



基于武汉出租车 GPS数据的网络学习 实证验证
摘要
在先前的研究中,开发了一种统计成本较低的方法,通过仅使用少量智能体组来监测交通网络性能,而无需预测群体流动。本研究利用来自中国武汉的出租车GPS轨迹数据,验证了这种多智能体逆向优化(MAIO)方法。通过使用受控的2062条链路的网络环境以及不同的GPS数据处理算法,在4小时周期内基于真实数据模拟了一个在线监测环境。结果表明,仅使用一对起讫点(OD)对的样本,MAIO方法即可学习网络参数,使得预测出行时间与观测出行时间之间的相关性达到0.23。当将监测范围增加至两对起讫点对时,相关性进一步提高至0.56。
M多项研究已阐明了准确且精确测量城市交通系统属性的重要性。随着大数据和物联网的兴起,出现了许多用于测量交通系统属性的机器学习方法。周[1]综述了这些技术,包括Allahviranloo和Recker[2]用于活动模式预测的应用;蔡等人[3]用于短期交通预测;Luque‐Bae‐na等人[4]用于车辆检测;吕等人[5]用于交通流量预测;以及马等人[6]用于网络拥堵预测。然而,通用的机器学习技术并未专门设计以充分利用城市交通网络的独特结构。
因此,近年来,一种逆问题理论[7]逐渐兴起,用于捕捉网络结构,徐等人将其称为逆向交通问题。[8]如果一个传统模型M将一组参数i转换为一组输出X,即,XMi=^h,则逆向模型旨在基于观测到的输出x来估计参数it,即。M x1 i= -t^ h。文献中已提出了多种类型的逆向交通问题:逆向最短路径[9];针对多种交通问题的逆向线性规划[10];最小费用流问题中的链路容量[11];逆向车辆路径问题[12],[13];均衡模型的广义逆变分不等式[14];以及路径选择[15]。
尽管相关文献日益增多,逆向交通问题旨在采用系统级模型,并根据样本数据估计该模型的参数。这存在一个问题:拥堵的系统需要估算人群属性(如流量)以量化拥堵效应参数,因为系统越拥堵,其异常程度就越高。马等人在[6]中的研究便是此类工作的范例,该研究利用深度受限玻尔兹曼机和循环神经网络,基于出租车轨迹样本数据来估计人群层级流量。另一个挑战在于缺乏对行为机制的考虑。许多推断模型,特别是属于网络断层扫描的模型(见[16]和[17]),能够根据数据解释系统的状态,但无法解释流量属性上的路径选择等行为机制。像[11]中Güler和Hamacher的系统级逆向交通问题会导致NP难问题,难以扩展到实际规模的网络。
徐等人[8]最近提出了一种基于多智能体逆优化(MAIO方法)的理论,该理论通过求解采样多智能体逆向交通问题来推断网络的容量效应,而不是求解单个系统级问题。在此背景下,智能体指的是做出出行决策并与虚拟环境进行交互的个体或集体个体(见[42]和[43])。这一方法的前提是假设所采样的智能体表现出诸如路径选择偏好等行为特征。该模型利用智能体逆最短路径问题的样本,推断出拥堵路段的容量对偶变量。该方法不仅量化并解释了网络中的拥堵情况——即不仅说明拥堵程度,还揭示每个路段的拥堵如何影响网络其余部分(相较于[6]中的方法更具可解释性);也就是说,我们不仅仅是预测网络中的行程时间,而是解释由于网络某一部分的拥堵而导致另一部分行程时间的变化。通过对纽约皇后区高速公路网络的查询数据进行模型测试,结果表明该方法能够随时间监控网络,并利用样本更新网络的链路容量效应。
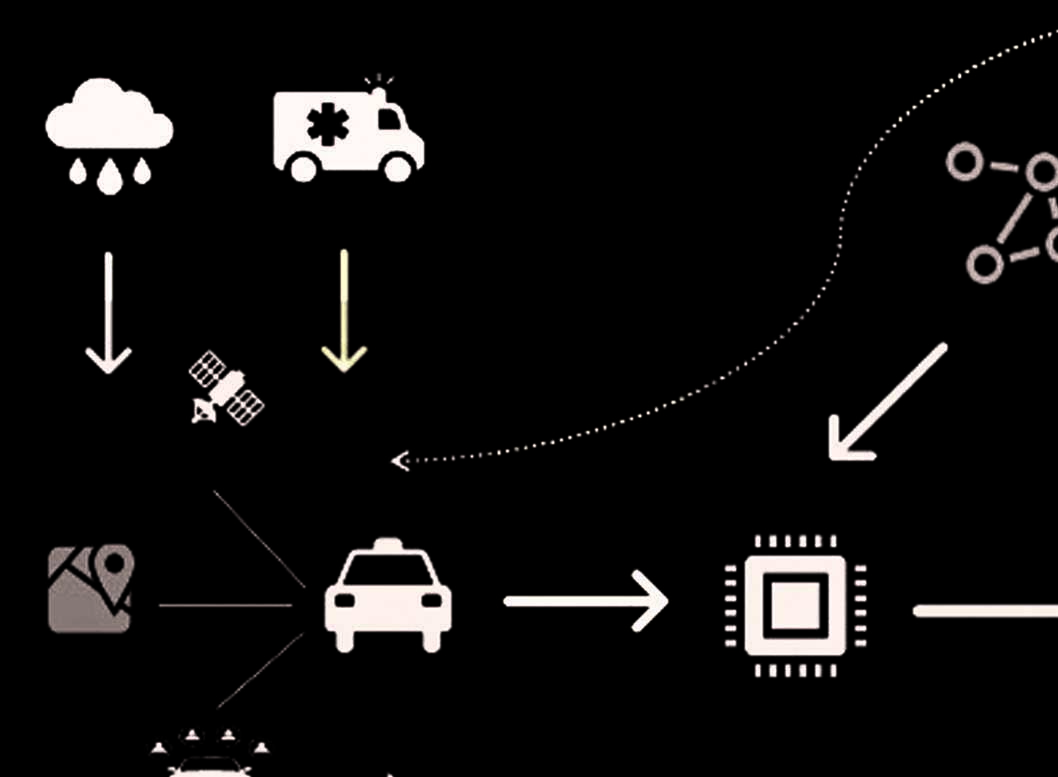
之前的研究提出了该方法的理论,并使用受控数据环境进行了验证,该环境基于在皇后区56个不同潜在起点‐终点(OD)对之间的查询路径。尽管行程时间对应于真实数据,但1)随时间推移对OD对的采样并非基于实际的信息需求,且2)实际路径选择被假定为与谷歌查询相同,而非来自实地收集的实际选择。在实践中,该方法需要服务于如图1所示的系统设计。系统设计的成功取决于终端用户的样本数据来源(例如,众包参与者如谷歌Waze,或受监管出租车的GPS数据,或两者兼有)。如果从实地收集的路径数据仅对应于特定OD需求,那么哪些OD需求能够充分监测网络,以及需要多少样本?
