) FEI数据集[46] 包含200个受试者的2800幅彩色图像。每个受试者有14幅图像,具有最多约180度的侧面旋转,同时包含光照和表情的变化。我们在实验中使用每个受试者的9幅图像(图像03、图像04、图像05、图像06、图像07、图像08、图像11、图像12、图像13)。在单次注册中,我们为每个受试者随机选择一张图像用于注册,剩余8幅用于认证。
3) 佐治亚理工人脸数据集 [47] 包含50个受试者的750幅彩色图像。每个受试者有15幅图像,具有姿态、光照和表情的变化。在单次注册中,我们为每个受试者随机选择一张图像用于注册,而剩余14幅则用于认证。
C. 评估指标
我们采用不同错误接受率(FAR)下的真实接受率(GAR)作为评估指标。由于训练集和测试集的划分是随机生成的,因此我们报告了5次不同训练测试划分下GAR在不同FAR处的平均值。
IV. 结果
在不同数据集上的实验结果如表1所示。我们还评估了未加密的人脸模板上的人脸匹配性能,用于对比。对于LFW [45]数据集,我们实现了86.58%@0.01%错误接受率的 GAR(正确接受率)、94.28%@0.1%FAR(错误接受率)和96.10%@1.0%FAR(错误接受率)。对于FEI[46]数据集,我们实现了99.33%@0.01%误识率的GAR、99.96% @0.1%FAR和99.99%@1.0%FAR。对于佐治亚理工学院 [47]人脸数据集,我们实现了75.40%@0.01%FAR的 GAR、98.37%@0.1%FAR和99.97%@1.0%FAR。值得注意的是,基于加密的人脸模板的人脸匹配性能与基于未加密的人脸模板的人脸匹配性能相当。因此,显而易见,所提出的方法不仅提供了模板保护,而且保护了用户的隐私。
| 数据集 | @0.01%FAR(错误接受率) | @0.1%FAR(错误接受率) | @1%FAR |
|---|---|---|---|
| LFW[45] | 86.58% | 94.28% | 96.10% |
| LFW 45 | 86.58% | 94.28% | 96.10% |
| FEI[46] | 99.33% | 99.96% | 99.99% |
| FEI 46 | 99.33% | 99.96% | 99.99% |
| 佐治亚理工学院 [47] | 75.4% | 98.37% | 99.97% |
| 佐治亚理工学院 47 | 75.4% | 98.37% | 99.97% |
表一 来自不同数据集的验证结果,注册类型:一次性注册
如表二所示,我们将我们的方法与Boddeti的[40]安全人脸识别方法在LFW数据集上进行了比较。[40]使用了三种不同的量化方案(针对128维人脸特征向量的每个元素),精度分别为0.1、0.01和0.0025。其中,采用精度为0.0025的量化方案获得了最佳的匹配性能。值得注意的是,即使采用一次性注册,本文提出的方法在FAR为0.01%时仍达到了86.58%@0.01%错误接受率的 GAR,优于[40]报告的84.05%@0.01%错误接受率。当 FAR增加到0.1%时,我们达到94.28%的GAR,与[40]报告的94.56%@0.1%错误接受率相当。然而,当FAR增加到1.0%时,所提出的方法获得的GAR略低,为96.10%,而[40]报告的GAR更高,达到98.65%@1.0%错误接受率。
| 方法 | 注册 | 量化 | GAR@0.01%FAR | GAR@0.1%FAR | GAR@1%FAR | 时间(毫秒) |
|---|---|---|---|---|---|---|
| 安全匹配[40] | 多镜头 | 2.5x10⁻³ | 84.05% | 94.56% | 98.65% | 10 |
| 安全匹配[40] | 多镜头 | 1.0x10⁻² | 83.89% | 94.53% | 98.66% | 10 |
| 安全匹配[40] | 多镜头 | 1.0x10⁻¹ | 78.82% | 92.58% | 98.35% | 10 |
