




 本文详细介绍了Scrapy爬虫框架的使用,包括Scrapy组件的作用、简单抓取的步骤、数据存储方法、CrawlSpider的LinkExtractor和Rule、Scrapy Shell的运用、Request和Response对象的操作、模拟登录社交平台、文件和图片的下载、下载器中间件的实现以及Scrapy-Redis分布式爬虫的原理。内容涵盖了从基础到进阶的多个方面,适合爬虫学习者参考。
本文详细介绍了Scrapy爬虫框架的使用,包括Scrapy组件的作用、简单抓取的步骤、数据存储方法、CrawlSpider的LinkExtractor和Rule、Scrapy Shell的运用、Request和Response对象的操作、模拟登录社交平台、文件和图片的下载、下载器中间件的实现以及Scrapy-Redis分布式爬虫的原理。内容涵盖了从基础到进阶的多个方面,适合爬虫学习者参考。
爬虫虫案例使用网址:Scrape Center
1. Scrapy框架
pip install scrapy
pip install pypiwin32提高效率
用scrapy创建爬虫文件。
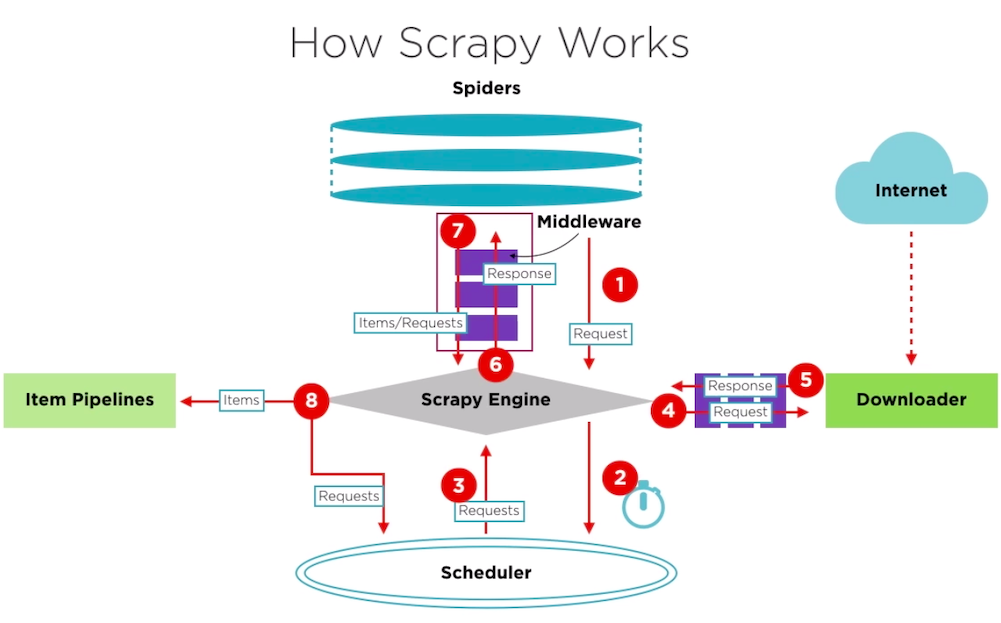
- Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
scrapy startproject scrapy_demo 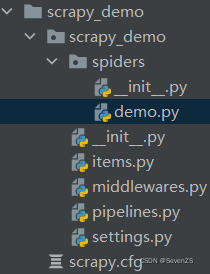
进入创建的文件夹内,用命令行
scrapy genspider demo "https://ssr1.scrape.center/"- items.py:用来存放爬虫爬取下来数据的模型。
- middlewares.py:用来存放各种中间件的文件。
- pipelines.py:用来将
items的模型存储到本地磁盘中。 - settings.py:本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)。
- scrapy.cfg:项目的配置文件。
- spiders包:以后所有的爬虫,都是存放到这个里面。
爬虫名不能和项目名一致。
2. 实验一简单抓取
1. response是一个 'scrapy.http.response.html.HtmlResponse' 对象,可以执行 'xpath' 和 'css' 语法来提取数据。
2. 提取出来的数据,是一个 ’Selector‘ 或者是一个 'SelectorList' 对象。如果想要获取其中的字符串,应该执行 'getall' 或者 'get' 方法
3. getall:获取 'Selector' 中的所有文本,返回一个列表
4. get:获取 'Selector' 中的第一个文本,返回一个str类型
5. 如果数据解析回来,要传给pipeline处理,可以使用‘yield‘返回,或者收集所有的item,最后统一使用return返回。
6. item:建议在 'items.py' 中定义好模型。以后不要使用字典。
7. pipeline:专门用来保存数据的。其中有三个方法经常用:
'open_spider(self, spider)':当爬虫被打开的时候执行
'process_item(self, item, spider)':当爬虫有item传过来的时候被调用
'close_spider(self, spider)':当爬虫关闭的时候被调用
要激活pipeline,要在’settings.py'中,设置'ITEM_PIPELINES'.
