






一、强化学习概念
概念:强化学习是机器学习的一种,它通过与环境不断地交互,借助环境的反馈来调整自己的行为,使得累计回报最大。强化学习要解决的是决策问题—
人话: 是让计算机实现从一开始什么都不懂, 脑袋里没有一点想法, 通过不断地尝试, 从错误中学习, 总结经验,最后找到规律, 学会了达到目的的方法.
eg:类似于人,考研数学,开始学微积分,跟着老师学习总结规律,
人会懒,机器人是卷王,比如近期最有名的 Alpha go, 机器头一次在围棋场上战胜人类
2、实际中的强化学习例子有很多. 让计算机自己学着玩i, 这些都是让计算机在不断的尝试中更新自己的行为准则, 从而一步步学会如何下好围棋, 如何操控游戏得到高分.
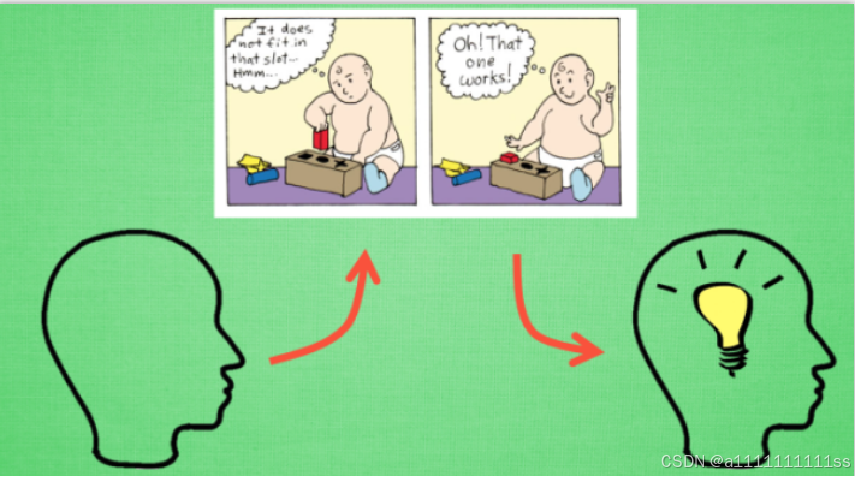
3、计算机也需要一位虚拟的老师, 这个老师比较吝啬, 他不会告诉你如何移动, 如何做决定, 他为你做的事只有给你的行为打分, 那我们应该以什么形式学习这些现有的资源, 或者说怎么样只从分数中学习到我应该怎样做决定呢? 很简单, 我只需要记住那些高分, 低分对应的行为, 下次用同样的行为拿高分, 并避免低分的行为
4、对比监督学习
我们知道监督学习, 是已经有了数据和数据对应的正确标签, 比如这样. 监督学习就能学习出那些脸对应哪种标签. 不过强化学习还要更进一步, 一开始它并没有数据和标签.

