







 软间隔支持向量机放宽了线性可分SVM的约束,允许部分样本出错,通过引入松弛变量和惩罚系数C来平衡模型的泛化能力和训练误差。在目标函数中,除了最大化间隔外,还考虑了样本点的误分类成本。通过拉格朗日乘子法转换为对偶问题,使用SMO算法求解。支持向量是对应于非零拉格朗日乘子的样本,它们可能位于间隔边界、超平面或误分类区域。
软间隔支持向量机放宽了线性可分SVM的约束,允许部分样本出错,通过引入松弛变量和惩罚系数C来平衡模型的泛化能力和训练误差。在目标函数中,除了最大化间隔外,还考虑了样本点的误分类成本。通过拉格朗日乘子法转换为对偶问题,使用SMO算法求解。支持向量是对应于非零拉格朗日乘子的样本,它们可能位于间隔边界、超平面或误分类区域。
软间隔支持向量机
1. 问题引入
在实际任务中,很难确定一个线性可分的超平面(存在某些异常点,这些点不能满足函数间隔≥1的约束条件);或者说找到了合适的超平面,也很难断定这个貌似线性可分的结果是否由于过拟合导致。
为了包容异常点或者为了避免过拟合,我们允许SVM在一些样本上出错(e.g 下图红色圈中的样本没有划分正确),此时最大化的间隔称为"软间隔"。
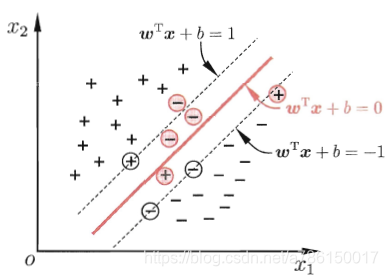
而在线性可分SVM中要求所有样本都满足约束条件(所有样本划分正确),此时最大化的间隔也称为"硬间隔"。
2. 模型描述 - 软间隔最大化
回顾线性可分SVM,它的优化问题是
min
w
,
b
1
2
∥
w
∥
2
\mathop {\min }\limits_{w,b} {1 \over 2}{\left\| w \right\|^2}
w,bmin21∥w∥2
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2...
m
s.t.\quad{y_i}\left( {{w^T}{x_i} + b} \right) \ge 1,i = 1,2...m
s.t.yi(wTxi+b)≥1,i=1,2...m
软间隔考虑异常点的情况,约束条件变成:
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
i
,
  
