






一、系统相应外部请求步骤
系统响应外部请求的完整步骤:
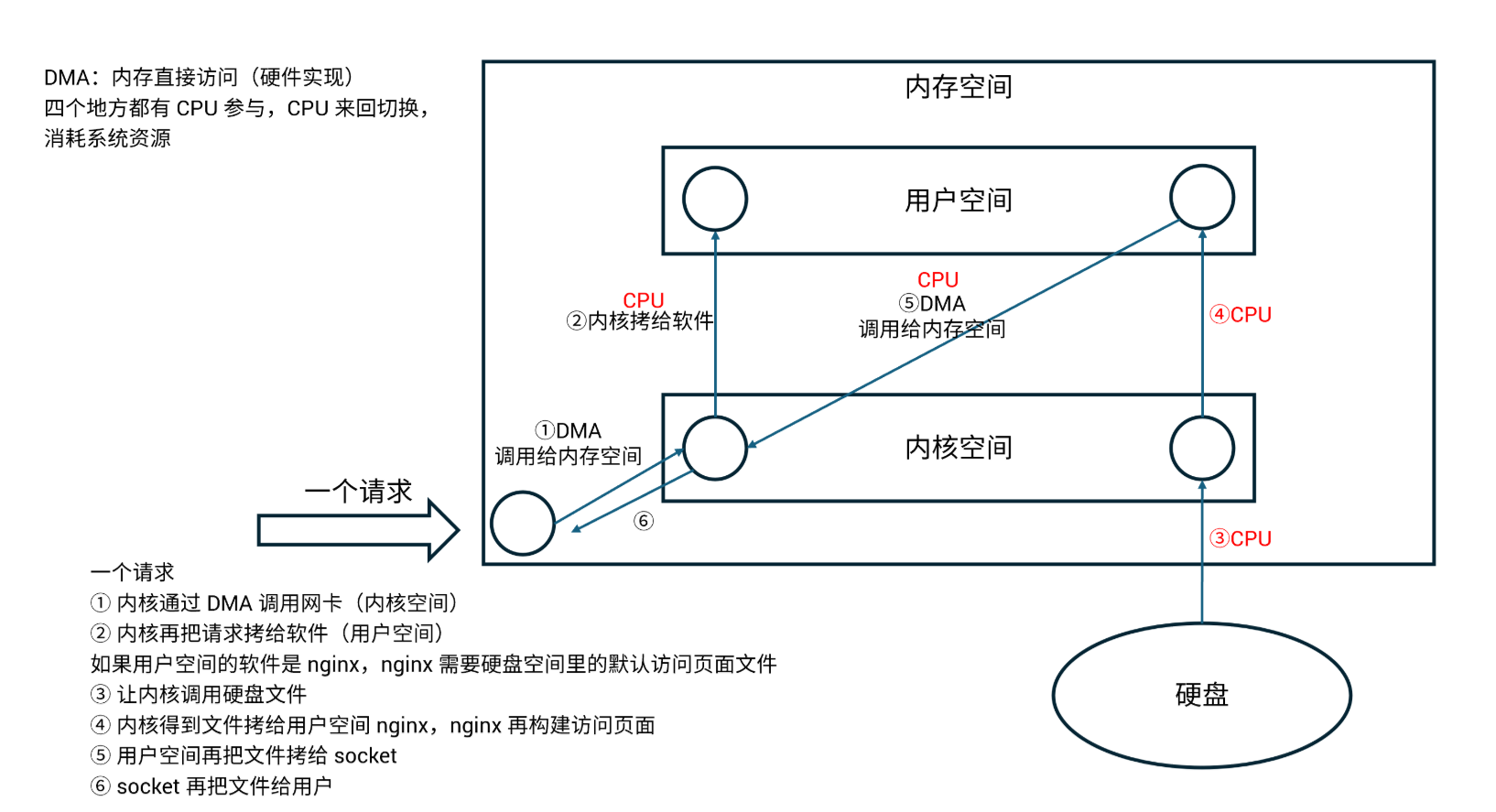
缺点:
-
数据从硬盘空间加载到内核空间(缓冲区),等待时间较长
-
数据从内核空间拷贝到用户空间,时间较短
二、I/O 模型相关概念
2.1.同步/异步
-
同步:内核准备好数据后,不通知用户空间自己已准备好,需要用户自己询问
-
异步:内核准备好数据后,通知用户空间自己已准备好

2.2.阻塞/非阻塞
-
阻塞:用户通知进程自己需要磁盘里的文件,进程需要内核从磁盘当中取文件,取文件的过程中,进程等待
-
非阻塞:用户通知进程自己需要磁盘里的文件,进程需要内核从磁盘当中取文件,取文件的过程中,进程不等待
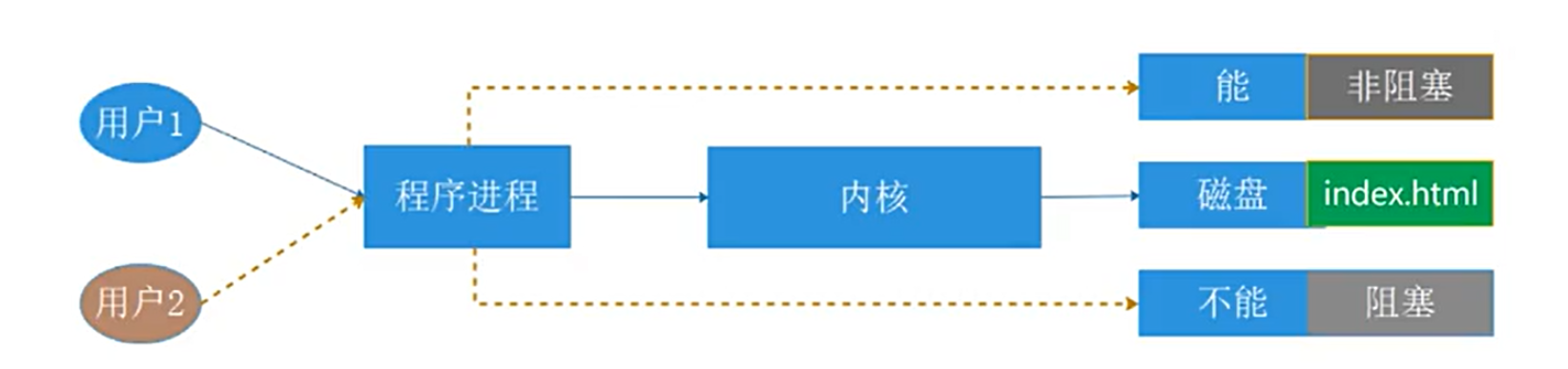
apache 是典型的同步阻塞模式
-
优点:稳定
-
缺点:慢
三、网络 I/O 模型
3.1.阻塞型 I/O 模型(blocking IO)
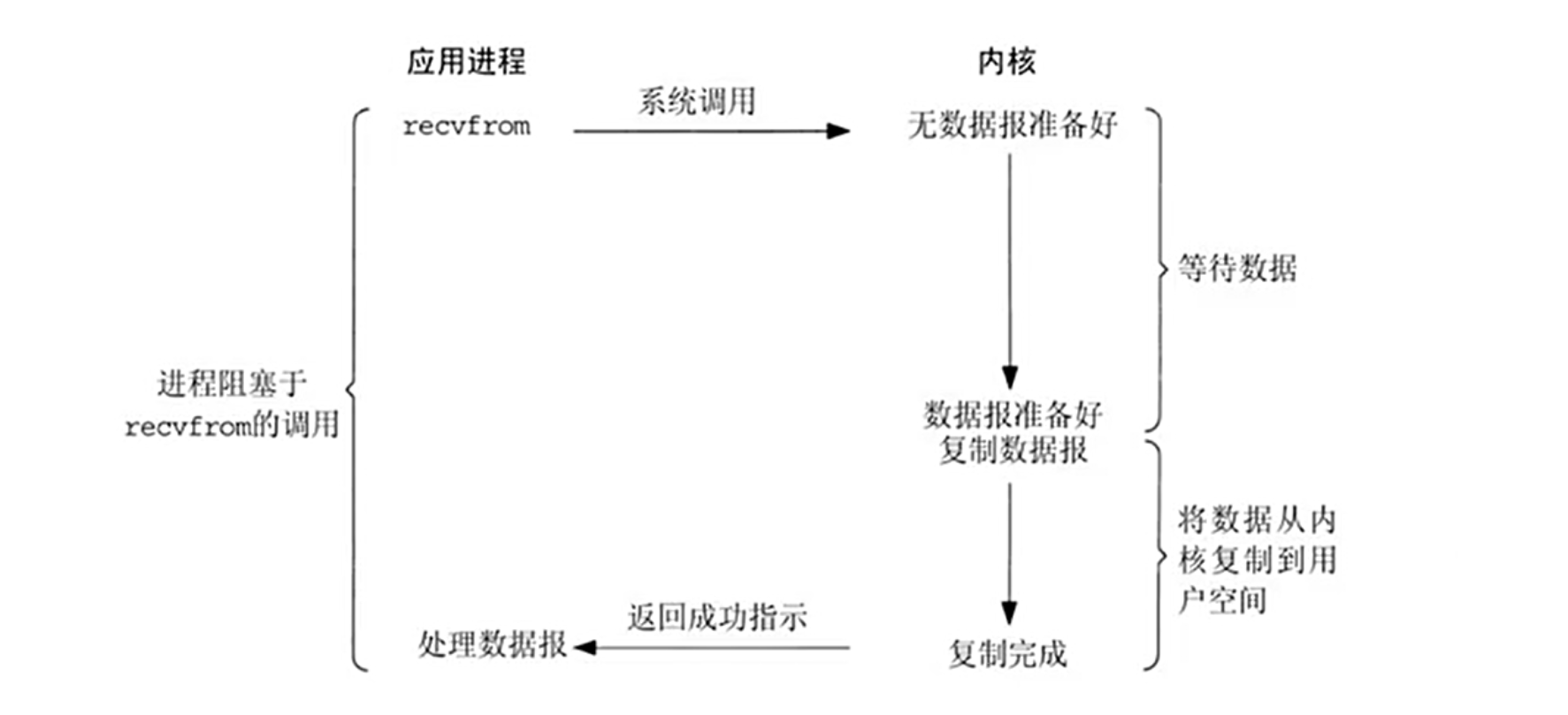
阻塞型 I/O 应该是最简单的,当应用程序发起 I/O 操作时,会一直等待直到数据准备好或完成传输。例如,当调用 recv() 函数时,如果没有数据可读,进程会一直阻塞在那里,直到有数据到达。这种模型的问题在于效率低,尤其是在高并发场景下,因为每个连接都需要一个线程或进程来处理,资源消耗大。
阻塞型 I/O(Blocking I/O)
-
原理: 应用程序发起 I/O 操作后,线程会完全阻塞,直到数据准备好并被复制到用户空间。
-
过程:
-
调用 recv() 等待数据到达内核缓冲区。
-
内核数据就绪后,将数据复制到用户空间。
-
复制完成后,线程恢复执行。
-
-
特点:
-
简单易用,但资源利用率低(线程被阻塞无法处理其他任务)。
-
适用于低并发场景(如单线程顺序处理)。
-
3.2.非阻塞型 I/O 模型(nonblocking IO)
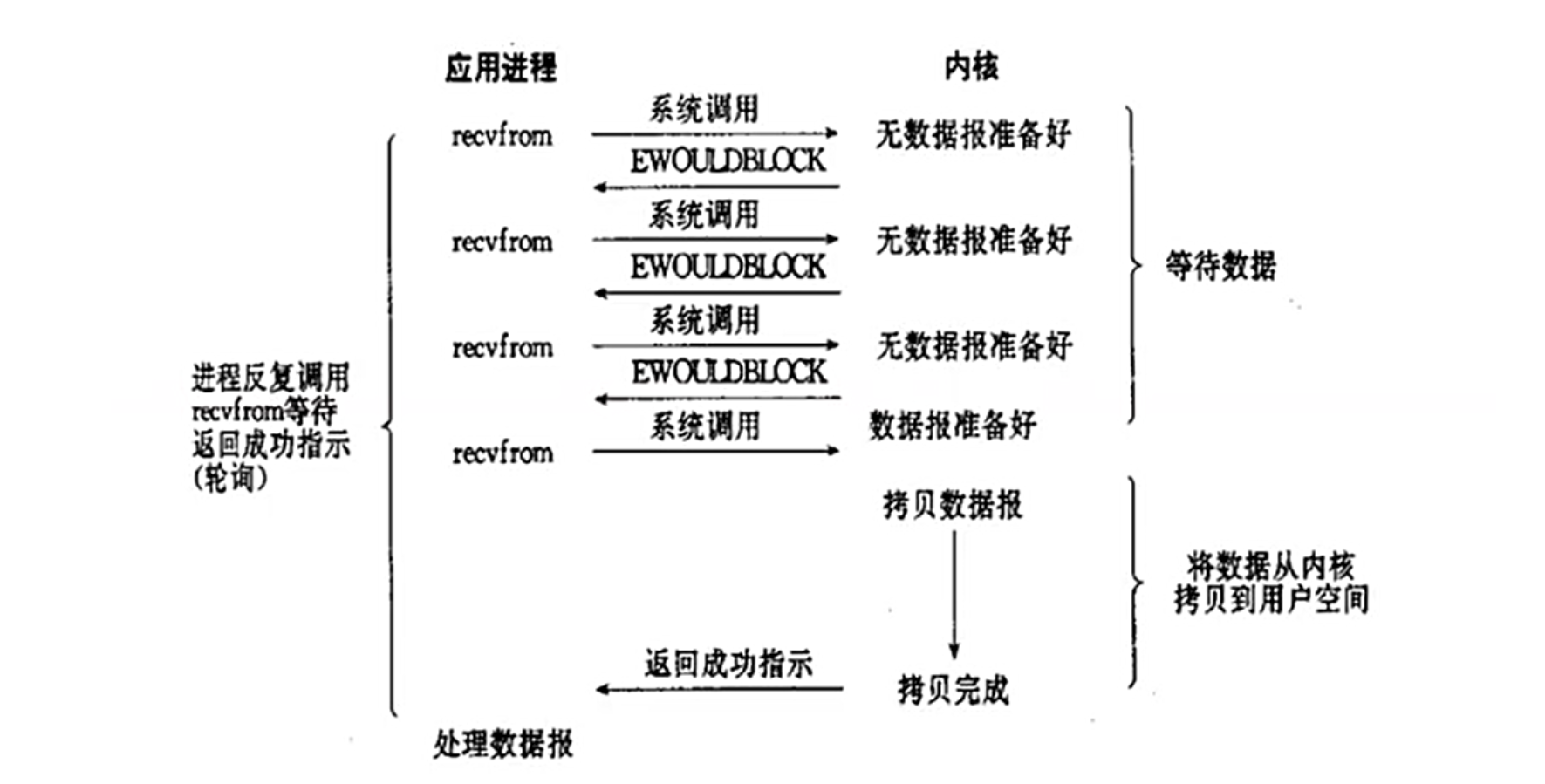