.5、做事情都会有一个自己的行为准则, 比如小时候爸妈常说”不写完作业就不准看电视”. 所以我们在 写作业的这种状态下, 好的行为就是继续写作业, 直到写完它, 我们还可以得到奖励, 不好的行为 就是没写完就跑去看电视了, 被爸妈发现, 后果很严重. 小时候这种事情做多了, 也就变成我们不可磨灭的记忆. 这和我们要提到的 Q learning 原来 Q learning 也是一个决策过程, 和小时候的这种情况差不多.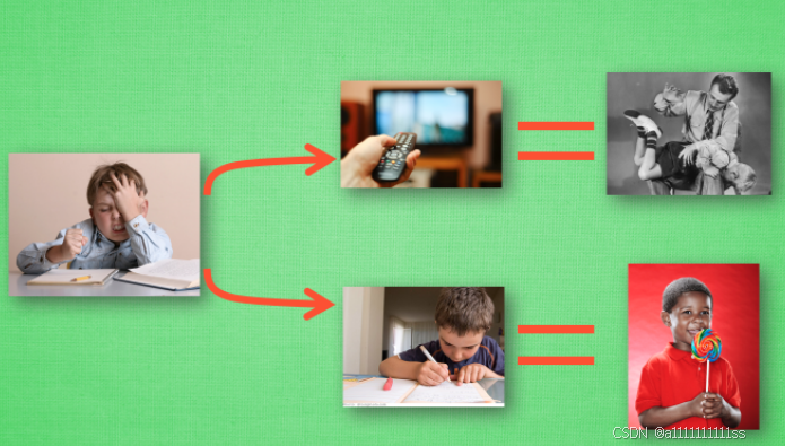
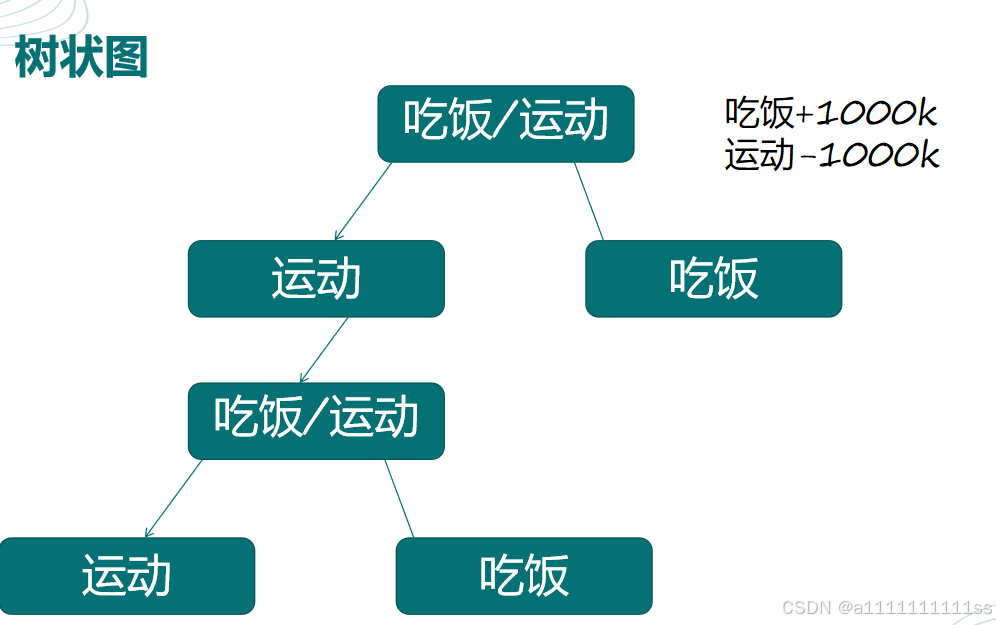


6、区别
做决定的计划好几个选项,然后选一个对我们最好的准备去做,eg你起床,计划今天
第一步,上午学习 第二步,下午学习 第三步,晚上学习, 但是实际上真的能够完成吗???
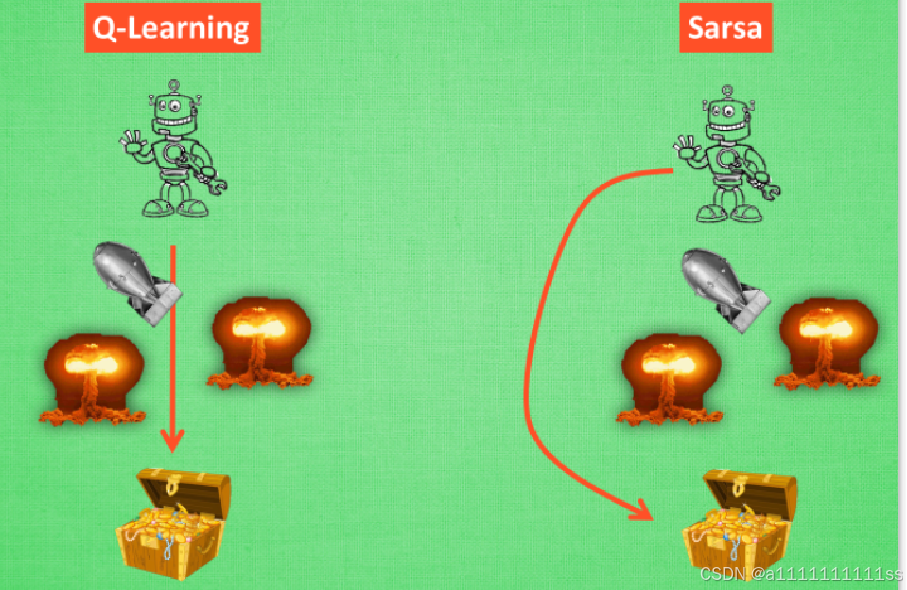
如果你用的是 Q learning, 那么就跟我们人一样,会偷懒明知学习最好,带来的收益最高,但是真选择的时候并非会选。但是Sarsa 是卷王不折不扣执行。
概念:Q-learning 是口嗨王者,在这一步只是估计了一下接下来的动作值. 而 Sarsa 是实践派, 他说到做到, 在 这一步估算的动作也是接下来要做的动作.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









