




关键词:新能源功率预测SaaS、风电功率预测、光伏功率预测、AI预测平台、LSTM、Informer、图神经网络GNN、多源气象融合、预测接口API、数据接入、MLOps、模型监控、漂移检测、回退机制、P10/P50/P90、现货交易、偏差考核、虚拟电厂
1. 现实:模型“做出来”不等于产品“卖得出去”
很多团队在新能源功率预测上会卡在同一个阶段:
-
技术侧:
LSTM、Informer、GNN 都能跑起来,指标也不错; -
商务侧:
客户问三句话,项目就推进不动了:-
怎么接入?要改我现有系统吗?
-
能稳定跑一年吗?极端天气会不会崩?
-
出问题谁负责?怎么监控?怎么回退?
-
这说明:新能源功率预测要变成 SaaS,关键不是“模型更复杂”,而是:
产品化:可卖(价值清晰)、可接入(成本低)、可维护(长期稳定)。
本文给出一套工程级框架,把“算法模型”升级为“可交付、可运营、可规模复制”的预测 SaaS。
2. SaaS 视角下,客户真正买的不是模型,而是“结果与责任边界”
新能源客户购买预测服务,本质上想获得三种收益:
-
偏差成本下降:偏差考核、平衡费用减少
-
交易收益提升:日前/日内/现货报量更优化
-
调度执行更稳:爬坡预警、备用与储能策略更合理
因此 SaaS 交付必须回答:
-
交付什么?(输出曲线 + 区间 + 风险事件 + 报表)
-
怎么接入?(接口、协议、字段、频率)
-
怎么保证长期稳定?(监控、回退、漂移、重训)
-
怎么定价?(按容量、按站点、按调用量、按收益分成)
只有把这些“非算法问题”解决,LSTM/Informer/GNN 才能真正变成可卖产品。
3. 总体架构:新能源功率预测 SaaS 的“六层系统”
一个可规模化的预测 SaaS,建议拆成六层:
-
接入层(Ingestion):数据接入与标准化
-
数据层(Data Lake/Feature Store):统一存储与特征管理
-
预测层(Forecast Engine):多模型与融合(LSTM/Informer/GNN)
-
策略层(Optional):交易/调度可执行建议(备用/储能/限电)
-
服务层(API & Delivery):对外接口、推送、权限与计费
-
运维层(MLOps & Observability):监控、回退、漂移、重训、审计
下面逐层拆解“怎么做才可卖、可接入、可维护”。
4. 接入层:决定你能不能规模复制(比模型更关键)
4.1 数据接入的“最小可用集”(MVP)
为了降低客户接入成本,你必须明确最小字段集合。
风电站点最小集:
-
时间戳(统一到 15 分钟或 1 小时)
-
场站总功率(P)
-
可用容量(AvailCap,强烈建议)
-
限电/检修标记(Curtail/Fault,至少其一)
-
站点经纬度、装机容量
-
气象输入(至少 1 套 NWP:风速风向、温度、气压)
光伏站点最小集:
-
时间戳
-
场站总功率
-
可用容量/逆变器可用台数(建议)
-
限电/故障标记
-
辐照度或云量相关变量(至少其一)
-
站点经纬度、装机容量
重要原则:
你要让客户“最快 1–2 天就能接通试用”,否则 SaaS 很难卖。
4.2 接入方式要“多种兼容”,不能只有一种
推荐同时支持:
-
API 拉取(REST/HTTPS)
-
文件投递(SFTP/OSS/对象存储)
-
消息队列(Kafka/MQ,适合大客户)
-
数据库直连(只对少数客户开放)
4.3 时间对齐与质量校验:必须内置
大多数预测失败不是模型,而是:
-
时间戳错位;
-
缺测;
-
乱序;
-
状态标记缺失。
因此 SaaS 接入层必须内置:
-
时间对齐(对齐到整 15 分钟/整点)
-
缺测策略(插值/回退/标记)
-
异常检测(跳点、零值、重复记录)
-
状态一致性校验(限电/可用容量与功率逻辑)
数据质量不做成产品能力,你的售后会非常痛苦。
5. 数据层:Feature Store 是“可维护”的核心
5.1 为什么必须做 Feature Store?
你想做 SaaS,就意味着:
-
不止一个客户;
-
不止一种机型/逆变器;
-
不止一个区域气象;
-
模型要滚动升级;
-
客户要追溯历史结果。
没有 Feature Store,会导致:
-
每个客户一套“脚本式工程”,无法复制;
-
模型升级一次,全链路重写;
-
数据追溯困难,出现争议无法审计。
5.2 Feature Store 应包含哪些内容?
至少包含四类特征:
-
时序特征:功率、残差、移动统计、爬坡特征
-
气象特征:多源 NWP、订正后风场/辐照场
-
状态特征:可用容量、限电、检修、设备状态
-
静态特征:机型、地形、经纬度、容量、站点标签
并提供版本管理:
-
特征版本 v1/v2/v3
-
可追溯:某天某条预测用的哪个版本特征
6. 预测层:LSTM/Informer/GNN 怎么“产品化”?