本文的贡献在于一项实证研究,用于验证以下实施问题:利用从受控数量的OD对收集的实际路径选择实地数据,我们能否有效使用[8]中的MAIO方法对中国武汉的2062条链路的网络进行监控?在[8],中进行了一项实验在实验室中定期通过外部查询路径进行,以评估算法的性能。由于网络监控的数据源来自现有传感器(谷歌),因此仅验证了算法对状态变化的敏感性,而未验证该方法在感知和推断两方面的有效性。本研究使用了反映网络内出行者实际拥堵体验的采样率下的真实轨迹数据,检验了利用网络中两对起讫点的采样数据同时作为传感器和推断机制的有效性。通过仅使用两对起讫点证明其有效性,本研究为可利用多个起讫点对轨迹的更大规模监控系统提供了可信支持。

如图1所示,监控系统需要对GPS轨迹数据进行处理,以将其映射到网络数据结构,或使用能够自动以网络数据结构输出位置数据的数据采集设备。由于许多数据源仅提供GPS数据,我们还提出了将位置数据与网络数据结构相匹配的映射算法。
文献综述
在现实环境中,获取网络中交通数据的一种方法是利用配备GPS的车辆。杰内利乌斯和库特索普oulos[18]将这类数据称为浮动车数据,即安装了全球定位系统设备的车辆以固定的时间间隔记录其位置和速度,时间间隔范围从几秒到几分钟。作为城市交通系统的重要组成部分,出租车为城市居民提供全天候、便捷、舒适和个性化的出行服务,并在城市客运移动性发展中发挥关键作用[19]。出租车GPS轨迹数据已广泛应用于交通研究中,包括行程时间估计[20],[21]和出行行为分析[22]–[25],,或用于推断城市的出行动量[26],[27]。此类探针数据有助于评估经常性与非经常性事件,以减轻其对交通的影响。例如[39]–[41],,可将GPS数据与其他传感器和计数数据结合,以监测事件随着时间推移的影响。
基于出租车全球定位系统轨迹和数据挖掘技术,我们可以实时获取有经验的出租车司机的路径选择行为,并为公众提供最短路径最优选择的指导[28]。尽管关于出租车运营和路径选择分析已有大量研究,但在本案例研究中,我们并不旨在分析出租车司机实际出行行为或其活动分析。出租车轨迹数据被用作抽样的异质代理信息,以在大型网络中测试MAIO方法。
有许多使用不同交通数据的网络拥堵推断方法。瓦尔迪[16]以及特巴尔迪和韦斯特[17]在网络断层扫描方面的早期研究提出了从观测到的链路计数数据中估计流量分布的方法。其他研究则试图整合路径选择在估计[29]–[33]中的行为机制。已有研究提出深度学习模型用于捕捉网络拥堵[6]。贝特西马斯等人提出了系统级逆向交通问题,以估计出租车的路径流量,使其具有一致的网络拥堵特征[34],,他们建议在优化目标函数中增加一项,对观测到的行程时间与路径上各链路行程时间之和之间的差异进行惩罚。
徐等人提出的MAIO方法[8]在目标函数中引入了对偶变量。对偶变量的值以行程时间的形式表示网络状态(如拥堵效应)的变化。尽管该方法没有显式地建模交通流动力学,但它通过线性优化模型[44]估计这些效应,从而隐式地捕捉了交通流动态。
徐等人[8]定义了一个网络,GNA^ h,该网络接收来自一组从起点节点rNi!到终点节点sNi!的智能体样本P的观测。在MAIO方法中,我们假设每个智能体iP!是理性的,其穿越的网络被建模为一个带容量的多商品问题,以矩阵形式表示于(1)–(4)中,其中,ca aA!为自由流链路成本,xm为OD对mM!的流量,A为节点‐链路关联矩阵,bm在OD对m的源节点处为q +m,在汇节点处为qm,其余为0。ua aA!为链路容量。当路径选择涉及更多因素时(例如,在多式联运网络中),可估计一个路径选择模型,以确定一个广义成本函数来替代.ca
, min c x
m T m x/ (1)
受限于
