







TextRank算法介绍
先说一下自动文摘的方法。自动文摘(Automatic Summarization)的方法主要有两种:Extraction和Abstraction。其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于生成式自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。所以本人学习的也是抽取式的自动文摘方法。
目前主要方法有:
- 基于统计:统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
- 基于图模型:构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
- 基于潜在语义:使用主题模型,挖掘词句隐藏信息。例如,采用LDA,HMM
- 基于整数规划:将文摘问题转为整数线性规划,求全局最优解。
textrank算法
TextRank算法基于PageRank,用于为文本生成关键字和摘要。
PageRank
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式: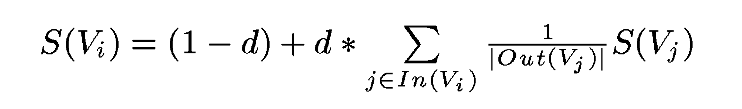
注意事项:
userdict.txt :是我需要增加专业性的词汇的词库data.data :数据集#! /usr/bin/python
# -*- coding: utf8 -*-
# @Time : 2019/3/4 15:40
# @Author : yukang
# 来源:https://blog.youkuaiyun.com/a2099948768/article/details/89189908
import sys
import pandas as pd
import jieba.analyse
"""
TextRank权重;
1,将待抽取关键词的文本进行分词,去停用词,刷选词性
2,以固定窗口大小,词之间的共现关系,构建图
3,计算图中节点的PageRank,注意是无向带权图
"""
# 处理标题和摘要,提取关键词
def getKeywords_textrank(data,topK):
idList, titleList, abstractList = data['id'], data['title'], data['abstract']
ids, titles, keys = [], [], []
for index in range(len(idList)):
text = '%s。%s'%(titleList[index],abstractList[index])
jieba.analyse.set_stop_words('./stop_words.txt') # 加载停用词
print(titleList[index]," 10 Keywords - TextRank:")
keywords = jieba.analyse.textrank(text,topK=topK,allowPOS=('n','nz','v','vd','vn','l','a','d'))
word_split = " ".join(keywords)
print(word_split)
keys.append(word_split.encode("utf-8"))
ids.append(idList[index])
titles.append(titles[index])
result = pd.DataFrame({"id":ids,"title":titles,"key":keys},columns=["id","title","key"])
return result
def main():
dataFile = "./data.data"
data = pd.read_csv(dataFile)
result = getKeywords_textrank(data,10)
print(result)
if __name__ == '__main__':
main()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