非阻塞型 I/O 应该是应用程序发起 I/O 操作后立即返回,不会阻塞进程。如果没有数据准备好,函数会返回一个错误码,比如 EAGAIN 或 EWOULDBLOCK,进程可以继续做其他事情,然后不断轮询检查状态。这种方式虽然避免了阻塞,但需要不断轮询,可能消耗 CPU 资源,特别是在没有数据的时候,空转会浪费处理能力。
非阻塞型 I/O(Non-blocking I/O)
-
原理: 应用程序发起 I/O 操作后立即返回,通过轮询检查操作是否完成。
-
过程:
-
调用 recv() ,若数据未就绪,返回 EWOULDBLOCK 错误。
-
应用程序循环重试,直到数据就绪并完成复制。
-
-
特点:
-
避免线程阻塞,但需高频轮询,CPU 占用率高。
-
适合轻量级任务或需要即时响应的场景(如游戏服务器心跳检测)。
-
3.3.信号动式 I/O 模型(signal-driven IO)
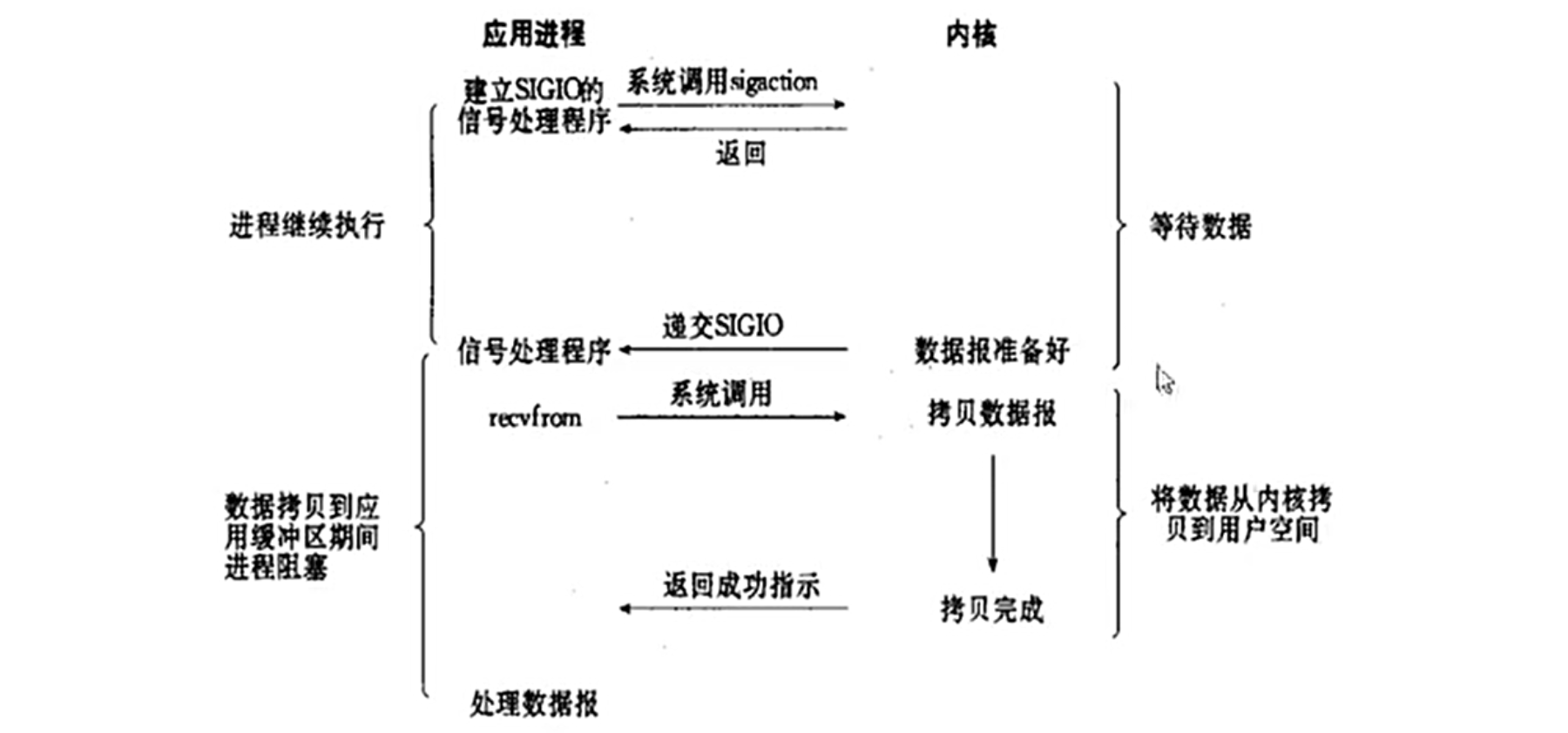
信号驱动 I/O 可能是指应用程序发起 I/O 请求后,注册一个信号处理函数,当数据准备好时,内核会发送一个信号(比如 SIGIO),然后应用程序再去处理数据。这种方式不需要轮询,而是通过信号通知,但信号处理本身可能比较复杂,且信号队列溢出时可能丢失通知,可靠性需要关注。
信号驱动 I/O(Signal-driven I/O)
-
原理: 应用程序注册信号处理函数,内核在数据就绪时发送信号(如 EIGIO)通知。
-
过程:
-
通过 fcntl() 设置文件描述符的信号驱动标志。
-
数据就绪时,内核发送信号触发回调函数。
-
应用程序在信号处理函数中读取数据。
-
-
特点:
-
减少轮询开销,但信号处理复杂度高,且信号可能丢失。
-
适用于低频率 I/O 操作(如串口通信)。
-
3.4.异步 I/O 模型(asynchronous IO)
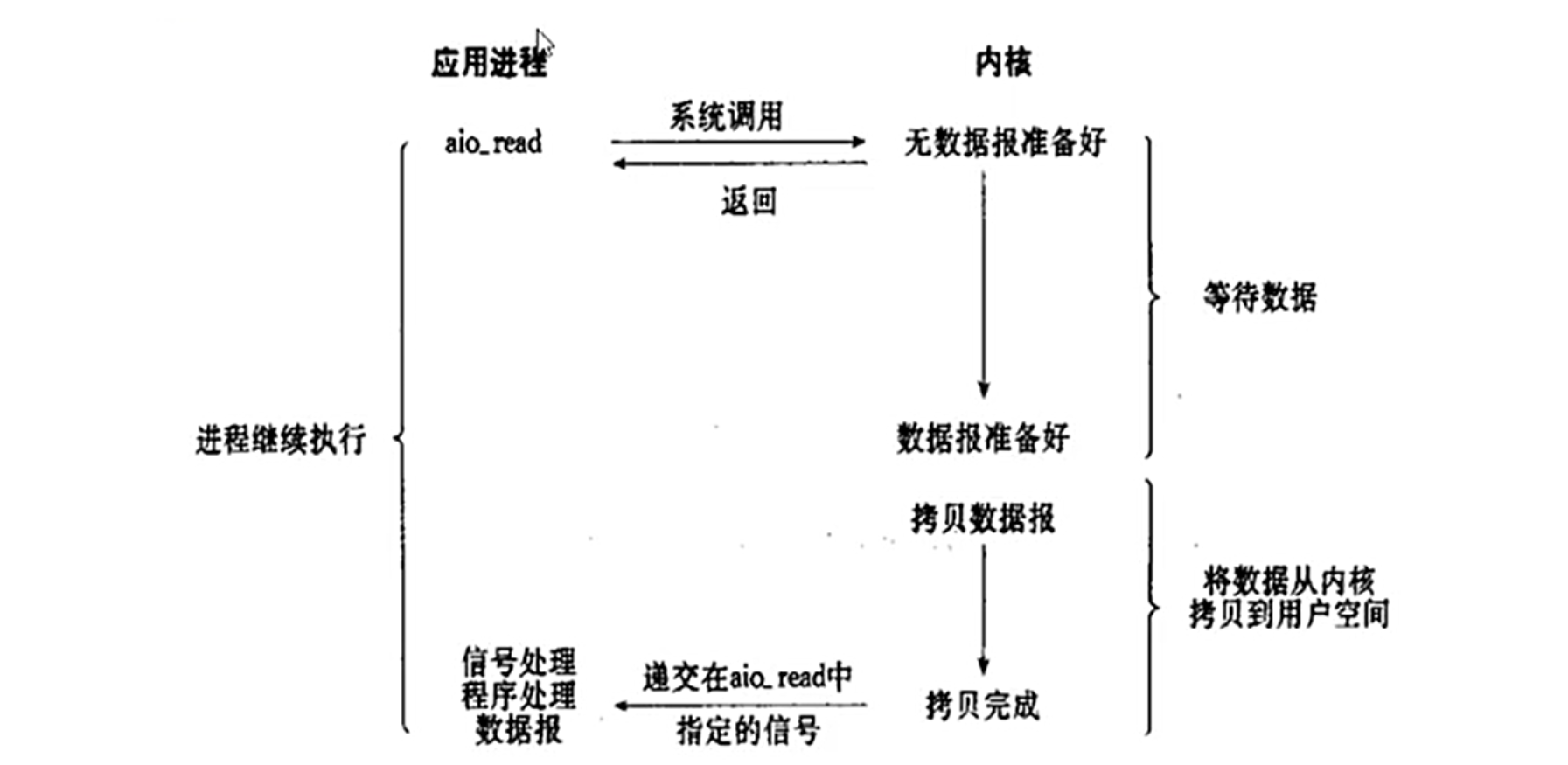
异步I/O则是应用程序发起I/O操作后立即返回,内核负责整个操作,完成后通过回调函数或者其他机制通知应用程序。比如在Linux中,aio_read函数。这种模型真正实现了非阻塞,应用程序不需要等待,也不需要进行轮询或处理信号,只需要在操作完成后处理结果即可。不过实现起来可能较为复杂,且不同平台的异步I/O支持程度不同,比如Windows的IOCP和Linux的AIO可能有差异。
