




摘要: 在移动互联网与数字媒体的高速发展下,每天都有海量的图片数据产生。如何对这些非结构化数据进行高效的自动化管理、分类与标签化,成为内容平台(如社交网络、电商、相册云服务)面临的典型落地挑战。本文将分享 CANN 在“智能内容处理”场景的落地实践,以业界标准的 ResNet-50 图像分类模型为例,实战演练如何利用 CANN 的异构计算能力,构建一个高吞吐、低延时的智能图片标签系统。我们将重点展示 CANN 在处理高并发推理任务时,如何通过软硬协同机制释放硬件潜能,解决传统 CPU 方案的算力瓶颈。
一、 场景背景:互联网内容的“算力焦虑”
在典型的互联网内容平台落地场景中,业务面临着巨大的流量压力:
-
海量并发:每秒钟可能有成千上万张用户图片上传,系统必须在秒级完成分析。
-
成本敏感:如果使用通用 CPU 进行深度学习推理,服务器集群的规模和电费将是不可承受之重。
CANN (Compute Architecture for Neural Networks) 的核心价值在于其专为矩阵计算设计的架构。在图片标签生成任务中,核心的卷积神经网络(CNN)计算占据了 99% 的负载。通过 ACL (Ascend Computing Language) 接口,我们可以将这些繁重的计算任务完整“卸载”到 NPU 的 AI Core 上执行。
相比于 CPU,NPU 就像是一个专精于数学计算的“特种部队”,能够以极高的能效比完成分类任务,从而大幅降低业务的 TCO(总体拥有成本)。
本次实操,我们将模拟一个“相册自动分类”的后端服务,使用 Python 调用 CANN 接口,完成对上传图片的智能识别与打标。
二、 环境配置与资源准备
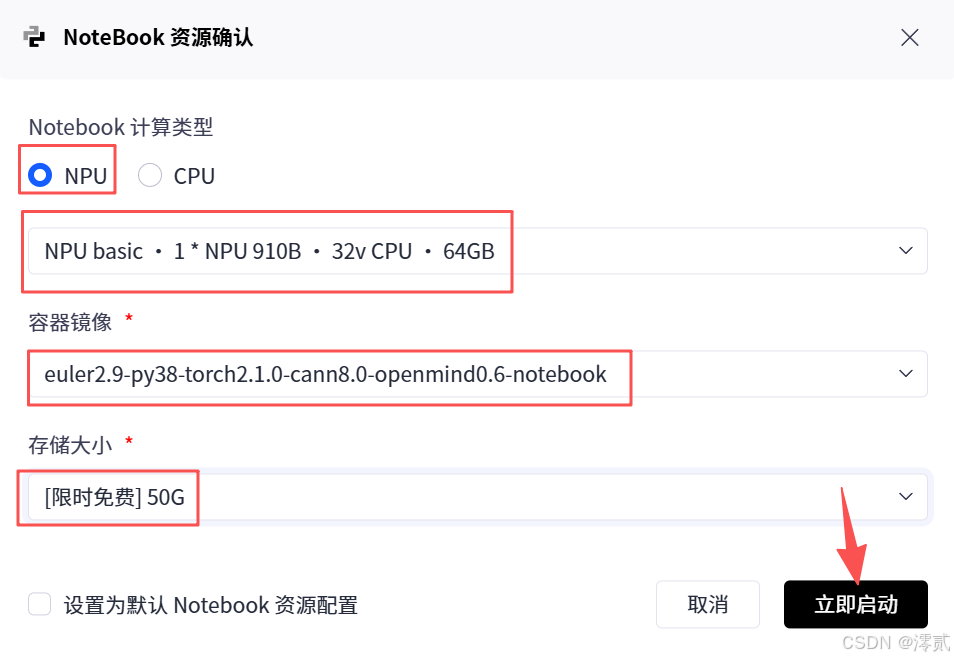
步骤 1:配置并启动 Notebook 环境
-
计算类型: NPU
-
容器镜像: 选择预装 CANN 的镜像(推荐
euler2.9-py38-torch2.1.0-cann8.0...) -
存储大小:
50G
启动 JupyterLab 后,我们开始搭建“智能标签系统”的原型。
步骤 2:打开终端 (Terminal) 准备引擎与数据
在 JupyterLab 顶部菜单栏点击 文件 -> 新建 -> 终端。
我们需要准备两样东西:
-
推理引擎:即编译好的 ResNet-50 离线模型(
.om)。 -
待处理数据:模拟用户上传的图片。
在终端中执行以下命令:
# 1. 回到主目录
cd ~
# 2. 创建系统目录结构
mkdir -p content_tagging_system/model
mkdir -p content_tagging_system/data
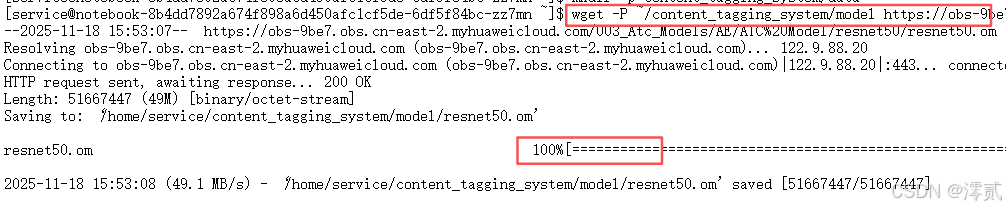
# 3. 下载 "推理引擎" (ResNet-50 模型)
# 该模型已针对 NPU 优化,并内置了 AIPP (图像预处理加速)
wget -P ~/content_tagging_system/model [https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/resnet50/resnet50.om](https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/resnet50/resnet50.om)
# 4. 下载 "用户上传图片" (模拟数据)
# 我们下载一张宠物的图片作为测试样例
wget -P ~/content_tagging_system/data [https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/yolov3/dog1_1024_683.jpg](https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/models/yolov3/dog1_1024_683.jpg)
