




 本文是上手机器学习系列的第三篇中篇,介绍如何使用Scikit-learn实现Logistic回归,并探讨数据来源、编码、模型结果评估方法,包括准确率、查准率、查全率、F1-Score和AUC。通过实例展示了混淆矩阵的计算和模型性能的综合评价。
本文是上手机器学习系列的第三篇中篇,介绍如何使用Scikit-learn实现Logistic回归,并探讨数据来源、编码、模型结果评估方法,包括准确率、查准率、查全率、F1-Score和AUC。通过实例展示了混淆矩阵的计算和模型性能的综合评价。
书接上回
在第3篇(上)中,笔者介绍了自己对于logistic回归是咋来的这一问题的思考。本文中篇让我们一起实战一下。用Python中的机器学习大杀器Scikit-learn来跑一个小任务。未来在下篇中,我们还会继续带领大家通读一遍sklearn的logistic回归源代码。
数据来源
本小节我们直接使用scikit-learn中自带的二分类数据集,通过以下方式可以导入:
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y=True)
这里return_X_y=True参数是可以直接就把数据集拆成特征集与标签集,默认是False,所以我们这里显式的指定。
编码
不管是什么算法包,只要不是我们自己写的,都要先研究一下对方接口的文档,看看人家的使用说明。即使同样的logistic回归算法包,在不同软件平台的实现上也是不同的,各有各的数据格式要求。
sklearn中LogisticRegression的使用文档详见:
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
从官方接口的格式来看,有很多需要配置的参数。不过不要怕,大部分参数都有默认值,我们了解了每个参数的意义后,对于不需要显示给定的参数,省略即可。
class sklearn.linear_model.LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
下面就直接开始应用logistic回归吧:
#导入LogisticRegression算法包
from sklearn.linear_model import LogisticRegression
#对数据进行标准化处理
from sklearn import preprocessing
X_scaled = preprocessing.scale(X)
#拆分训练集与测试集
#sklearn自带了train_test_split可以快速将数据进行随机拆分,可一次性返回多个数据集
from sklearn.model_selection import train_test_split
#下面得到的X_train,X_test分别表示对特征变量拆分后的训练集与测试集,Y_train,Y_test代表对标签变量拆分后的训练集与测试集
X_train,X_test,Y_train,Y_test = train_test_split(X_scaled,y,test_size=0.2,random_state = 0) #test_ratio指定测试集数据量的占比,random_state是为了保证实验可复现,如果不指定数值,下一次运行随机拆分的数据未必就是本次的结果了
