




许久之前写了一篇《Python网络爬虫实战》的博客,里面讲了爬虫的过程,但是没有讲如何分析。这次讲述一下用如何通过词云分析,来从这些文本数据里面获得结论
首先,回顾一下分析背景
主要是看了一下随着日期,玩家每天的评论变化,其中红色柱状是总的评论数
这里我们发现几个非常有趣的点, (1)4.13前后出现了评分陡降的情况 (2)4月底评分持续低迷
这段时间肯定是发生了什么事情,所以才出现掉分的情况。具体的原因,我们可以通过对评论的内容进行挖掘探究
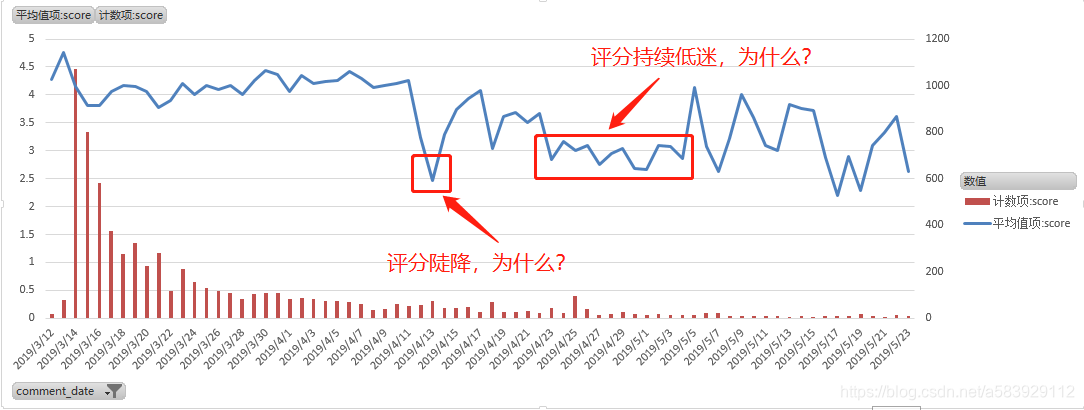
所以我们这里 要做的是,对这问题时间的评论进行提取,并对其进行词云分析,得到热词 从而可以通过这些热词来反推玩家的讨论焦点,找到导致评分下降的原因
-------------------------------------以下过程仅针对第一个评分陡降的点,即4月13日前后---------------------------
主要逻辑:词云分析的4个步骤:
1、语句分词:将完整的自然语言语句,切割成一个个单独的词汇,便于词频统计。这是个挺复杂的事情,尤其是中文的分词,因为汉语中并没有空格这样的分隔符,但是不用担心,python有第三方库函数可以解决——Jieba分词
2、过滤停用词:分词后的词汇里面,会带有很多的 “的” 、“我” 、“我们” 、“游戏”等高频但是没有什么意义的词汇,因此需要过滤掉。这里我们需要自己准备好一些需要过滤的词库,称为停用词——Jieba分词已支持该功能
3、词频分析:分割后的语句,其实就是一大堆的词汇,我们再通过统计词频,就可以知道哪些是高频词汇了——Jieba分词同样已支持该功能
4、词云生成:其实当你拥有词频后,分析就已经基本结束了。如果需要更直观的展示出来(例如放进PPT或者分析报告里),可以生成一个词云来实现——这里要用到的是wordcloud库函数
代码实现:
下面贴一下各部分对应的代码。(需要注意的是,以下分析使用的是目标时间4月12日~4月14日的评论数据,因为提取过程与本文关系不大,因此没有单独贴出来)
step 1 语句分词:
#调用了jieba分词的函数cut,对sentensce进行分词。这里的sentence是包含多个语句的List对象,需要转成str
sentence_seged=jieba.cut(str(sentence)) #jieba初步分词
step 2 过滤停用词:
#加载停用词,从停用词文件star_stopwords.txt中逐行读取词汇
stopwords=[line.strip 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 324
324




 到【灌水乐园】发言
到【灌水乐园】发言







