






 本文介绍了YOLO目标检测算法的发展历程,从YOLOv1的实时性与精度平衡到YOLOv2的分辨率提升、anchor box引入及结构优化,再到YOLOv3的多尺度检测和网络深化,探讨了其在小物体检测上的改进。
本文介绍了YOLO目标检测算法的发展历程,从YOLOv1的实时性与精度平衡到YOLOv2的分辨率提升、anchor box引入及结构优化,再到YOLOv3的多尺度检测和网络深化,探讨了其在小物体检测上的改进。
YOLO
YOLO是stage one和real-time detector检测方法的鼻祖。速度高达45fps,fast YOLO达到155fps。
将图片划分为S x S的网格,在每个网格中预测B个Bounding box和一个confidence score,这个score由所有box 共享。故YOLO最终输出tensor个数是S * S * (B*5 + C),其中C是class的个数。
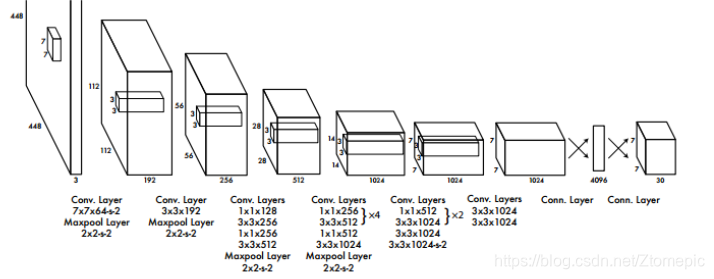 YOLO的结构如上图,基于LeNet,24 x 卷积层 + 2 x FC层。
YOLO的结构如上图,基于LeNet,24 x 卷积层 + 2 x FC层。
对自动驾驶来说,YOLOv1实时性够,但是精度太差;由于小物体的信息在conv和pooling中损失,而YOLO只关注最后卷积后的信息,所以对小物体表现较差;每个网格内只能检测出一类物体(SSD改进),往往选用FPN(+Faster R-CNN)。
YOLOv2
相比YOLO:
1.提高了输入图片的分辨率
2.引入了anchor box
3.优化结构
anchor box
对每个检测出的中心点,取多种不同比例的可能的候选窗口(不懂anchorbox到底怎么生成和使用。。估计得看看faster RCNN的文献)
优化结构
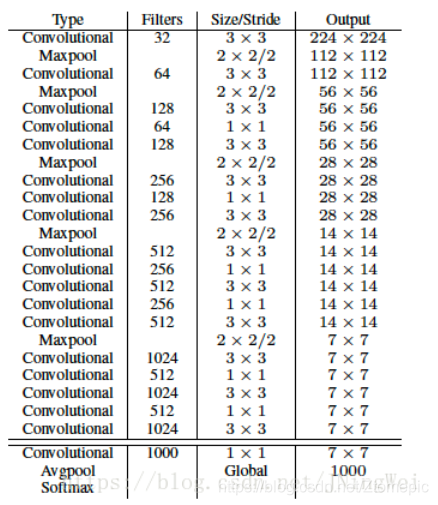
使用1x1卷积层来替代v1中的全连接层,解除了v1中使用固定节点数的全连接层而对输入图片大小产生的限制。
参考VGG,使用大量3x3卷积核,池化操作使图片尺寸减半后,总是使通道数翻倍。网络使用了全局平均池化(global average pooling),把 1 * 1 的卷积核置于 3 * 3 的卷积核之间,用来压缩特征。使用batch normalization稳定模型。最终对应的模型是Darknet-19。
Batch Normalization
卷积层全部使用Batch Normalization。
K-Means
Faster R-CNN的anchor box由经验设定,网络随后在训练中调整其尺寸。YOLOv2使用K-Means对训练集的bounding box聚类,寻找anchor box合适的大小和比例。
K-Means通常使用欧氏距离,这会导致一个问题,当尺寸大时。其误差也更大,为了解决这个问题,通过IOU来定义特定的距离函数:D = 1 - IOU。综合考虑模型的效率和recall值,采用K=5.
多种输入图像尺寸
每迭代训练几次后会微调输入尺寸,具体次数与设置文件中的random有关。
YOLOv3
bbox的分类方法从softmax换成了逻辑回归。
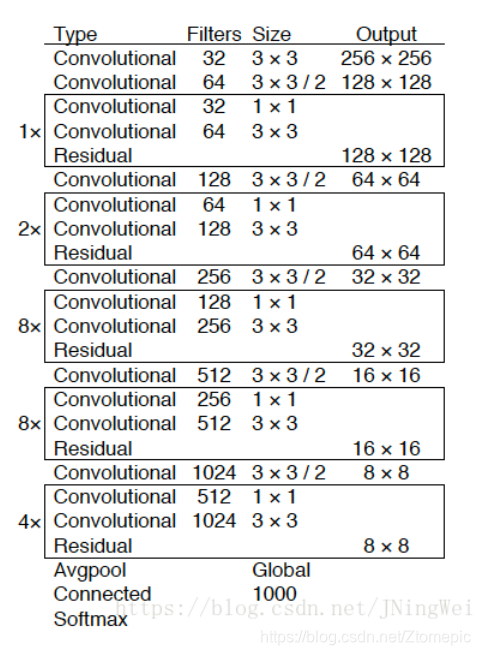
采用了3种scale,使用leaky relu激活函数,加深网络至53层,提升了精度,特别是小物体的精度,但是速度减慢一半。

















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