技术点解析:我们下载的 resnet50.om 模型不仅包含了神经网络权重,还内置了 AIPP (AI Pre-Processing) 模块。在实际落地中,这意味着业务端可以直接传输 JPG 解码后的原始像素数据,无需在 CPU 上做复杂的归一化(Normalization)操作,进一步释放了 CPU 算力用于业务逻辑处理。
三、 核心实操:开发智能标签服务
回到 JupyterLab 左侧文件栏,进入 content_tagging_system 目录,新建一个 Notebook 文件 tagging_service.ipynb。
我们将使用 CANN 的 acl-python 库来实现这个服务。
(请务必依次运行以下单元格)
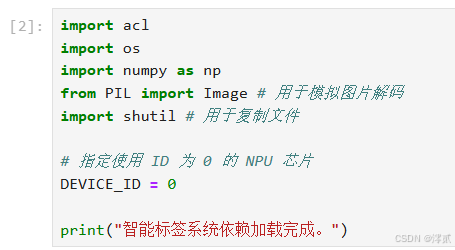
单元格 1:导入依赖与环境配置
我们引入必要的库,并配置 NPU 设备 ID。
import acl
import os
import numpy as np
from PIL import Image # 用于模拟图片解码
# 导入 ACL 常量配置 (新版 API 标准)
import acl.constants
# 指定使用 ID 为 0 的 NPU 芯片
DEVICE_ID = 0
print("智能标签系统依赖加载完成。")
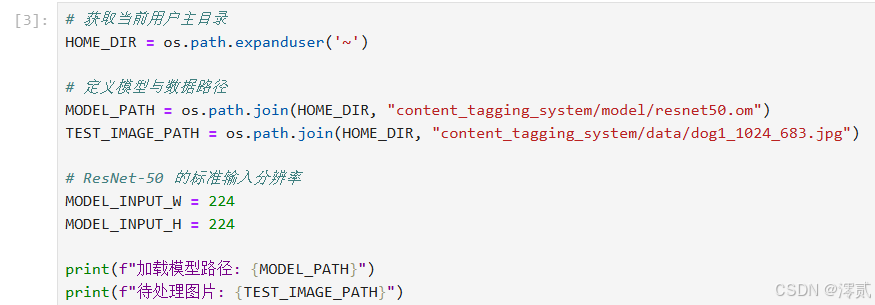
单元格 2:定义服务路径
指向我们刚才下载的资源。
# 获取当前用户主目录
HOME_DIR = os.path.expanduser('~')
# 定义模型与数据路径
MODEL_PATH = os.path.join(HOME_DIR, "content_tagging_system/model/resnet50.om")
TEST_IMAGE_PATH = os.path.join(HOME_DIR, "content_tagging_system/data/dog1_1024_683.jpg")
# ResNet-50 的标准输入分辨率
MODEL_INPUT_W = 224
MODEL_INPUT_H = 224
print(f"加载模型路径: {MODEL_PATH}")
print(f"待处理图片: {TEST_IMAGE_PATH}")
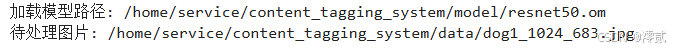
单元格 3:启动 NPU 推理运行时 (Runtime)
在处理任何业务请求前,我们需要先初始化 CANN 的运行时环境(Runtime),这相当于启动了我们的“AI 加速引擎”。
# --- 启动推理引擎 ---
print("正在启动 NPU 推理运行时...")
# 1. 系统级初始化
ret = acl.init()
if ret != acl.constants.ACL_SUCCESS:
print("ACL 初始化失败")
# 2. 激活指定 NPU 芯片
ret = acl.rt.set_device(DEVICE_ID)
if ret != acl.constants.ACL_SUCCESS:
print("NPU 设备激活失败")
# 3. 创建上下文 (Context)
# Context 是一个能够容纳 Stream、内存、事件的容器,用于隔离不同的推理任务
context, ret = acl.rt.create_context(DEVICE_ID)
print("NPU 运行时启动成功,随时待命。")