在setting里修改
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39',
}
DOWNLOADER_MIDDLEWARES = {
'scrapy_demo.middlewares.ScrapyDemoDownloaderMiddleware': None,
}
ITEM_PIPELINES = {
'scrapy_demo.pipelines.ScrapyDemoPipeline': 300,
}
AUTOTHROTTLE_START_DELAY = 0.5实验
demo.py里 做实验。
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['https://ssr1.scrape.center']
start_urls = ['https://ssr1.scrape.center/']
def parse(self, response):
print('=' * 40)
print(type(response))
print('=' * 40)运行的时候,在scrapy_demo文件夹下打开terminal
scrapy crawl demo
新建一个py文件
在start.py里运行在命令行运行的代码。以后都只运行start就可以了。
#encoding: utf-8
from scrapy import cmdline
cmdline.execute("scrapy crawl demo".split())简单的爬虫
demo.py
import scrapy
from scrapy.http.response.html import HtmlResponse
from scrapy.selector.unified import SelectorList
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['https://ssr1.scrape.center']
start_urls = ['https://ssr1.scrape.center/']
def parse(self, response):
# SelectorList类型
print("=" * 40)
movies = response.xpath('//*[@id="index"]/div[1]/div[1]/div')
for movie in movies:
# Selector类型
movie_name = movie.xpath('.//h2/text()').get().strip() # 获取当前目录下的h2标签
movie_locate = movie.xpath('./div/div/div[2]/div[2]/span[1]/text()').getall()
movie_locate = "".join(movie_locate).strip()
print(movie_name)
print(movie_locate)
print("=" * 40)保存数据
推荐放在pipelines里写。
demo.py里添加
movie_dic = {"name": movie_name, "locate": movie_locate}
yield movie_dic # 把普通函数变成一个生成器yield 会给engine,由engine移交给pipelines
pipelines.py
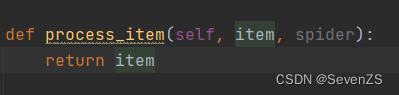
yield会把数据传给item进入process_item函数
import json
class ScrapyDemoPipeline:
def __init__(self):
self.fp = open("./movie.json", 'w', encoding='utf-8')
def open_spider(self, spider):
print('spider open!')
def process_item(self, item, spider):
item_json = json.dumps(item)
self.fp.write(item_json + '\n')
return item
def close_spider(self, spider):
self.fp.close()
print('down!')item.py
import scrapy
class ScrapyDemoItem(scrapy.Item):
movie_name = scrapy.Field()
movie_locate = scrapy.Field()在demo.py中import
专业的写法
下面yield修改。这是一个比较专业的写法。
from scrapy_demo.items import ScrapyDemoItem
......
item = ScrapyDemoItem(movie_name=movie_name, movie_locate=movie_locate)
yield item # 把普通函数变成一个生成器
修改pipelines.py
def process_item(self, item, spider):
item_json = json.dumps(dict(item), ensure_ascii=False)
self.fp.write(item_json + '\n')
return item优化存储
'JsonItemExporter' 和 'JsonLinesItemExporter'
保存json数据的时候,使用这两个类,可以让操作变得更简单。
1. ‘JsonItemExporter’:每次把数据添加到内存中,最后统一写入到磁盘中。
好处是,存储的数据是一个满足json规则的数据。
坏处是如果数据量比较大,那么比较耗内存。
2. ‘JsonLinesItemExporter’:每次调用 'export_item' 的时候酒吧这个item存储到硬盘中。
好处是每次处理数据的时候直接存储到硬盘中,这样不会耗内存,数据比较安全。
坏处是每一个字典是一行,整个文件不是一个满足json格式的文件。
用二进制存储进json,二进制不能指定编码encoding
JsonItemExporter
由于是先缓存再一起保存,当存储的内容太多时,缓存压力大。并且保存的结果是一整行的字典。
from scrapy.exporters import JsonItemExporter
class ScrapyDemoPipeline:
def __init__(self):
self.fp = open("./movie.json", 'wb')
self.exporter = JsonItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
self.exporter.start_exporting()
def open_spider(self, spider):
print('spider open!')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.exporter.finish_exporting()
self.fp.close()
print('down!')JsonLinesItemExporter
一行行保存,不需要开始和关闭。并且保存的是一个字段一行。
from scrapy.exporters import JsonLinesItemExporter
class ScrapyDemoPipeline:
def __init__(self):
self.fp = open("./movie.json", 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
def open_spider(self, spider):
print('spider open!')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.fp.close()
print('down!')抓取多个页面
找到下一页,点击下一页。注意在最后一页的时候没有下一页。
dont_filter=True一定要加上,否则第二次爬取会被过滤。
import scrapy
from scrapy.http.response.html import HtmlResponse
from scrapy.selector.unified import SelectorList
from scrapy_demo.items import ScrapyDemoItem
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['https://ssr1.scrape.center']
start_urls = ['https://ssr1.scrape.center/page/1']
base_domain = "https://ssr1.scrape.center"
def parse(self, response):
# SelectorList类型
print("=" * 40)
movies = response.xpath('//*[@id="index"]/div[1]/div[1]/div')
for movie in movies:
# Selector类型
movie_name = movie.xpath('.//h2/text()').get().strip() # 获取当前目录下的h2标签
movie_locate = movie.xpath('./div/div/div[2]/div[2]/span[1]/text()').getall()
movie_locate = "".join(movie_locate).strip()
# print(movie_name)
# print(movie_locate)
item = ScrapyDemoItem(movie_name=movie_name, movie_locate=movie_locate)
yield item # 把普通函数变成一个生成器
next_url = response.xpath('//*[@id="index"]/div[2]/div/div/div/a[@class="next"]/@href').get()
if not next_url:
return
else:
print(next_url)
yield scrapy.Request(self.base_domain+next_url, callback=self.parse, dont_filter=True)
print("=" * 40)
3. CrawlSpider
需要使用 ’LinkExtractor‘ 和 'Rule' 。这两类决定爬虫的具体走向。
1. allow设置规则方法:要能够限制在我们想要的url上面。不要跟其他的url产生相同的正则表达式即可。
2. 什么情况下使用follow:如果在爬取页面的时候,需要将满足当前条件的url再进行跟进,那么就设置为True,否则设置为False。
3. 什么情况下该指定callback:如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不指定callback。如果想要获取url对应页面中的数据,那么就需要指定一个callback。
创建CrawlSpider命令
scrapy genspider -c crawl wechatapp_spider ""LinkExtractor类