, , Ax b m M m m 6! = (2) , x u
m M
m#
!
/ (3)
, . x m M 0 m 6 $ ! (4)
解决此问题的方法可以包括分解为一个受限主问题,以确定对应于路段容量的对偶变量wa。ua 基于这些对偶变量,每个OD对的子问题随后可以以非捆绑形式作为无约束问题求解最短路径问题如(5)–(7)所示,其中b是一个向量,在起点处为+1,在,1-目的地处为,其他情况下为0。z表示最短路径算子,其中-1 z是逆算子。对偶化链路成本为成本,ca r,即。c c wa a a=+r当没有拥堵时,。w 0 a=当存在足够引起路径选择行为变化的拥堵时,。w 0 a2
, min c w y T y
z=+ ^ h (5)
受限于
, Ay =b (6) ,, . y a A 0 1 a! ! “, (7)
MAIO方法利用该结构来估计每个智能体对,wa的感知,记为.wa i在逆问题中,我们观察到每个智能体.iP!的yi )。如果所选路径是根据自由流条件下的最短路径,则w0a, i$在所选路径上成立。如果选择了其他路径,则需要增加自由流条件下更短路径的wa i。以最优方式增加这些值以适应每个智能体,便构成了一个逆最短路径问题,如公式(8)–(12)所示,该问题由阿胡贾和奥尔林[10],推导为一个线性规划,其中vi是无界的节点势。该问题假设每条链路容量约束的先验对偶变量已知,.wr目标是最小程度地偏离先验值,从而基于观察到的智能体选择路径yi[,获得新的对偶变量wwefi ii= ‐+r,针对智能体iP!(8)],满足弱对偶条件[(9)],强对偶条件[(10)],容量对偶变量可行性条件[(11)],以及非负性约束[(12)]。,,wgwyi iii1z= ) )‐r^ h是智能体起讫点位置的函数,表示为其图参数,gi、先验值以及所选路径.yi )
, min e f
,, e f v i i i 1
i i i
z=+ -(8)
受限于
, A v c w e f T i i i #+-+ r (9) , b v c w e f y T i i i T =+-+ ) r ^ h (10) , e f w i i -# r (11) , . f e 0 i i $
在在线环境中,我们假设群体P随时间依次到达。在这种情况下,w r 的值从先前的智能体观测i 1-获得w w= i 1 ) r,并用于将当前观测i输入以更新。wi )。这在算法1中进行了总结。该算法利用逆向最短路径问题,其计算效率与其他最短路径算法相当(参见[8]),且已知可用logOn n^ h的效率求解。因此,该算法将轨迹数据作为传感器,并结合路线决策来支持推断。
 )
)
在[8],中,唯一进行的验证是通过在实验室中定期查询外部(谷歌)路径,来检验算法对网络中状态变化的敏感性。但这并未验证该方法在感知和推断两方面的有效性,而要验证这一点,需要真实现场数据以及一个精心设计的实验,将这些数据与使用相同数据进行推断感知的结果进行比较。尚未开展任何测试来验证输出对偶变量作为来自真实数据的推断和传感器之间的相关性。如果没有这一点,就缺乏关于该方法本身以这种方式工作的实证证据,而这是交通网络管理者考虑采用该技术所必需的。
实验设计建议
我们使用来自中国武汉的真实出租车数据测试了MAIO方法。在观察到出租车沿路段的行程时间后,我们能否证明由受监控路段的对偶变量生成的行程时间与在线运行仿真下的实际行程时间之间存在相关性?这就是本实证研究需要解决的研究问题。我们考虑了以下评估标准:
- 预测路线与实际路线选择的对比
- 实际行程时间与估计行程时间相关性的计算。
基于这两个标准,我们设计了一个涉及多时间间隔观测的实验,并评估了MAIO方法的性能。我们的目标是证明,即使在起讫点数据有限的情况下,当我们从一个起讫点对采样增加到两个时,监控系统的准确性仍能得到提升,因为增加了采样…
