







目录
2.2 初步思路——以大语言模型LLM作为支点构建MLLM:
3 架构1:将LLM作为离散调度/控制器(Discrete Schedule/Controller)
4.6 统一多模态编码器(Unified Multimodal Encoders):
8.2.1 方式一:扩散模型(Diffusion Models)
15.3 如何缩小纯粹的多模态模型与当前SoTA“LLM+编码器/解码器”架构的mllm在下游任务上的性能差距?
0 完整Tutorial内容
本文为"⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程"——第二部分的学习笔记,完整内容参见:
⭐⭐MLLM Tutorial⭐⭐——多模态大语言模型最新教程-优快云博客

1 内容讲解安排
1.1 内容结构:

- 介绍现有架构:梳理当前多模态模型的主流构建方法和常见类别。
- 总结现有模型:概述主要模型及其在多模态处理中的应用场景。
- 开放问题:提出一些尚未解决的关键问题,以激发后续讨论。
1.2 说明:
教程讲解保持在“高层次”介绍(high-level),不深入技术细节,确保覆盖更多内容和角度。
2 多模态模型的核心概念
2.1 当前语言模型的优势:

- 受“规模法则”和“涌现行为”的驱动,现有语言模型(如大语言模型)已经具备强大的语义理解能力。
- 语言被视为多模态智能的核心模态,相当于多模态系统中的“CPU”或“大脑”,用来协调和处理其他模态的信息。
2.2 初步思路——以大语言模型LLM作为支点构建MLLM:
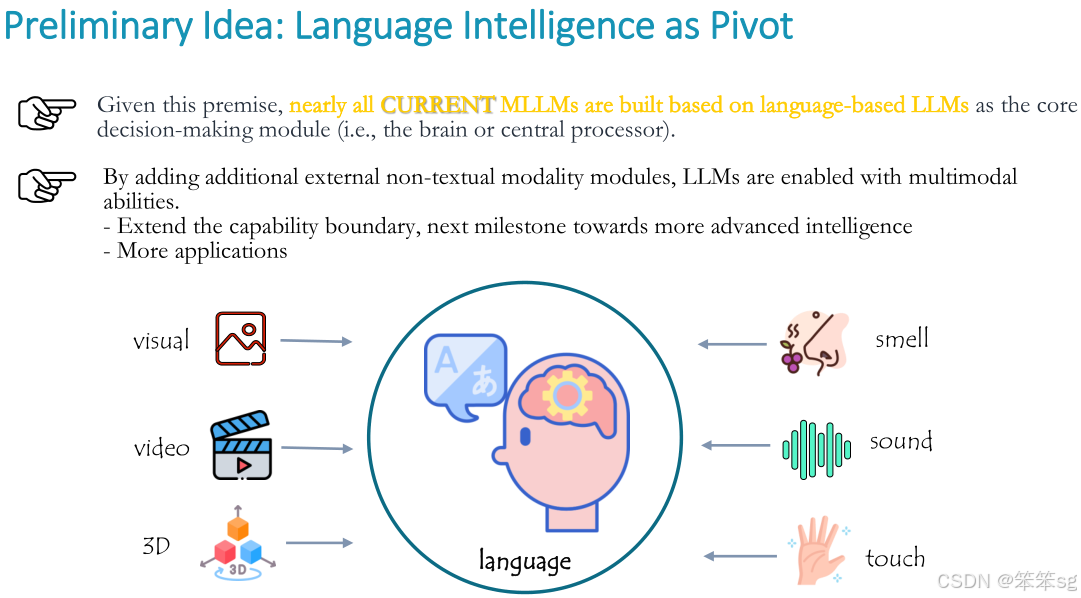
- 在大语言模型具备巨大优势的前提下,几乎所有当前的MLLM都是基于LLM作为核心决策模块(即大脑或中央处理器)构建的。
- 在语言模型基础上,加入其他外部非文本模态(如视觉、音频等),实现多模态感知和操作。
- 多模态模型通过对多种模态信息的融合,进一步拓展其任务处理能力,实现了迈向更高级智能的下一个里程碑
3 架构1:将LLM作为离散调度/控制器(Discrete Schedule/Controller)
3.1 LLM扮演角色
在这个架构中,LLM的作用是接收文本信号并构建文本命令调用下游模块。
3.2 关键特性
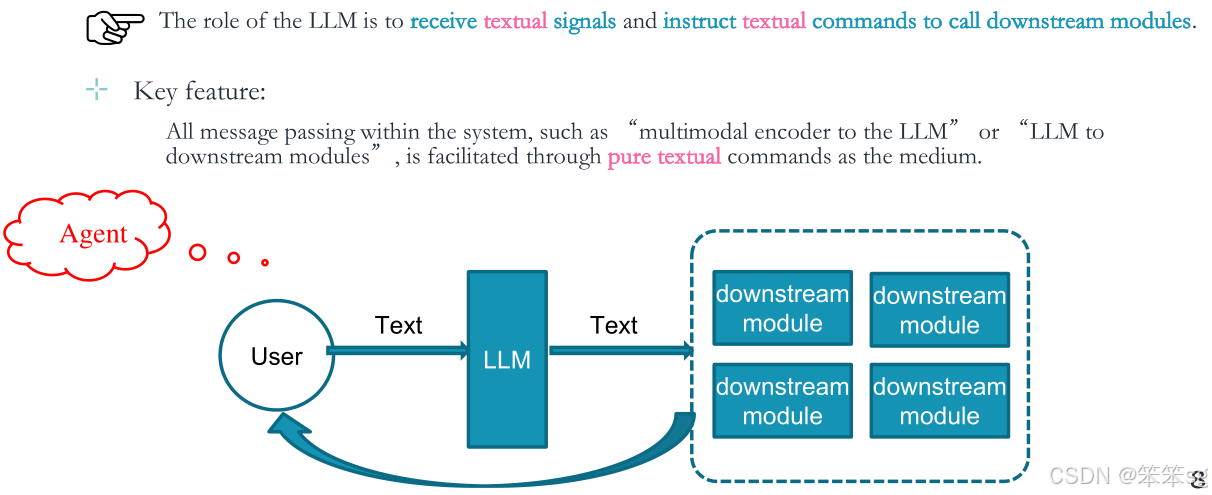
这一架构的核心是通过文本信号接收和输出所有信息,即所有在系统内传递的消息,如“多模态编码器到LLM”或“LLM到下游模块”,都是通过纯文本命令作为媒介来实现的。
3.3 代表模型:
4 架构2:将LLM作为系统的一部分
4.1 LLM扮演角色
在这个架构中,LLM的作用是感知多模态信息,并在编码器-LLM-解码器的结构中自行反应。
4.2 关键特性
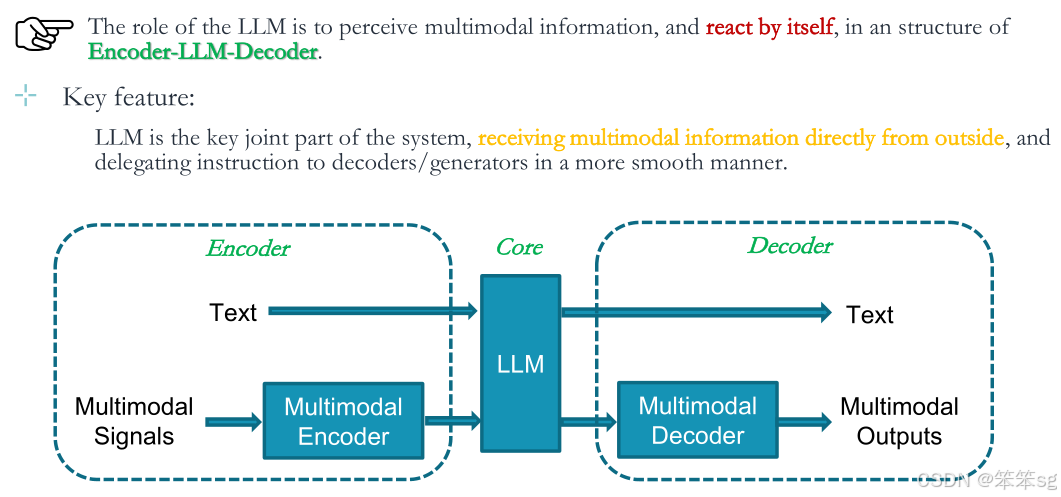
LLM是系统的关键连接部分,直接从外部接收多模态信息,并以更流畅的方式将指令委托给解码器/生成器。
4.3 更有前景
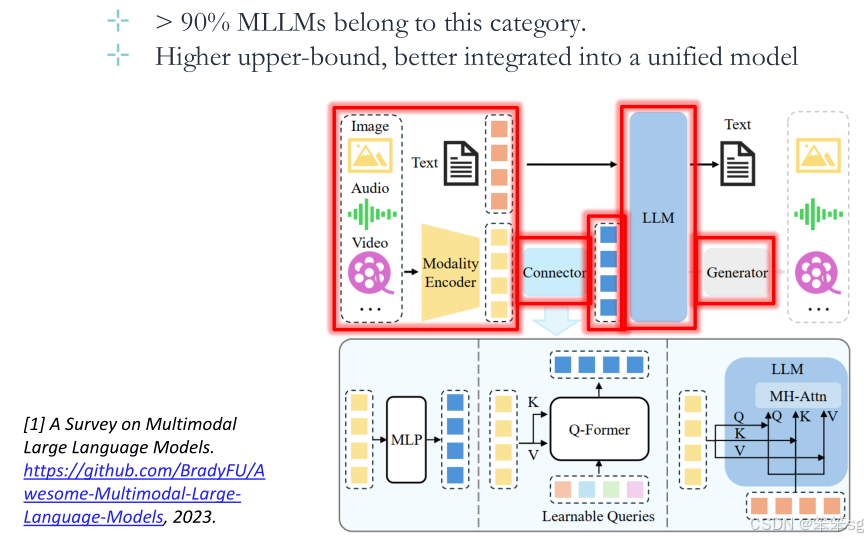
- 90%以上的MLLM都使用该框架;
- 更高的上限,更好地集成到统一的模型中。
4.4 视觉编码器
4.4.1 最流行的视觉编码器
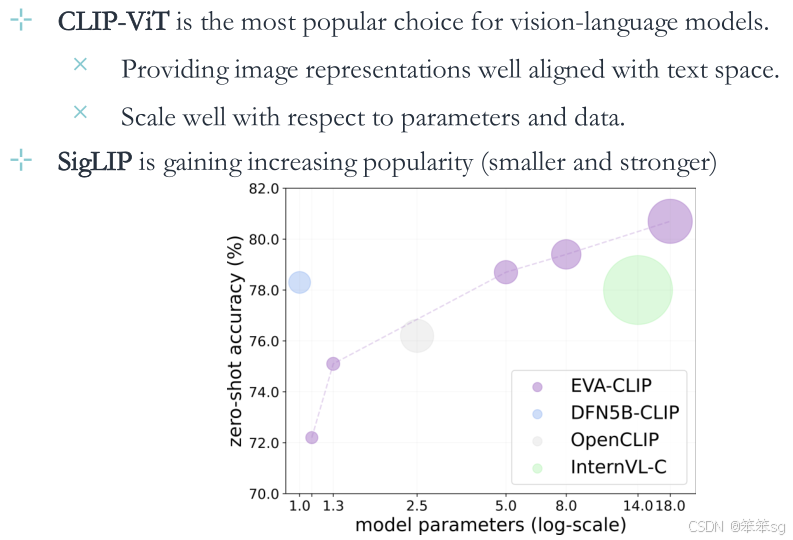
CLIP-ViT是视觉语言模型中最流行的选择。
- 提供与文本空间对齐的图像表示。
- 在参数和数据方面可以很好地扩展。
除此之外,SigLIP越来越受欢迎(更小更强)
4.4.2 ViT的限制
ViT编码器设计时只支持固定大小的输入图像(如 224x224 或 512x512 像素),如果输入一张超出这些尺寸的大图,模型可能无法正常处理,或者需要强制缩放,这会导致图像细节的丢失。
然而,高分辨率感知是必不可少的,特别是对于OCR功能!低分辨率编码忽略了细粒度的视觉细节!