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)- allow:允许的url。所有满足这个正则表达式的url都会被提取。
- deny:禁止的url。所有满足这个正则表达式的url都不会被提取。
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取。
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule类
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)- link_extractor:一个
LinkExtractor对象,用于定义爬取规则。 - callback:满足这个规则的url,应该要执行哪个回调函数。因为
CrawlSpider使用了parse作为回调函数,因此不要覆盖parse作为回调函数自己的回调函数。 - follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
crawlspider里不要再写parse方法了,因为crawlspider底层会调用parse,如果写了会冲掉crawlspider的,不安全。
爬虫代码
重点是Rule里的alllow如何根据自己所需写。
wechatapp_spider.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from crawl_wechatapp.items import CrawlWechatappItem
class WechatappSpiderSpider(CrawlSpider):
name = 'wechatapp_spider'
allowed_domains = ['wxapp-union.com']
start_urls = ['https://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1']
# ./表示前面可以为任意内容
rules = (
Rule(LinkExtractor(allow=r'.+mod=list&catid=2&page=\d'), follow=True),
Rule(LinkExtractor(allow=r'.+article-.+\.html'), callback='parse_item', follow=False)
)
def parse_item(self, response):
print("=" * 40)
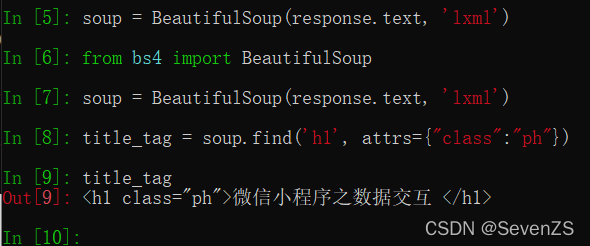
title = response.xpath('//h1[@class="ph"]/text()').get()
author_P = response.xpath('//p[@class="authors"]')
author = author_P.xpath('.//a/text()').get()
pub_time = author_P.xpath('.//span/text()').get()
article_content = response.xpath('//td[@id="article_content"]//text()').getall()
content = "".join(article_content).strip()
item = CrawlWechatappItem(title=title, author=author, pub_time=pub_time, content=content)
print(title)
print('author:%s / pub_time:%s' % (author, pub_time))
print(content)
print("=" * 40)
yield itemitems.py
import scrapy
class CrawlWechatappItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
pub_time = scrapy.Field()
content = scrapy.Field()
pass
pipelines.py
from scrapy.exporters import JsonLinesItemExporter
class CrawlWechatappPipeline:
def __init__(self):
self.fp = open('wechatapp_course.json', 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.fp.close()4. Scrapy Shell
1. 方便做数据提取的测试代码
2. 如果想要执行scrapy命令,需要进入到scrapy所在的环境
3. 如果想要读取某个项目的配置信息,首先进入项目文件夹下,再执行 ’scrapy shell‘ 命令
进入scrapy项目所在的终端目录,进入到虚拟环境,输入
scrapy shell https://www.wxapp-union.com/article-7259-1.html直接跟链接,不用“”。

5. Request和Response对象
Request对象
在我们写爬虫,爬取一页的数据需要重新发送一个请求的时候调用。这个类需要传递一些参数,其中比较常用的参数有:
1. url :这个request对象发送请求的url
2. callback:在下载器下款完相应的数据后执行的回调团数。
3. method:请求的方法。默认为GET方法,可以设置为其他方法。
4. headers :请求头,对于一些固定的设置,放在settings.py中指定就可以了。对于那些非图定的,可以在发送请求的时候指定。
5. meta:比较常用,用于在不同的请求之间传通数据用的。
6. encoding :编码,默认的为utf-8 ,使用默认的就可以了。
7. dot_filter:表示不由调度器过法,在执行多次重复的请求的时候用得比较多。
8. errback:在发生错误的时候执行的团数。
Response对象
Response对象一般是由Scrapy拾你自动构建的,因此开发者不需要关心如何创建Response对象,而是如何快用他。Response对象有很多属性,可以用未提取数据的。主要有以下属性:
1. meta:从其他请求传过来的neta属性,可以用来保持多个请求之间的数据连接。
2. encoding:返回当前字符串摘码和解码的格式。
3. text:将返回来的数据作为 unicode字符串返回。
4. body:将返回来的数据作为bytes字符串返回。
5. xpath: xapth选择器
6. css: css选择器。
发送Post请求
有时候我们想要在请求数据的时候发送post请求,那么这时候需要使用 'Request' 的子类 'FornRequest' 来实现。
如果想要在爬虫一开始的时候就发送POST请求,那么需要在爬虫类中重写 'start_reguests(self)' 方法,并且不再调用 'start_urls' 里的url。
6. 模拟登录社交平台
renren
17年的视频,人人可以登。现在这个用不了了。
1. 发送post请求,使用 ‘scrapy.FormRequest’ .可以方便的指定表单数据。
2. 如果想要爬虫一开始就发送post请求,那么要重写 'start_requests' 方法。在这个方法中发送post请求。
renren.py
import scrapy
class RenrenSpider(scrapy.Spider):
name = 'renren'
allowed_domains = ['renren.com']
start_urls = ['http://renren.com/']
def start_requests(self):
url = "https://rrwapi.renren.com/account/v1/loginByPassword"
data = {
"user": "120****@qq.com",
"password": "a****4",
}
request = scrapy.FormRequest(url, formdata=data, callback=self.parse_page)
yield request
def parse_page(self, response):
# with open('renren.html', 'w', encoding='utf-8') as fp:
# fp.write(response.text)
request = scrapy.Request(url='http://www.renren.com/personal/5****43', callback=self.parse_profile)
yield request
def parse_profile(self, response):
with open('my.html', 'w', encoding='utf-8') as fp:
fp.write(response.text)
douban
豆瓣页面有大改,这个是17年可以用的。学习就好。
import scrapy
from urllib import request
from PIL import Image
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
start_urls = ['https://accounts.douban.com/passport/login']
login_url = 'https://accounts.douban.com/passport/login'
profile_url = 'http://www.douban.com/people/xxxxx'
editsignature_url = 'https://www.douban.com/j/people/xxxxx/edit_signature'
def parse(self, response):
formdata = {
'source': 'None',
'redir': 'https://www.douban.com/',
'form_email': '461614193@qq.com',
'form_password': 'popo8888dd',
'remember': 'on',
'login': '登录'
}
captcha_url = response.css('img#captcha_image::attr(src)').get()
if captcha_url:
captcha = self.recognize_captchar(captcha_url)
formdata['captcha0solution'] = captcha
captcha_id = response.xpath("//input[@name='capture-id']/@value").get()
formdata['captcha-id'] = captcha_id
yield scrapy.FormRequest(url=self.login_url, formdata=formdata, callback=self.parse_after_login)
def parse_after_login(self, response):
if response.url == 'https://www.douban.com/':
yield scrapy.Request(self.profile_url, callback=self.parse_profile) # 解析个人中心
print('登陆成功!')