信息只会改善输出。
数据准备:网络
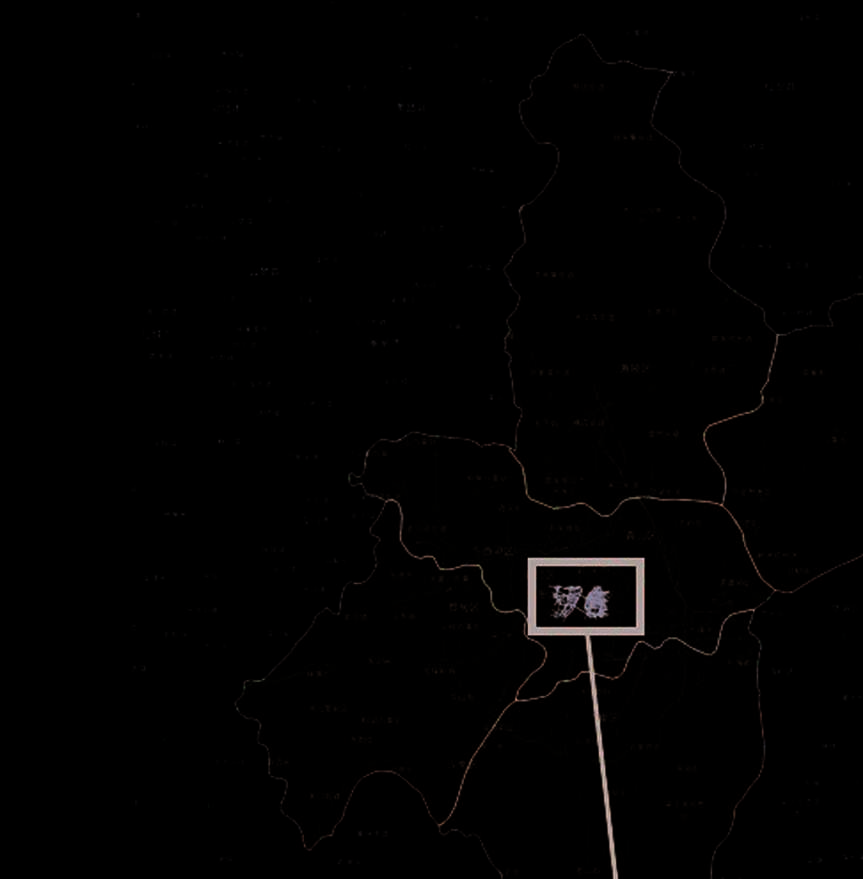
数据包含来自中国武汉的出租车GPS轨迹。武汉是中国湖北省的省会,人口为1100万(中国第九大城市)。在特大城市拥堵榜单[36],中,武汉排名第10位。如图2所示,武汉由长江分隔的13个区组成。汉阳和武昌区构成武汉城市核心区的一部分,且均有地铁线路覆盖。
中国武汉的一个城市交通网络叠加在OpenStreetMap上,如图3所示。该网络的属性数据可在GitHub上获取[38]。自由流路段行程时间(FF时间)的采样数据见表1。提取的城市路网包含2,833条路段和855个节点。该网络设计用于监测两对起讫点(见图3中的红点):汉阳区(4号线和6号线)的站点到武昌火车站(武昌区,4号线和7号线),以及中家村站到潘谢家站(武昌区,2号线和7号线),这些站点是从城市上下车热点中选取的。
2014年5月6日上午5:00至9:00的4小时出租车轨迹数据用于测试的时段是全天高峰时段,如图4中的每日出行时间所示。所分析的时段代表非平稳的出行量,因此如果该方法对此有效,则将其扩展到其他时段也是轻而易举的。
使用全球定位系统坐标的路径重建算法总结在算法2–5中。处理后的路径数据、网络信息以及网络学习代码均位于GitHub[38]网站上。
 )
)
| 链路ID (a) | 起始节点ID(O) | 终止节点ID (D) | 时自间由_流秒(c) |
|---|---|---|---|
| 9 | 12 | 1500 | 16.04 |
| 10 | 12 | 588 | 9.34 |
| 13 | 20 | 1516 | 7.03 |
| 14 | 20 | 1504 | 37.43 |
| 15 | 20 | 28 | 5.06 |
| 16 | 22 | 237 | 17.09 |
| 17 | 22 | 1298 | 14.14 |
| 18 | 22 | 17 | 2.66 |
| 19 | 28 | 20 | 5.2 |
表1. 网络研究中链路属性的一个样本。

数据准备:仿真设置
网络在自由流条件下启动。每当获取新的路径信息(例如,来自出租车GPS记录)时,MAIO方法会持续更新整个网络的出行成本。当获得新路径时,我们使用算法1来更新链路容量对路径的影响,以使观测路径为智能体认为最优的。在此情况下,我们对系统进行4小时的监控和更新。
实验步骤如下:1)以中国武汉城市交通网络中所有路段的对偶变量初始值为零开始。2)从早上5:00开始,每隔5分钟直至早上9:00:
- 对于该时段内到达的所有轨迹,识别起讫点对。
- 运行路径重建算法(见算法2–5)以获取每个起讫点对的实时出行者选择(在此步骤中,假设出行者的选择为最短路径)。
- 比较预测路线和选择的实际路线。
- 运行算法1,基于重建的路径更新链路对偶变量。
- 计算实际与估计行程时间之间的相关性。
当网络中出现拥堵时,网络学习算法应认识到容量对路径转移的影响(参见图5,以了解这些变化在不同时间间隔内的示意图)。对偶变量应反映那些变得更加拥堵的路段建议采用起作用的容量效应,从而导致路径分流。对偶变量的数值大小应能相对衡量该链路相对于其他链路的容量不足程度。
 )
)
数据准备:出租车轨迹
该市每天约有8,200辆出租车运营16小时。本测试所使用的数据集称为武汉出租车(COWT)数据,包含武汉市所有注册出租车的GPS轨迹。每条GPS记录包含出租车ID、经度/纬度、时间戳、瞬时速度和航向,以及运营和载客状态信息,如表2所示。两个数据点之间的最小间隔约为15秒,最大间隔为2分钟。
| IDa | 时间戳b | 经度 | 纬度 | 角度c | 速度d | 操作状态e |
|---|---|---|---|---|---|---|
| 10287 | 2014年4月5日 23:59 | 114.300472 | 30.557818 | 64 | 20 | 操作 0 |
