




 本文探讨GPU并行计算的异步和同步模式。异步模式以其速度优势,但存在更新不确定性;同步模式则需等待所有GPU完成计算,达到全局最优,但效率较低。实践中,通常结合两者进行选择。
本文探讨GPU并行计算的异步和同步模式。异步模式以其速度优势,但存在更新不确定性;同步模式则需等待所有GPU完成计算,达到全局最优,但效率较低。实践中,通常结合两者进行选择。
GPU并行计算包括同步模式和异步模式:
异步模式:
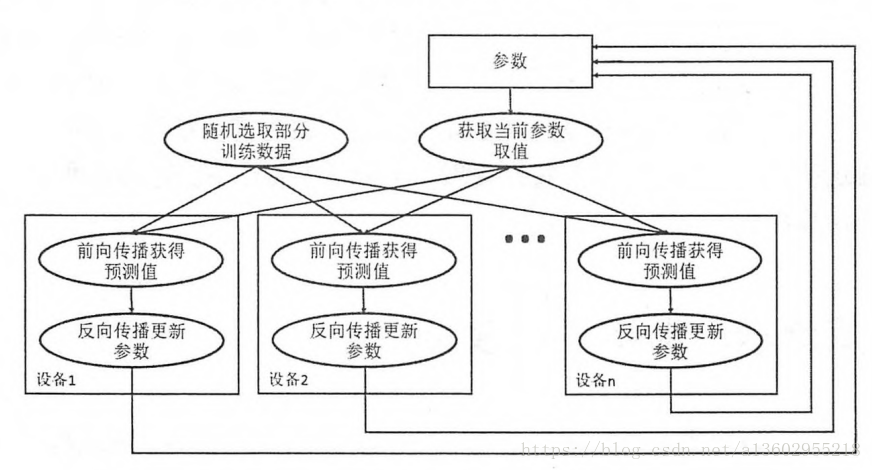
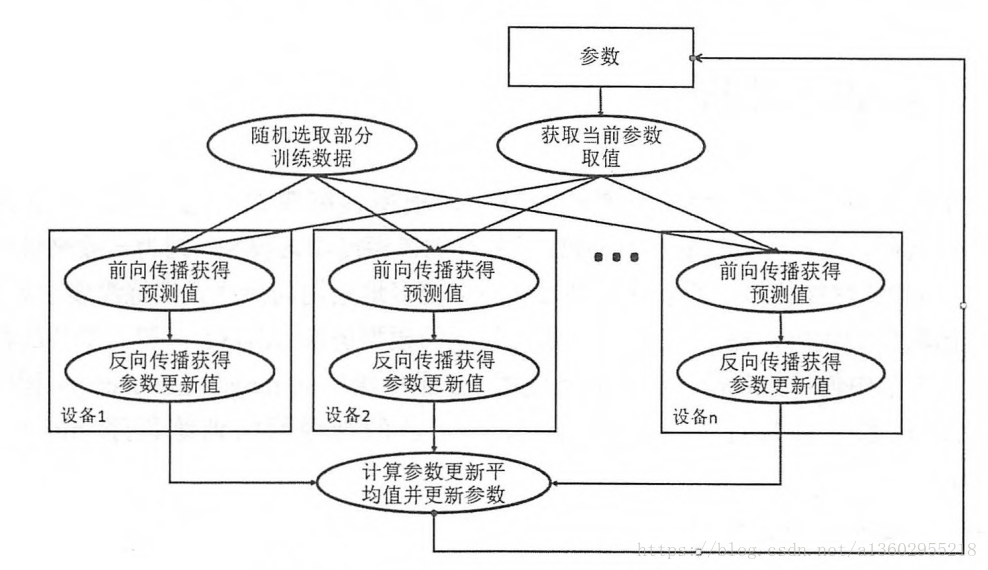
同步模式:
异步模式的特点是速度快,不用等待其他GPU计算完毕再更新,但是更新的不确定性可能导致到达不了全局最优。
同步模式需要等到所有GPU计算完毕,并计算平均梯度,最后赋值,缺点是需要等待最后一个GPU计算完毕,时间较慢。
实践中通常视情况使用上述两种方式。
实例
from datetime import datetime
import os
import time
import tensorflow as tf
BATCH_SIZE = 128
LEARNING_RATE_BASE = 0.1
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 1000
MOVING_AVERAGE_DECAY = 0.99
N_GPU = 1
MODEL_SAVE_PATH = 'logs_and_models/'
MODEL_NAME = 'model.ckpt'
DATA_PATH = './output.tfrecords'
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
#获取权重张量,并将L2损失加入损失集合中
def get_weight_variable(shape, regularizer):
weights = tf.get_variable("weights", shape, initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(weights))
return weights
#实现两层的全连接神经网络
def  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