else:
print('登陆失败')
def parse_profile(self, response):
if response.url == self.profile_url:
ck = response.xpath("//input[name='ok']/@value").get()
formdata = {
'ok': 'ok',
'signature': '更改签名档',
}
yield scrapy.FormRequest(self.editsignature_url, formdata=formdata)
print('修改成功!')
else:
print('没有进入到个人中心')
def recognize_captchar(self, image_url):
request.urlretrieve(image_url, 'captchat.png')
image = Image.open('captchat.png')
image.show()
captcha = input('请输入验证码: ')
return captcha
7. 下载文件和图片
scrapy为item中包含的文件(比如在爬到产品时,同时想保存对应的图片)提供了一个可重用的 'item pipelines' ,这些 'pipeline' 有一些共同的方法和结构,称为 'media pieline' 。一般来说使用 'Files Pipeline' 和 'Image Pipeline' 。
选择scrapy内置的下载文件方法的原因:
- 避免重新下载最近已经下载过的数据。
- 可以方便的指定文件存储的路径。
- 可以将下载的图片转换成通用的格式。比如png,jpg。
- 可以方便的生成缩略图。
- 可以方便的检测图片的宽和高,确保他们满足最小限制。
- 异步下载,效率非常高。
下载文件 Files Pipeline
当使用Files Pipeline下载文件的时候,按照以下步骤来完成:
- 定义好一个Iten,然后在这个Iten中定义两个属性,分别为file_urls以及files。 file_urls是用来存储需要下载的文件的url链接,需要给一个列表。
- 当文件下载完成后,会把文件下载的相关信息存储到item的files属性中。比如下载路径、下载的url和文件的校检码等。
- 在配置文件settings.py中配置FILES_STORE,这个配置是用来设置文件下载下来的路径。
- 启动pipeline:在ITER_PIPELINESP设置scrapy.pipelines.files.FilesPipeline:1
下载图片 Images Pipeline
当快用Inages Pipeline下载文件的时候,按照以下步骤来完成:
- 定义好一个Iten,然后在这个iten中定义两个属性,分别为 image_urls以及 Images。image_urls 是用来存储需要下载的图片的url链接,需要给一个列表。
- 当文件下载完成后,会把文件下载的相关信息存储到item的images属性中。比如下载路径、下载的url和图片的校验码等。
- 在配置文件settings.py中配员IMAGES_STORE,这个配置是用来设置图片下载下来的路径
- 启动 pipeline:在ITEM_PIPELINES中设置scrapy-pipelinPipeline:1
太复杂了。视频16p
items.py
import scrapy
class LamborghiniItem(scrapy.Item):
category = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
huracan.py
import scrapy
from lamborghini.items import LamborghiniItem
class HuracanSpider(scrapy.Spider):
name = 'huracan'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/pic/series/3277.html#pvareaid=3454438']
def parse(self, response):
# SelectorList -> list
uiboxes = response.xpath('//div[@class="uibox"]')[1:]
for uibox in uiboxes:
category = uibox.xpath('.//div[@class="uibox-title"]/a/text()').get()
urls = uibox.xpath('.//ul/li/a/img/@src').getall()
# for url in urls:
# # url = "https:"+url
# url = response.urlj oin(url) # 自动拼接成网址的样子
# print(url)
urls = list(map(lambda url: response.urljoin(url), urls))
item = LamborghiniItem(category=category, image_urls=urls)
yield item
setting.py
ITEM_PIPELINES = {
# 'lamborghini.pipelines.LamborghiniPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 1,
}
# 图片下载路径,供images pipelines使用
IMAGES_STORE = os.path.join(os.path.diname(os.path.dirname(__file__)), 'images')因为执行后会把图片全部放在full里,要创建各自的文件夹,因此进行修改。
pipelines.py
包含大量解析源码后的函数重用。很复杂
class LamborghiniPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 在发送下载请求之前调用。本身是发送请求的
request_objs = super(LamborghiniPipeline, self).get_media_requests(item, info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
def file_path(self, request, response=None, info=None, *, item=None):
# 在图片将被存储的时候调用,来获取图片存储的路径
path = super(LamborghiniPipeline, self).file_path(request, response, info)
category = request.item.get('category')
images_store = settings.IMAGES_STORE
category_path = os.path.join(images_store, category)
if not os.path.exists(category_path):
os.mkdir(category_path)
image_name = path.replace("full/", "")
image_path = os.path.join(category_path, image_name)
return image_path
settings.py
ITEM_PIPELINES = {
# 'lamborghini.pipelines.LamborghiniPipeline': 300,
# 'scrapy.pipelines.images.ImagesPipeline': 1,
'lamborghini.pipelines.LamborghiniPipeline': 1,
}8. Downloader Middlewares 下载器中间件
下载器中问件是引擎和下就器之问通信的中间件。在这个中间件中我们可以设置代理、更换请求头等来达到反反爬虫的目的。
要写下载器中间件,可以在下载器中实现两个方法
一个是process_request(self,neouest,spider),这个方法是在请求发送之前会执行
还有一个是process_response(self, request, response, spider) ,这个方法是数据下找到引擎之前执行。
process_request(self,neouest,spider)
这个方法是下载器在发送请求之前会执行的。一般可以在这个里面设置随机代理ip等。
1.参数:
- request:发送请求的request对象.
