




你可能会想 Python (用 Scrapy、BeautifulSoup) 才是爬虫之王。没错,Python 的生态非常成熟,写起来很快,但 Rust 爬虫是另一个维度的猛兽:它拥有并发性能的天花板🚀、绝对的稳定性🛡️、极高的执行效率⚡
本项目将爬取一个专门用来练习爬虫的网站:Books to Scrape (一个模拟书店),并发抓取前 5 页的所有书名和价格
一、初始化项目引入外部库
要实现一个异步任务,我们得先有零件。在 Rust 里,这些零件就是 Crates(库):
使用 vscode 打开终端:
cargo new rusty-spider
cd rusty-spider

创建一个名为 rusty-spider 的项目,进入该目录
[package]
name = "rusty-spider"
version = "0.1.0"
edition = "2021"
[dependencies]
tokio = { version = "1", features = ["full"] }
reqwest = "0.12.24"
scraper = "0.24.0"
futures = "0.3"
anyhow = "1.0"
colored = "3.0.0"
[package] 模块包含基本的项目信息,[dependencies] 模块包含需要的项目依赖项,最为重要
tokio🚀
提供网络、多线程、定时器等异步能力。full 特性包含所有子功能,适合爬虫场景的高并发需求
reqwest🌐
HTTP 客户端(“下载器”),用于发送网络请求,下载目标网页的 HTML 内容
scraper🛠️
HTML 解析器(“解码器”),通过 CSS 选择器从 HTML 中提取目标数据(如书名、价格),它能让我们用 CSS 选择器从 HTML 中精准地提取我们想要的数据
- **
futures📦
提供 join_all 等工具,用于管理和组合多个异步任务。futures 库就提供了这样的工具,它能帮我们等待所有异步任务都完成任务后再报告
anyhow/colored🖌️
错误处理库和彩色终端输出库,简化不同错误类型的统一管理,让错误处理代码更简洁,还有用于美化日志和结果输出(如将书名标蓝、价格标绿)
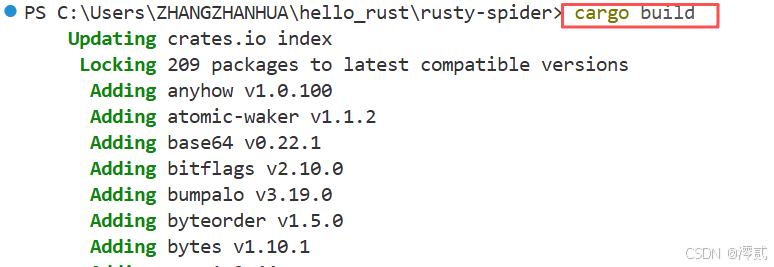

🔥值得注意的是: 引入外部库后,记得运行一次 cargo build,Rust 的包管理器 cargo 就会自动帮我们把这些零件全部下载并编译好。最后显示 Finished release profile [optimized] target(s) in 31.08s说明下载成功
二、核心抓取函数编写
在 src/main.rs 里,我们先不考虑创建多少个异步任务,而是先编写一个异步任务负责爬取单个页面的核心逻辑,通过代码定义它的行为规则
明确其目标抓取网页,学会如何怎么下载网页内容,从混乱的 HTML 中精准定位目标数据(如书名、价格)
use anyhow::Result;
use colored::*;
use futures::future::join_all;
use reqwest;
use scraper::{Html, Selector};
#[derive(Debug)]
struct Book {
title: String,
price: String,
}
async fn scrape_page(url: &str) -> Result<Vec<Book>> {
let html_content = reqwest::get(url).await?.text().await?;
let document = Html::parse_document(&html_content);
let book_selector = Selector::parse("article.product_pod").unwrap();
let title_selector = Selector::parse("h3 > a").unwrap();
let price_selector = Selector::parse("p.price_color").unwrap();
let mut books = Vec::new();
for element in document.select(&book_selector) {
let title = element
.select(&title_selector)
.next()
.and_then(|a| a.attr("title"))
.map_or("N/A".to_string(), |s| s.to_string());
let price = element
.select(&price_selector)
.next()
.map_or("N/A".to_string(), |p| p.inner_html().to_string());
books.push(Book { title, price });
}
Ok(books)
}
scrape_page抓取函数流程分为 4 步:
- 下载网页内容