| 我们的方法 | 一次性 | None | 86.58% | 94.28% | 96.10% | 2.83 |
表二 在LFW[45]数据集上与其他算法的性能比较
如表三所示,我们将我们方法的结果与Jindal等人在FEI数据集上的结果进行比较。[32]使用深度卷积神经网络进行人脸模板保护。值得注意的是,本文提出的方法在FAR为0.01%时达到了 99.33%@0.01% FAR的更高GAR,相比之下,[32]报告的 GAR为96.05%@0.01% FAR。
本文提出的方法需要32.8 KB的存储空间来存储一个加密人脸模板。该大小的产生是因为浮点数需乘以缩放因子以转换为定点运算,这导致加密密文产生额外的内存需求。本文提出的方法在匹配一对加密人脸模板(针对128 维特征)时耗时约2.83毫秒,而[40]在匹配一对加密人脸模板(针对512维特征)时耗时约10毫秒。在本研究中,加密域中的匹配(如II‐F节所述)是在已注册用户的打包密文(表示对应六个单位归一化特征向量的六个加密模板)与待验证用户的打包密文(表示一个加密模板)之间进行的。因此,本文提出的方法一次验证耗时约17毫秒。
| 方法 | 注册类型 | GAR@FAR |
|---|---|---|
| 深度CNN [32] | 一次性 | 96.05%@0.01%FAR |
| 我们的方法 | 一次性 | 99.33%@0.01%FAR |
表三 在FEI[46]数据集上与其他算法的性能比较
A. 安全性分析
使用同态加密进行生物特征模板保护的所提出的方法在诚实但好奇的安全模型下是安全的(在此模型中,所有参与方均诚实地执行注册和验证步骤,且仅能获知自身的输出结果)。在此安全模型下,通信信道(客户端与服务器之间)能够抵御攻击者的攻击,因为信道中仅传输加密内容(无论是加密的人脸模板还是加密匹配分数),而这些内容在没有私钥的情况下无法被访问。同样,服务器上的数据库也能够抵御攻击,因为它仅存储加密的人脸模板,这些模板在没有私钥的情况下也无法被访问。用户无法篡改认证结果,因为客户端设备在隔离区内解密结果并公布。然而,客户端设备的安全性至关重要,因为它可访问正在注册用户的原始人脸图像和提取的特征向量。
B. 理想生物特征模板保护的要求
我们的方法满足理想生物特征模板保护的全部四项要求。
- 安全性 :由于受保护模板是实际生物特征的全同态加密密文,其安全性完全依赖于全同态加密的安全性。我们的加密方案至少提供80位安全性。
- 性能 :本文提出的方法在加密人脸模板上进行的人脸匹配性能与在未加密的人脸模板上的匹配性能相当,并且比最先进的生物特征模板保护方法高出 ∼ 3%。
- 可撤销性 :当用户的生物特征信息泄露时,该用户的生物特征模板可以轻松地被撤销。这可以通过对用户原始生物特征的取反结果进行加密,并将所得密文添加到服务器存储的受保护模板中来实现。另一种简单的方式是为用户生成一组新的公钥和私钥密钥对。
- 多样性 :FHE即使对相同的消息每次也会生成唯一的密文。因此,我们可以为同一用户获得不同的生物特征模板。此外,还可以生成新的公钥和私钥密钥对,从而为同一用户生成不同的加密受保护模板。
V. 结论与未来工作
在本研究中,我们提出了一种基于全同态加密的生物特征模板保护的安全且隐私保护方法。我们采用一个全同态加密方案,该方案支持(i)对实值特征向量的操作以及(ii)将实值特征向量打包到密文中的功能。所提出的方法具有实际可行性,每个加密人脸模板(针对128维特征向量)仅需32.8 KB的存储空间。此外,匹配一对加密模板仅需2.83毫秒。另外,与最先进的技术(使用多镜头注册用户)相比,所提出的方法(使用一次性注册用户)使匹配性能提升了 ∼ 3%,同时提供了高模板安全性。我们计划扩展本工作,通过引入算法改进进一步提升匹配性能、时间和空间效率。

















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