异步 I/O(Asynchronous I/O)
-
原理: 应用程序发起 I/O 操作后立即返回,内核完成所有操作(包括数据复制)后通知应用。
-
过程:
-
调用 aio_read() 提交异步请求。
-
内核完成数据准备和复制后,通过回调或信号通知应用。
-
应用程序直接处理用户空间的数据。
-
-
特点:
-
真正的非阻塞,无轮询或等待。
-
实现复杂,且平台支持差异大(如 Linux AIO vs Windows IOCP)。
-
适用于高性能存储系统(如分布式文件系统)。
-
3.5.多路复用 I/O 模型(I/O multiplexing)
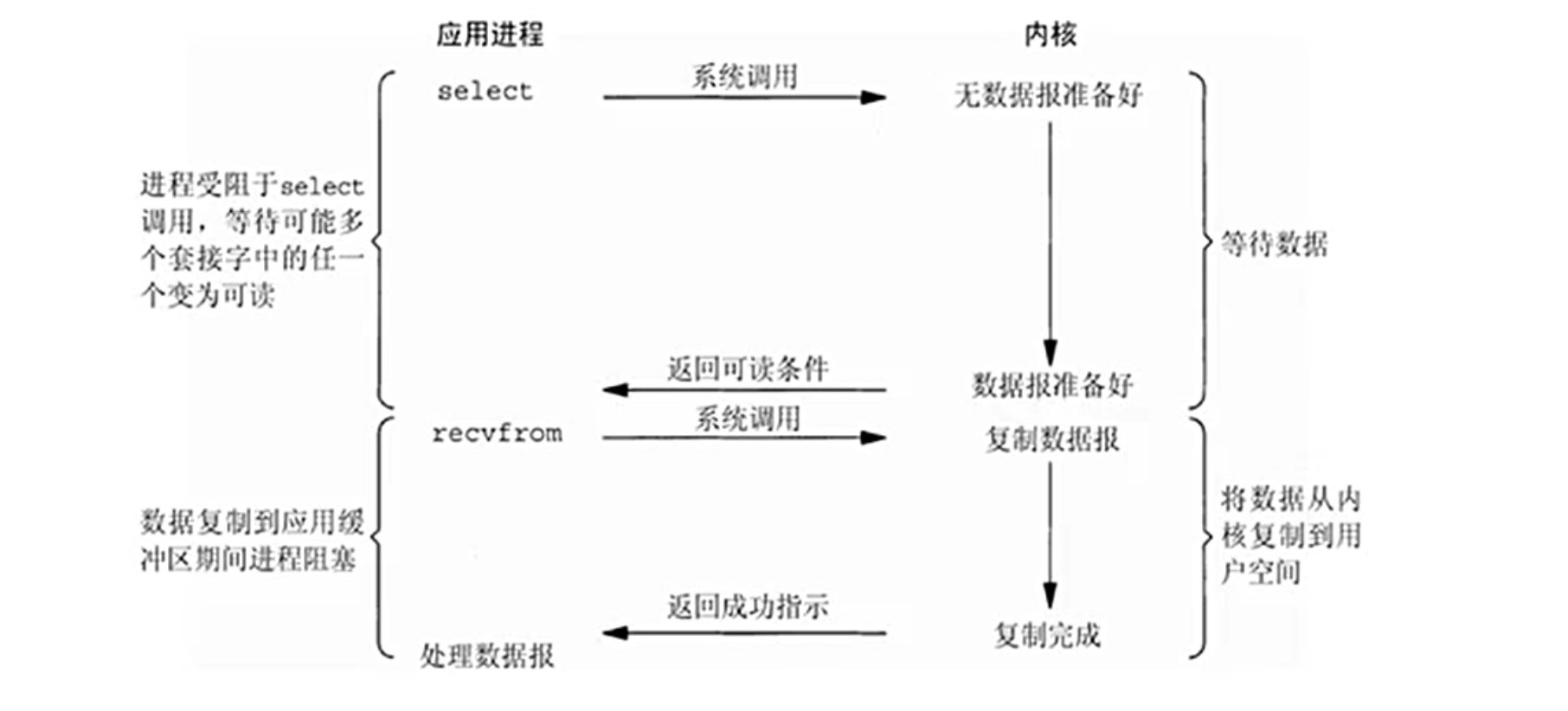
多路复用 I/O,比如 select、poll、epoll 等,应用程序通过一个系统调用监控多个文件描述符的状态,当其中任何一个就绪时,系统调用返回,应用程序再处理就绪的 I/O。这种方式减少了线程或进程的数量,提高了并发处理能力。尤其是 epoll,使用事件驱动的方式,避免了轮询所有描述符,效率更高。但多路复用本身还是同步的,因为实际的 I/O 操作(如 recv)还是需要应用程序主动调用。
多路复用 I/O(I/O Multiplexing)
-
原理: 使用 select、poll、epoll 等系统调用监控多个描述符,当任一描述符就绪时返回。
-
过程:
-
调用 epoll_wait() 阻塞等待就绪事件。
-
内核返回就绪的描述符列表。
-
应用程序遍历处理就绪的 I/O 操作。
-
-
特点:
-
高并发支持,单线程可处理数千连接。
-
实际 I/O 操作(如 recv)仍是同步的。
-
适用于 Web 服务器(如 Nginx)、数据库连接池。
-
| 对比维度 | select | poll | epoll |
|---|---|---|---|
| 最大描述符数量 | 有限制(通常 1024) | 无限制(受系统内存限制) | 无限制(百万级支持) |
| 时间复杂度 | O(n)(每次遍历所有 fd) | O(n)(同上) | O(1)(仅处理活跃 fd) |