reqwest::get(url).await表示发送HTTP GET请求,异步等待响应获取响应头.text().await表示将响应体转换为字符串(获取网页HTML内容)?操作符表示若请求或转换失败,直接返回错误;成功则继续执行
- 解析 HTML 文档
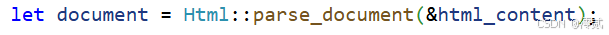
将 HTML 字符串解析为 Html 结构体,便于后续通过选择器提取数据
- 定义 CSS 选择器(定位目标数据)

基于目标网页 http://books.toscrape.com,先用 book_selector 找到所有书籍的根容器 article.product_pod,得到一个书籍列表,对每个书籍容器,用 title_selector 找到书名所在的 <a> 标签,提取 title 属性值作为书名。同样在每个书籍容器中,用 price_selector 找到价格所在的 <p> 标签,提取其文本内容作为价格
- 提取数据并封装

遍历所有书籍容器 document.select(&book_selector),逐个提取数据:
- 书名: 通过
title_selector定位a标签,获取其title属性;若提取失败(如标签不存在),默认值为N/A - 价格: 通过
price_selector定位p标签,获取其内部文本;失败时默认值为N/A,将提取的书名和价格封装为Book结构体,存入Vec<Book>并返回。
三、并发执行主函数编写
现在我们的异步任务有了核心的实现逻辑 (scrape_page 函数),我们如何让多个异步任务同时去爬多个个不同的页面呢?
#[tokio::main]
async fn main() -> Result<()> {
println!("{}", "锈蜘蛛军团 🕷️ 启动!...".yellow().bold());
let base_url = "http://books.toscrape.com/catalogue/page-";
let max_pages = 5;
let mut tasks = Vec::new();
for i in 1..=max_pages {
let url = format!("{}{}.html", base_url, i);
let task = tokio::spawn(async move {
println!("{} 正在爬取: {}", "🕷️".cyan(), url);
match scrape_page(&url).await {
Ok(books) => {
println!("{} 成功爬取 {} 页: 找到 {} 本书", "✅".green(), i, books.len());
Some(books)
}
Err(e) => {
eprintln!("{} 爬取 {} 页失败: {}", "❌".red(), i, e);
None
}
}
});
tasks.push(task);
}
let all_results = join_all(tasks).await;
println!("\n{}", "--- 战果汇总 ---".magenta().bold());
let mut total_books = 0;
for result in all_results {
match result {
Ok(Some(books)) => {
total_books += books.len();
for book in books.iter().take(2) {
println!(
" 📚 {} - {}",
book.title.blue(),
book.price.green()
);
}
println!(" ...");
}
Ok(None) => {
println!(" (某个页面爬取失败,已在上面报告)");
}
Err(e) => {
eprintln!("{} 一个任务执行失败(panic): {}", "💥".red(), e);
}
}
}
println!("\n{} 报告将军!“蜘蛛军团”已完成任务!", "🎉".bold());
println!("{} {} 个页面,共抓取 {} 本书。", "📊".bold(), max_pages, total_books);
Ok(())
}
#[tokio::main] 是 Tokio 异步运行时提供的一个宏,用于简化异步程序的启动。它的作用是自动生成异步运行时的初始化代码,将标记的 main 函数转换为异步入口点。使用这个宏后,无需手动创建和管理 Tokio 运行时,就能直接在 main 函数中使用 async/await 语法编写异步逻辑
main主函数流程分为 4 步:
-
初始化配置