i
=
1
,
2...
m
{y_i}\left( {{w^T}{x_i} + b} \right) \ge 1 - {\xi _i},\; i = 1,2...m
yi(wTxi+b)≥1−ξi,i=1,2...m
其中
ξ
i
≥
0
{\xi _i} \ge 0
ξi≥0 称为松弛变量,也就是说我们对样本到超平面的函数距离约束放松了。但如果
ξ
i
{\xi _i}
ξi 任意大,会导致任意的超平面都符合要求。所以,目标函数上应该考虑
ξ
i
{\xi _i}
ξi 的成本:
min
w
,
b
1
2
∥
w
∥
2
+
C
∑
i
=
1
m
ξ
i
\mathop {\min }\limits_{w,b} {1 \over 2}{\left\| w \right\|^2} + C\sum\limits_{i = 1}^m {{\xi _i}}
w,bmin21∥w∥2+Ci=1∑mξi
其中 C > 0 C > 0 C>0 是正则化惩罚系数,用来权衡目标函数中的两项(“寻找间隔最大的超平面"和"保证数据点偏差最小”)。 C C C 越大,对误分类的惩罚越大; C C C 越小,对误分类的惩罚越小。
原始最优化问题
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ξ i \mathop {\min }\limits_{w,b} {1 \over 2}{\left\| w \right\|^2} + C\sum\limits_{i = 1}^m {{\xi _i}} w,bmin21∥w∥2+Ci=1∑mξi s . t . y i ( w T x i + b ) ≥ 1 − ξ i ,    i = 1 , 2... m s.t.\quad{y_i}\left( {{w^T}{x_i} + b} \right) \ge 1 - {\xi _i},\; i = 1,2...m s.t.yi(wTxi+b)≥1−ξi,i=1,2...m ξ i ≥ 0 ,    i = 1 , 2... m {\xi _i} \ge 0,\;i = 1,2...m ξi≥0,i=1,2...m等价于最优化问题(合页损失函数)
m i n ⎵ w , b ∑ i = 1 m [ 1 − y i ( w ∙ x i + b ) ] + + λ ∥ w ∥ 2 \underbrace {min}_{w,b}\sum\limits_{i = 1}^m {{{[1 - {y_i}(w \bullet {x_i} + b)]}_ + }} + \lambda {\left\| w \right\|^2} w,b mini=1∑m[1−yi(w∙xi+b)]++λ∥w∥2
注: λ = 1 2 C , [ 1 − y i ( w ∙ x i + b ) ] + = ξ i \lambda = {1 \over {2C}},\quad {[1 - {y_i}(w \bullet {x_i} + b)]_ + } = {\xi _i} λ=2C1,[1−yi(w∙xi+b)]+=ξi
在sklearn中的参数是 λ \lambda λ。
3. 模型求解
和线性可分SVM的模型求解方法类似,具体如下所述。
1)优化目标为:
min
w
,
b
1
2
∥
w
∥
2
+
C
∑
i
=
1
m
ξ
i
\mathop {\min }\limits_{w,b} {1 \over 2}{\left\| w \right\|^2} + C\sum\limits_{i = 1}^m {{\xi _i}}
w,bmin21∥w∥2+Ci=1∑mξi
s . t . y i ( w T x i + b ) ≥ 1 − ξ i ,    i = 1 , 2... m s.t.\quad{y_i}\left( {{w^T}{x_i} + b} \right) \ge 1 - {\xi _i},\; i = 1,2...m s.t.yi(wTxi+b)≥1−ξi,i=1,2...m
ξ i ≥ 0 ,    i = 1 , 2... m {\xi _i} \ge 0,\;i = 1,2...m ξi≥0,i=1,2...m
2)将约束条件加入目标函数中,得到拉格朗日函数:
L
(
w
,
b
,
ξ
,
α
,
μ
)
=
1
2
∥
w
∥
2
+
C
∑
i
=
1
m
ξ
i
−
∑
i
=
1
m
α
i
(
y
i
(
w
T
x
i
+
b
)
−
1
+
ξ
i
)
−
∑
i
=
1
m
μ
i
ξ
i
L\left( {w,b,\xi ,\alpha ,\mu } \right) = {1 \over 2}{\left\| w \right\|^2} + C\sum\limits_{i = 1}^m {{\xi _i}} - \sum\limits_{i = 1}^m {{\alpha _i}\left( {{y_i}\left( {{w^T}{x_i} + b} \right) - 1 + {\xi _i}} \right)} - \sum\limits_{i = 1}^m {{\mu _i}{\xi _i}}
L(w,b,ξ,α,μ)=21∥w∥2+Ci=1∑mξi−i=1∑mαi(yi(wTxi+b)−1+ξi)−i=1∑mμiξi
其中 α i ≥ 0 , ξ ≥ 0 {\alpha _i} \ge 0,\xi \ge 0 αi≥0,ξ≥0 均为拉格朗日系数。
3)原始问题转换成对偶问题求解:
min
w
,
b
,
ξ
max
α
,
μ
L
(
w
,
b
,
ξ
,
α
,
μ
)
⇔
max
α
,
μ
min
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
α
,
μ
)
\mathop {\min }\limits_{w,b,\xi } \mathop {\max }\limits_{\alpha ,\mu } L\left( {w,b,\xi ,\alpha ,\mu } \right) \Leftrightarrow \mathop {\max }\limits_{\alpha ,\mu } \mathop {\min }\limits_{w,b,\xi } L\left( {w,b,\xi ,\alpha ,\mu } \right)
w,b,ξminα,μmaxL(w,b,ξ,α,μ)⇔α,μmaxw,b,ξminL(w,b,ξ,α,μ)
4)对偶问题求解:
先求优化函数对于
w
,
b
,
ξ
{w,b,\xi }
w,b,ξ 的极小值,求偏导:
∂
L
∂
w
=
w
−
∑
i
=
1
m
α
i
y
i
x
i
=
0
⇒
w
=
∑
i
=
1
m
α
i
y
i
x
i
∂
L
∂
b
=
∑
i
=
1
m
α
i
y
i
=
0
⇒
∑
i
=
1
m
α
i
y
i
=
0
∂
L
∂
ξ
=
0
⇒
C
−
α
i
−
μ
i
=
0