- spider:发送请求的spider对象。
2.返回值:
- 返回None:如果返回None, Scrapy将继续处理该request,执行其他中间件中的相应方法,直到合适的下载器处理的数被调用。
- 返回Response对象: Scrapy将不会调用任何其他的process_request方法,将直接返回这个response对象。已经激活的中间件的process_response0方法则会在每个response返回时被调用。
- 返回Request对象:不再使用之前的request对象去下款数据,而是根据现在返回的request对象返回数据。
- 如果这个方法中批出了异常,则会调用process_exception方法。
process_response(self, request, response, spider)
这个是下载器下载的数据到引蒙中间会执行的方法。
1.参数:
- request: request对象,
- response:被处理的response对象
- spider: spider对象
2.返回值:
- 返回Response对象:会将这个新的response对象传给其他中间件,最终传给爬虫。
- 返回Request对象:下就器链被切断,返回的request会重新被下载器调度下就。
- 如果批出一个异常,那么调用request的 errback方法,如果没有指定这个方法,那么会抛出一个异常。
随机请求头 反反爬虫
爬虫在须繁访问一个页面的时候,这个请求头如果一直保持一致。那么很容易被服务器发现,从而禁止掉这个请求头的访问。因此我们要在访问这个页面之前随机的更改请求头,这样才可以避免爬虫被抓。
随机更改请求头,可以在下载中间件中实现。在请求发送给服务器之前,随机的选择一个请求头。这样就可以避免总快用一个请求头了
各个浏览器版本的请求头 最好用最新的
middlewares.py
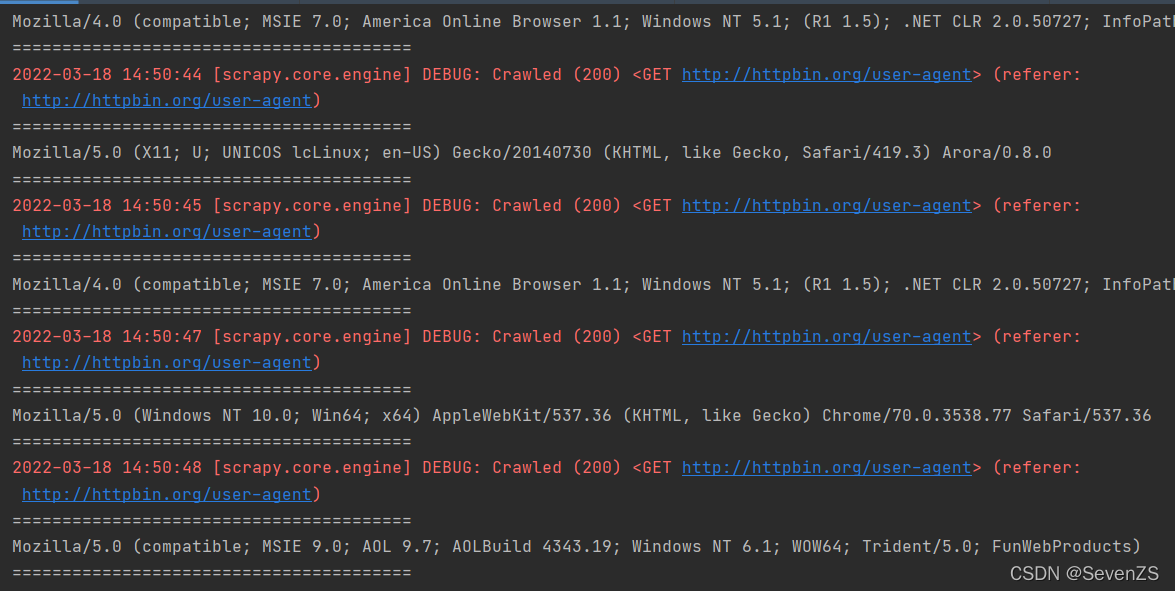
class UserAgentDemoDownloaderMiddleware(object):
USER_AGENTS = [
'Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser 1.98.744; .NET CLR 3.5.30729)',
'Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)',
'Mozilla/4.0 (compatible; MSIE 7.0; America Online Browser 1.1; Windows NT 5.1; (R1 1.5); .NET CLR 2.0.50727; InfoPath.1)',
'Mozilla/5.0 (compatible; MSIE 9.0; AOL 9.7; AOLBuild 4343.19; Windows NT 6.1; WOW64; Trident/5.0; FunWebProducts)',
'Mozilla/5.0 (X11; U; UNICOS lcLinux; en-US) Gecko/20140730 (KHTML, like Gecko, Safari/419.3) Arora/0.8.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
]
def process_request(self, request, spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agentsetting.py
DOWNLOAD_DELAY = 1
DOWNLOADER_MIDDLEWARES = {
'useragent_demo.middlewares.UserAgentDemoDownloaderMiddleware': 543,
}注意!里面的类名修改成了重新写的名字。
httpbin.py
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/user-agent']
def parse(self, response):
user_agent = json.loads(response.text)['user-agent']
yield scrapy.Request(self.start_urls[0], dont_filter=True)反复请求尝试
ip代理池中间件
在上面的基础上修改
middlewares.py
class IPProxyDownloadMiddleware(object):
# 多个代理ip使用
ROXIES = [
'5.196.189.50:8080',
'134.17.141.44:8080',
'178.49.136.84:8080',
'45.55.132.29:82',
'178.44.185.15:8080',
]
def process_request(self, request, spider):
proxy = random.choice(self.PROXIES)
request.meta['proxy'] = proxy
# # 独享代理 单个ip
# def process_request(self, request, spider):
# proxy = ['']
# user_password = ""
# request.meta['proxy'] = proxy
# # bytes
# b64_user_password = base64.b64encode(user_password.encode('utf-8'))
# request.headers['Proxy-Authorization'] = 'Basic ' + b64_user_password.decode('utf-8')setting.py
DOWNLOADER_MIDDLEWARES = {
'useragent_demo.middlewares.UserAgentDemoDownloaderMiddleware': 543,
'useragent_demo.middlewares.IPProxyDownloadMiddleware': 100,
}ipproxy.py
import scrapy
import json
class IpproxySpider(scrapy.Spider):
name = 'ipproxy'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/']
def parse(self, response):
origin = json.loads(response.text)['origin']
print('=' * 40)
print(origin)
print('=' * 40)
yield scrapy.Request(self.start_urls[0], dont_filter=True)9. BOSS直聘
正常爬取
访问次数多会403
zhipin.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from boss.items import BossItem
class ZhipinSpider(CrawlSpider):
name = 'zhipin'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/c101020100/?query=python&page=1&ka=page-1']
rules = (
# 匹配职位列表页的规则
Rule(LinkExtractor(allow=r'.+\?query=python&page=\d'), follow=True),
