







 本篇博文通过使用Apache Spark对搜狗实验室提供的迷你日志文件进行处理,介绍了如何加载数据、过滤无效记录,并统计搜索结果排名第一且被用户点击的记录数量,最后展示了如何进行session查询次数的排行。
本篇博文通过使用Apache Spark对搜狗实验室提供的迷你日志文件进行处理,介绍了如何加载数据、过滤无效记录,并统计搜索结果排名第一且被用户点击的记录数量,最后展示了如何进行session查询次数的排行。
《Spark亚太研究院系列丛书——Spark实战高手之路 从零开始》本书通过Spark的shell测试Spark的工作;使用Spark的cache机制观察一下效率的提升构建Spark的IDE开发环境;通过Spark的IDE搭建Spark开发环境;测试Spark IDE开发环境等等。本节为大家介绍Join操作深入实战。
动手实战操作搜狗日志文件
本节中所用到的内容是来自搜狗实验室,网址为:
http://www.sogou.com/labs/dl/q.html
用户可以根据自己的Spark机器实际的内存配置等情况选择下载不同的数据版本,为了让所有的学习者都可以成功操作日志,我们使用的是迷你版本的tar.gz格式的文件,其大小为87K,下载后如下所示:
打开该文件,其内容如下所示:
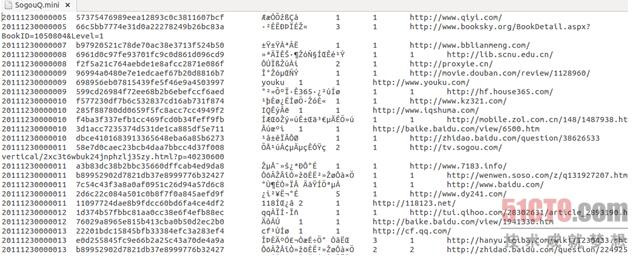
该文件的格式如下所示:
访问时间\t用户ID\t查询词\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
把文件解压:
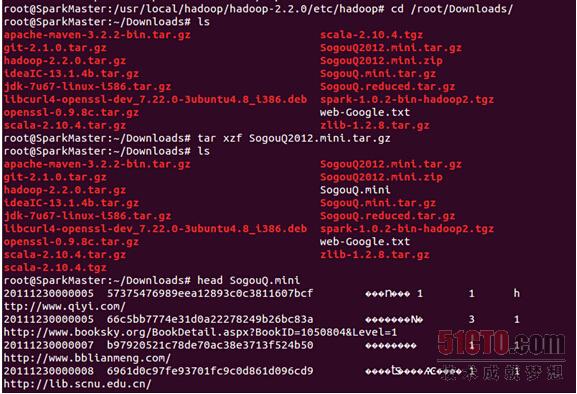
把解压后的文件上传到hdfs的data目录下:

从web控制台上查看一下上传的文件:
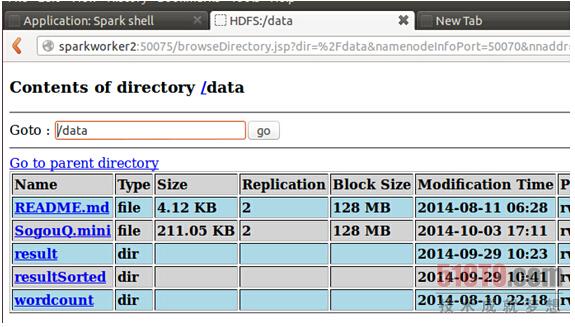
点击打开该文件:
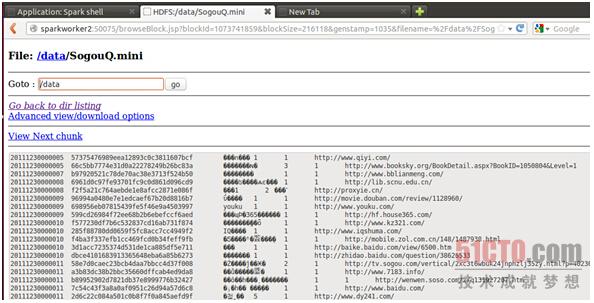