| 内存开销 | 低(位图存储) | 高(需维护结构体数组) | 中(内核维护红黑树) |
| 事件注册方式 | 每次调用需重新传入 fd 集合 | 每次调用需传入完整数组 | 通过 epoll_ctl 动态增删(一次注册多次使用) |
| 跨平台支持 | 所有主流系统(POSIX 标准) | 多数 UNIX 系统 | 仅 Linux(2.6+) |
| 性能 | 低(高并发下效率差) | 中(优于 select,但弱于 epoll) | 高(尤其活跃连接少时) |
概念:
-
select:select 库是一种事件驱动模型库,在 Linux 和 Windows 平台基本都受支持,接口定义也大致相同,只是部分参数含义稍有差异。它是早期的事件驱动模型,最大并发限制为 1024。
-
poll:poll 是 Linux 平台的基本驱动模型,Windows 不支持。它是 select 的升级版,取消了最大并发限制。在编译 Nginx 时,可通过
--with - poll_module和--without - poll_module这两个参数,指定是否编译该库。 -
epoll:epoll 库是 Nginx 服务器所支持的高性能事件驱动库之一,被公认为非常出色的事件驱动模型。它与 select 和 poll 区别较大,虽可看作是 poll 的升级版,但处理方式独具特色。epoll 会创建一个待处理事件列表并交给内核,返回时轮询检查该列表以判断事件是否发生。epoll 支持的一个进程打开的最大事件描述符上限,是系统可打开的文件最大数。而且,epoll 库的 I/O 效率不会随描述符数目增加而线性下降,因其仅对内核上报的 “活跃” 描述符进行操作。
优缺点:
1. select
-
优点:
-
跨平台兼容性强(Windows、Linux、macOS 均支持)。
-
实现简单,适合少量连接场景。
-
-
缺点:
-
最大描述符限制(FD_SETSIZE 通常为 1024)。
-
每次调用需重置 fd 集合,存在内存拷贝开销。
-
线性遍历所有 fd,时间复杂度高。
-
2. poll
-
优点:
-
突破 select 的 fd 数量限制。
-
支持更多事件类型(如 POLLRDHUP)。
-
-
缺点:
-