4.4.3 高分辨率场景的改进——切片策略:
为了解决传统视觉编码器只能处理固定低分辨率图像的问题,提出了切片策略(Slicing),即将高分辨率图像分割为多个小块以降低信息损失。
例如:一张 1024x1024 的图像可以被分割为 16 个 256x256 的小块,每个小块都通过编码器生成对应的特征,将所有切片的特征重新整合为整幅图像的表示;此外还可以通过resize保留一份全局特征,与上述切片得到的特征拼接后从而实现对高分辨率图像的全面理解。这种整合方式可以是简单的特征拼接,也可以是通过 Transformer 等模型进行更复杂的上下文建模。
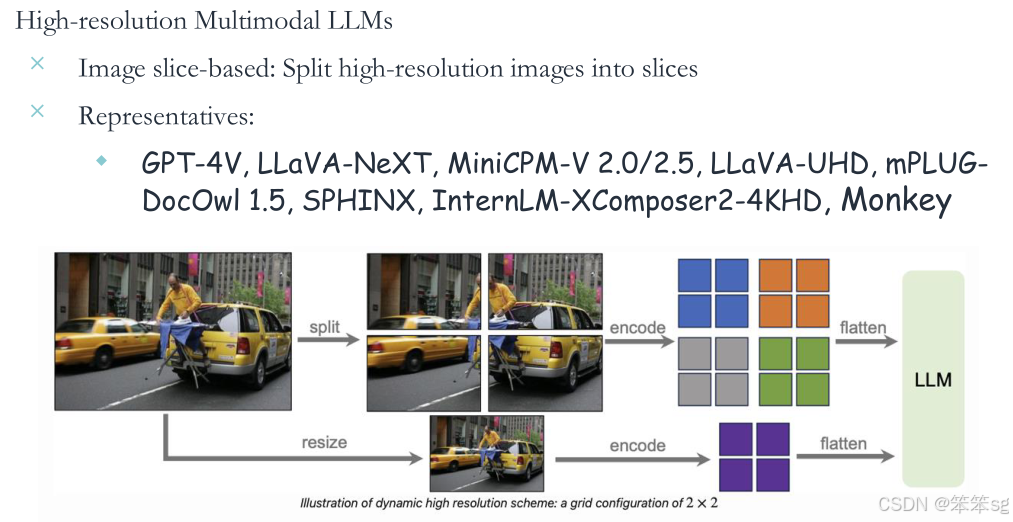
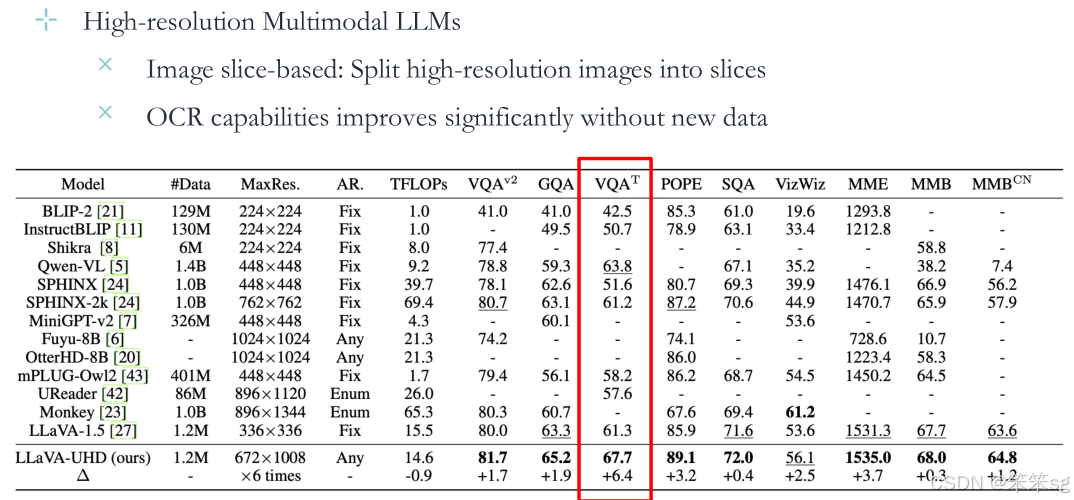
应用场景:OCR(光学字符识别)任务中表现尤为重要。
代表性研究:GPT-4V、LLaVA-NeXT等。
结果:在没有新数据的情况下,OCR功能显著提高。
4.4.4 双分支编码器:
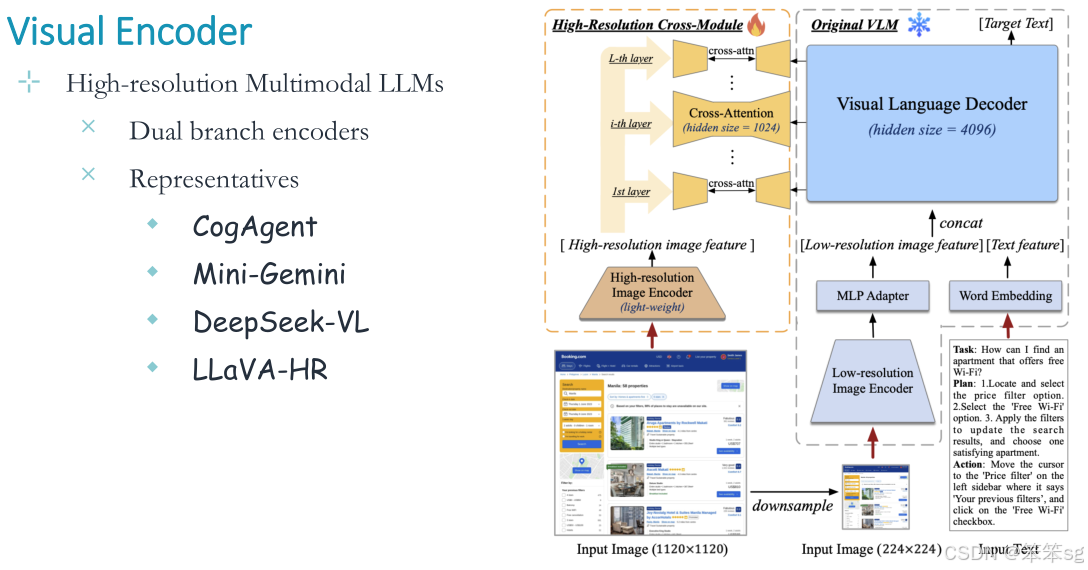
双分支编码器(Dual-Branch Encoders)是一种常见的多模态学习架构,尤其是在视觉-语言模型中被广泛应用。它的主要特点是利用两个独立的编码器分别处理不同的模态数据(如图像和文本),然后通过某种机制将两种模态的信息进行融合或对齐,以实现多模态任务的目标。
主要组成部分
1)两个独立的分支(Branch):
每个分支是一个专门的编码器,用于处理特定模态的数据:
视觉分支:通常基于卷积神经网络(CNN)或视觉 Transformer(如 ViT、CLIP)对图像或视频数据进行编码。
语言分支:通常基于预训练的语言模型(如 BERT、GPT)对文本数据进行编码。
2)特征对齐模块:
将视觉分支和语言分支提取的特征映射到一个共享的表示空间中,以实现跨模态的信息交互和对齐。
常用方法包括:
投影层(Projection Layer):通过全连接层将两种模态的特征投影到相同的维度。
注意力机制(Attention Mechanism):捕获模态间的关联,例如交叉注意力(Cross-Attention)。
3)融合与预测模块:
融合两种模态的特征后,进行下游任务(如分类、生成或检索)的预测。
4.4.5 ViT-free
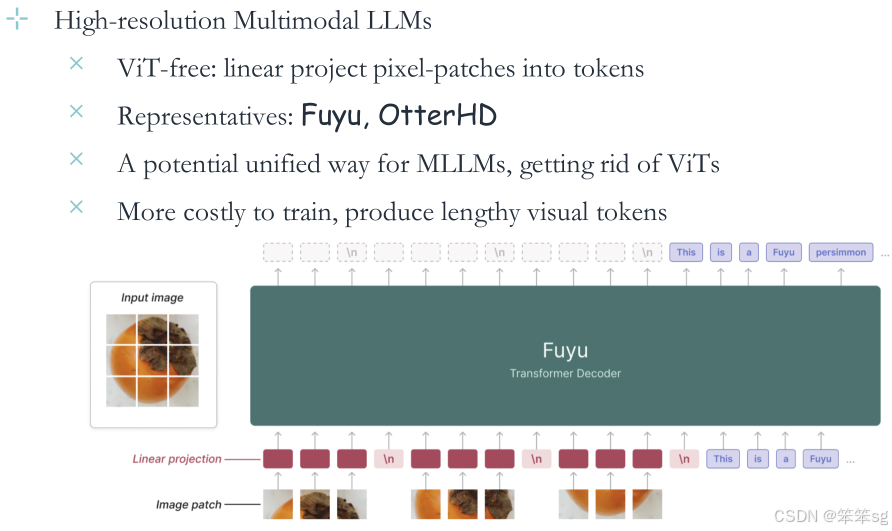
ViT-free 是一种视觉编码方法,旨在减少 Vision Transformer (ViT) 模型的复杂性,同时保持其在视觉任务中的强大性能。这种方法通过线性投影将图像的像素块(patches)直接转换为 token 表示,从而省略了 ViT 的一些复杂处理步骤。
1)做法比对
-
传统 ViT 的做法:
- 图像分块(Patch Division):将输入图像分割成大小固定的小块(如 16x16)。
- 线性嵌入(Linear Embedding):通过一个全连接层将每个小块的像素展平后映射到一个高维向量空间(即 token 表示)。
- 位置编码(Positional Encoding):为每个 token 加入位置信息,使模型能够捕捉空间关系。
-
ViT-free 的改进:
- 通过一个简单的线性投影,直接将图像的像素块映射为 token,而不需要复杂的嵌入层或 Transformer 模块。
- 省略了传统 ViT 中的位置编码,但仍能通过下游模型捕获一定的空间关系。
2)具体流程
-
像素分块(Pixel Patches):
- 将输入图像划分为若干小块,每个小块包含固定数量的像素。
- 例如,对于分辨率为 224x224 的图像,划分为 16x16 的小块,共有 (224 / 16)^2 = 196 个块。
-
线性投影(Linear Projection):
- 对每个小块的像素进行展平操作(flattening),形成一个向量。
- 使用一个简单的线性变换(如矩阵乘法)将这些向量投影到模型的 token 表示空间。
-
生成 token:每个小块经过线性投影后生成一个 token,这些 token 作为后续模型的输入。
3)缺点:
这种方法直接使用线性投影对每个像素块生成 token,缺乏对高维视觉特征的充分建模,因此需要更复杂的后续模块(如自注意力机制)去理解这些 token 表示。这可能导致模型:
- 需要更多数据:以弥补特征提取的不足。
- 需要更大的计算资源:处理更加密集的 token。
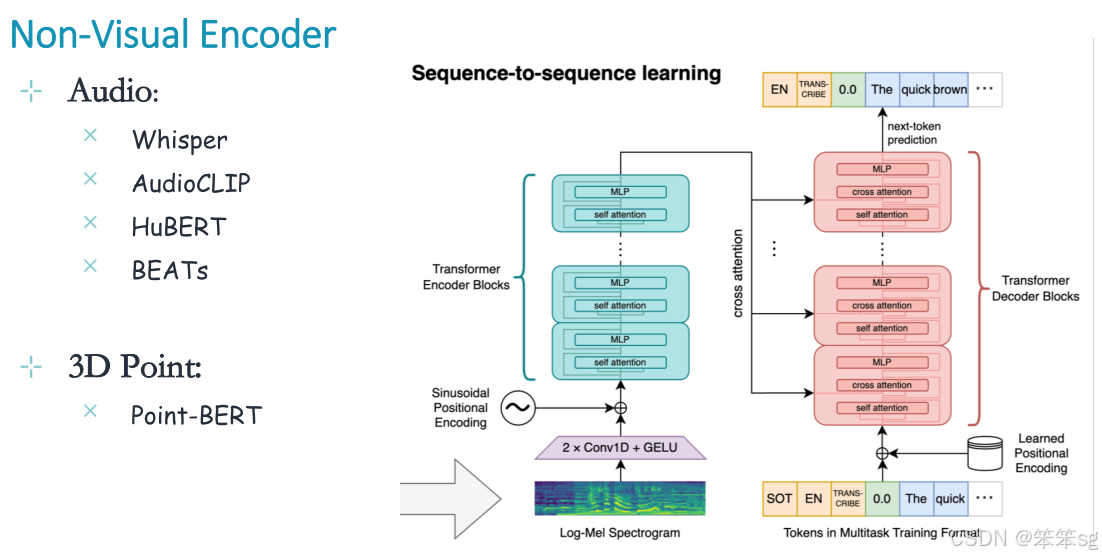
4.5 其他模态编码器:
多数多模态模型依赖现有模态特定编码器(Modality-Specific Encoders),这些编码器在多模态时代之前已开发完成。
4.6 统一多模态编码器(Unified Multimodal Encoders):
通过对所有模态特征对齐到共享表示空间(Shared Representation Space),实现模态间的一致性。
关键技术:基于预训练的统一编码器,典型模型包括 ImageBind 和 LanguageBind。
4.6.1 ImageBind——以图像为中介:
- 将所有模态嵌入到图像的联合表示空间中。
- 对齐良好的模态表示有利于LLM的理解

