




先说说背景吧:
之前玩了一段时间的《跨越星弧》,后来太忙了就没玩了,最近突然想起来想看看,发现TapTap评分居然掉到7.7分了
其实我觉得这个产品挺好的,玩法、剧情、美术都有可圈可点之处。但是为什么突然就从8.5分+掉到7.7了呢
于是我就去翻了翻评论,翻了10+页,好像也没看出什么问题。也没兴致往下看了,因为评论真的太多了,这样人工一条条的看,根本看不出个所以然来
刚好最近在看游戏数据分析,于是就想到,要不自己做个爬虫扒一下评论数据吧
项目源码已上传至GitHub项目——Tap-Comment-Scrapy,欢迎查看和下载源码。(使用Jupyter Notebook环境开发)
///////////////////////////以下是正文///////////////////////////////
为了分析需要,我们要爬取的信息包括【评论文本】、【评论分数】、【评论时间】,在TapTap的页面中基本是按块呈现的
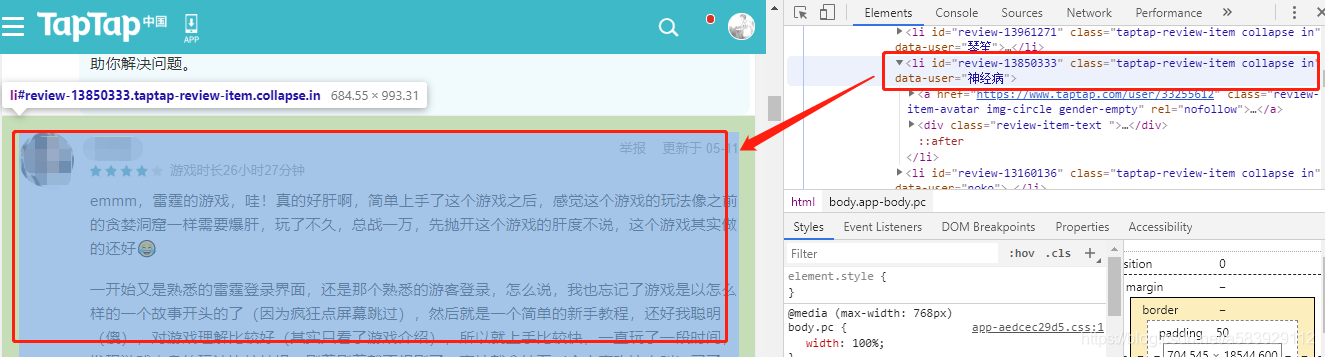
在页面中按F12可以查看页面的源码,这里很重要的是要【找到对应模块的类名】
这里用到的爬虫的基本原理就是:
step1 加载url源码
step2 从里面找到我们需要的信息所在的类
step3 通过正则匹配,获取我们需要的信息
step4 整理输出
这个过程的实现需要用到几个库,但核心的代码非常简单,只有几行。下面是代码
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1434
1434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