| 12448 | 2014年4月5日 23:59 | 114.137636 | 30.600324 | 55 | 15 | 操作 0 |
| 4864 | 2014年4月5日 23:59 | 114.214882 | 30.571331 | 94 | 51 | 操作 1 |
| 8695 | 2014年4月5日 23:59 | 114.320283 | 30.636952 | 0 | 0 | 操作 0 |
| 8538 | 2014年4月5日 23:59 | 114.298862 | 30.602568 | 0 | 0 | 操作 1 |
| 2034 | 2014年4月5日 23:59 | 114.197638 | 30.558353 | 0 | 0 | 操作 0 |
| 6700 | 2014年4月5日 23:59 | 114.323372 | 30.521492 | 0 | 1 | 操作 0 |
| 5620 | 2014年4月5日 23:59 | 114.415055 | 30.478973 | 184 | 54 | 操作 0 |
| 10179 | 2014年4月5日 23:59 | 114.282767 | 30.612157 | 190 | 25 | 操作 0 |
表2. COWT数据的一个样本
仿真的关键步骤是根据出租车的GPS行程轨迹重建其实际路径。
数据准备:热点识别
轨迹根据观察到的载客状态被划分为载客和空驶行程。对2014年5月6日的行程起终点分布进行了分析,预计上下车点更可能发生在热点区域。因此,在QGIS3.4中创建了出租车上下车点的热力图,如图6(a)所示。热力图分别显示了上车点和下车点的高密度区域。使用QGIS中的热点分析插件从热力图中提取聚类,并在图6(b)中标识为热点。在此实验中,我们选择中佳村地铁站作为起点,另选两个地铁站——武昌火车站和彭徐家作为目的地,以构建一个受控环境。
 中国武汉2014年5月6日出租车上下车热力图。(b)2014年5月6日出租车上下车热点及测试所研究的起讫点。)
中国武汉2014年5月6日出租车上下车热力图。(b)2014年5月6日出租车上下车热点及测试所研究的起讫点。)
数据准备:行程提取
我们将trip定义为出租车从接客到送客的行程。由于COWT数据提供了状态信息,当状态从0变为1时,我们认为出租车接载了乘客;当状态从1变为0时,我们认为出租车卸载了乘客。“行程轨迹”指的是在行程的一部分期间生成的GPS记录,这意味着该期间的状态始终为1。一条行程轨迹。一旦确定了每次实验的OD对,我们便选择那些起点位置接近(在特定阈值c内,例如500米)出发地且终点位置接近目的地的行程轨迹,如算法2所示(参见“算法符号说明”)。
数据准备:道路网络抽象
OpenStreetMap矢量文件包含多个要素,每个要素表示现实世界中的一段道路,并具有一系列GPS点。我们通过为每个要素从第一个GPS点到最后一个点绘制一条有向边,从而得到一个有向图要素。如果一个要素具有单向属性,B则相应道路为双向的。因此,我们为这类要素在相反方向添加一条额外的有向边。将所有有向边的集合记为。E每条有向边有两个端点,其权重等于自由流时间,计算公式为/,长度最高速度其中长度由要素测量得到,最高速度是该要素的一个属性,表示道路的限速。最高速度的缺失值根据属性f class(用于识别道路类型的标签)进行填充。
考虑到存在许多长度较短的道路,尤其是在十字路口和环形交叉口处,我们通过合并彼此接近的端点并将其替换为质心来移除此类道路(边)(参见算法3)。我们将接近定义为小于预定义阈值,b,例如50米。算法3的输出是一个有向图,G N A=^ h,其中N是质心(节点)的集合,A是弧的集合。