产品化的关键不是把三个模型都堆上去,而是做成“可配置、可解释、可回退”的预测引擎。
6.1 推荐的模型分工(工程最佳实践)
-
LSTM/GRU:稳定、低成本、短序列与残差修正
-
Informer/Transformer:长序列、趋势与日前/日内形态
-
GNN/GAT:区域级、多场站相关性、聚合预测更稳
对应输出层:
-
单站预测(风/光)
-
区域聚合预测(可选)
-
概率预测 P10/P50/P90(强烈建议)
6.2 SaaS 里的“模型编排”(Model Orchestration)
建议做成可编排流水线:
-
基线预测(传统/电网/客户模型)
-
残差建模(LSTM/GRU)
-
长序列校正(Informer)
-
区域一致性/空间校正(GNN)
-
融合输出(动态权重 + 置信度)
形成最终:
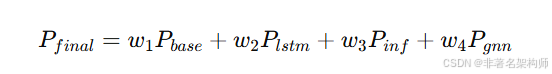
并且权重随天气型/置信度变化。
6.3 “可维护”的关键:必须有回退与熔断
任何 SaaS 预测引擎必须具备:
-
数据缺失回退:回退到基线预测或持久性预测
-
异常漂移回退:模型误差连续异常,自动降权或停用
-
极端天气回退:置信度低时用保守策略(P30/P40)
没有回退,就没有“可维护”。
7. 服务层:可卖的 SaaS 必须“易接入 + 易结算 + 易对接业务”
7.1 输出接口必须标准化(客户最在意)
推荐输出字段(示例):
-
时间戳(t)
-
点预测(P50)
-
区间预测(P10/P90)
-
置信度(confidence)
-
风险事件(ramp_prob, ramp_amp)
-
状态说明(data_quality_flag)
支持:
-
JSON API
-
CSV 推送
-
Webhook 回调
7.2 交付形式要“多层级”
建议按客户成熟度提供三档产品:
-
预测曲线版:只给 P10/P50/P90
-
预测+风险版:加 ramp 预警、置信度、解释
-
预测+策略版:加备用建议/储能计划/限电建议(可选)
这样更容易成交,也更容易做 upsell。
7.3 计费与商业模式:可复制的四种方式
-
按装机容量(元/MW/月)
-
按站点数量(元/站/月)
-
按调用量(API 次数)
-
按收益分成(适合交易侧客户,但合同复杂)
工程建议:
先用“按容量/站点”做标准化报价,
再对大客户提供收益分成或定制方案。
8. 运维层(MLOps):决定你能不能“长期可维护”
预测 SaaS 的最大风险是:
-
模型上线后 3 个月开始漂移;
-
客户说“怎么越来越不准了”;
-
你无法解释,也无法快速修复。
因此必须把 MLOps 做成产品能力。
8.1 必须监控的四类指标(上线必备)
-
数据质量监控:缺测率、延迟、异常点比例
-
模型效果监控:nRMSE、MAE、ramp 命中率
-
分布漂移监控:风速分布、辐照分布、残差分布
-
业务指标监控:偏差电量、考核金额、交易收益(可选)
8.2 漂移检测与自动重训策略
建议采用:
-
每周/每月滚动训练(视数据量)
-
漂移触发重训(当分布变化超过阈值)
-
A/B 灰度发布(新模型先小流量上线)
8.3 审计与可追溯:解决“扯皮”的关键
客户发生争议时,最常见的问题是:
-
“你这条曲线为什么这么报?”
-
“那天不准是谁的责任?”
SaaS 必须做到:
-
每条预测可追溯:
-
输入数据版本
-
特征版本
-
模型版本
-
融合权重
-
-
可导出审计报告(PDF/CSV)
可追溯性是 SaaS 的护城河。
9. 如何让产品“可卖”?售前必须讲清楚三件事
9.1 价值证明:用“业务指标”而不是“模型指标”
客户不买 nRMSE,客户买的是:
-
偏差考核少多少;
-
现货收益多多少;
-
储能利用率提升多少。
因此你的售前材料必须有:
-
“提升 1–2% 的收益账”
-
试点期 KPI 与验收口径
-
风险边界(在什么条件下会下降、如何回退)
9.2 试点方法:2 周跑通,1 个月出结论
建议标准试点流程:
-
第 1 周:数据接入与质量评估
-
第 2 周:基线对比 + 离线回测
-
第 3–4 周:在线并跑(不切换,只对比)
-
第 5 周:输出收益评估与扩容报价
把“试点流程产品化”,成交率会明显上升。
9.3 合同与责任边界:必须写清楚
常见边界条款:
-
数据缺失/错误导致的预测偏差不计入考核;
-
限电/检修未标记导致的误差归客户侧;
-
提供回退机制,保证业务连续性;
-
预测服务用于辅助决策,最终调度执行责任归属明确。
写清楚责任边界,才能做成长期可维护的 SaaS。
10. 结语:从“算法模型”到“预测 SaaS”,关键是工程化与产品化
把 LSTM/Informer/GNN 做成“可卖、可接入、可维护”的新能源功率预测 SaaS,核心不是模型名词,而是这四句话:
-
接入成本要低:一两天能接通,客户才愿意试;
-
输出要可执行:不仅曲线,还要区间、风险、报表;
-
系统要可运维:监控、回退、漂移、重训必须成体系;
-
价值要可量化:用偏差成本与交易收益讲清楚 ROI。
当你把这些做到位,模型就不再是“技术展示”,而是一个可规模复制的产品。


















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











