







文章目录
回溯核心思想
1 组合问题I
1.1 题目描述
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
示例 2:
输入:n = 1, k = 1
输出:[[1]]
1.2 解题思路
- 终止条件,当符合条件的结果集合>=k时,将结果输出。我们通常会使用两个全局数组,一个时path(一维),来存储符合条件的结果集合,另一个result,存储所有符合条件的集合(二维)
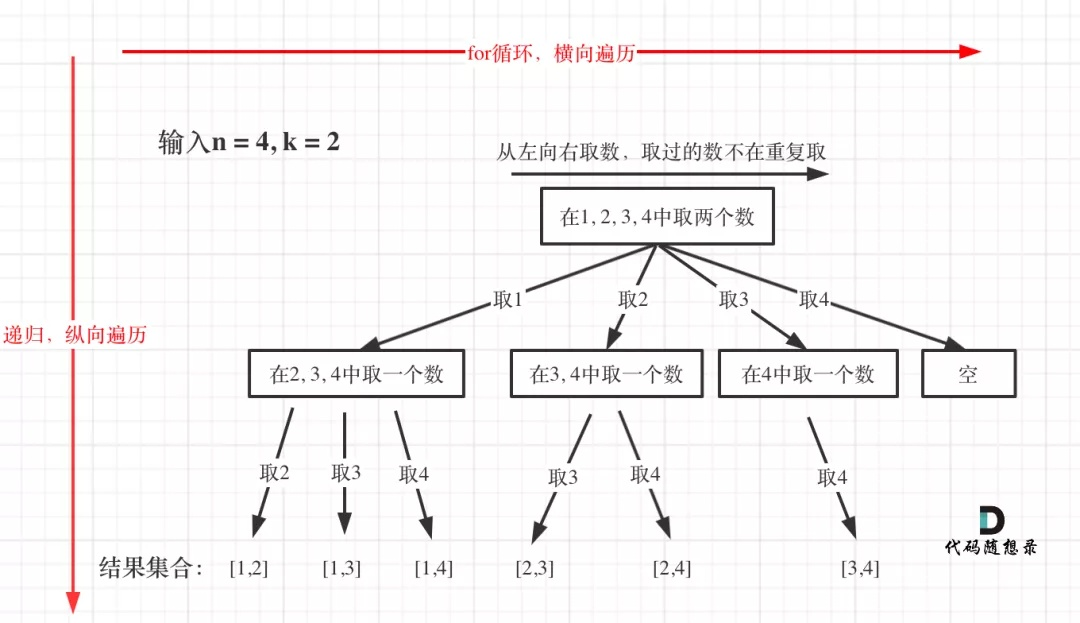
1.3 核心代码
void backTrack(int startIndex, int n, int k){
if(path.size() >= k){
lists.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i <= n; i++) {
path.add(i);
backTrack(i+1, n, k);
path.remove(path.size() - 1);
}
}
2 组合问题II
2.1 题目描述
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
LeetCode 78
2.2 解题思路
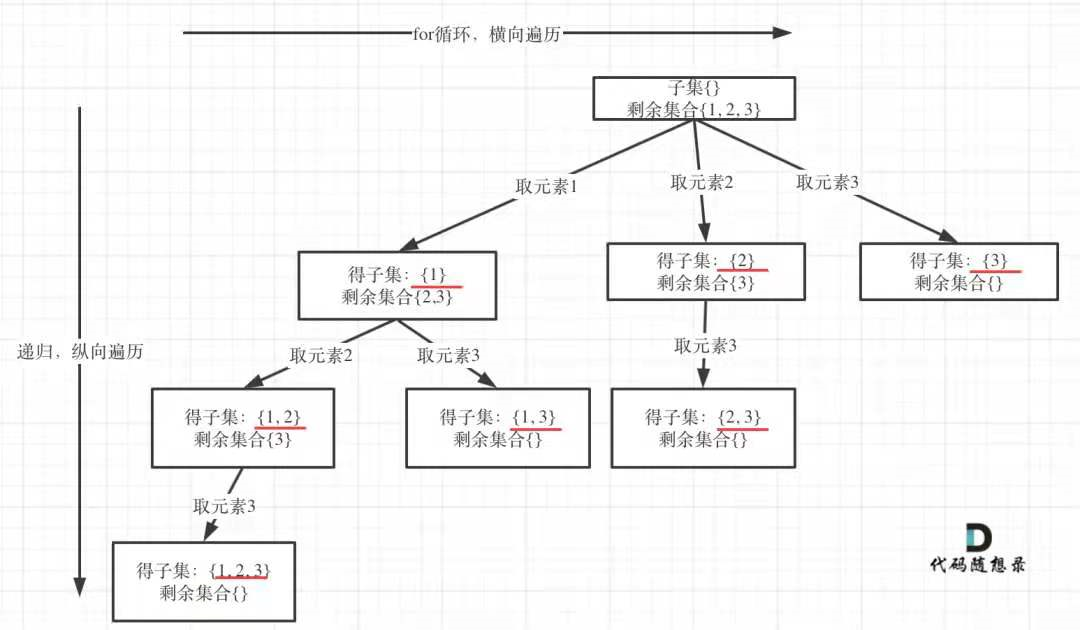
将每一步添加到path中的内容进行输出,然后再从可选集合中选取元素进行加入。可选集合为startIndex之后的元素。
2.3 核心代码