仍需要遍历所有 fd,性能未本质提升。
-
大量空闲连接时,效率显著下降。
-
3. epoll
-
优点:
-
高效事件通知:仅返回就绪的 fd,时间复杂度 O(1)。
-
边缘触发(ET)模式:减少重复事件通知,提升吞吐量。
-
内存复用:通过 epoll_ctl 动态管理,避免重复拷贝。
-
-
缺点:
-
仅限 Linux 平台。
-
编程复杂度较高(需处理 ET 模式下的非阻塞读写)。
-
需求
-
小型项目/跨平台需求:
- 使用 select 或 poll(优先 poll)。
-
高并发 Linux 服务:
- 必须选择 epoll(Nginx、Redis 等均依赖)。
-
实时性要求高:
- 使用 epoll 的 边缘触发(ET)模式 + 非阻塞 I/O。
3.6.模型对比与核心区别
| 模型 | 同步/异步 | 阻塞阶段 | CPU 利用率 | 适用场景 |
|---|---|---|---|---|
| 阻塞型 | 同步 | 全程阻塞 | 低 | 简单应用、低并发 |
| 非阻塞型 | 同步 | 仅数据复制阶段阻塞 | 高(轮询) | 即时响应任务 |
| 信号驱动型 | 同步 | 无阻塞(信号触发) | 中 | 低频事件驱动 |
| 多路复用型 | 同步 | 等待就绪阶段阻塞 | 高(高效处理) | 高并发服务(Nginx) |
| 异步型 | 异步 | 无阻塞 | 高(无轮询) | 高性能存储、大规模 I/O |
3.7.关键区别总结
-
同步 vs 异步:
-
同步:应用程序需主动参与数据就绪后的读写操作(如
recv)。 -
异步:内核完成所有操作后通知应用,应用仅处理结果。
-
-
阻塞阶段:
-
阻塞型:全程等待。
-
非阻塞/多路复用:仅在数据复制阶段可能阻塞。
-
异步:全程无阻塞。
-
-
编程复杂度:
-
阻塞型最简单,异步型最复杂(需处理回调或信号)。
-
-
性能与扩展性:
-
多路复用和异步模型适合高并发场景,阻塞型受限于线程/进程数。
-
3.8.经典应用场景
-
阻塞型:命令行工具(如 curl)。
-
多路复用:Nginx、Redis。
-
异步型:Windows IOCP、Linux AIO(数据库日志写入)。
-
信号驱动:嵌入式设备通信。