#好了,现在创建一个logistic回归的算法实例,并把它应用到训练集上进行训练吧
clf = LogisticRegression(random_state=0).fit(X_train,Y_train)
#当上面这个fit执行完成后,模型就训练好了,只在到了clf中,我们后面就可以用clf来对未知的数据集进行分类预测了
#clf.predict就可以把上面训练好的模型应用到测试集上
predict = clf.predict(X_test)
这里咱们把上述过程再拆解一下:
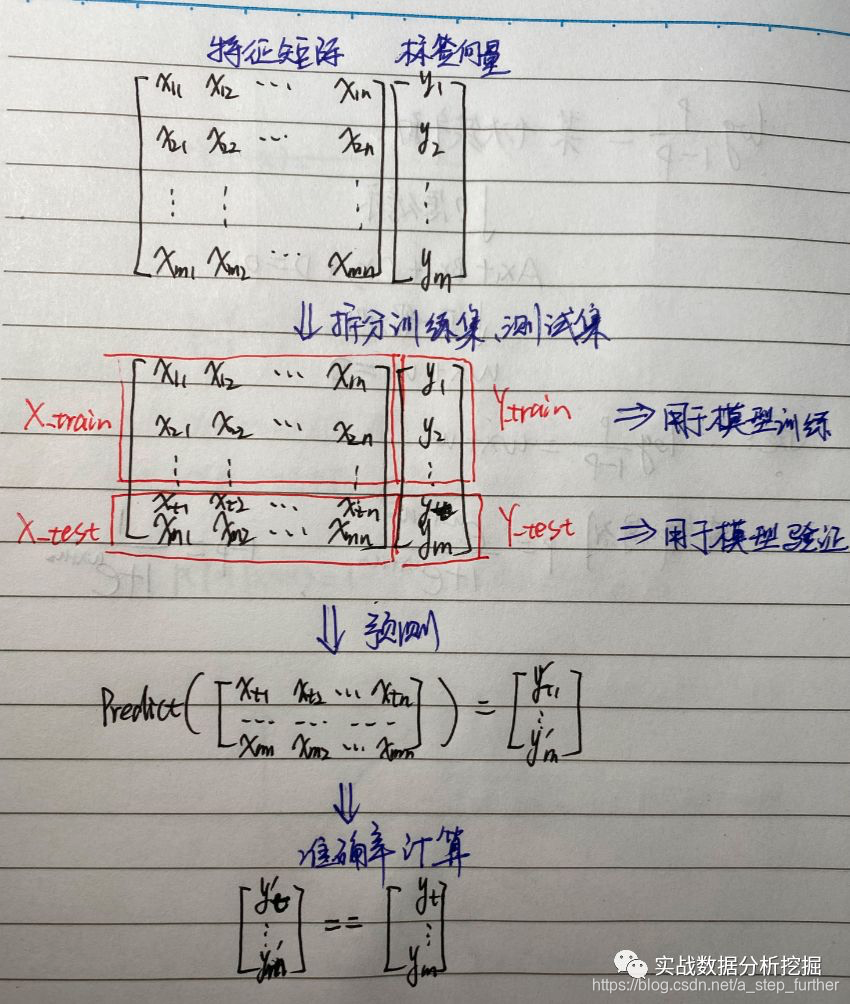
然后就可以计算准确率喽,先手工算一下:
right = 0
for i in range(0,len(predict)):
if predict[i] == Y_test[i]:
right += 1
print("分类准确率为 %f" % (1.0*right/len(Y_test))) #这里乘以1.0是为了把数据转成浮点型
结果得到0.964912,即96.49%的准确率,还不错。
其实,在sklearn中,也有一个现成的函数可以用于计算准确率:即存在于sklearn.metrics中的accuracy_score,我们也可以直接使用该函数来计算上述模型的准确率,看是否与我们自己手工计算的结果一致:
from sklearn.metrics import accuracy_score
accuracy_score(Y_test,predict)
答案显示:0.9649122807017544,前6位有效数字都是一样的,说明结果一致。
更专业的模型结果评估方法
上面我们计算了模型分类的准确率,即预测值=真值的数据量在总测试集数据量中的占比,别忘了数据本身有真假之分,而对于真、假的准确评估有可能重要性是不同的!例如如果需求是根据人物特征来预测其是否恐怖分子,那么误判一个人,可能就仅仅是多花了成本就预防灾难发生,但如果预测错误,OH,MY GOD!可能就是又一架被绑架的飞机了。再比如,根据医学图像来识别是否存在肿瘤,对于真假的预测准确度也是结果迥异的,权重并不应该相等。这一点也可以联想到假设检验中学到的弃真错误、采伪错误等说法。
事实上,在企业实际工作中,很多人会经常提到模型的“准确率”(注意这里的准确率不同于上文)、“覆盖率或者召回率”,比如在风控领域,如果我们建立模型来识别存在金融诈骗的账号,那么准确率往往是说在我们识别为坏人的集合中,有多少是真正的坏人;覆盖率是说大盘中(全量账号中)有多少坏人,我们的模型可以抓到其中多少人。
对于二分类来说,我们可以得到下面这样一个数据结果,很多书上叫做“混淆矩阵”:
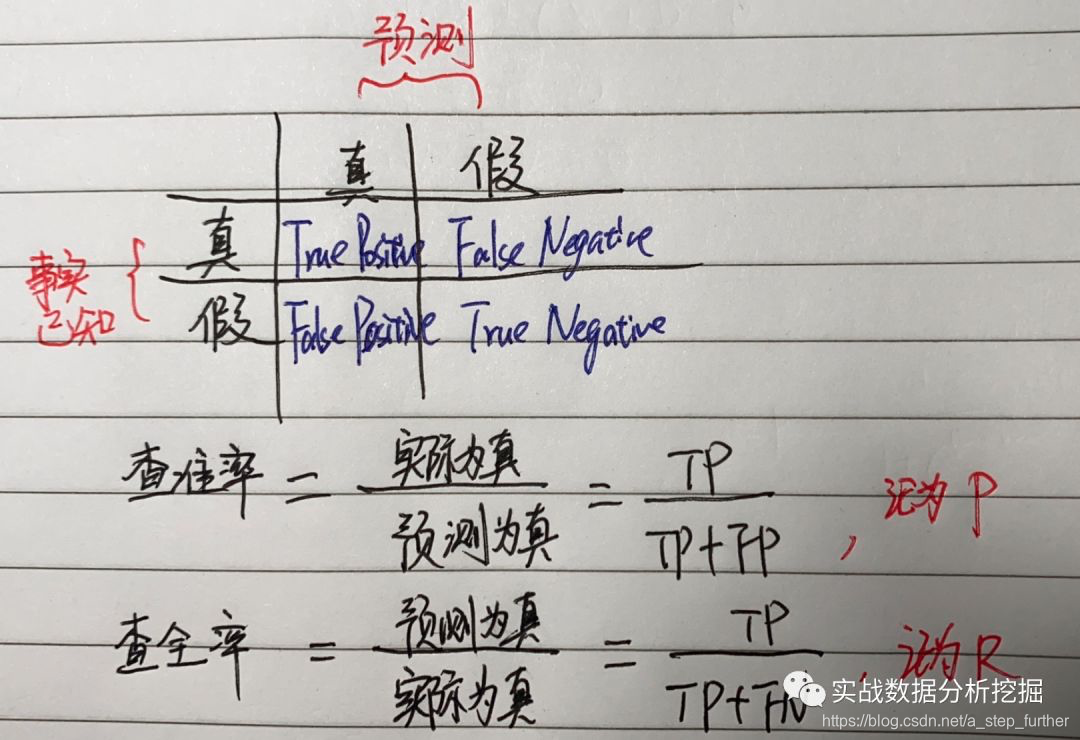