public void backTracking(int[] nums, int startIndex){
list.add(new ArrayList<>(path));
if(path.size() >= nums.length){
return;
}
for (int i = startIndex; i < nums.length; i++) {
path.add(nums[i]);
backTracking(nums, i + 1);
path.remove(path.size()-1);
}
}
3 排列问题
3.1 题目描述
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
LeetCode 46
3.2 解题思路
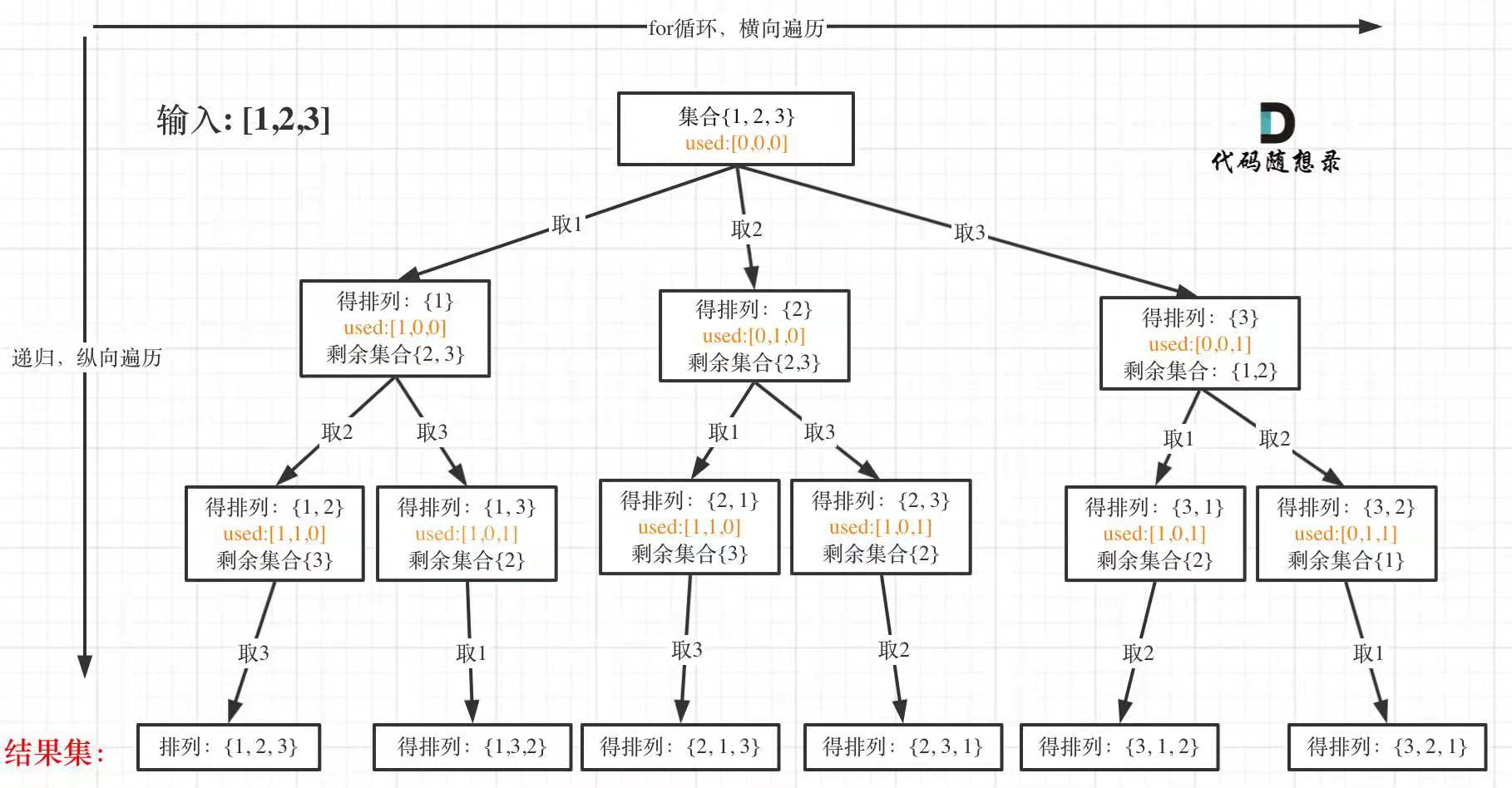
每层遍历时都是从0开始而不是startIndex,使用used数组表征当前元素是否被使用,直到将数组中的元素大于等于n,才将数组进行输出。
public void backTracking(int[] nums, boolean[] used){
if(path.size() >= nums.length){
list.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
if(used[i] == true)
continue;
used[i] = true;
path.add(nums[i]);
backTracking(nums, used);
path.remove(path.size() - 1);
used[i] = false;;
