







当前环境
| 软件 | 版本 |
|---|---|
| CUDA | 10.2 |
| cudnn | 7.6.5 |
| TensorRT | 7.0.0.11 |
根据当前环境编译trtexec
源码在TensorRT里面,路径TensorRT-7.0.0.11\samples\trtexec
1. 使用Visual Studio打开项目
打开trtexec.sln文件
2. 给项目配置正确的头文件和静态库路径
头文件
右键解决方案属性=> C/C++ => 常规 => 附加包含目录
添加以下路径(根据自身情况调整)
D:\TensorRT-7.0.0.11\include;
D:\TensorRT-7.0.0.11\samples\common;
D:\TensorRT-7.0.0.11\samples\common\windows;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
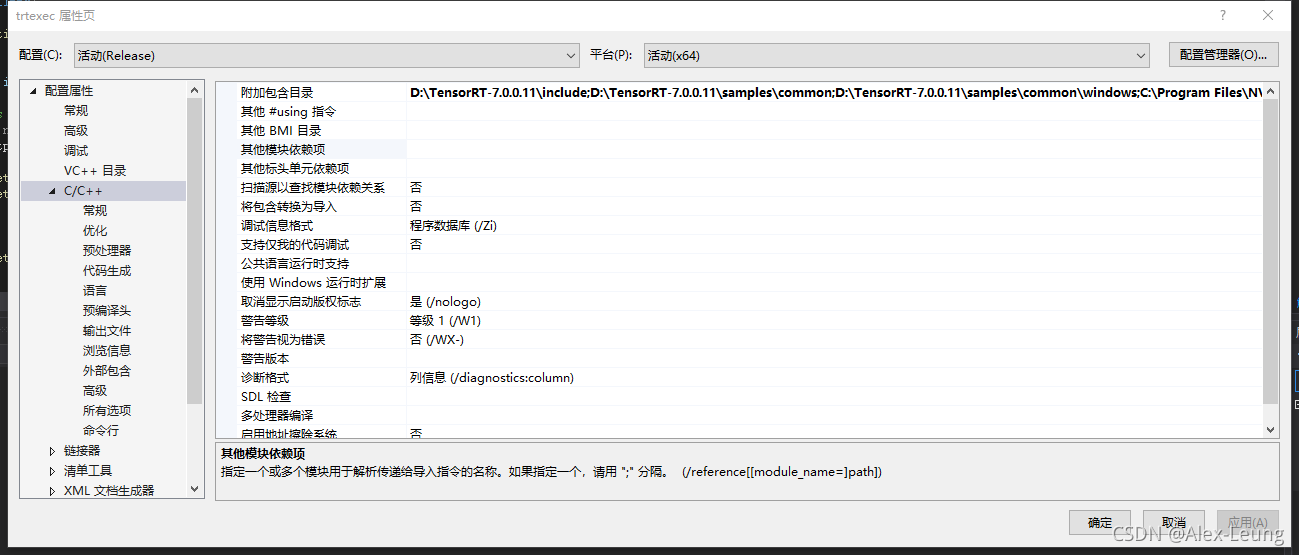
静态库
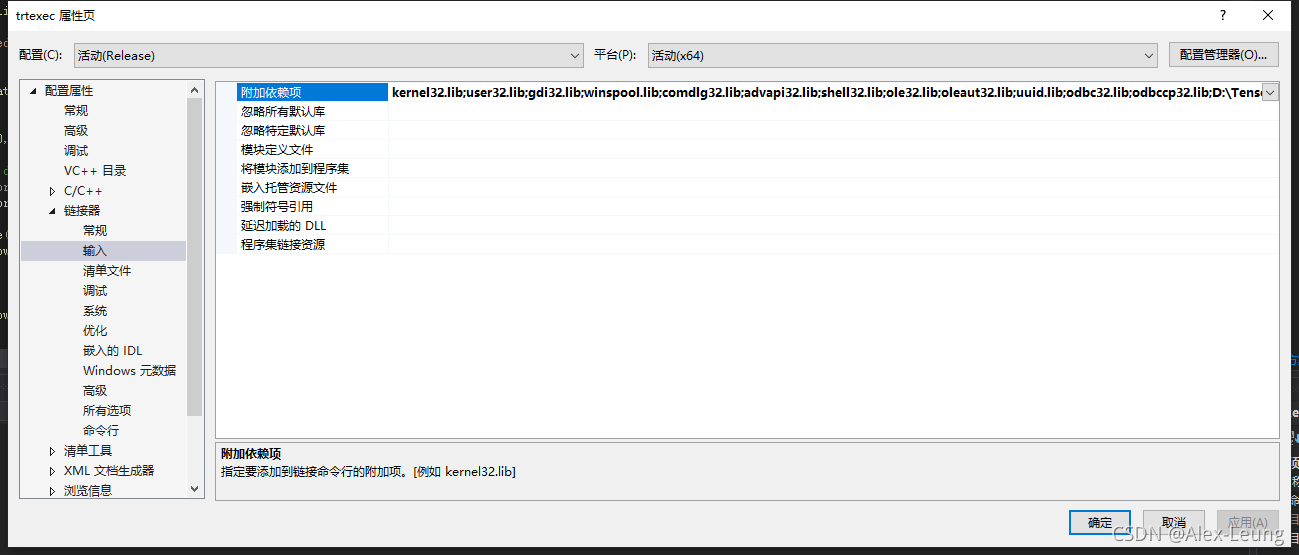
右键解决方案属性=> 链接器 => 输入 => 附加依赖项
添加以下路径(根据自身情况调整)
D:\TensorRT-7.0.0.11\lib\*.lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64\*.lib
3. 生成解决方案
文件生成路径在TensorRT-7.0.0.11\bin\trtexec.exe, 可选择添加到环境变量Path里,打开powershell就能使用trtexec命令
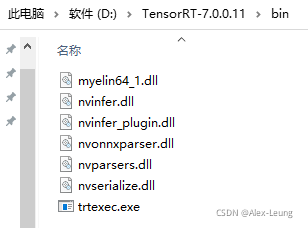
4. 复制需要的动态链接库到同级路径
这里怕麻烦直接把所有TensorRT的动态链接库都复制过来了,不复制就会无法运行,调试模式可以看到提示缺少了某个.dll文件,缺那个补哪个
测试
将之前一篇文章基于百度PaddleCV导出来的onnx模型转成TensorRT的engine文件
将onnx文件复制到同级目录下,然后输入以下指令
导出onnx文件固定了batch_size,需要添加explicitBatch参数