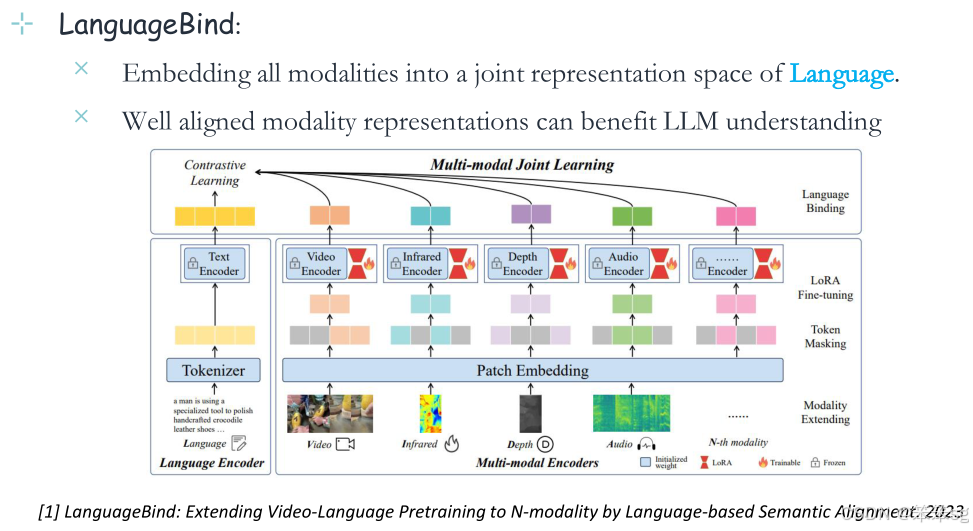
4.6.2 LanguageBind——以语言为中介:
- 将所有模态嵌入到语言的联合表示空间中。
- 对齐良好的模态表示有利于LLM的理解。
4.7 多模态信号的分词技术(Tokenization)
在前面的Encoder中都是将多模态信号直接编码为连续表示,那么能不能量化多模态信号呢?例如将图像、视频等非文本信号表示为离散的“模态词元”(Discrete Tokens),如使用代码本(Codebooks)进行量化。
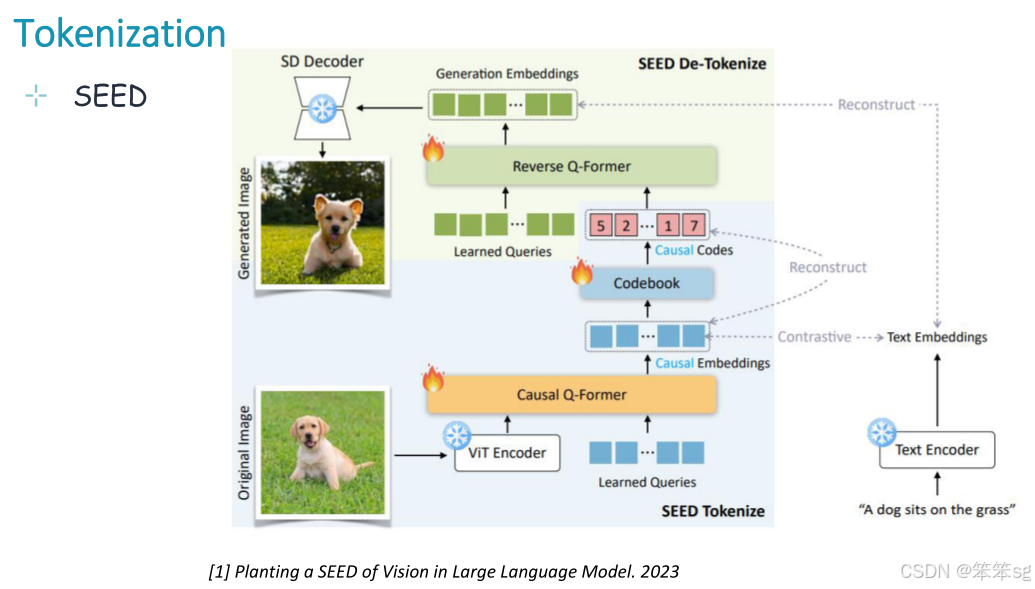
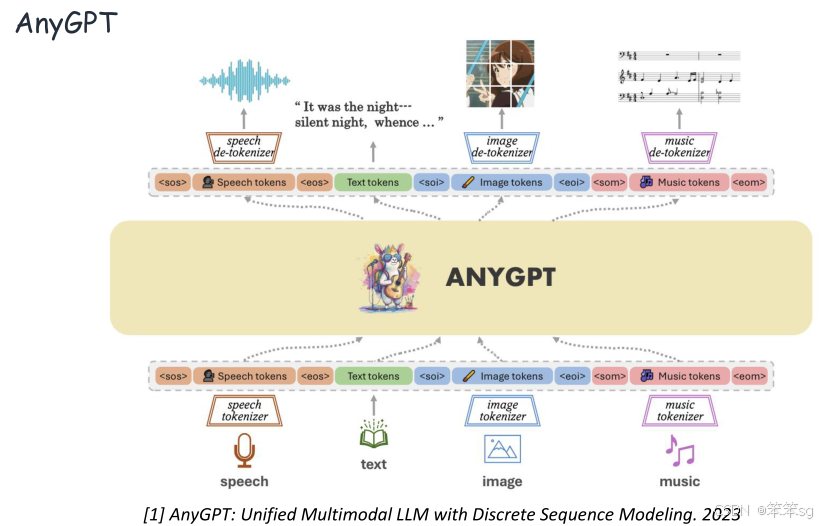
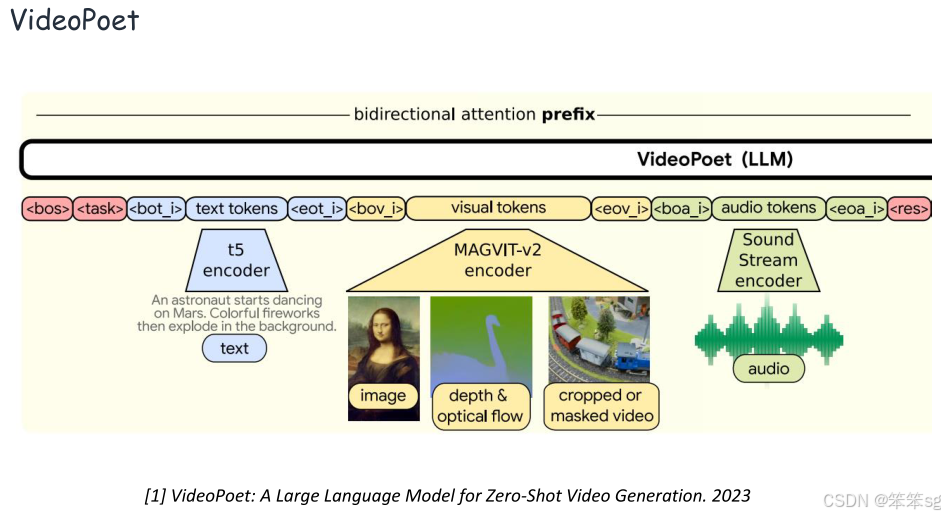
多模态信号的离散化表示:这是指将多种不同模态(例如图像、文本、音频等)通过某种方式转换成离散的tokens。这些tokens通常被存储在一个“codebook”中,即一个包含不同tokens的字典或表格。

Codebook:类似于一个词汇表,包含图像、文本等模态的表示。通过tokenization,将连续的特征表示(例如图像的像素值)转换成更结构化的离散单位,使得模型能够更高效地处理这些信息。
优势:通过将多模态信号转化为离散的tokens,可以在同一个统一的框架下理解和生成这些信号。这种框架通常是自回归的(auto-regressive),也就是模型通过预测下一个token来生成数据(比如文本生成、图像生成等)。
5 将多模态表示连接到语言模型(LM)——投影
5.1 投影方法的作用
通过将多模态特征投影到语言空间,模型能够理解并处理这些多模态输入。这一过程使得不同类型的多模态特征(例如,图像、文本等)能够在语言模型中得到统一处理。
有众多投影方法,例如:Q-Former、Liner projection、Two-layer MLP等等。