}
return;
}
4 排列问题II
4.1 题目描述
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
LeetCode 47
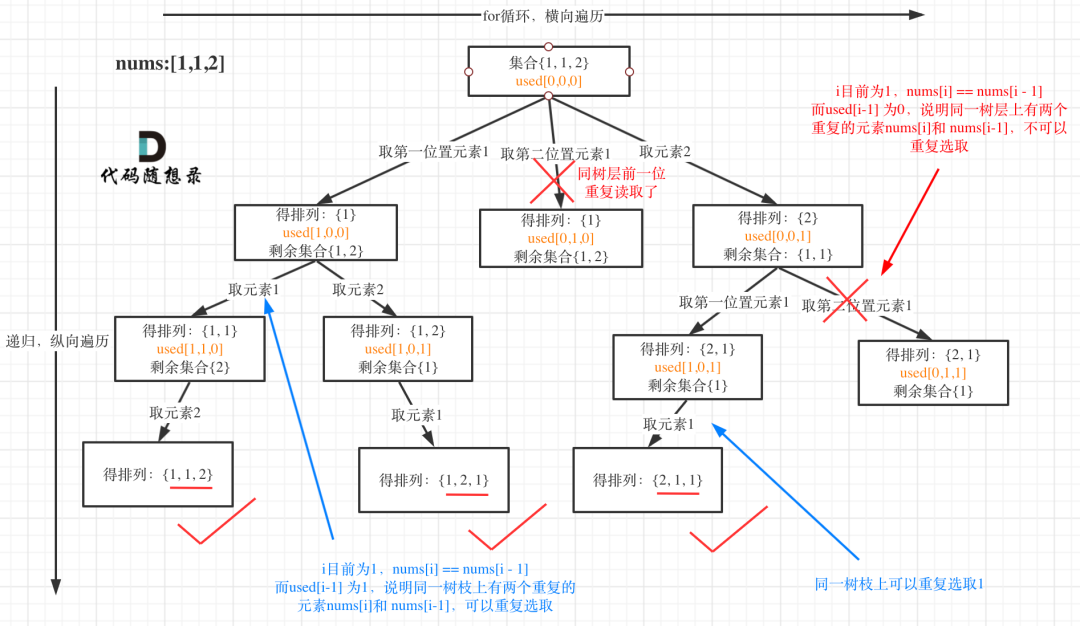
当访问的元素等于前一个元素,并且前一个元素已经使用完时,直接跳过递归。
当然,前提是需要对数组进行排序才可;nums[i] == nums[i-1] 并且 used[i-1] = 0(前一个节点要么已经递归访问退出,要么直接跳过递归continue)
4.2 核心代码
public void backTracking(int[] nums, boolean[] used){
if(path.size() >= nums.length){
list.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
if(used[i] == true || (i > 0 && nums[i] == nums[i-1] && used[i-1] == false))
continue;
used[i] = true;
path.add(nums[i]);
backTracking(nums, used);
path.remove(path.size() - 1);
used[i] = false;;
}
return;
}

















 2140
2140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