总结:选择合适的 I/O 模型需权衡并发需求、开发复杂度和平台支持。多路复用是当前高并发服务的首选,而异步 I/O 是未来高性能系统的趋势。
3.9.五种 I/O 总结
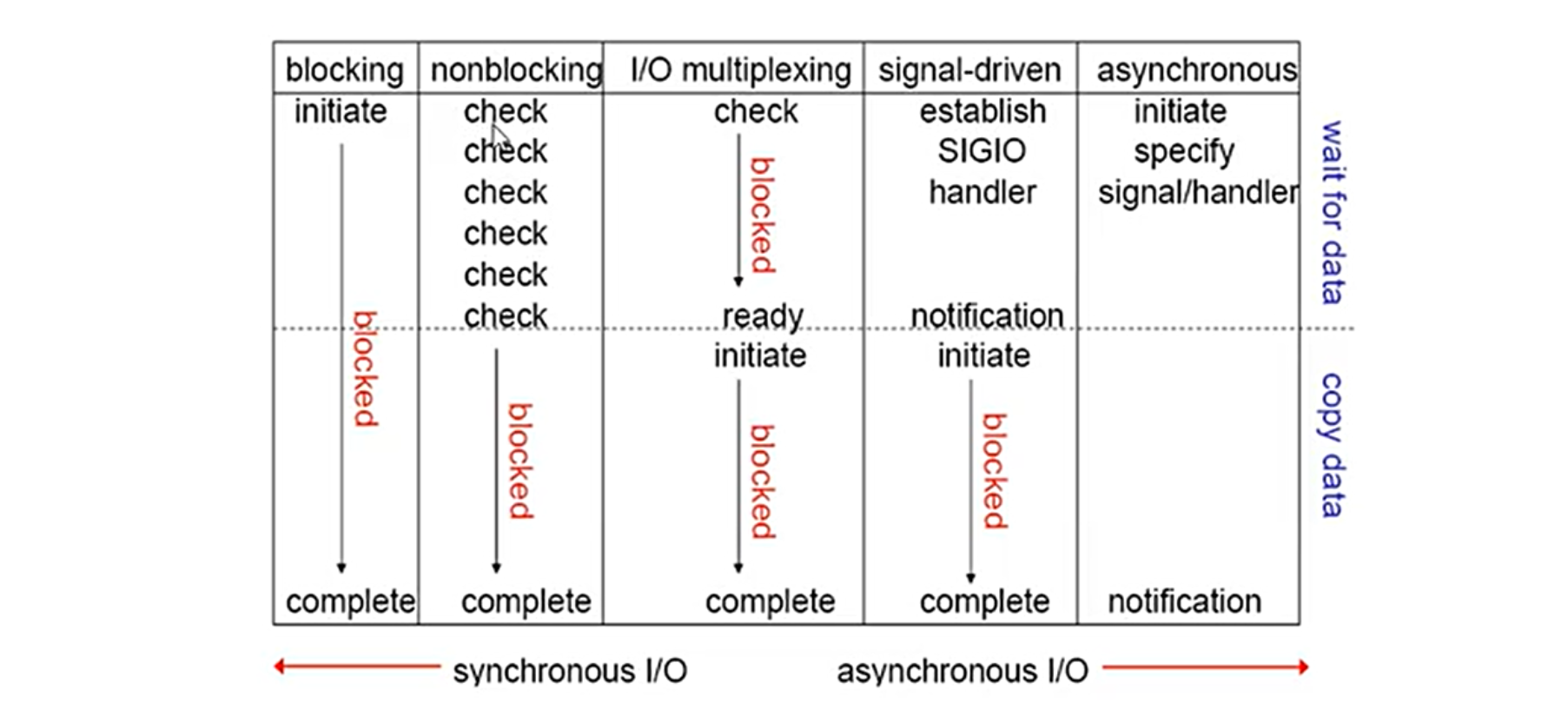
这五种 10 模型中,越往后,阴寒越少,理论上效率也是最优前四种属于同步 10,因为其中真正的 /0 操作(recvfrom)将阻塞进程/线程,只有异步 1/0 模型才与 POSIX 定义的异步 I/0 相匹配
-
apache 用的是同步阻塞 nonblocking
-
nginx 用的是异步非阻塞 asynchronous
3.10.面试题
从网络I/O模型的方面讲,apache和nginx的区别是什么,什么时候选择apache为什么选择apache,什么时候选择nginx为什么选择nginx
1. 网络 I/O 模型的核心差异
| 特性 | Apache | Nginx |
|---|---|---|
| I/O 模型 | 多进程/多线程(阻塞式 I/O) | 事件驱动(异步非阻塞 I/O + 多路复用) |
| 并发处理 | 每个连接独占进程/线程 | 单线程/少量进程处理数万并发连接 |
| 资源消耗 | 高(内存和 CPU 随连接数线性增长) | 低(内存占用固定,CPU 高效利用) |
| 适用场景 | 动态内容处理、模块化扩展需求 | 高并发静态资源、反向代理、负载均衡 |
-
选择 Apache:
-
需要直接嵌入动态语言解释器(如传统 PHP 应用)。
-
依赖
.htaccess实现目录级动态配置。 -
项目依赖 Apache 特有模块(如
mod_rewrite复杂规则)。
-
-
选择 Nginx:
-
高并发场景(如电商大促、直播平台)。
-
静态资源服务、API 网关、微服务入口。
-
资源受限的云环境或容器化部署。
-
-
混合使用:
-
用 Nginx 处理静态请求和负载均衡,Apache 处理动态请求。
-
平衡性能与功能扩展性。
-
无论哪一个模型,最终都有信息的浪费(数据的三次拷贝),所以需要减少数据的拷贝次数,使 CPU 负载变低,速度变快,引入下面的零拷贝
四、零拷贝
零拷贝核心原理:将内核的缓冲区共享给用户的缓冲区所使用,从而减少拷贝的次数