# 匹配职业详情页的规则
Rule(LinkExtractor(allow=r'.+job_detail/\d*.html'), callback="parse_job", follow=False),
)
def parse_job(self, response):
title = response.xpath('///div[@class="info-primary"]/div[2]/h1/text()').get().strip()
salary = response.xpath('//span[@class="salary"]/text()').get().strip()
job_info = response.xpath('//div[@class="job-primary detail-box"]/div[@class="info-primary"]/p//text()').getall()
city = job_info[0]
work_years = job_info[1]
education = job_info[2]
company = response.xpath('//div[@class="sider-company"]//a/text()').get()
item = BossItem(title=title, salary=salary, city=city, work_years=work_years, education=education, company=company)
yield item
pipelines.py
from scrapy.exporters import JsonLinesItemExporter
class BossPipeline:
def __init__(self):
self.fp = open('jobs.json', 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False)
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.fp.close()无限爬取
使用代理池
middlewares.py 全部重写
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import random
import requests
import json
from boss.model import ProxyModel
from twisted.internet.defer import DeferredLock # 进程锁
class UserAgentDownloadMiddleware(object):
USER_AGENTS = [
'Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser 1.98.744; .NET CLR 3.5.30729)',
'Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)',
'Mozilla/4.0 (compatible; MSIE 7.0; America Online Browser 1.1; Windows NT 5.1; (R1 1.5); .NET CLR 2.0.50727; InfoPath.1)',
'Mozilla/5.0 (compatible; MSIE 9.0; AOL 9.7; AOLBuild 4343.19; Windows NT 6.1; WOW64; Trident/5.0; FunWebProducts)',
'Mozilla/5.0 (X11; U; UNICOS lcLinux; en-US) Gecko/20140730 (KHTML, like Gecko, Safari/419.3) Arora/0.8.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
]
def process_request(self, request, spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agent
class IPProxyDownloadMiddleware(object):
PROXY_URL = ''
def __init__(self):
super(IPProxyDownloadMiddleware, self).__init__()
self.current_proxy = None
self.lock = DeferredLock
def process_request(self, request, spider):
if 'proxy' not in request.meta or self.current_proxy.is_expiring:
# 请求代理
proxy_model = self.get_proxy()
request.meta['proxy'] = self.current_proxy.proxy
def process_response(self, request, response, spider):
if response.status != 200 or "captcha" in response.url:
if not self.current_proxy.blacked:
self.current_proxy.blacked = True
print("%s这个代理被加入黑名单了"%self.current_proxy.ip)
# 如果到这里,相当于被boss直聘识别为爬虫屏蔽了。没有获得数据
# 这个请求被拒绝了
self.update_proxy()
return request
# 如果是正常的,要返回response,如果不返回,就不会被传到爬虫,不会被解析
return response
def update_proxy(self):
# 异步锁
self.lock.acquire()
if not self.current_proxy or self.current_proxy.is_expiring or self.current_proxy.blacked:
response = requests.get(self.PROXY_URL)
text = response.text
result = json.loads()
if len(result['data']) > 0:
data = result['data'][0]
proxy_model = ProxyModel(data)
self.current_proxy = proxy_model
# return proxy_model
self.lock.release()新建了一个model.py
#encoding: utf-8
from datetime import datetime, timedelta
# 这个是把买来的ip地址的链接打印出来后,里面的字典有什么就写什么。不固定的。
class ProxyModel(object):
def __init__(self, data):
self.ip = data['ip']
self.port = data['port']
self.expire_str = data['expire_time']
self.blacked = False
date_str, time_str = self.expire_str.split(" ")
year, month, day = date_str.split("-")
hour, minute, second = time_str.split(":")