trtexec --onnx=pdkp.onnx --saveEngine=kp.trt --explicitBatch --fp16 --workspace=4096 --buildOnly
# 模板
.\trtexec --onnx=your_network.onnx --saveEngine=your_network.trt --explicitBatch --fp16 --workspace=4096 --buildOnly
# 生成混合精度模型,非动态输入
.\trtexec.exe --onnx=erfnet.onnx --saveEngine=erfnet_best.trt --workspace=6144 --maxBatch=1 --batch=1 --iterations=1 --best --verbose
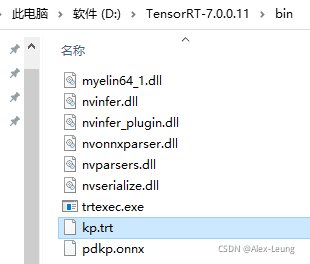
最后会在同级目录下生成一个kp.trt的engine文件
资料
更多资料可以查阅以下地址
https://docs.nvidia.com/deeplearning/tensorrt/quick-start-guide/index.html#convert-onnx-engine
问题合集
问题1. CUBLAS报错
报错信息
[ltWrapper.cpp::nvinfer1::rt::CublasLtWrapper::setupHeuristic::327] Error Code 2: Internal Error (Assertion cublasStatus == CUBLAS_STATUS_SUCCESS failed. )
环境信息
- cuda 10.2
- cudnn 8.2
- TensorRT 8.2.1.8
解决方案
cuda10.2有两个补丁,如果打完还是报错,就使用下面这个方法。
在转换命令添加一句–tacticSources=-cublasLt,+cublas
.\trtexec.exe --onnx=erfnet.onnx --tacticSources=-cublasLt,+cublas --saveEngine=erfnet_best.trt --workspace=6144 --iterations=1 --verbose



















 5122
5122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