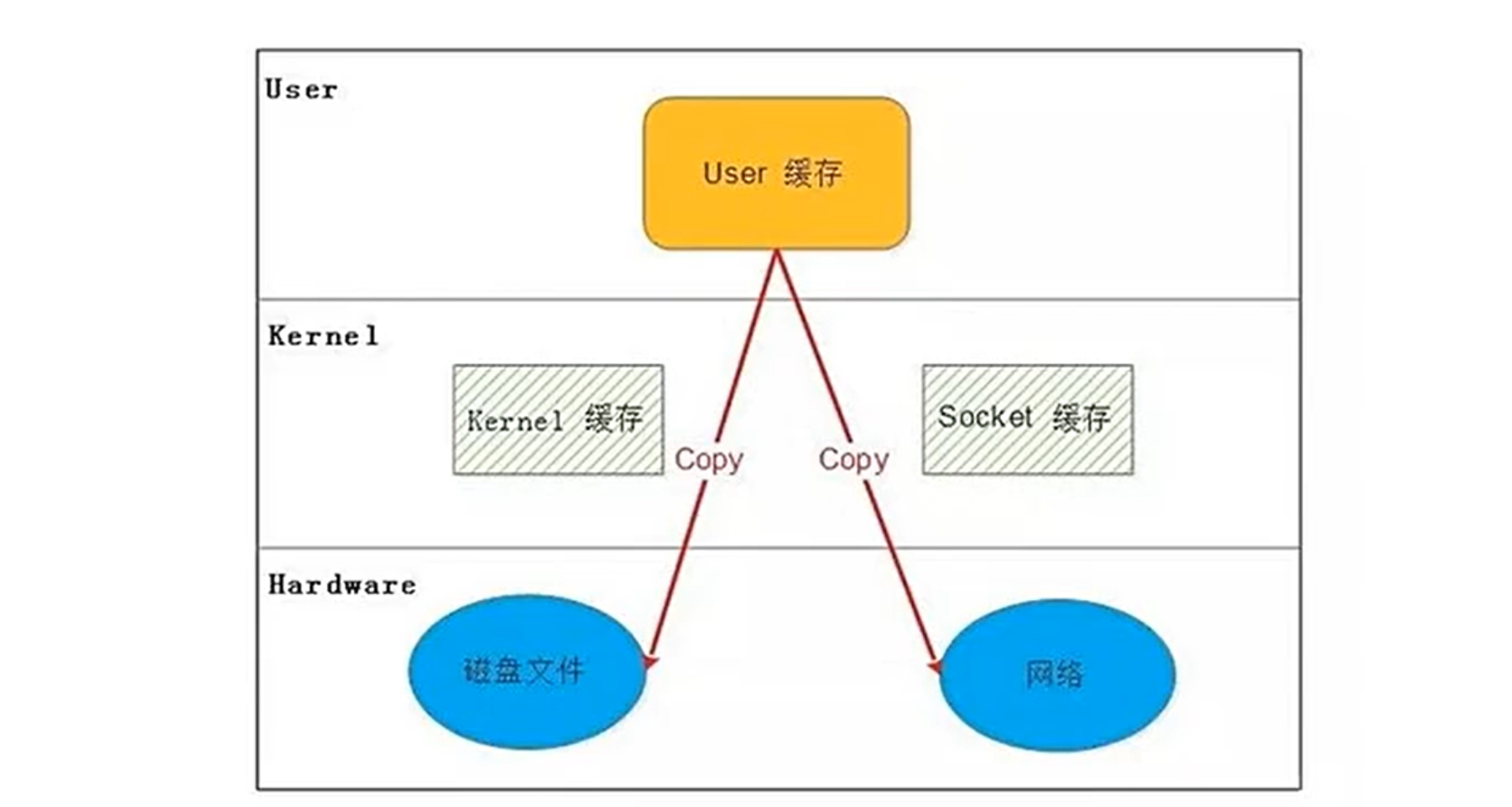
4.1.传统 I/O
-
数据流:
磁盘 → 内核缓冲区 → 用户空间缓冲区 → Socket 内核缓冲区 → 网卡 -
步骤分解:
-
磁盘到内核:DMA 控制器将数据从磁盘拷贝到内核缓冲区。
-
内核到用户空间:CPU 将数据从内核缓冲区拷贝到用户空间(应用进程)。
-
用户空间到 Socket:CPU 将数据从用户空间拷贝到 Socket 内核缓冲区。
-
Socket 到网卡:DMA 控制器将数据从 Socket 缓冲区拷贝到网卡。
-
-
缺点:
-
4 次上下文切换(用户态↔内核态切换)。
-
4 次数据拷贝(2 次 CPU 拷贝 + 2 次 DMA 拷贝)。
-
CPU 占用率高,吞吐量低。
-
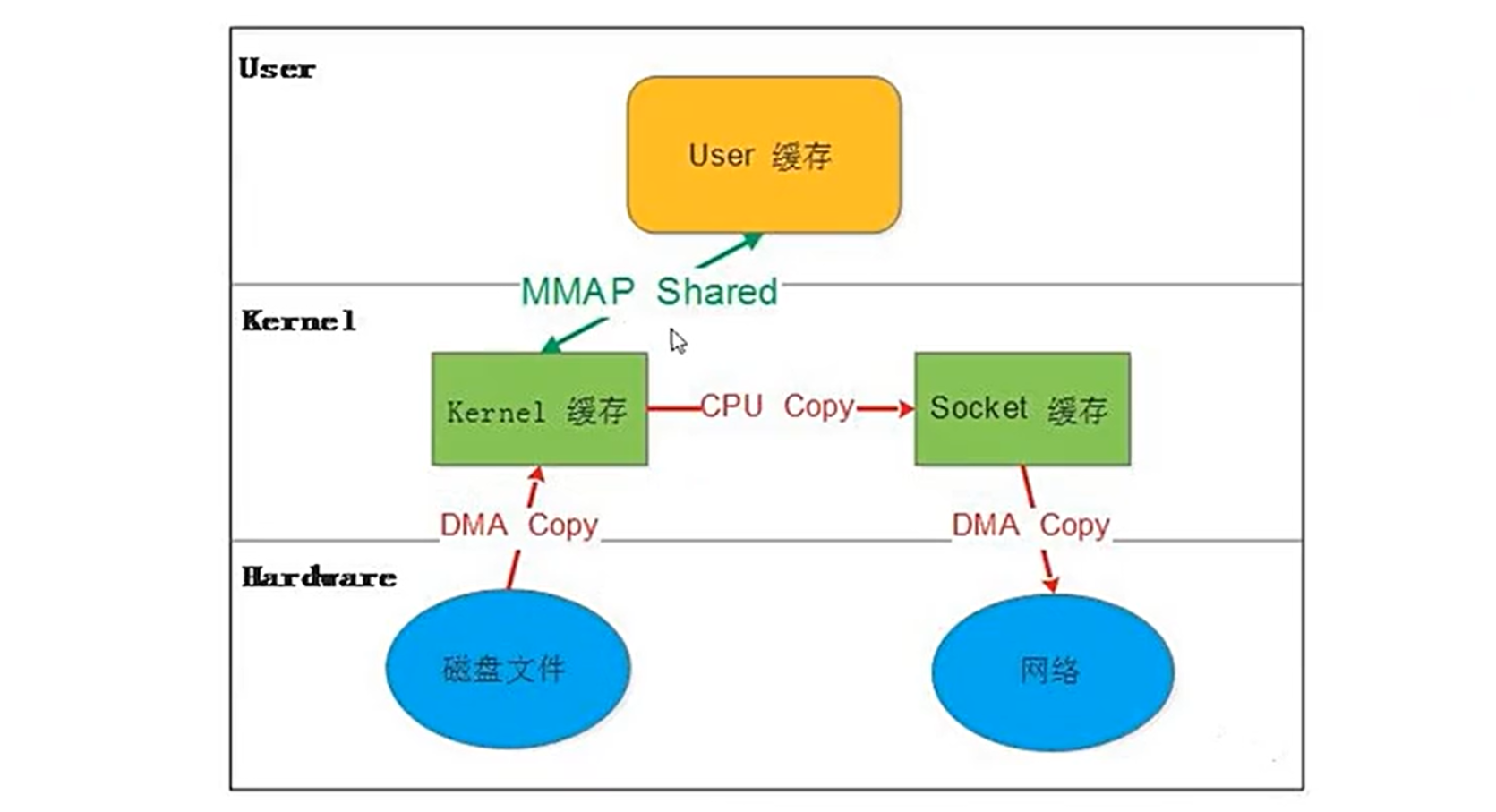
4.2.MMAP(Memory Mapping)
-
原理:
将文件映射到用户空间的虚拟内存中,应用程序直接操作内核缓冲区,避免用户空间拷贝。 -
数据流:
磁盘 → 内核缓冲区 → 用户空间虚拟内存(映射) → Socket 内核缓冲区 → 网卡 -
步骤优化:
-
省去内核到用户空间的 CPU 拷贝(仍需要 1 次 CPU 拷贝到 Socket)。
-
-
优点:
-
减少 1 次数据拷贝(共 3 次)。
-
适合大文件处理(如视频流、数据库文件)。
-
-
缺点:
-
内存映射可能引发缺页中断(Page Fault)。
-
文件大小受虚拟内存限制。
-
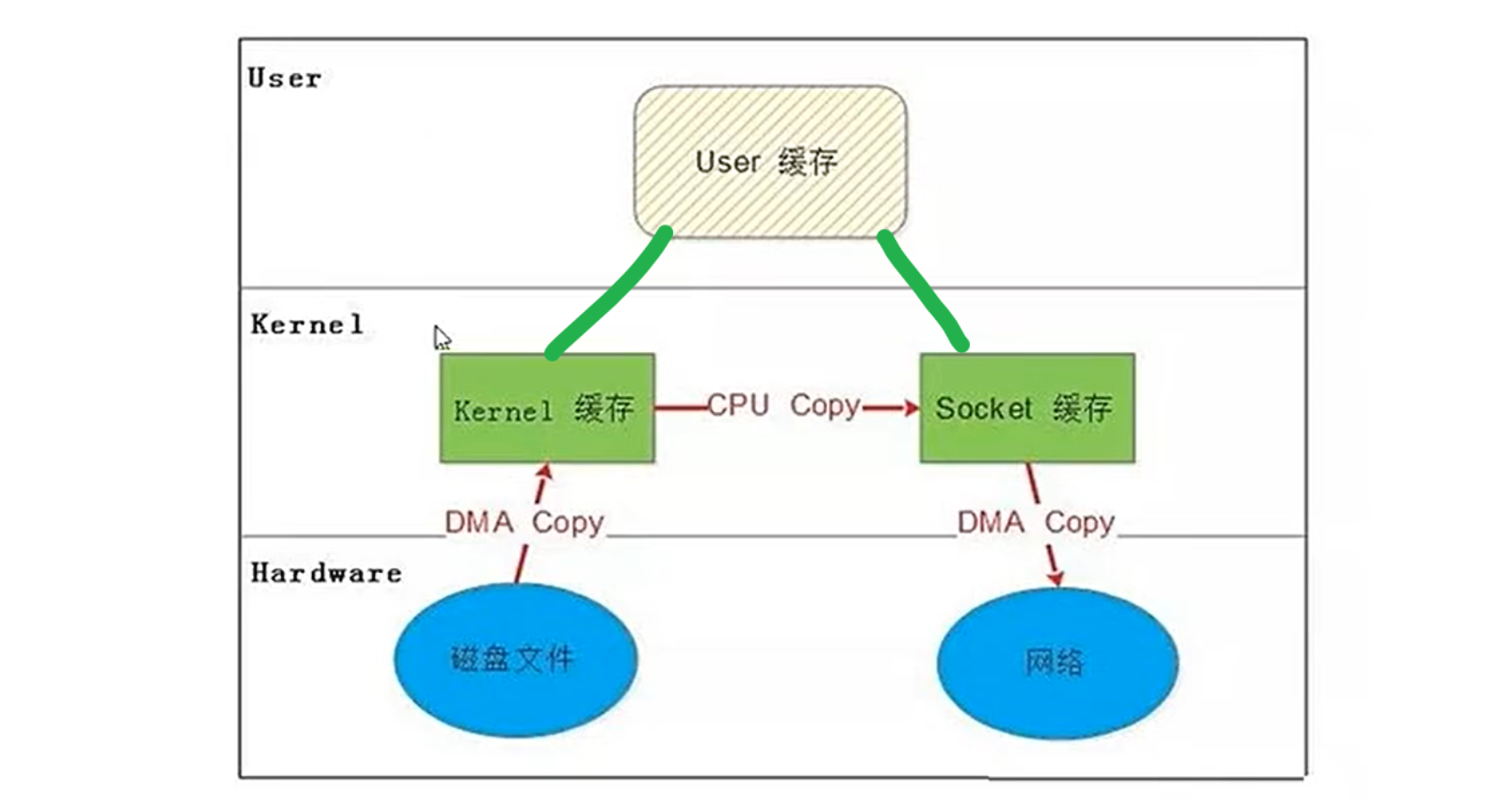
4.3.SENDFILE
-
原理:
在内核中直接将数据从文件描述符(FD)传输到 Socket,完全绕过用户空间。 -
数据流:
磁盘 → 内核缓冲区 → Socket 内核缓冲区 → 网卡 -
步骤优化:
-
省去用户空间的所有拷贝(仅剩 2 次 DMA 拷贝 + 1 次 CPU 拷贝)。
-
-
优点:
-
仅 2 次上下文切换,3 次数据拷贝。
-
适合静态文件传输(如 Web 服务器发送 HTML/CSS)。
-
-
限制:
-
源和目的必须都是文件描述符(不能修改数据)。
