







 本文介绍使用Scrapy框架进行图片爬取的具体实现方法,包括配置下载中间件、定义Item和解析图片链接的过程。通过设置特定的下载路径和字段,实现了图片的有效下载。
本文介绍使用Scrapy框架进行图片爬取的具体实现方法,包括配置下载中间件、定义Item和解析图片链接的过程。通过设置特定的下载路径和字段,实现了图片的有效下载。
获得图片 传入下载得item
name = 'demo'
end = 1
url = 'https://www.qiushibaike.com/pic/'
start_urls = [url+str(end)]
def parse(self, response):
it = ScrapydemoItem()
mt = response.xpath('.//div[@class="thumb"]/a/img/@src').extract()
print(len(mt))
for ms in mt:
it['url'] = ['http:'+ms]
yield it
在settings 里面设置
ITEM_PIPELINES = {
'scrapydemo.pipelines.ScrapydemoPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
IMAGES_STORE = 'imagesrc'
IMAGES_URLS_FIELD = 'url'
结果
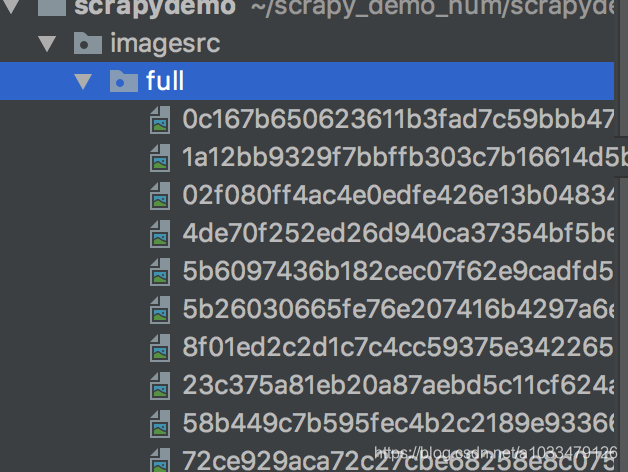

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