网格方法(参见[35]中的几何哈希)在算法3中用于加速,其主要思想是首先确定道路网络的边界,并根据边界的边长将网络划分为相同大小的网格,然后在相邻网格中搜索最近的节点(曼哈顿距离不超过一个网格的长度)。在具体实现中,每个节点在其八个相邻网格中均有一个副本。现在只需在一个网格内搜索最近的节点,从而大大减少了搜索时间(暴力搜索方法必须遍历所有节点以计算它们之间的距离)。
数据准备:最佳匹配路径
仿真的关键步骤是根据出租车的GPS行程轨迹重建其实际路径。然而,给定有向图上的起讫点对,即使节点和路段并非全部已知,仍存在多条从起点出发并以目的地结束的候选路径。
可在候选路径中选择最佳匹配路径,我们在此提供最佳匹配路径的定义。
定义3.1
给定一个有向图,GNA^ h和一条行程轨迹,,,Tp p p m 1 2 f=6@,由GPS点组成,其中A由表示地图上实际道路的路段组成。每个pi是一个包含经度的观测GPS点以及纬度信息。设ta^ h为链路a的尾部,ha^ h为头部,ca为链路a的长度。“最佳匹配路径”,,,Baaa k 1 2 f=”,aAi!^ h是一条最短长度的有向路径:argminchataB aBaii1R= ! + ^ ^ hh”;ik 1 1 6= f‐,,:,jkdpa 1 i = 1 1 6= f‐,其中,,dp a^ h是点p与链路a之间的投影距离,c是一个预定义阈值。
考虑到1)潜在的GPS误差会给最佳匹配路径的搜索带来困难,以及2)相邻GPS记录之间相对较大的时间间隔可能导致许多可能路径,我们的路径重建算法基于以下两个假设: 1)GPS误差不超过阈值.c2)作为理性人,出租车司机通常会在相邻GPS点采集时刻之间选择最短路径。
数据准备:路径重建
路径重建存在一些困难。首先,GPS点存在一定不准确性。仅通过返回最近的链路来判断出租车所在道路并不总是正确的。考虑以下三种情况:1)出租车在一条双向道路上,暴力搜索方法返回了与正确方向相反的链路;2)一条高速公路正好位于某条道路的上方,当出租车实际行驶在道路时,暴力搜索方法却返回了高速公路,或反之;3)出租车靠近两条道路的交叉路口,暴力搜索方法返回了与正确链路相交的链路。
其次,即使我们能够确定两个连续GPS点的道路信息,这两条道路也可能是不连续的,因为两个数据点之间的时间间隔可能足够长,足以经过多条道路(通过一个街区可能仅需20秒)。我们需要进行数据填补。例如,当出租车穿过武汉长江隧道时,由于信号差而没有GPS记录。然而,我们可以利用进入隧道前的最后一个GPS记录和出隧道后的第一个GPS记录来推断缺失的道路(隧道)。最后,我们必须从一条GPS轨迹的若干可能路径中选择最佳匹配路径。
针对第一个困难,我们为行程轨迹上的每个点找到若干链路(弧)候选(见算法3)。对于第二个困难,每次我们获得相邻GPS点的链路候选集合X和Y,对每个头
:O起点:D终点:E有向边集合E,表示现实道路:G由道路网络抽象算法输出的有向图G:N节点(中心点)集合N: A弧(链路)集合A,a,b和:c分别为搜索靠近起讫点、邻近节点和候选链路的GPS点的邻近阈值:M节点ID与节点GPS之间的一对多映射M:T从起点到终点的一条行程轨迹T:B“最佳匹配路径”B,包含最符合GPS行程轨迹的一系列链路:h道路上(链路上)的等距点(空洞)h
算法符号说明
算法2:行程提取。
算法3:道路网络抽象。
算法4:获取链路候选集。
算法5:获取最佳匹配路径。
| 节点数量 | 855 |
|---|---|
| 链路数量 | 2,833 |
| 观测时段 | 上午5:00至9:00 2014年5月6日 |
| 观测平均间隔时间 | 5分钟 |
| 时间间隔数量 | 48 |
| OD1观测到的样本数量 | 132 |
| OD2观测到的样本数量 | 48 |
| OD1采取的不同路径数量 | 53 |
| OD2采取的不同路径数量 | 29 |
| 平均观测路径行程时间/自由流行程时间比值 | 2.72 |
表3. 实验参数摘要。