-
旧版本 Linux 不支持大于 2GB 的文件。
-
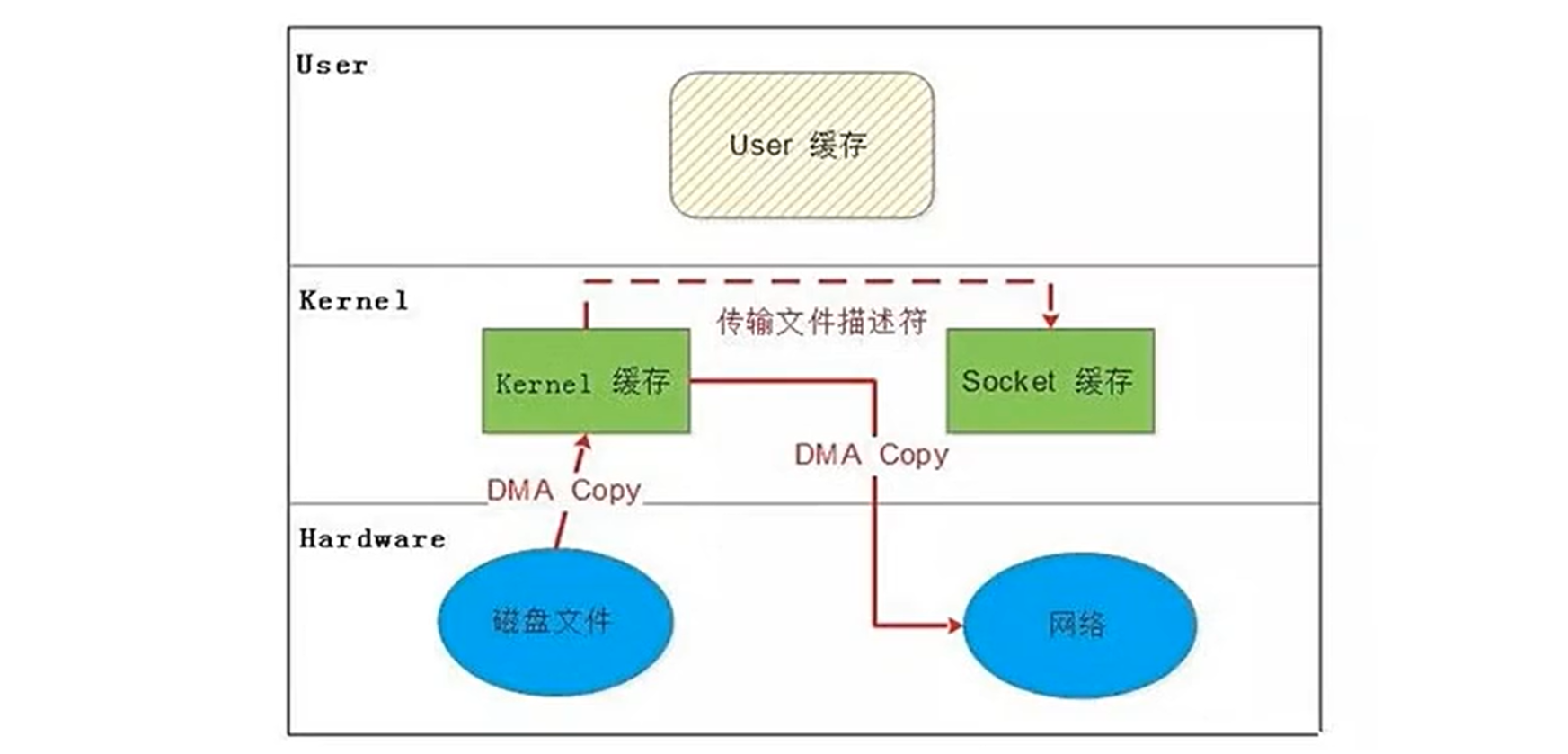
4.4.DMA 辅助的 SENDFILE
-
原理:
在支持 Scatter-Gather 的 DMA 控制器下,数据可直接从磁盘缓冲区分散读取到网卡,无需 CPU 参与拷贝。 -
数据流:
磁盘 → 内核缓冲区 → 网卡(通过 DMA 分散聚合) -
步骤优化:
-
完全零拷贝(0 次 CPU 拷贝,仅 2 次 DMA 拷贝)。
-
-
优点:
-
零 CPU 拷贝,吞吐量最大化。
-
上下文切换减少到 2 次。
-
-
条件:
-
需要硬件支持 Scatter-Gather DMA。
-
Linux 2.4+ 内核支持。
-
4.5.总结
| 技术 | 数据拷贝次数 | CPU 参与拷贝 | 适用场景 |
|---|---|---|---|
| 传统 I/O | 4 次 | 2 次 | 通用场景(兼容性优先) |
| MMAP | 3 次 | 1 次 | 大文件读写(如视频处理) |
| sendfile | 3 次 | 1 次 | 静态文件传输(Web 服务器) |
| DMA 辅助 sendfile | 2 次 | 0 次 | 高性能网络传输(如 CDN、云计算) |
性能影响分析
-
吞吐量:
-
DMA 辅助 sendfile > sendfile > MMAP > 传统 I/O。
-
-
CPU 占用:
-
传统 I/O(最高) → MMAP → sendfile → DMA 辅助 sendfile(最低)。
-
-
延迟:
-
零拷贝技术显著减少处理时间,尤其在高并发场景下。
-
选择建议
-
优先 DMA 辅助 sendfile:若硬件和内核支持,追求极致性能。
-
静态内容服务:使用标准 sendfile。
-
需处理数据内容:选择 MMAP(如数据库引擎)。
-
兼容老旧系统:回退到传统 I/O。
总结:零拷贝技术通过减少数据拷贝和 CPU 参与,显著提升 I/O 性能,是现代高并发系统的核心优化手段。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