\begin{aligned} {{\partial L} \over {\partial w}} &= w - \sum\limits_{i = 1}^m {{\alpha _i}{y_i}{x_i}} = 0 \Rightarrow w = \sum\limits_{i = 1}^m {{\alpha _i}{y_i}{x_i}} \\ {{\partial L} \over {\partial b}} &= \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0 \Rightarrow \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0 \\ {{\partial L} \over {\partial \xi }} &= 0 \Rightarrow C - {\alpha _i} - {\mu _i} = 0 \end{aligned}
∂w∂L∂b∂L∂ξ∂L=w−i=1∑mαiyixi=0⇒w=i=1∑mαiyixi=i=1∑mαiyi=0⇒i=1∑mαiyi=0=0⇒C−αi−μi=0
将其代回优化函数
L
(
w
,
b
,
α
)
L\left( {w,b,\alpha } \right)
L(w,b,α),消去
w
w
w 和
C
C
C,得到和线性可分SVM一样的目标函数,但约束条件不同:
max
α
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
+
∑
i
=
1
m
α
i
\mathop {\max }\limits_\alpha - {1 \over 2}\sum\limits_{i = 1}^m {\sum\limits_{j = 1}^m {{\alpha _i}{\alpha _j}{y_i}{y_j}{x_i}^T{x_j}} } + \sum\limits_{i = 1}^m {{\alpha _i}}
αmax−21i=1∑mj=1∑mαiαjyiyjxiTxj+i=1∑mαi
s . t . ∑ i = 1 m α i y i = 0 s.t.\quad \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0 s.t.i=1∑mαiyi=0
C − α i − μ i = 0 C - {\alpha _i} - {\mu _i} = 0 C−αi−μi=0
α i ≥ 0 , μ i ≥ 0 ,    i = 1 , 2... m {\alpha _i} \ge 0,{\mu _i} \ge 0,\; i = 1,2...m αi≥0,μi≥0,i=1,2...m
对于后面三个约束条件,可以消去
μ
i
{\mu _i}
μi, 只留下
α
i
{\alpha _i}
αi。同时目标函数变号,求极小:
min
α
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
T
x
j
−
∑
i
=
1
m
α
i
\mathop {\min }\limits_\alpha {1 \over 2}\sum\limits_{i = 1}^m {\sum\limits_{j = 1}^m {{\alpha _i}{\alpha _j}{y_i}{y_j}{x_i}^T{x_j}} } - \sum\limits_{i = 1}^m {{\alpha _i}}
αmin21i=1∑mj=1∑mαiαjyiyjxiTxj−i=1∑mαi
s . t . ∑ i = 1 m α i y i = 0 , 0 ≤ α i ≤ C ,    i = 1 , 2... m s.t.\quad \sum\limits_{i = 1}^m {{\alpha _i}{y_i}} = 0,\quad 0 \le {\alpha _i} \le C,\;i = 1,2...m s.t.i=1∑mαiyi=0,0≤αi≤C,i=1,2...m
同理,也是用SMO算法对 α \alpha α 求极小。
在SMO算法求得 α ∗ {\alpha}^* α∗ 后,若某样本点的 α i ∗ {\alpha _i}^* αi∗ 满足 0 < α i ∗ < C 0 < {\alpha _i}^* < C 0<αi∗<C, 则可依据 y i ( w T x i + b ) = 1 {y_i}\left( {{w^T}{x_i} + b} \right) = 1 yi(wTxi+b)=1 对 b b b 进行求解。(具体原因参见第4.2节)
4.支持向量
4.1 硬间隔最大化的支持向量
根据KKT的对偶互补条件,最优化问题的解 α ∗ {\alpha ^*} α∗需满足: α i ∗ ( y i ( w T x i + b ) − 1 ) = 0 {\alpha _i}^*\left( {{y_i}\left( {{w^T}{x_i} + b} \right) - 1} \right) = 0 αi∗(yi(wTxi+b)−1)=0
又因为线性可分SVM的支持向量均满足
y
s
(
w
T
x
s
+
b
)
=
1
{y_s}\left( {{w^T}{x_s} + b} \right) = 1
ys(wTxs+b)=1,所以
α
i
∗
>
0
⇔
y
i
(
w
T
x
i
+
b
)
=
1
⇒
样
本
都
在
支
持
向
量
上
α
i
∗
=
0
⇔
y
i
(
w
T
x
i
+
b
)
≥
1
⇒
样
本
都
在
支
持
向
量
上
或
已
被
正
确
分
类
\begin{aligned} {\alpha _i}^* > 0 &\Leftrightarrow {y_i}\left( {{w^T}{x_i} + b} \right) = 1 \Rightarrow 样本都在支持向量上 \\ {\alpha _i}^* = 0 &\Leftrightarrow {y_i}\left( {{w^T}{x_i} + b} \right) \ge 1 \Rightarrow 样本都在支持向量上或已被正确分类 \end{aligned}
αi∗>0αi∗=0⇔yi(wTxi+b)=1⇒样本都在支持向量上⇔yi(wTxi+b)≥1⇒样本都在支持向量上或已被正确分类
4.2 软间隔最大化的支持向量
根据KKT的对偶互补条件,最优化问题的解 α ∗ {\alpha ^*} α∗需满足: α i ∗ ( y i ( w T x i + b ) − 1 + ξ i ) = 0 , μ i ∗ ξ i = 0 {\alpha _i}^*\left( {{y_i}\left( {{w^T}{x_i} + b} \right) - 1 + {\xi _i}} \right) = 0,\quad {\mu _i}^*{\xi _i} = 0 αi∗(yi(wTxi+b)−1+ξi)=0,μi∗ξi=0
约束条件有
α
i
+
μ
i
=
C
{\alpha _i} + {\mu _i} = C
αi+μi=C ,所以有
a
)
  