5.2 一些发现
5.2.1 投影效果
- 根据LlaVA 1.5论文,两层MLP(多层感知器)投影效果优于线性投影。
- Resampler(重采样器)在某些方面与C-Abstractor (MM1) 和 MLP (LLaVA-UHD) 具有可比性。
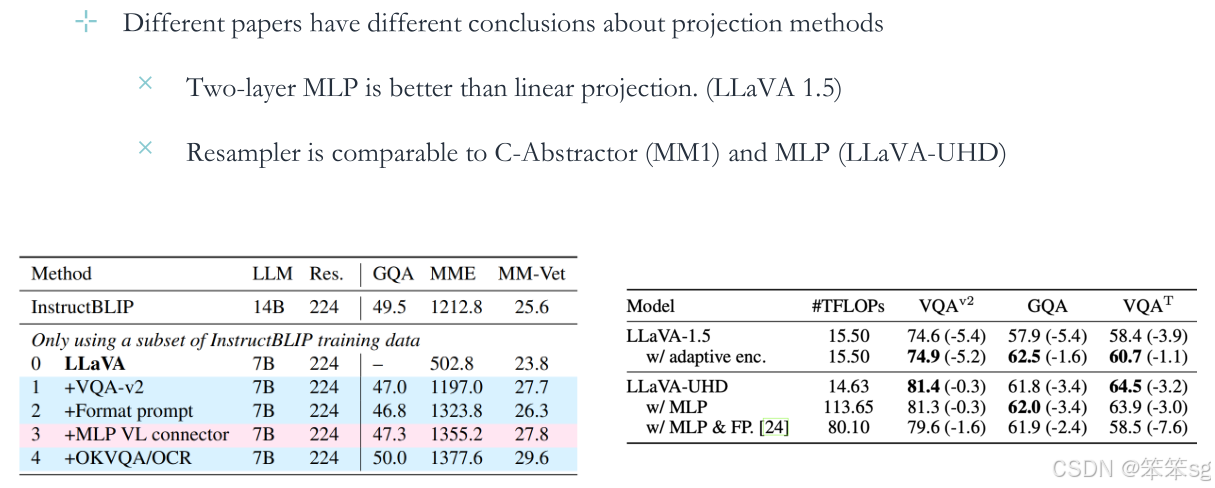
Resampler(重采样器):在多模态模型中,Resampler通常指一种通过对多模态特征进行采样、调整或重排序的方法,以优化特征的表达或提升模型效率。这个方法可能涉及从不同模态中提取特定的信息并进行重构,以便更好地融合不同模态的数据。
C-Abstractor (MM1):C-Abstractor通常是某些多模态系统中用于对特征进行抽象化处理的模块(如抽象或提取关键的特征信息)
MLP (LLaVA-UHD):MLP指的是多层感知器(Multi-Layer Perceptron),这是神经网络中的一种基本架构,用于特征的处理与转换。
5.2.2 视觉token的数量很重要,尤其是在效率方面:
在处理图像和其他多模态数据时,视觉token(即图像或视觉内容的离散表示)的数量对模型的效率和效果有显著影响。特别是在处理高分辨率图像时,视觉token的数量会影响模型的理解能力和计算效率。
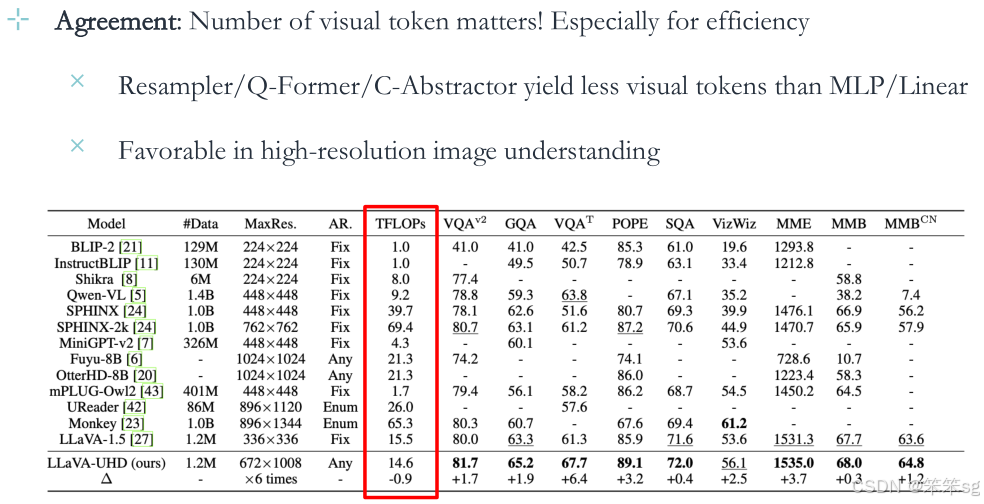
1)Resampler/Q-Former/C-Abstractor生成的视觉token少于MLP/Linear:
Resampler、Q-Former和C-Abstractor这些方法生成的视觉token数量通常少于MLP(多层感知器)和Linear(线性投影)方法。这意味着,前者可能更注重信息的提取与压缩,而后者则可能生成更多的token以保留更多的细节信息。
2)在高分辨率图像理解中更为有利:
在处理高分辨率图像时,减少视觉token的数量可能有助于提升处理效率。因为高分辨率图像包含的信息量大,减少token数量有助于降低计算开销,从而提高效率,而不会大幅损失关键信息。
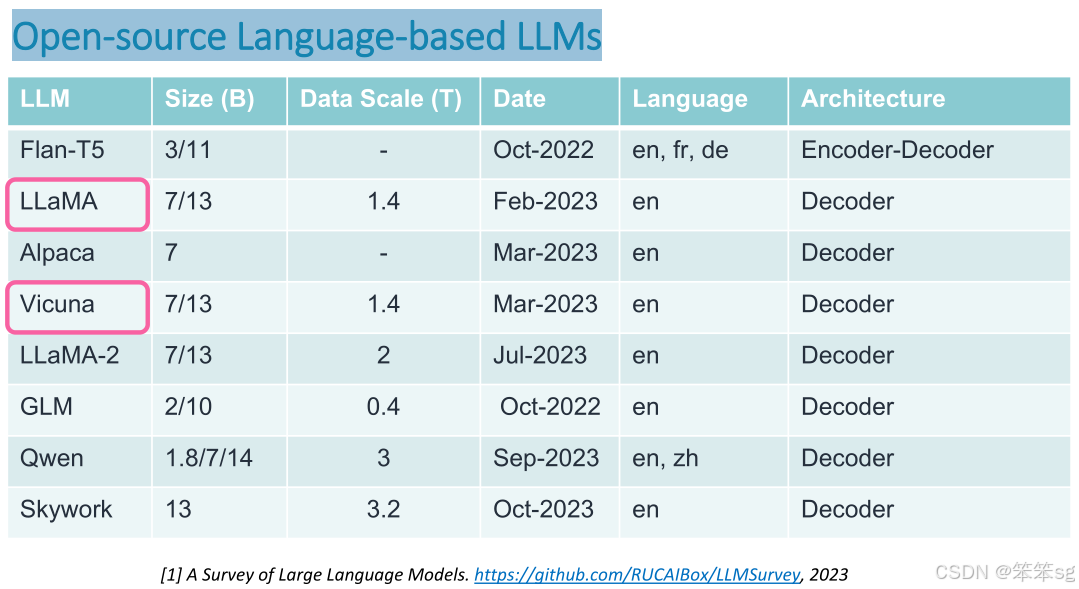
6 多模态模型(MLLM)依赖于开源的语言模型(LLM)
当前,大多数多模态系统依赖于开源的语言模型来处理多模态输入。在多模态社区中,LLaMA和Vicuna是最为广泛使用的语言模型。
7 多模态模型解码器端的连接
解码器设置连接投影。其主要职责是传递消息,将多模态指令转化为下游解码器可理解的信号。
7.1 方法一:离散token
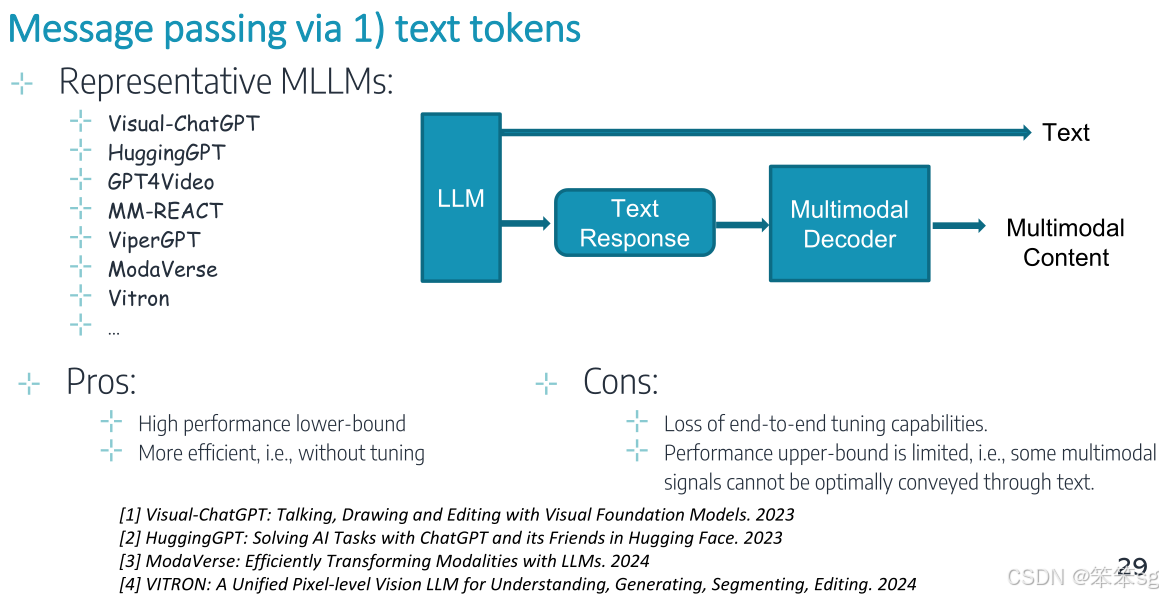
这种方法是标准实践,直接输出离散的文本响应,将指令传递给下游解码器。
这种方法的优势是效率较高,无需额外的训练;
但它的短处是由于其离散性质,失去端到端调优功能。此外,离散的文本token方法的性能上限比较低,因为某些多模态信号(例如图像、视频等的丰富信息)不能通过简单的文本token最优地传递。这意味着这种方法无法完全捕捉和表达某些模态的信息,影响了模型的整体性能。
7.2 方法二:连续嵌入表示
这种方法通过嵌入表示(embedding)来传递信号,能够比离散token携带更多的模态特定特征
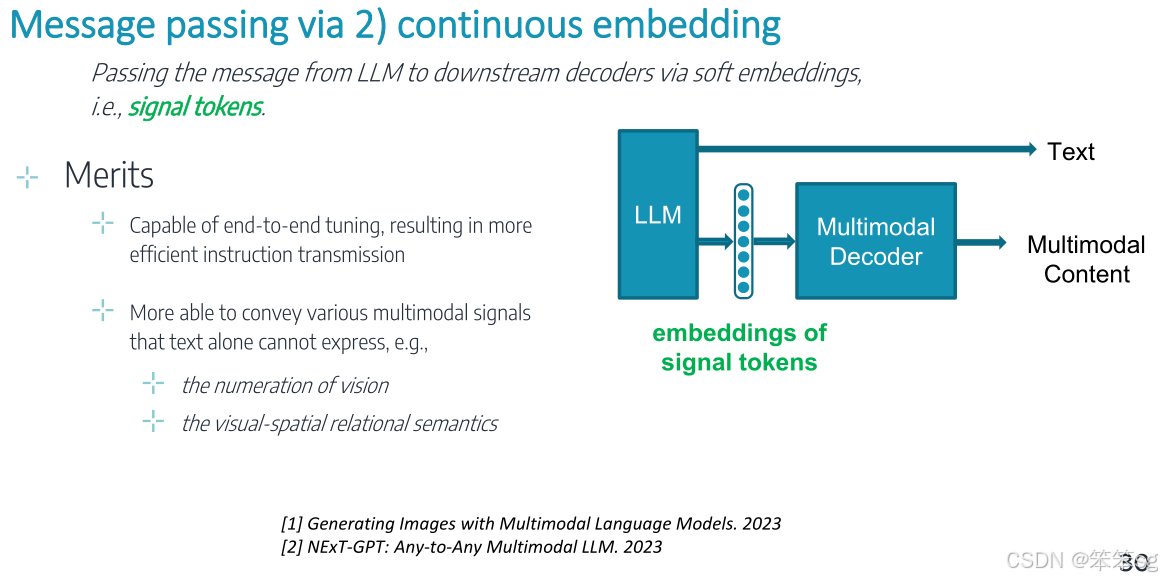
优势:
1)使用连续的嵌入表示方法,能够进行端到端的训练调优。这意味着模型的所有部分可以在训练过程中一起优化,整体提升了多模态信息的理解和传递效率。
2)相比于离散的文本token,连续嵌入表示能够更好地表达和传递复杂的多模态信号,尤其是文本单独无法传达的内容。例如:
- 视觉数值化:这种表示方法能够更好地处理和表达视觉信息中的数值特征,如图像中的大小、数量等。
- 视觉-空间关系语义:它可以更有效地捕捉图像中不同物体之间的空间关系,例如物体的相对位置和方向等,这些信息无法仅通过文本来完整描述。
7.3 方法三:使用代码本(Codebooks):
这种方法与输入端的token化过程类似,通过生成特殊的token ID来传递给下游解码器。
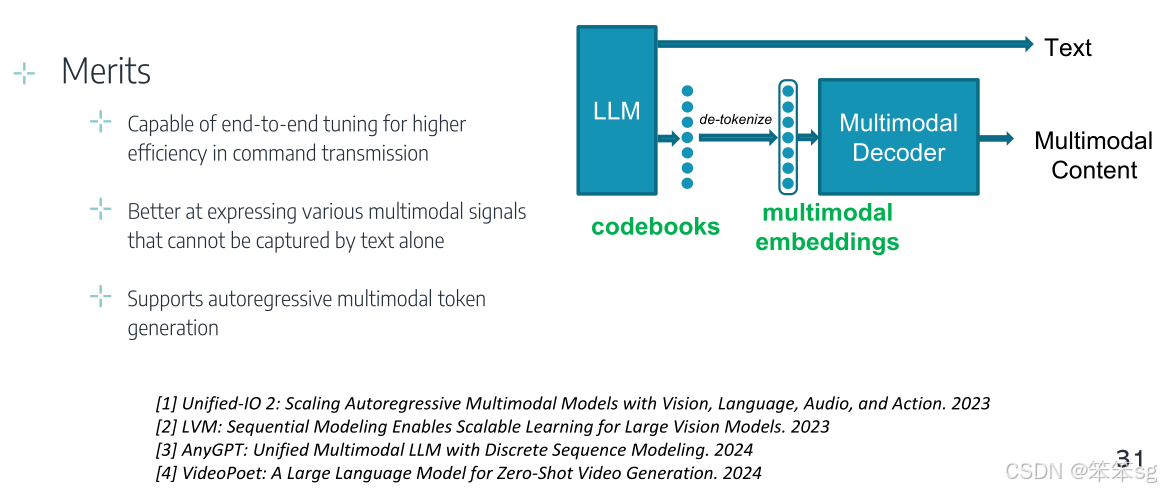
优势:
-
支持端到端调优,提高指令传递效率
-
更擅长表达文本无法捕捉的多模态信号
-
支持自回归多模态token生成:自回归生成是指在生成下一个token时,模型会基于之前生成的内容进行预测。在这种方法下,代码本能够支持这种自回归的生成过程,使得多模态信息的生成更加顺畅和连贯。
8 多模态生成
8.1 文本生成
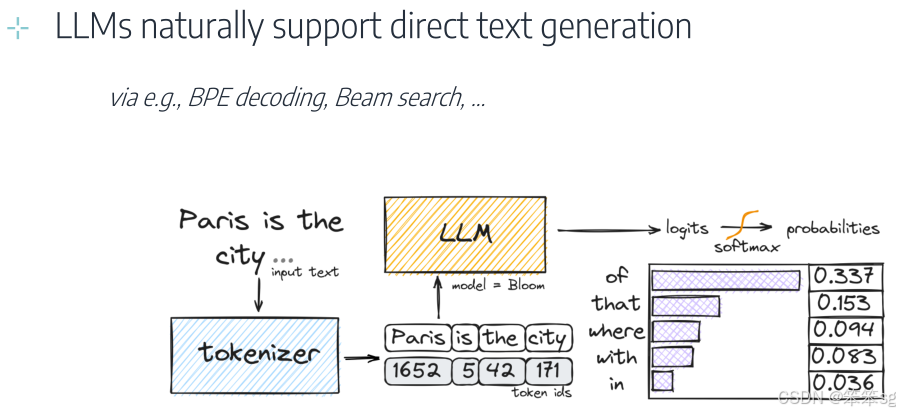
支持直接文本生成:多模态模型(MMs)通常基于语言模型(LMs),天然支持直接的文本生成。
8.2 其他模态生成
多模态生成包括图像、视频和音频生成,主要有两种方式:
8.2.1 方式一:扩散模型(Diffusion Models)
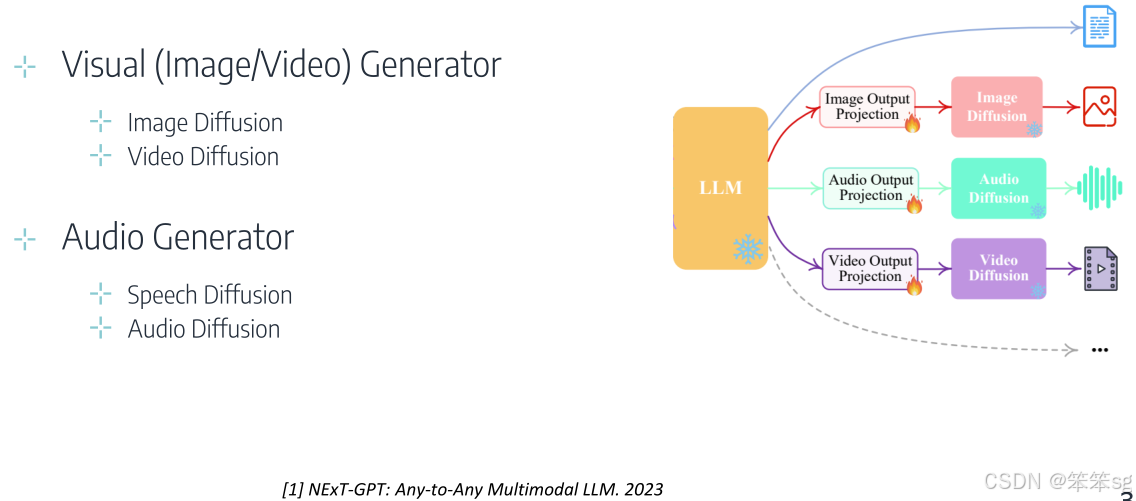
- 过程:结合连续的信号Token(如从多模态嵌入中获取的特征)和扩散模型,系统可以生成图像、视频和音频。
- 代表性用途:
- 高质量图像生成
- 时间序列生成(如视频中的逐帧生成)
- 声音信号的合成
8.2.2 方式二:代码本(Codebook)方法
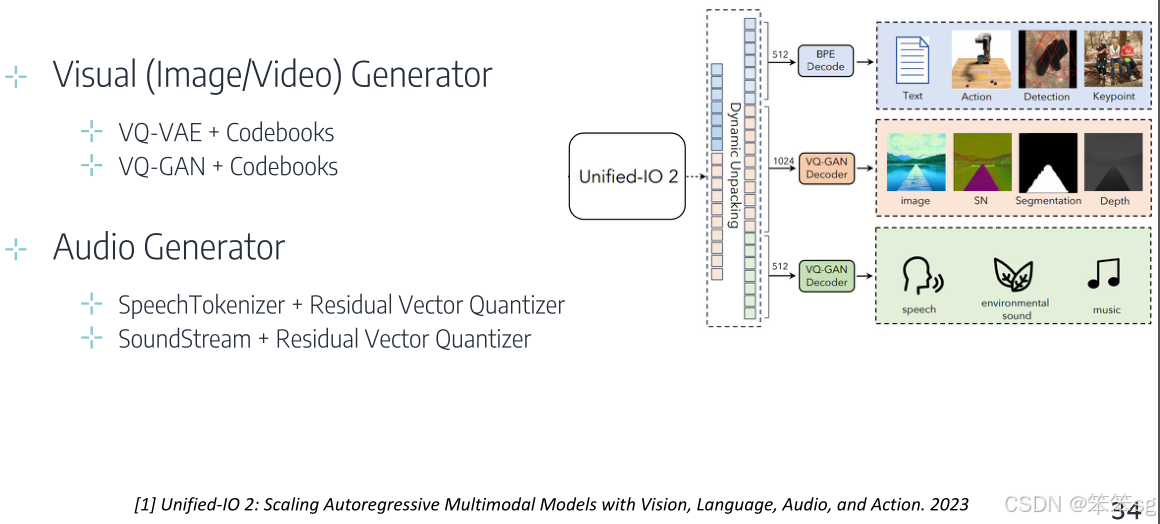