date_time = datetime(year=int(year), month=int(month), day=int(day), hour=int(hour), minute=int(minute),
second=int(second))
# https://ip:port
self.proxy = "https://{}:{}".format(self.ip, self.port)
#property
def is_expiring(self):
now = datetime.now()
if (self.expire_str - now) < timedelta(seconds=5): # 过期就换
return True
else:
return False
主代码zhipin.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from boss.items import BossItem
class ZhipinSpider(CrawlSpider):
name = 'zhipin'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/c101020100/?query=python&page=1&ka=page-1']
rules = (
# 匹配职位列表页的规则
Rule(LinkExtractor(allow=r'.+\?query=python&page=\d'), follow=True),
# 匹配职业详情页的规则
Rule(LinkExtractor(allow=r'.+job_detail/\d*.html'), callback="parse_job", follow=False),
)
def parse_job(self, response):
title = response.xpath('///div[@class="info-primary"]/div[2]/h1/text()').get().strip()
salary = response.xpath('//span[@class="salary"]/text()').get().strip()
job_info = response.xpath('//div[@class="job-primary detail-box"]/div[@class="info-primary"]/p//text()').getall()
city = job_info[0]
work_years = job_info[1]
education = job_info[2]
company = response.xpath('//div[@class="sider-company"]//a/text()').get()
item = BossItem(title=title, salary=salary, city=city, work_years=work_years, education=education, company=company)
yield item
setting.py
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
}
DOWNLOADER_MIDDLEWARES = {
'boss.middlewares.UserAgentDownloadMiddleware': 100,
'boss.middlewares.UserAgentDownloadMiddleware': 200,
}
ITEM_PIPELINES = {
'boss.pipelines.BossPipeline': 300,
}
AUTOTHROTTLE_START_DELAY = 1pipelines.py
from scrapy.exporters import JsonLinesItemExporter
class BossPipeline:
def __init__(self):
self.fp = open('jobs.json', 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False)
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.fp.close()items.py
import scrapy
class BossItem(scrapy.Item):
name = scrapy.Field()
salary = scrapy.Field()
city = scrapy.Field()
work_years = scrapy.Field()
education = scrapy.Field()
company = scrapy.Field()10. 简书网站整站爬虫
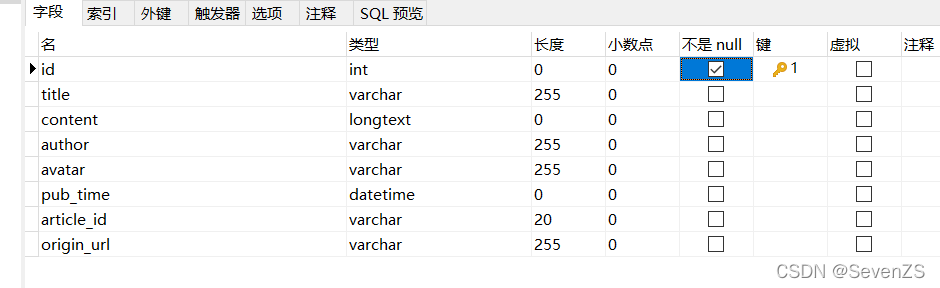
将数据保存到mysql数据库中
讲selenium+chromedriver集成到scrapy
特点是,很多数据是通过Ajax加载进来的。不能直接获取。
简单的爬虫
主文件js.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from jianshu_spider.items import ArticleItem
class JsSpider(CrawlSpider):
name = 'js'
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/']
rules = (
Rule(LinkExtractor(allow=r'.*/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),
)
def parse_detail(self, response):
title = response.xpath('//h1[@class="_1RuRku"]/text()').get()
author = response.xpath('//span[@class="_22gUMi"]/text()').get()
avatar = response.xpath('//div[@class="image-view"]/img/@data-original-src').get()
# pub_time = response.xpath('//div[@class="s-dsoj"]/time/text()').get()
pub_time = []
url = response.url
# 直接从url里找
url1 = url.split("?")[0]
article_id = url1.split("/")[-1]
content = response.xpath('//article[@class="_2rhmJa"]').get()
item = ArticleItem(title=title,
avatar=avatar,
author=author,
pub_time=pub_time,
origin_url=response.url,
article_id=article_id,
content=content,
)
yield item
items.py
import scrapy
class ArticleItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
article_id = scrapy.Field()
origin_url = scrapy.Field()
author = scrapy.Field()
avatar = scrapy.Field()