这里的P其实就对应了我们上文提到了预测为真的结果中,有多少是事实上也为真的比例;R对应了覆盖率。直观想来,要想提升准确率,有可能预测为真的集合越小越好,例如我只预测3个账号为存在欺诈的坏人,那极有可能全是对的(大不了是我人肉挖出来的账号嘛!),那么P就是100%了。但R呢,可能现实在有1万个坏人的账号,但你只找到了3个,那查全率R就是万分之三。反过来,如果我的账号集合总量是10万,我无脑地把所有账号全部分类为坏人,那么查全率就是100%了嘛,因为所有的坏人全都被我误别出来了;但P呢,就只有10%了。所以在实操中这两个指标往往是有一些冲突的。但逻辑上,这两个值也有可能同时达到100%,例如我精准地把所有坏人找了出来,不冤枉一个好人。
一般地,可以用一个综合性的指标来进行衡量,这里就轮到F1-Score出场了。
就像一个和事佬一样,F1就是把查准率与查全率进行了综合;而且还可以用不同的权重来综合。

如果我们使用同一个模型在多个数据集上进行训练(这种场景往往发生在需要对比多个模型,可以在不同规模的数据集上进行效果评估),那么就会得到多个混淆矩阵,这时可以通过求平均值的方式得到一个综合的模型评估,而两种
不同求平均值的方式的就分别得到了macro-F1、micro-F1。其中macro-F1是分别针对每个混淆矩阵求P,R,然后最终求一个P的平均值,R的平均值,再拿来计算F1;micro-F1则是对不同混淆矩阵对应的元素求平均值,最均得到一个平均值的混淆矩阵,再用该矩阵来计算F1。目前在学术论文中,micro-F1使用更多。
使用sklearn可以如下这样计算:
from sklearn.metrics import f1_score
print("Micro-F1: %f" % f1_score(Y_test,predict, average='micro'))
print("Macro-F1: %f" % f1_score(Y_test,predict, average='macro'))
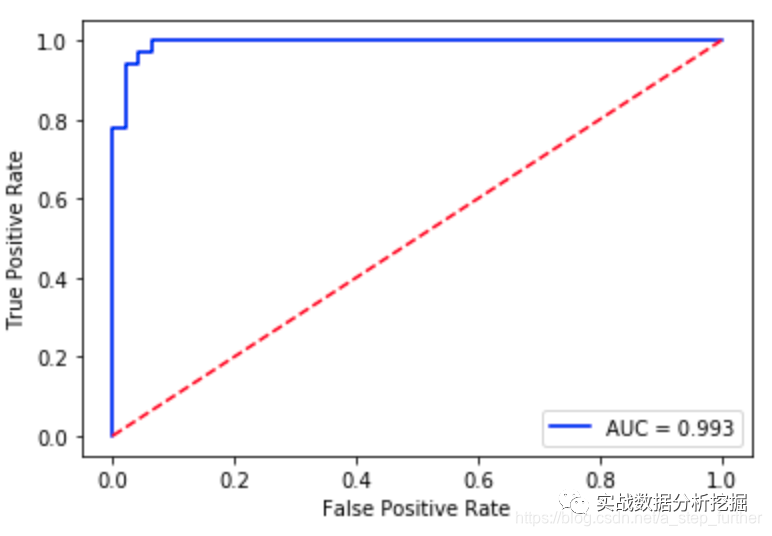
另外还有一个常用的就是AUC(表示ROC曲线下的面积), 代码可以这样写:
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(Y_test,y_prob[:,1]) #这里y_prob[:,1]这样写是因为y_prob预测的结果其实是两列,第一列是每个样本分类为0的概率,第二列是分类为1的概率
roc_auc = auc(fpr, tpr) #auc为Roc曲线下的面积
print("ROC 曲线下面积: %f" % roc_auc)
#开始画ROC曲线
import matplotlib.pyplot as plt
plt.plot(fpr, tpr, 'b',label='AUC = %0.3f'% roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.show()
小结
至此我们用一个简单的案例初步跑了一个logistic回归,以及模型评估的过程,也知道了怎么去调用sklearn中的包。再下一次,我们会实际去读一下sklearn中logistic回归的源代码,看看底层是怎样实现的。敬请继续关注本人公众号后续推送文章。


















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