- 过程:
- 将信号编码到潜在空间中并量化为离散的Token(通过代码本)。
- 使用解码器将量化后的Token还原为多模态内容(如图像或音频)。
- Token的生成是自回归的,即逐步生成下一个Token。
- 特点:
- 适合离散化的信号生成。
- 可以在多种模态间保持一致性。
9 多模态支持的信号模态
当前的多模态模型(MM)通常支持以下几种信号模态:
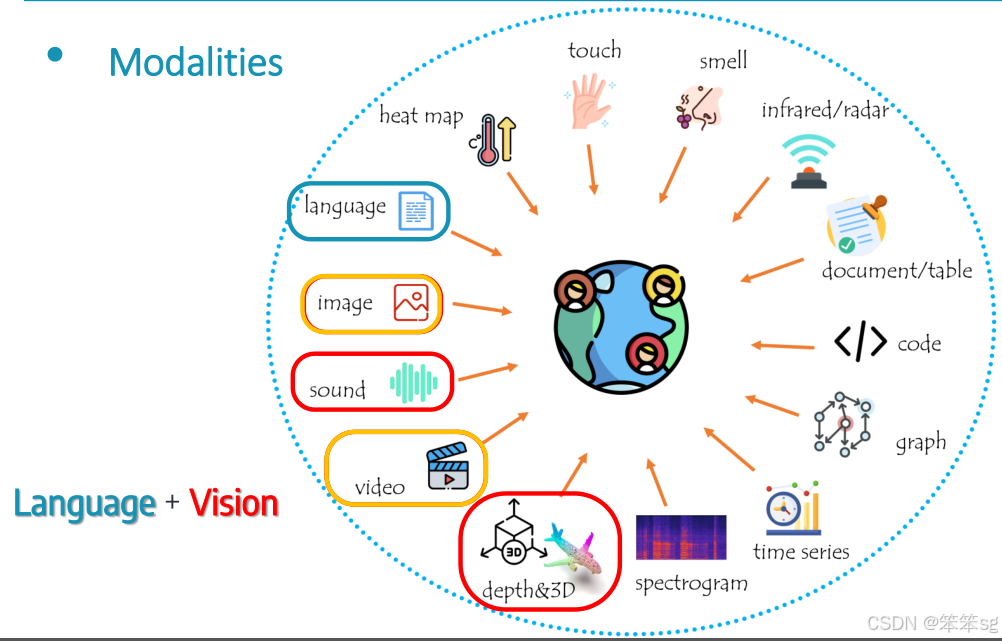
- 语言(Language)
- 视觉(Vision):通常包括图像(Image)和视频(Video)。
- 音频(Audio)
- 3D(3D 模态)
这些模态是目前多模态研究中最常见的类型。
在当前的研究中,很多多模态模型支持这些模态的理解和生成能力。
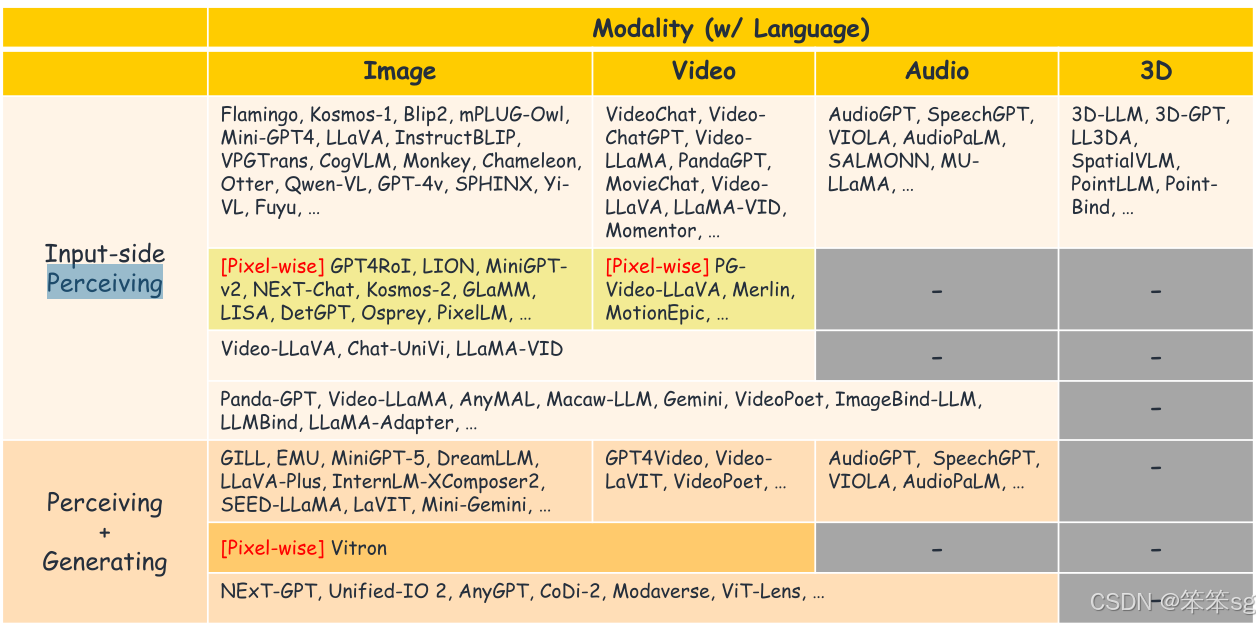
表格总结了各种模型支持的模态,并按它们的多模态理解能力和生成能力进行了分类。其中包括一些代表性模型,但这只是一个选择性的总结,实际中有很多不同的多模态模型存在。
10 MLLM在不同模态的理解能力
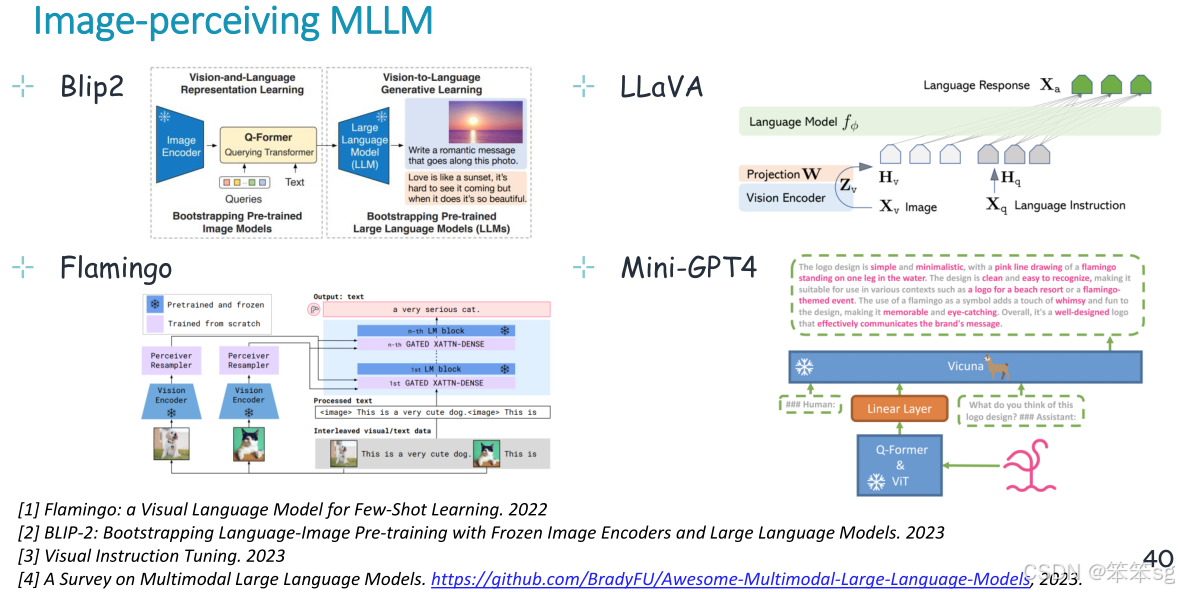
10.1 图像理解
使用外部图像编码器对输入图像进行编码,生成LLM可理解的视觉特征,然后将其输入LLM。然后,LLM根据输入文本指令解释输入图像并生成文本响应。
代表性的模型如下所示:

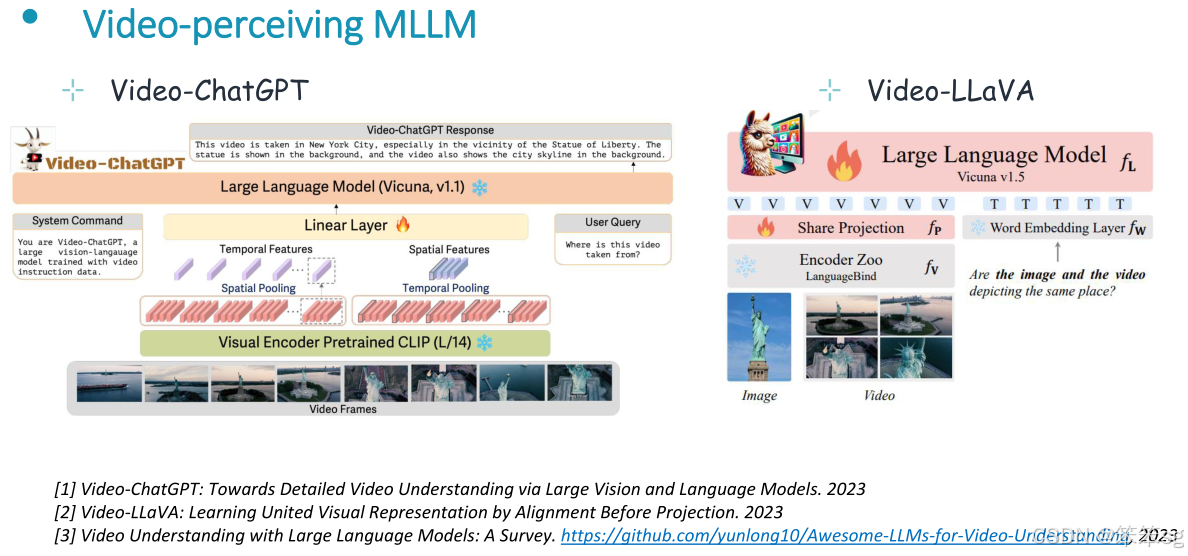
10.2 视频理解
使用外部视频编码器对输入视频进行编码,生成LLM可理解的视觉特征,输入到LLM中,LLM根据输入文本指令对输入视频进行解释,并产生文本响应。
代表性的模型如下所示:

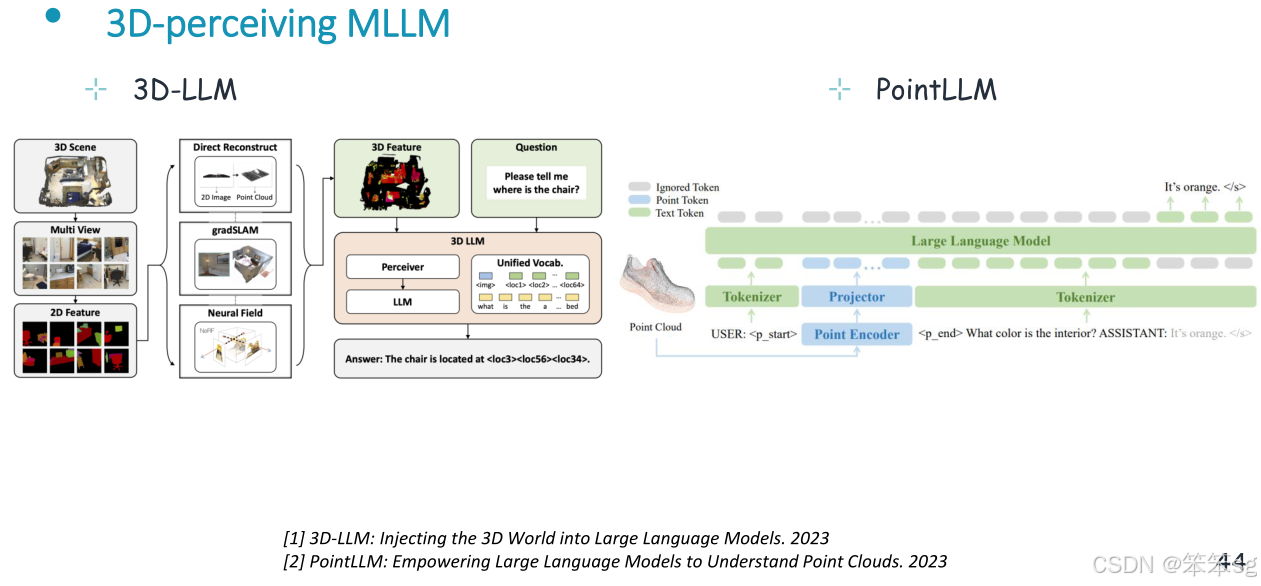
10.3 3D理解
使用外部编码器对输入的3D信息进行编码,生成LLM可理解的3D特征,并将其输入到LLM中,然后LLM根据输入的文本指令对输入的3D/点进行解释,并产生文本响应。
代表性的模型如下:

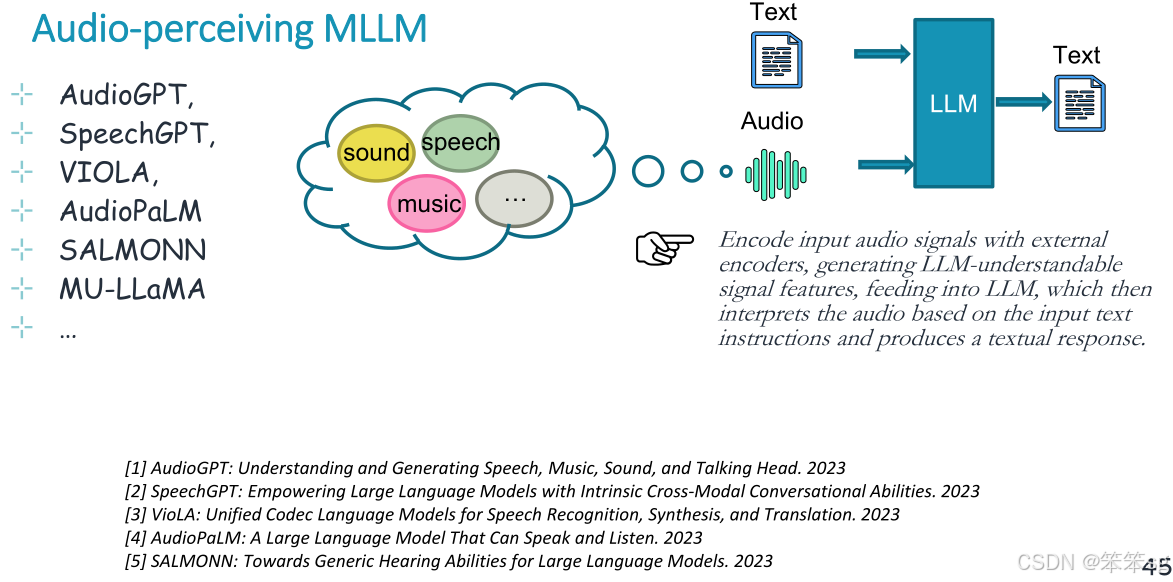
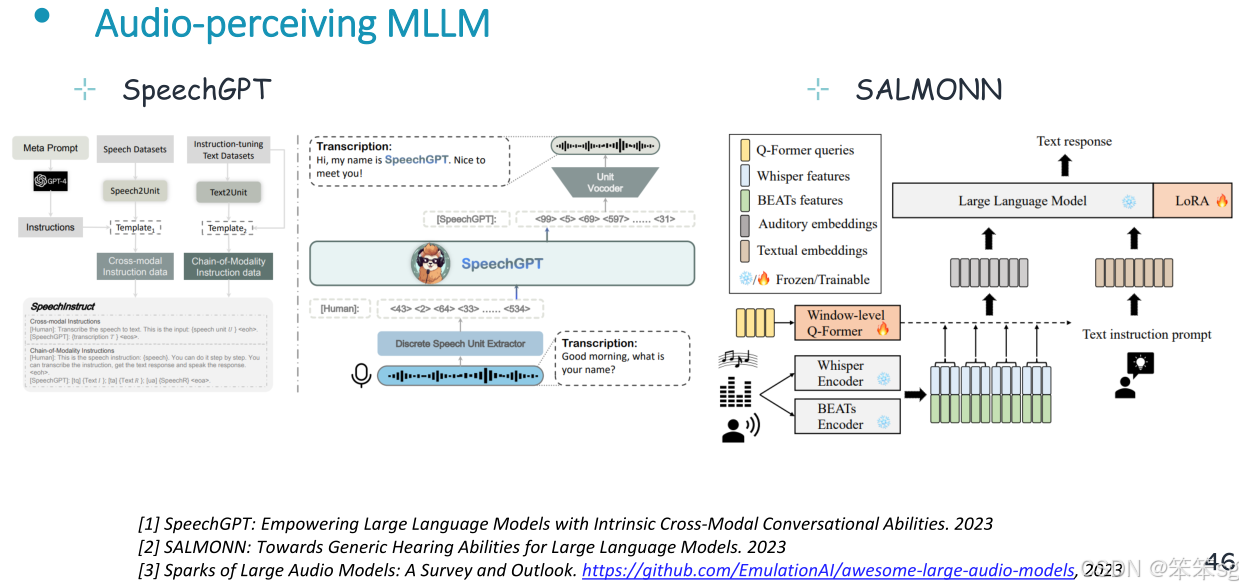
10.4 音频理解
使用外部编码器对输入音频信号进行编码,生成LLM可理解的信号特征,并将其输入LLM,然后LLM根据输入文本指令解释音频并产生文本响应。
代表性的模型如下:
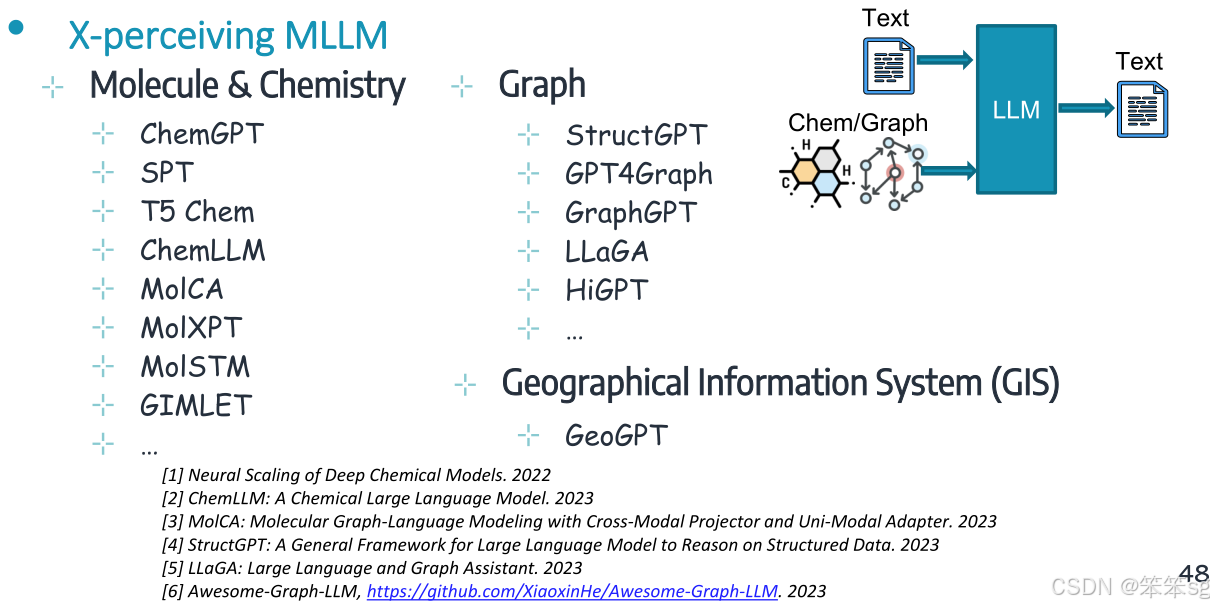
10.5 X领域的多模态理解
在生物医学或医疗领域,有大量的模型和研究工作可以参考,此外,化学、图谱等领域也有相应的多模态模型。
代表性的模型如下:

11 统一的MLLM:兼顾理解与生成
在多模态模型(MMS)中,单纯关注模态理解是不够的,还需要具备生成多模态内容的能力。
11.1 单一模态理解的不足
传统的多模态模型(MMS)主要支持单一模态的理解,但这并不足以满足更复杂的需求。研究人员发现,仅关注模态理解是不够的,还需要模型具备生成多模态内容的能力。
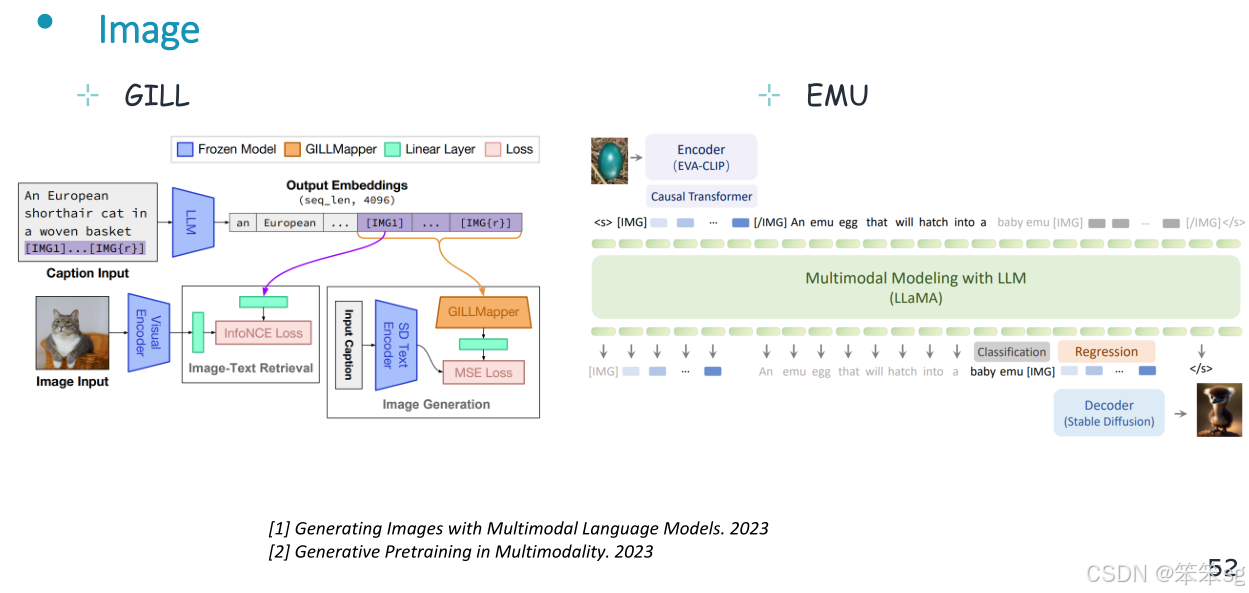
11.2 图像理解与生成
中间的llm将文本和图像作为输入,经过语义理解,生成文本和图像。