这表明MAIO方法的有效性取决于在不同OD对之间的有效采样,以实现对网络更全面的覆盖。
基于武汉出租车 GPS数据的网络学习 实证验证
结果
在线监控仿真
我们首先考虑单个起讫点对(OD 1:中佳村站到武昌火车站)。MAIO方法在MATLAB R2017a中实现,并调用IBM ILOG CPLEX优化工作室v12.8来求解式(8)–(12)中的逆最短路径问题。每次更新对偶变量的运行耗时不到一秒。
 研究网络中链路对偶变量在4小时周期内通过算法2.1估计的轨迹。(来源:OpenStreetMaps))
研究网络中链路对偶变量在4小时周期内通过算法2.1估计的轨迹。(来源:OpenStreetMaps))
图8(a)展示了链路对偶变量(起作用的)在每次新观测更新过程中的轨迹变化。该图基于132个观测到的个体路径选择,说明了该方法对随时间变化的网络参数的敏感性。共有409条链路被经过从中家村站到武昌火车站的出租车,上午5:00至9:00,25条链路的对偶变量为正。这些链路在地图上以红色突出显示,对偶变量较高的链路已标注。
如果该结果成立,则表明在上午6:35之前,交通走廊附近的道路路段1,708具有最高的对偶变量(即446秒),这意味着在上午6:35至7:25拥堵消除之前,链路1,708是拥堵最严重的路段。随后出现了110秒的轻微延误,并且直到上午7:55才恢复至0。这表明早前的拥堵高峰是由某一事件引起的,因其未持续存在。另一方面,链路1733在整个时间段内均表现出持续性拥堵,表明其在周期性拥堵效应下承受着高负荷使用。这些结果验证了徐等人[8]的方法能够估计真实城市交通网络中的对偶变量(或拥堵效应),从而为决策者提供可解释的洞察。
如果我们从多条OD路径进行采样,而不是仅从一条路径采样(即更改了我们的抽样框架),会发生什么?我们在观察中增加了一个OD对(OD 2: 48),并重新运行实验,以查看网络状态如何变化。链路对偶变量的时序分布看起来有很大不同。在图8(b)左侧映射了被观测的路段,而在图8(b)右侧的分布中显示了链路对偶变量的更新情况。与之前相比,链路1,708的对偶变量显著下降,仅监控单个起讫点。这表明方法的有效性依赖于在不同起讫点对之间的有效采样,以实现对网络更全面的覆盖。仅关注有限起讫点对的数据可能会降低量级估计的准确性。当考虑网络不同部分的更多路径观察时,它们会提供关于对偶变量的更多信息,从而改变重叠的其他路径的数值大小。理想情况下,应采样每个对,但这并不总是可行的。
 随着新的起讫点被加入网络,根据新观察更新的对偶变量。(来源:OpenStreetMaps。))
随着新的起讫点被加入网络,根据新观察更新的对偶变量。(来源:OpenStreetMaps。))
观测行程时间与在线监控之间的相关性
最后,我们对实际行程时间与估计行程时间进行了比较,以展示估计精度的提升。需要说明的是,这些数据仅来自两对起讫点对,因此我们并不期望得到一个完整的图景。相反,我们旨在证明,即使仅通过两对起讫点对采样,我们仍能对整个网络的监测实现一定的准确性,并且相较于仅使用一个起讫点对采样的情况,其准确性有所提升。

图9展示了所有观察到的路径选择中,估计行程时间(即自由流行程时间加上已行驶路段上的估计对偶变量)与实际行程时间(即每段行程中最后一个GPS点的时间戳减去第一个GPS点的时间戳)之间的相似性。共有180个观察值,其中44个观察值来自新的起讫点。
我们可以从中得出两个结论。首先,基于MAIO方法并使用两对起讫点采样的图估计明显比仅使用单个起讫点采样更准确。其次,当我们计算观测与估计的行程时间之间的相关性时,我们发现单个和两对起讫点的相关性值分别为0.23和0.56。
我们对单个和两个起讫点情景下估计行程时间与观测出行时间的[45]之间的n 132 180 = ” ,观察的相关性进行假设检验。我们检验:H 0 0 t=相对于备择:H 0 A !t ,并得到以下检验统计量:
.