单元格 4:加载智能标签模型
将 ResNet-50 模型加载到 NPU 的高带宽内存中,准备处理请求。
# --- 加载业务模型 ---
print(f"正在加载智能标签模型...")
# 加载离线模型
model_id, ret = acl.mdl.load_from_file(MODEL_PATH)
if ret != acl.constants.ACL_SUCCESS:
print("模型加载失败")
# 获取模型元数据 (用于自动适配内存大小)
model_desc = acl.mdl.create_desc()
ret = acl.mdl.get_desc(model_desc, model_id)
print("智能标签模型加载完毕。")


单元格 5:处理用户请求 (图片预处理与内存调度)
这是落地场景中的关键环节。我们需要将用户上传的图片(Pillow读取)传输到 NPU 的专用内存中。
# --- 处理用户请求 ---
# 1. [模拟业务端] 读取用户上传的图片
# 实际场景中,这里可能是从 HTTP 请求或对象存储中读取
img_raw = Image.open(TEST_IMAGE_PATH)
# 缩放至模型所需尺寸 (224x224)
img_resized = img_raw.resize((MODEL_INPUT_W, MODEL_INPUT_H))
# 转为二进制流
input_bytes = img_resized.tobytes()
input_np = np.frombuffer(input_bytes, dtype=np.uint8)
# 2. [CANN 调度] 申请 NPU 侧输入内存
# 查询模型输入所需的 buffer 大小
input_size = acl.mdl.get_input_size_by_index(model_desc, 0)
# 申请 Device 内存 (ACL_MEM_MALLOC_HUGE_FIRST 策略可提升性能)
input_dev, ret = acl.rt.malloc(input_size, acl.constants.ACL_MEM_MALLOC_HUGE_FIRST)
# 3. [数据搬运] Host -> Device
# 将图片数据从 CPU 内存拷贝到 NPU 内存
if input_np.size > 0:
# 注意:这里为了演示简单,假设数据是对齐的。
# 生产环境中,CANN 的 dvpp 接口可以处理更复杂的对齐和格式转换
ptr = acl.util.numpy_to_ptr(input_np)
ret = acl.rt.memcpy(input_dev, input_size, ptr, input_size, acl.constants.ACL_MEMCPY_HOST_TO_DEVICE)
# 4. 构建推理数据集结构
input_dataset = acl.mdl.create_dataset()
input_buffer = acl.mdl.create_data_buffer(input_dev, input_size)
acl.mdl.add_dataset_buffer(input_dataset, input_buffer)
print("用户图片已加载至 NPU,准备推理。")

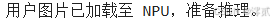
单元格 6:执行智能打标 (Inference)
NPU 全速运转,计算图片的特征向量并输出分类概率。
# --- 准备输出容器 ---
output_dataset = acl.mdl.create_dataset()
output_size = acl.mdl.get_output_size_by_index(model_desc, 0)
output_dev, ret = acl.rt.malloc(output_size, acl.constants.ACL_MEM_MALLOC_HUGE_FIRST)
output_buffer = acl.mdl.create_data_buffer(output_dev, output_size)
acl.mdl.add_dataset_buffer(output_dataset, output_buffer)
# --- 执行推理 ---
print("正在进行智能识别...")
# 这一步是真正的硬件加速计算
ret = acl.mdl.execute(model_id, input_dataset, output_dataset)
print("推理完成!")