pub_time = scrapy.Field()没有办法获取到pub_time。审查元素和源代码不同,源代码里的时间是获取来的。没办法抓到。
保存到mysql
这里是手动创建数据库。
一直报错1064,查不出错。
pipelines.py
import pymysql
class JianshuSpiderPipeline:
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '1234',
'database': 'jianshu',
'charset': 'utf8'
}
self.conn = pymysql.connect(**dbparams)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
self.cursor.execute(self.sql, (item['title'], item['content'], item['author'], item['avatar'], item['pub_time'],
item['origin_url'], item['article_id']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql = """
insert into article(id, title, content, author, avatar, pub_time, origin_url, article_id) values(null, {%s}, {%s}, {%s}, {%s}, {%s}, {%s}, {%s})
"""
return self._sql
return self._sql
如果使用异步连接池,效率更高。
pipelines.py 记得改掉setting里的pipeline
class JianshuTwistedPipeline(object):
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '1234',
'database': 'jianshu',
'charset': 'utf8',
'cursorclass': cursors.DictCursor
}
self.dbpool = adbapi.ConnectionPool('pymysql', **dbparams)
self._sql = None
@property
def sql(self):
if not self._sql:
self._sql = """
insert into article(id, title, content, author, avatar, pub_time, origin_url, article_id) values(null, {%s}, {%s}, {%s}, {%s}, {%s}, {%s}, {%s})
"""
return self._sql
return self._sql
def process_item(self, item, spider):
defer = self.dbpool.runInteraction(self.insert_item, item)
defer.addErrback(self.handle_error, item, spider)
def insert_item(self, cursor, item):
cursor.execute(self.sql, (item['title'], item['content'], item['author'], item['avatar'], item['pub_time'],
item['origin_url'], item['article_id']))
def handle_error(self, error, item, spider):
print('=' * 10 + "error" + '=' * 10)
print(error)
print('=' * 10 + "error" + '=' * 10)爬取ajax数据
集成的selenium和chromedriver都放在middlewares.py里。其实是重写中间件。
middlewares.py
from selenium.webdriver import ChromiumEdge
from selenium.webdriver.common.by import By
import time
from scrapy.http.response.html import HtmlResponse
class SeleniumDownloadMiddleware(object):
def __init__(self):
self.driver = ChromiumEdge(executable_path="D:\Anaconda\msedgedriver.exe")
def process_request(self, request, spider):
self.driver.get(request.url)
time.sleep(2)
try:
while True:
showMore = self.driver.find_element(by=By.CLASS_NAME, value='show-more')
showMore.click()
time.sleep(0.3)
if not showMore:
break
except:
pass
source = self.driver.page_source
response = HtmlResponse(url=self.driver.current_url, body=source, request=request, encoding='utf-8')
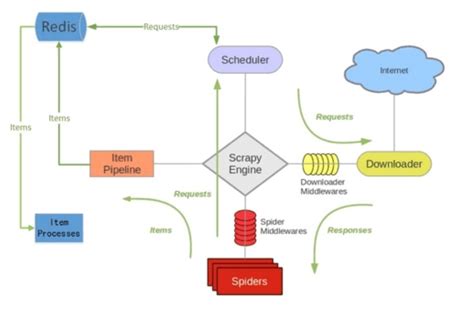
return response11. Scrapy-Redis分布式爬虫
并没有很多公司用,用的话这个公司做爬虫做的会很大了。
scrapy是一种支持分布式的nosql数据库。同时redis可以定时把内存数据同步到磁盘。
优点:
- 可以充分利用多台机器的带宽。
- 可以充分利用多台机器的ip地址。
- 多台机器做,爬取效率更高。
必须要解决的问题
- 分布式爬虫是好几台机器同时运行,如何保证不同的机器爬取的页面不重复。
- 如何把不同机器上爬取的数据保存在同一个地方。
redis可以解决多台机器共享数据。
pip install scrpy-redis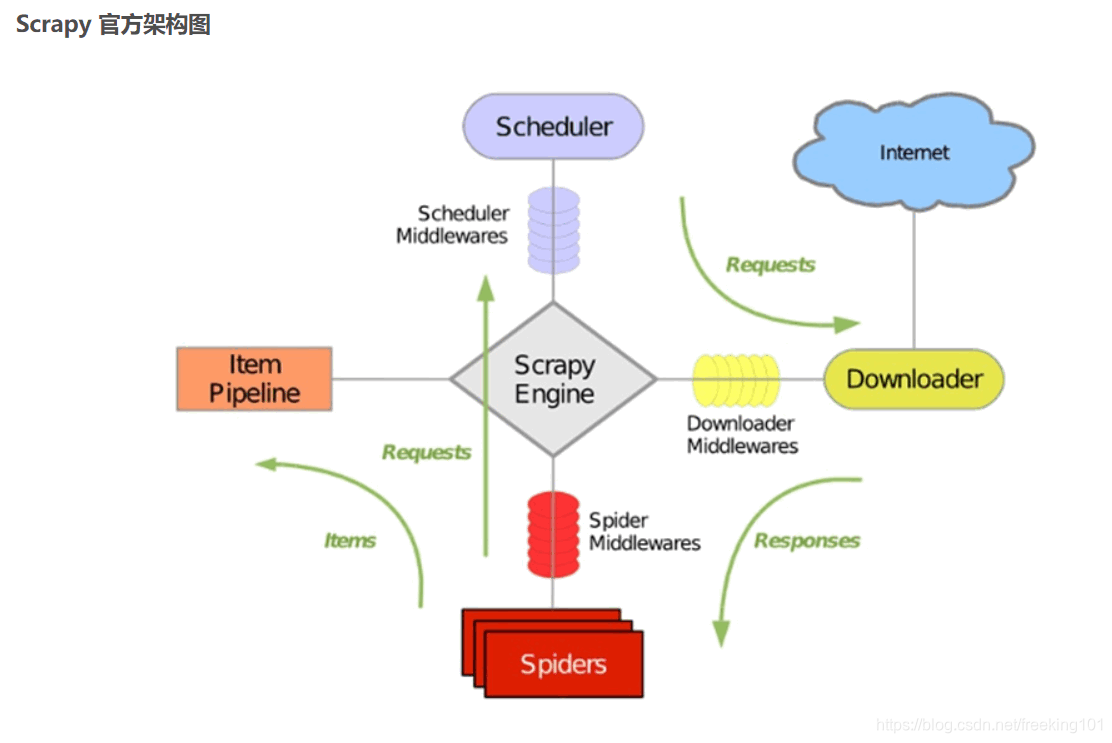
使用场景
- 登录会话存储:存储在redis 中,与memcached相比,数据不会丢失。
- 排行版/计数器:比如一些秀场类的项目,经常会有一些前多少名的主播排名。还有一些文章阅读量的技术,或者新浪微博的点赞数等。
- 作为消息队列:比如celery就是使用redis作为中间人.
- 当前在线人数:还是之前的秀场例子,会显示当前系统有多少在线人数。
- 一些常用的数据缓存:比如我们的bbs论坛,板块不会经常变化的,但是每次访问首页都要从mysql中获取,可以在redis中缓存起来,不用每次请求数据库。
- 把前200篇文章缓存或者译论缓存:一段用户浏览网站,只会浏览前面一部分文章或者评论,那么可以把前面200篇文章和对应的评论缓存起来。用户访问超过的,就访问数据库,并且以后文章超过200篇,则把之前的文章删除。
- 好友关系:微博的好友关系使用redis实现。
- 发布和订阅功能:可以用来像聊天软件。
sp.29


















 3150
3150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