.
., .
.
.
t r r n p
r r n 1 2 1 0 23 0 23 132 2 2 69 0 008
1 2 1 0 56 0 56 180 2
2 2
2 2 5
singleOD
two ODs
)
)
= –= –= =
)
) -., . t p 9 02 1 #10 = = = =
^ ^ h h
p 值小于显著性水平 0.05,因此可以得出结论:仅使用两对起讫点即可获得具有统计显著性的相关性。这验证了仅从两对起讫点对进行采样便能较好地反映实际网络状况,并且相较于一个起讫点对采样,相关性显著提升(超过两倍)。这表明 MAIO方法与真实观察结果具有良好的拟合度。该方法是一种统计成本较低的方法,因为它无需预测人口流动。具体而言,结果表明,从业者可以建立一个监控系统,通过随时间观察在受控的起讫点对集合上所做的路径选择——利用这些结果来解释整个网络中的拥堵效应实时评估干预策略,如图1所示。
徐结等论人在[8]中提出的MAIO模型仅使用GPS探测样本推断整个网络的容量效应,而无需进行预测人口流动这一统计成本较高的步骤。然而,早期的研究仅提供了基于真实数据的理论论证和数值示例,未对方法在监控系统中的准确性进行验证。我们通过在受控网络环境中将MAIO方法应用于出租车GPS数据以模拟在线环境,解决了这一研究空白。
从本次实证验证实验中得出若干结论。诸如链路容量对偶变量之类的网络系统属性,仅通过个体路径观测样本(例如出租车GPS轨迹)即可更新,而无需估计总路段或路径流量。这表明MAIO方法能够以较低成本持续监测交通网络的系统性能。对偶变量的变化显示,推断模型对系统变化具有敏感性。在研究期间,上午5:00至9:00交通量增加,导致更多回流和事件影响链路容量,如图8所示,对偶变量集合平均值呈现稳步上升趋势。推断的准确性通过基于MAIO方法更新的对偶变量所得到的观测与估计的行程时间之间的相关性得以体现。视觉对比(见图9)表明了二者之间的相似性,并显示出从一对OD对采样到两对OD对时结果有所改善。两对起讫点对的相关性更高,表明MAIO方法在以行程时间形式估计对偶变量(或拥堵效应)方面表现良好,且来自其他OD对的更多观测将进一步提升模型性能。
本文面临的主要困难之一是数据处理,即如何从原始出租车GPS轨迹中提取并重建最佳匹配路径。必须考虑GPS误差以及相邻GPS点之间的大间隔所导致的信息缺失问题。路径重构过程通过实施多种算法来完成:行程提取算法获取满足实验要求的轨迹,道路网络抽象算法将复杂地图转换为有向图,候选边算法为每个GPS点找到候选边,最优路径选择算法则应用各种剪枝与加速技术,以高效地从大量候选路径中为每条轨迹选择最佳匹配路径。
未来的工作应在现实环境中实施图1中描述的系统,使用地理信息系统工具,并通过预定义阈值进行监控,以对对偶变量设置警报在线仪表板。相关工作还可以包括在灾前、灾中和灾后监控网络,以量化由于容量退化导致的对偶价格上升的影响。由于用户GPS数据可能因隐私问题而无法自由共享,我们可以尝试使用区块链设计来匿名化用户共享的GPS数据,或建立一个面向差分隐私的数据库[1]。

















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