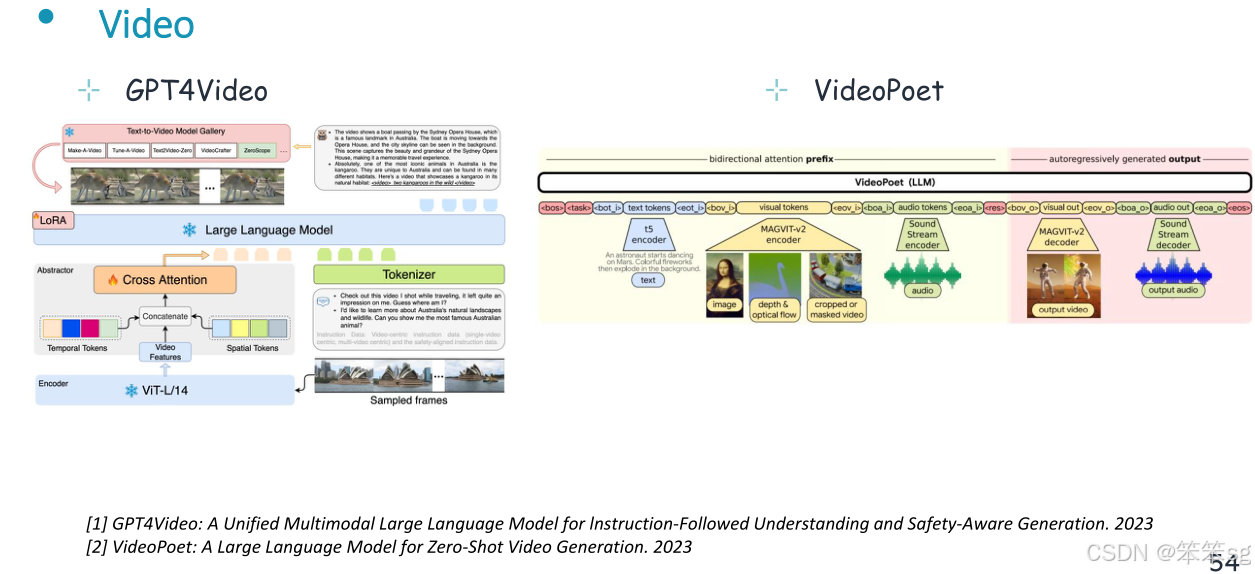
11.3 视频理解与生成
中央llm将文本和视频作为输入,经过语义理解,生成文本和视频。
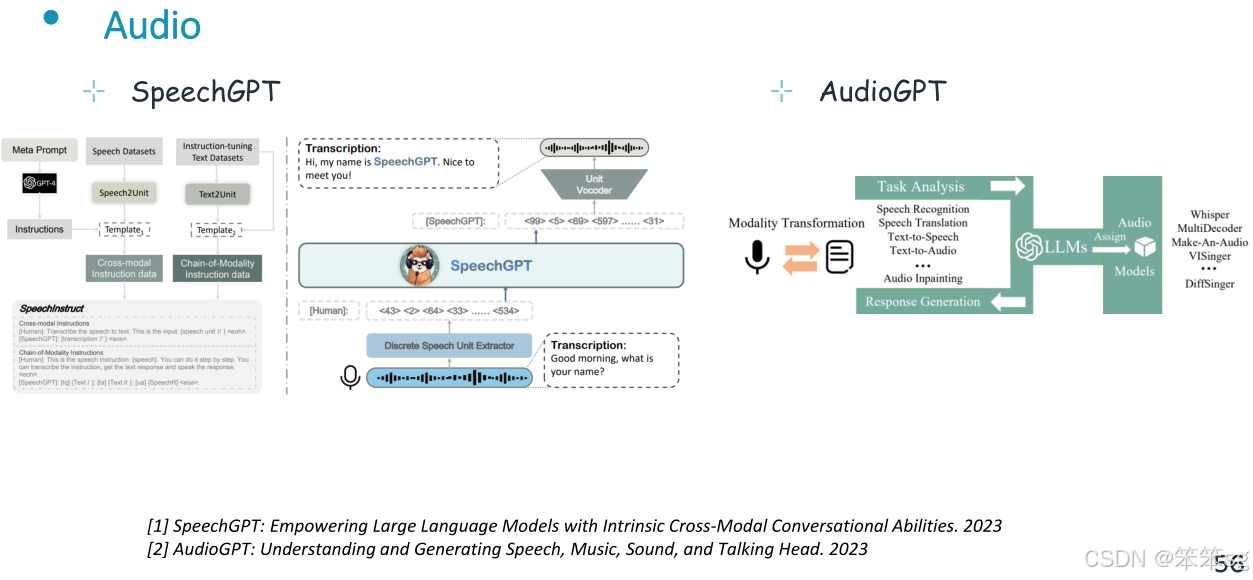
11.4 音频理解与生成
中央llm将文本和音频作为输入,经过语义理解,生成文本和音频。

12 支持多模态交互
12.1 单一模态支持的不足

在现实中,模态通常同时具有很强的相互联系。因此,mllm经常需要同时处理多种非文本模态的理解,而不仅仅是一种(非文本)模态。
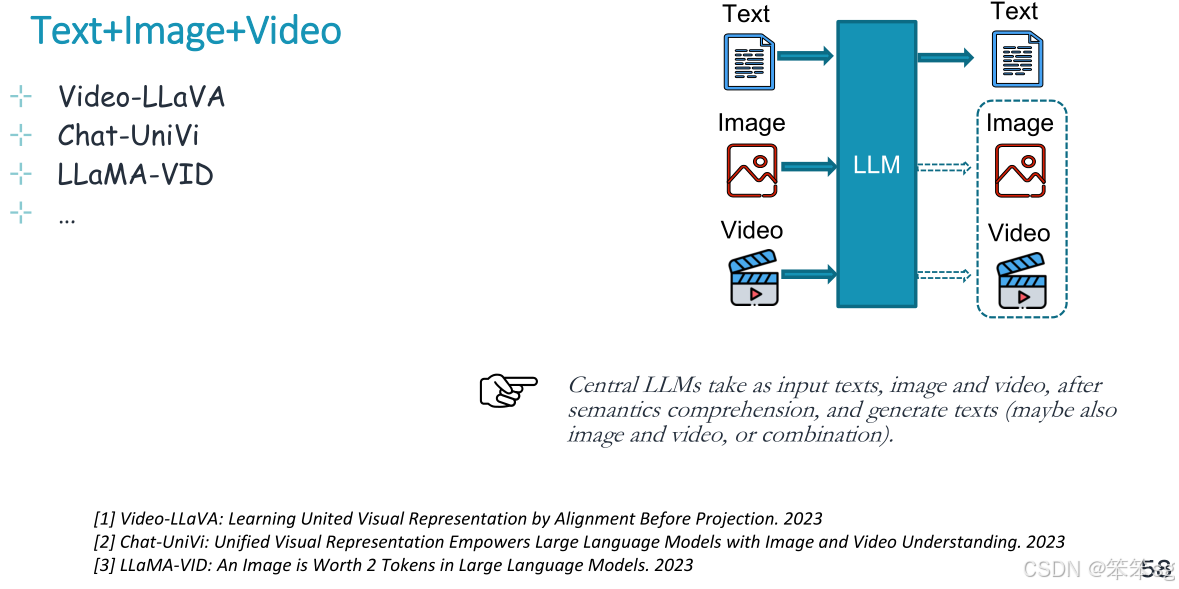
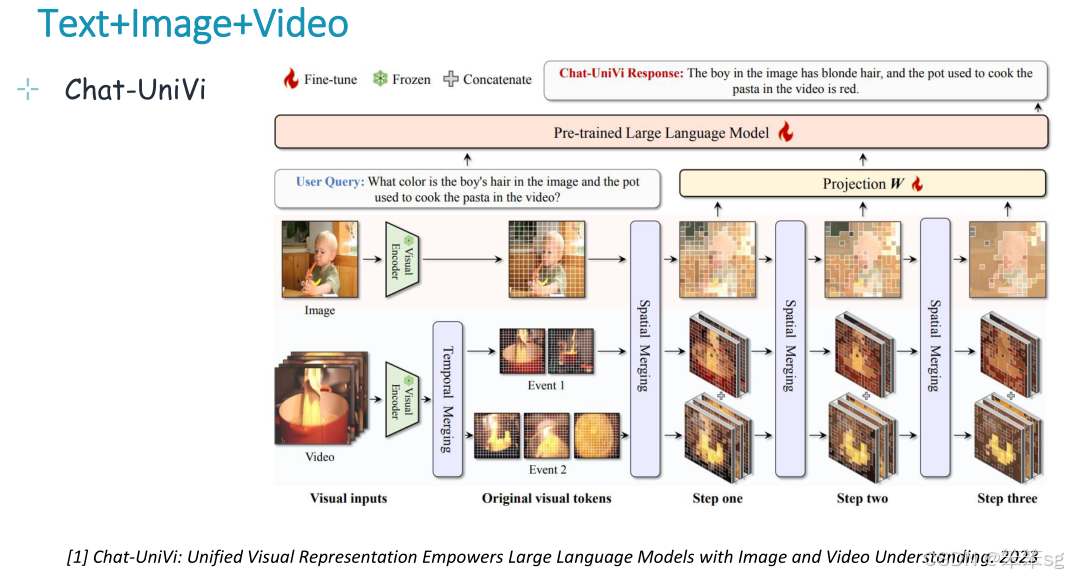
12.2 文本+图片+视频
中央llm以文本、图像和视频作为输入,经过语义理解,生成文本(也可能是图像和视频,或组合)。
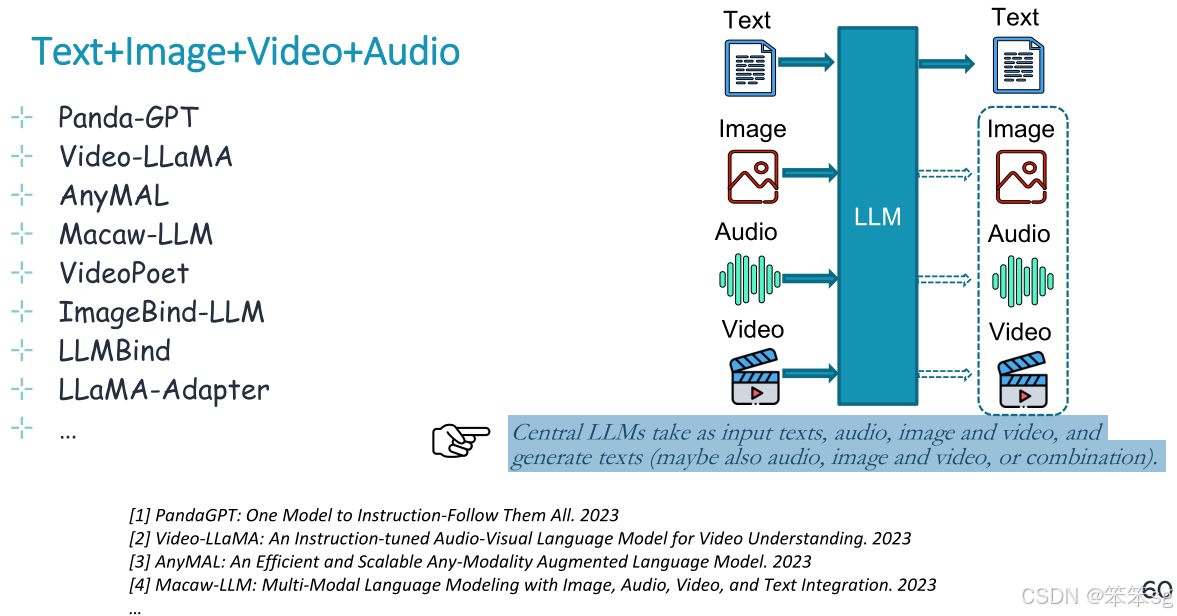
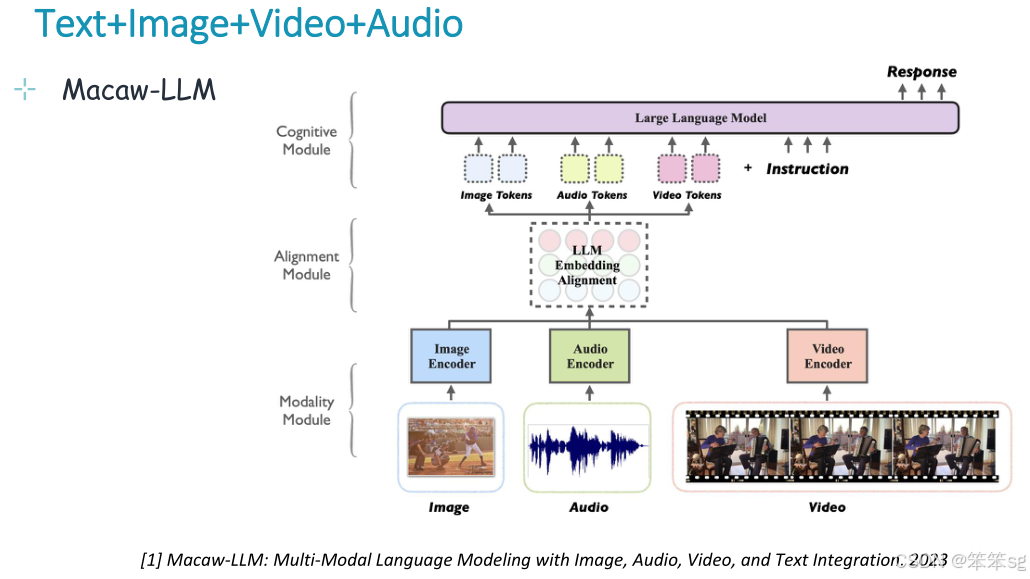
12.3 文本+图片+视频+音频
中央llm以文本、音频、图像和视频作为输入,并生成文本(也可能是音频、图像和视频,或组合)。
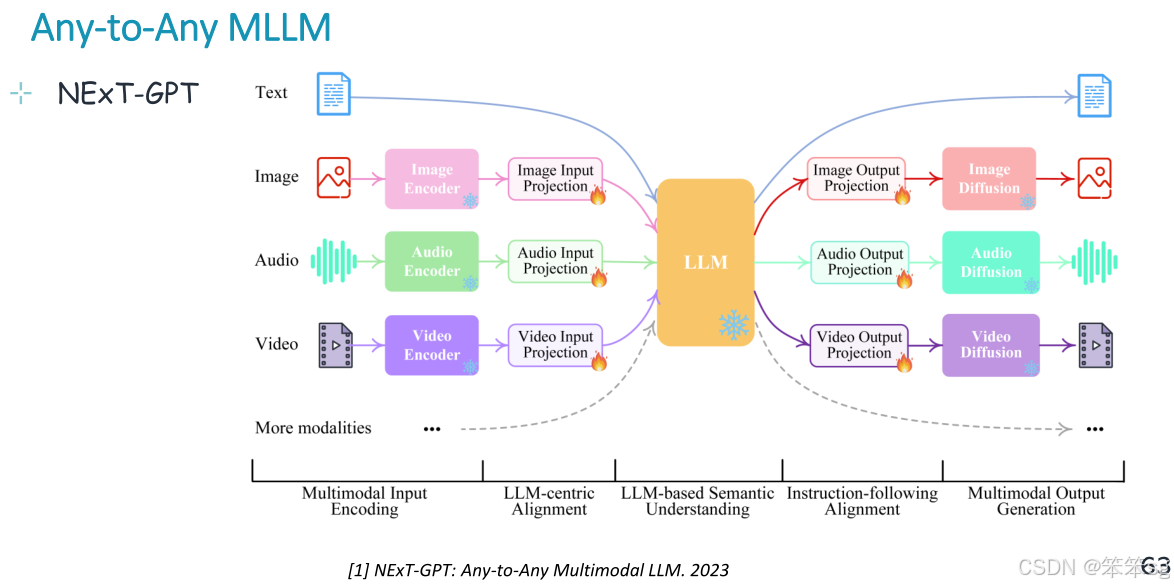
12.4 Any-to-Any 多模态交互
中央llm以文本、音频、图像和视频为输入,自由生成文本、音频、图像和视频或组合。能够处理任意组合的输入模态(如视频、音频、文本等)并生成相应的输出。