单元格 7:解析结果与生成标签
将 NPU 的计算结果取回,解析出置信度最高的标签。
# --- 解析结果 ---
# 1. [数据搬运] Device -> Host
output_host, ret = acl.rt.malloc_host(output_size)
ret = acl.rt.memcpy(output_host, output_size, output_dev, output_size, acl.constants.ACL_MEMCPY_DEVICE_TO_HOST)
# 2. 转为 Numpy 数组进行后处理
# ResNet-50 输出 1000 个分类的概率
result_np = acl.util.ptr_to_numpy(output_host, (1000, ), 1) # 1 = float32
# 3. 获取 Top 1 标签索引
top_label_index = result_np.argmax()
confidence = result_np[top_label_index]
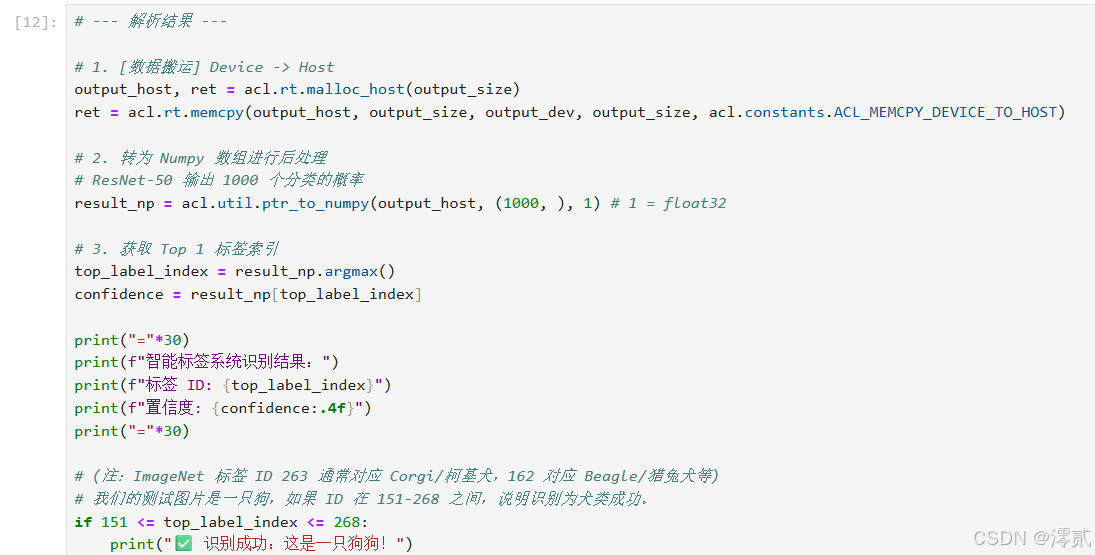
print("="*30)
print(f"智能标签系统识别结果:")
print(f"标签 ID: {top_label_index}")
print(f"置信度: {confidence:.4f}")
print("="*30)
# (注:ImageNet 标签 ID 263 通常对应 Corgi/柯基犬,162 对应 Beagle/猎兔犬等)
# 我们的测试图片是一只狗,如果 ID 在 151-268 之间,说明识别为犬类成功。
if 151 <= top_label_index <= 268:
print("✅ 识别成功:这是一只狗狗!")

单元格 8:资源释放
# --- 释放资源 ---
# 释放内存
acl.rt.free(input_dev)
acl.rt.free(output_dev)
acl.rt.free_host(output_host)
# 销毁描述符
acl.mdl.destroy_dataset(input_dataset)
acl.mdl.destroy_dataset(output_dataset)
acl.mdl.unload(model_id)
acl.mdl.destroy_desc(model_desc)
# 释放运行时
acl.rt.destroy_context(context)
acl.rt.reset_device(DEVICE_ID)
acl.finalize()
print("系统资源已回收。")


四、 总结
通过构建这个“海量图片智能标签系统”的原型,我们直观地体验了 CANN 架构在处理高并发内容识别任务时的优势:
-
高效的内存管理:通过
acl.rt.malloc和acl.rt.memcpy,我们实现了 Host(业务层)与 Device(计算层)之间的高效数据流转。 -
极简的推理接口:仅需几行代码
acl.mdl.execute,即可调度强大的 NPU 算力,无需关心底层复杂的硬件指令。 -
落地价值:在真实的互联网业务中,这种架构意味着可以用更少的服务器处理更多的用户请求,显著提升了服务的响应速度和经济效益。
CANN 不仅是一个开发框架,更是连接上层互联网应用与底层硬件算力的坚实桥梁。



















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