α
i
∗
=
0
⇒
μ
i
∗
=
C
⇒
ξ
i
=
0
  
⇒
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
i
⇒
y
i
(
w
T
x
i
+
b
)
≥
1
⇒
在
间
隔
边
界
上
/
已
被
正
确
分
类
b
)
  
0
<
α
i
∗
<
C
⇒
y
i
(
w
T
x
i
+
b
)
−
1
+
ξ
i
=
0
  
⇒
μ
i
∗
≠
0
⇒
ξ
i
=
0
⇒
y
i
(
w
T
x
i
+
b
)
=
1
⇒
在
间
隔
边
界
上
c
)
  
α
i
∗
=
C
⇒
μ
i
∗
=
0
⇒
ξ
i
≠
0
    
⇒
y
i
(
w
T
x
i
+
b
)
=
1
−
ξ
i
i
)
  
0
≤
ξ
i
≤
1
时
,
点
被
正
确
分
类
,
但
在
超
平
面
和
间
隔
边
界
之
间
i
i
)
  
ξ
i
=
1
时
,
点
在
超
平
面
上
,
无
法
被
正
确
分
类
i
i
)
  
ξ
i
>
1
时
,
点
在
超
平
面
另
一
侧
,
被
误
分
\begin{aligned} a)\;&{\alpha _i}^* = 0 \Rightarrow {\mu _i}^* = C \Rightarrow {\xi _i} = 0\\ &\quad\quad\quad\;\Rightarrow {y_i}\left( {{w^T}{x_i} + b} \right) \ge 1 - {\xi _i} \\ &\Rightarrow {y_i}\left( {{w^T}{x_i} + b} \right) \ge 1 \Rightarrow 在间隔边界上/已被正确分类\\ b)\;&0 < {\alpha _i}^* < C \Rightarrow {y_i}\left( {{w^T}{x_i} + b} \right) - 1 + {\xi _i} = 0\\ &\quad\quad\quad\quad\quad\; \Rightarrow {\mu _i}^* \ne 0 \Rightarrow {\xi _i} = 0\\ &\Rightarrow {y_i}\left( {{w^T}{x_i} + b} \right) = 1 \Rightarrow 在间隔边界上\\ c)\;&{\alpha _i}^* = C \Rightarrow {\mu _i}^* = 0 \Rightarrow {\xi _i} \ne 0\\ &\quad\quad\quad\;\;\Rightarrow {y_i}\left( {{w^T}{x_i} + b} \right) = 1 - {\xi _i} \\ &i)\;0 \le {\xi _i} \le 1时,点被正确分类,但在超平面和间隔边界之间\\ &ii)\;{\xi _i} = 1时,点在超平面上,无法被正确分类\\ &ii)\;{\xi _i} > 1时,点在超平面另一侧,被误分 \end{aligned}
a)b)c)αi∗=0⇒μi∗=C⇒ξi=0⇒yi(wTxi+b)≥1−ξi⇒yi(wTxi+b)≥1⇒在间隔边界上/已被正确分类0<αi∗<C⇒yi(wTxi+b)−1+ξi=0⇒μi∗̸=0⇒ξi=0⇒yi(wTxi+b)=1⇒在间隔边界上αi∗=C⇒μi∗=0⇒ξi̸=0⇒yi(wTxi+b)=1−ξii)0≤ξi≤1时,点被正确分类,但在超平面和间隔边界之间ii)ξi=1时,点在超平面上,无法被正确分类ii)ξi>1时,点在超平面另一侧,被误分
软间隔的支持向量是对应于 α i ∗ > 0 {\alpha _i}^* > 0 αi∗>0 的样本点的实例,可能在间隔边界上,可能在超平面和间隔边界之间,也可能在被误分的一侧。

















 1736
1736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