13 当前多模态模型的局限性
目前,大多数多模态系统依赖语言作为核心,即利用语言理解来增强视觉等其他模态的能力。
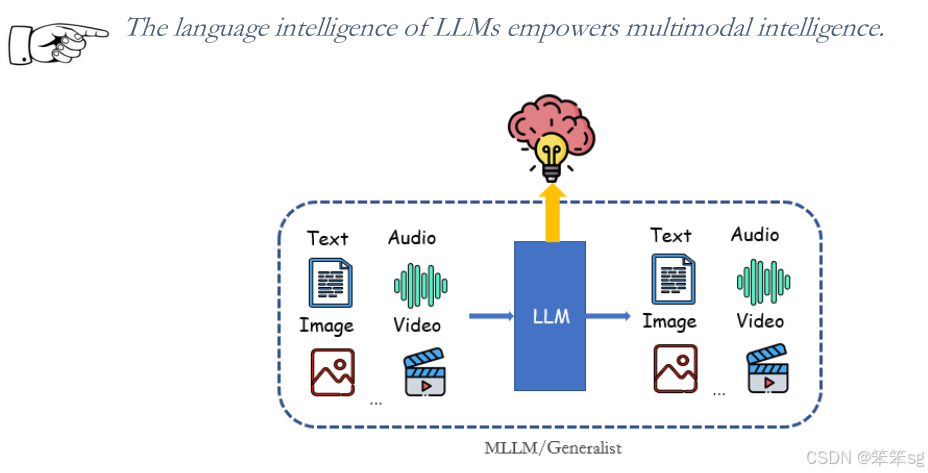
LLMs的扩展法则和出现的成功是否可以在多模态中复制,以实现原生多模态LLMs的智能?
语言智能的依赖是否限制了模型的潜力?
14 能否通过大规模预训练实现多模态智能?
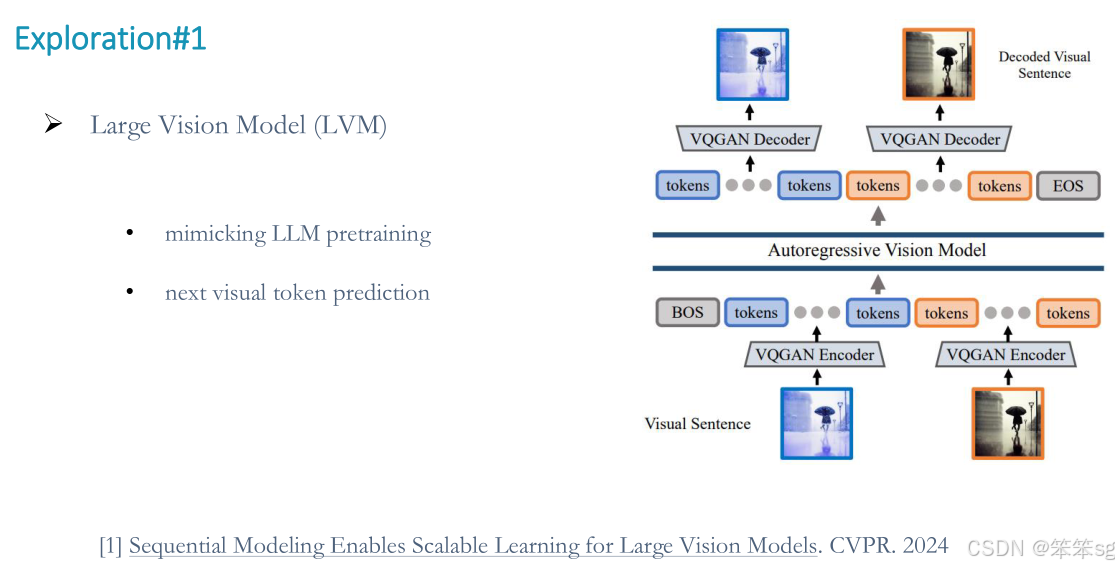
14.1 大视觉模型
LVM(Language-Visual Models) 提出了一个基于视觉的序列建模方法,类似于语言模型的预训练,这允许视觉模型在没有语言数据的情况下学习。
模拟LLM预训练;下一个视觉标记预测。
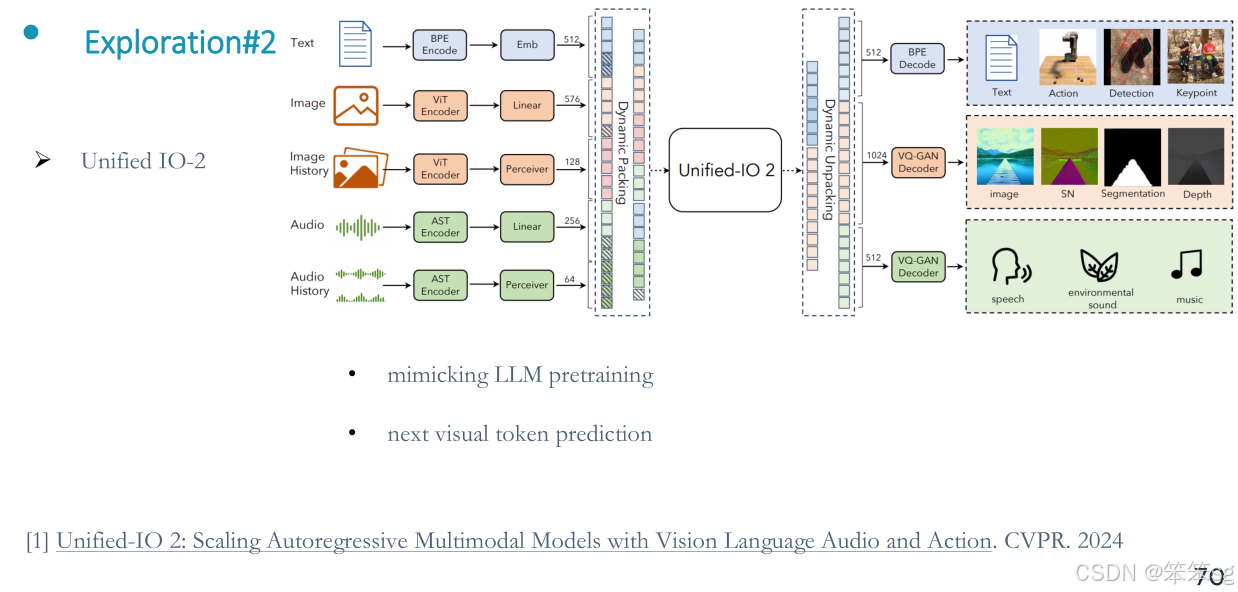
14.2 全自动多模态大模型
Unified IO2 是一个全自动的多模态模型,经过大规模的预训练,能够处理多种任务,如图像生成、语言理解、视频音频理解等。
15 一些值得探究的问题
15.1 统一MLLM下的最优模型架构是什么?
多模态系统是否可以完全去除语言模型,而仅依赖视觉或其他模态?比如,Diffusion模型已被广泛应用于图像生成,但对于其他模态,哪些架构是最优的?

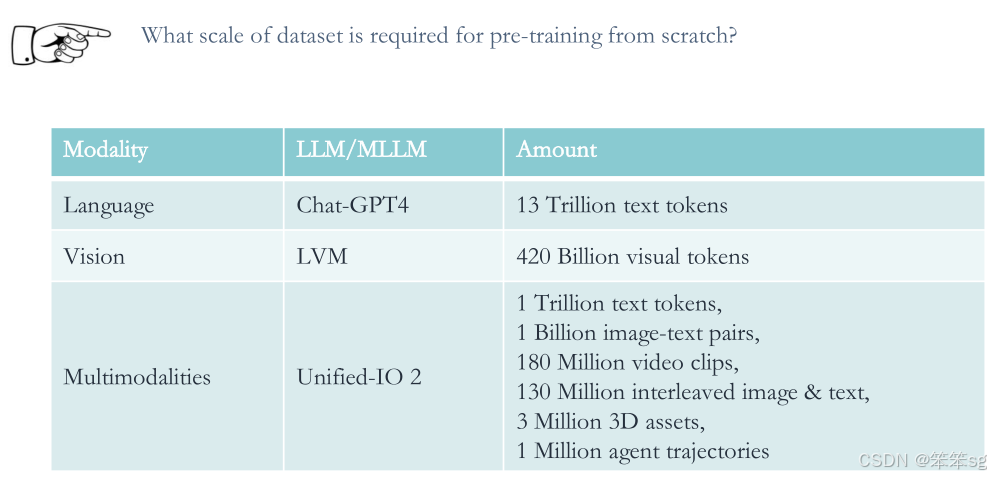
15.2 从头开始预训练需要多大规模的数据集?
例如,Unified IO2 使用了大量的多模态数据进行训练,但仍未表现出真正强大的多模态智能行为。问题:需要多少数据才能触发“多模态行为”的出现?
15.3 如何缩小纯粹的多模态模型与当前SoTA“LLM+编码器/解码器”架构的mllm在下游任务上的性能差距?
目前的多模态系统使用编码器-解码器架构,问题:如何缩小这种差距,使得纯粹的多模态模型能在实际应用中表现得更好?

15.4 多模态数据的最佳表示方法是什么?
多模态数据集的表示方法对模型性能至关重要。当前大多数模型依赖patches来表示图像,但这可能会导致问题。
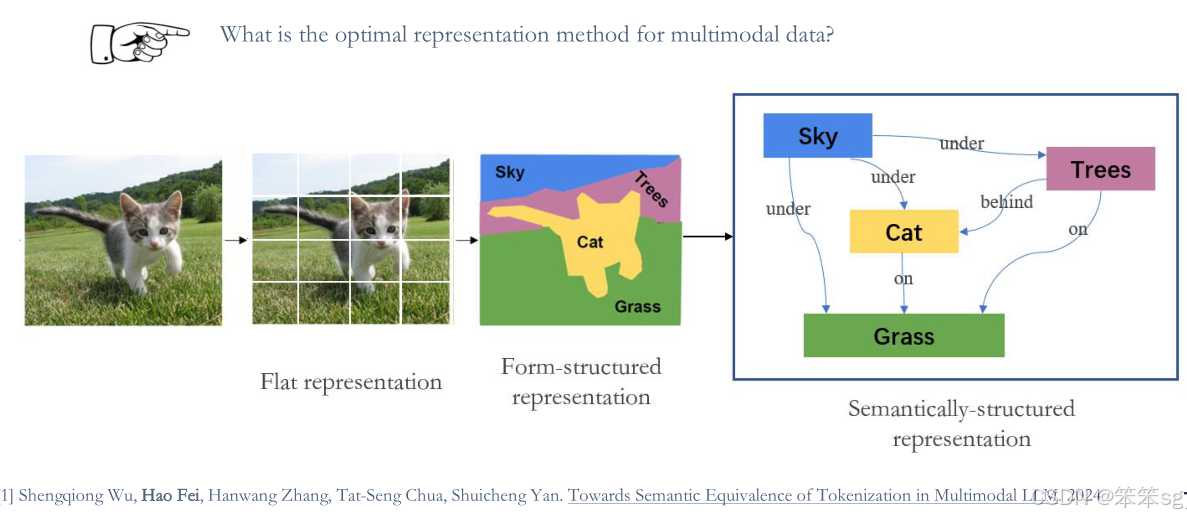
方案:提出了语义等效区域标记器(semantic equivalent region tokenizer)来实现视觉和文本标记之间的语义对齐。


















 2010
2010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