成功上传了该文件。
接下来 我们使用Spark获得搜索结果排名第一同时点击结果排名也是第一的数据量,也就是第四列值为1同时第五列的值也为1的总共的记录的个数。
先读取SogouQ.mini文件:
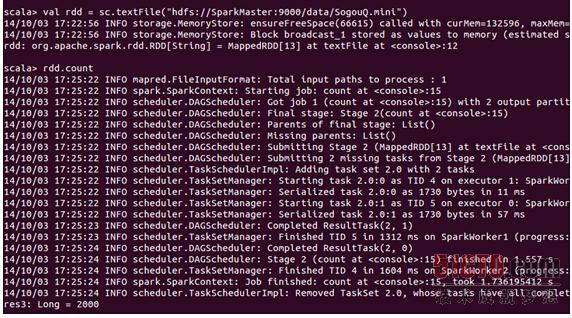
可以看到其中一共是2000条数据。
首先过滤出有效的数据:
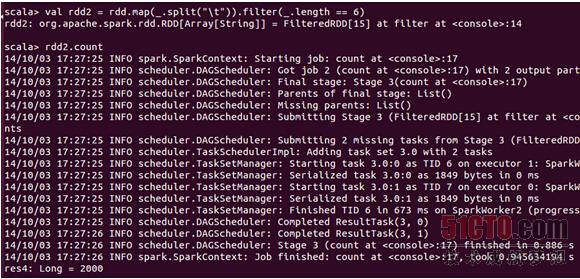
可以发现该文件中的数据都是有效数据。
下面使用Spark获得搜索结果排名第一同时点击结果排名也是第一的数据量:
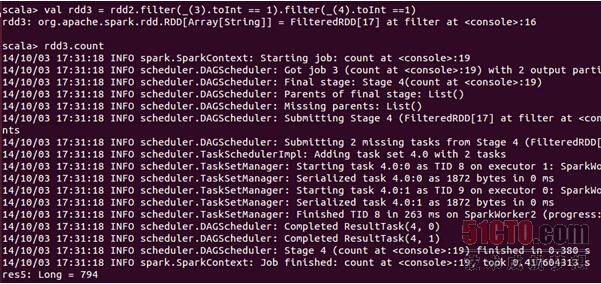
可以发现搜索结果排名第一同时点击结果排名也是第一的数据量为794条;
使用toDebugString查看一下其lineage:
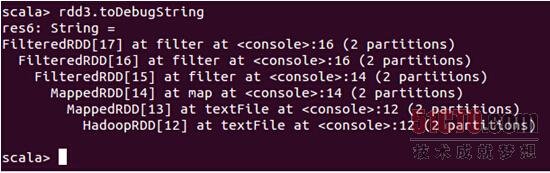
下面看session查询次数排行榜:
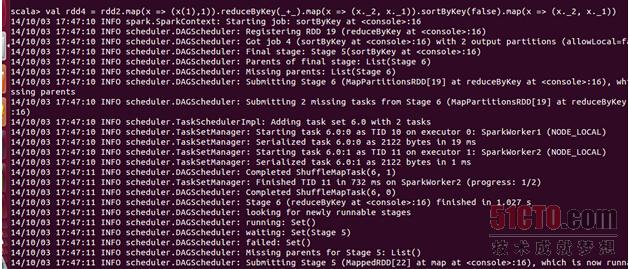
把结果保存在hdfs上:
![]()
到web控制台上查看结果:
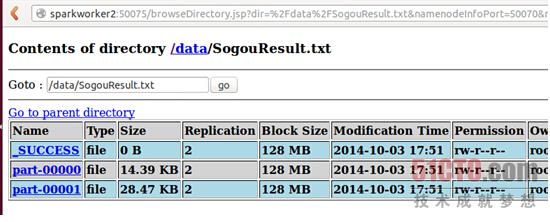
查看数据:
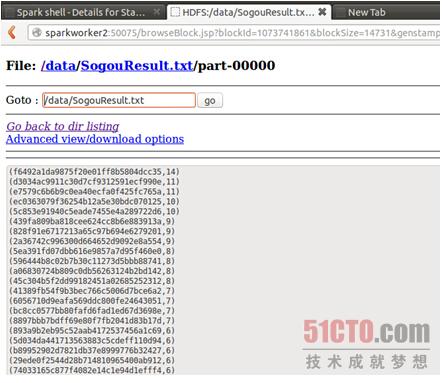
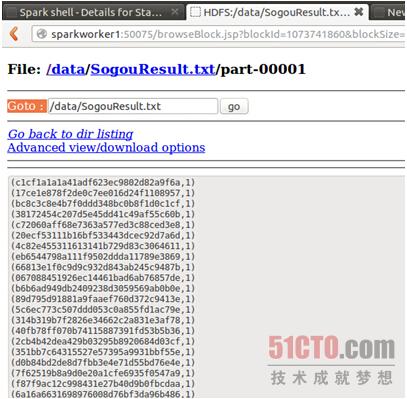
我们通过hadoop命令把上述两个文件的内容合并起来:
![]()
查看一下合并后的本地文件:
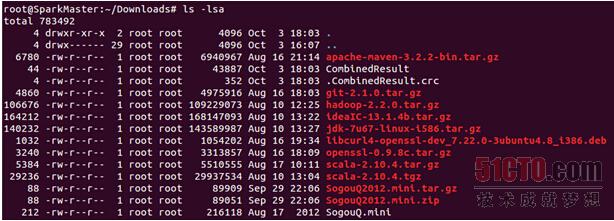
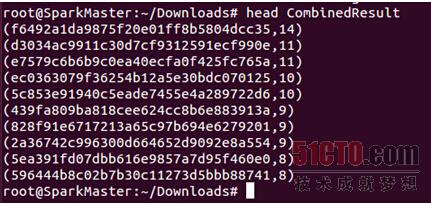
使用head命令查看其具体内容:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