定义目标网页的网址URL和爬取的总页数,这里我们爬取5页 -
创建并发任务

循环生成 5 个 URL(page-1.html 到 page-5.html),tokio::spawn(async move { ... }) 函数用于创建异步任务,每个任务负责爬取一个页面,任务立即后台执行,不阻塞主线程,任务结果通过 JoinHandle 类型存入 tasks 向量,用于后续汇总
- 等待所有任务完成

join_all 等待所有异步任务执行完毕,返回包含每个任务结果的向量 all_results
- 汇总与输出结果

遍历所有任务结果,统计总书籍数量,并打印每页前 2 本书的信息(用 colored 着色),最终输出汇总结果(总页数、总书籍数)
四、运行爬虫程序
在你的终端里运行以下代码:
cargo run --release
--release 模式非常重要,不加 --release 会很慢,加了会快到飞起
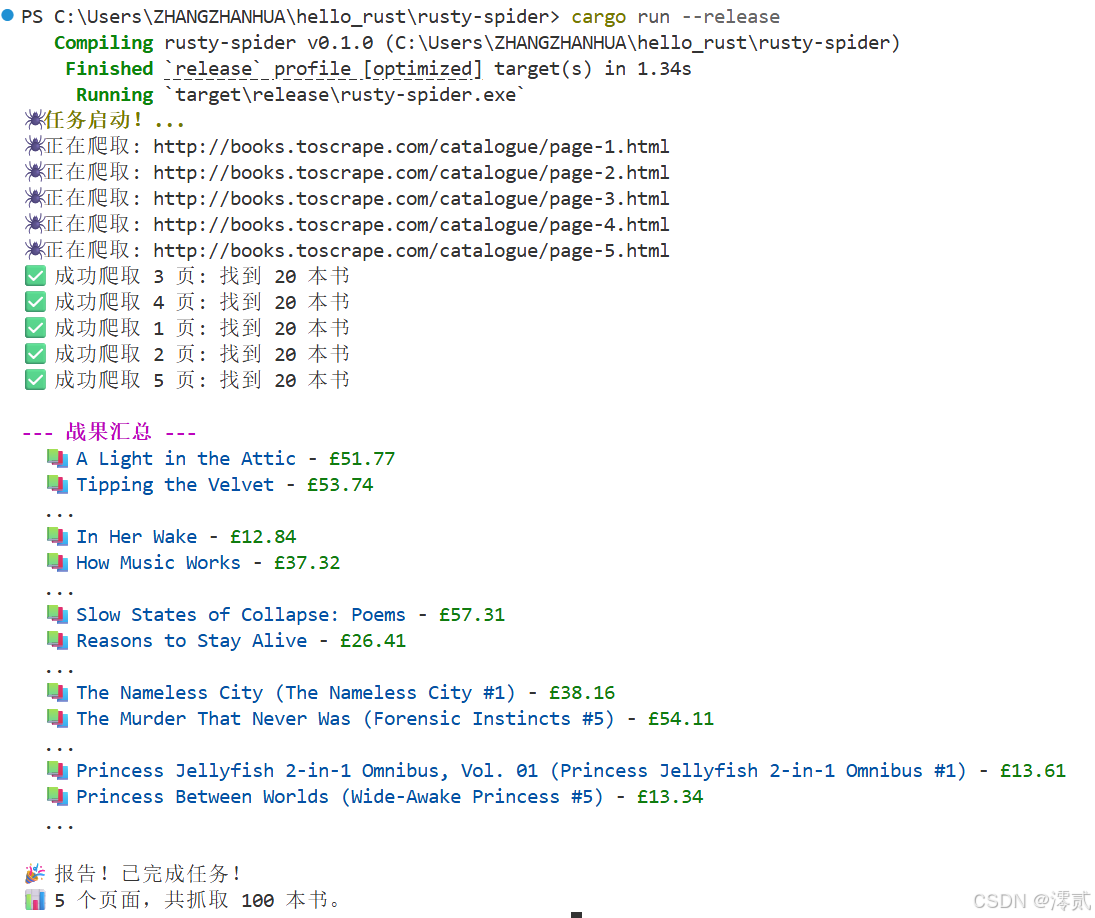
可以看到确实爬取下来了 5 页的内容
五、总结
rust 的高性能也能使用于爬虫,不一定是只有 python
🔥值得注意的是:
-
爬取前先检查网站的
robots.txt文件,看它允许你爬哪些 -
控制频率,不要太快
// 在 scrape_page 的开头或结尾加上 tokio::time::sleep(std::time::Duration::from_millis(500)).await; // 暂停 500 毫秒
我们的程序太快了,可能会把别人的小网站“爬死”。在你的任务 task 里加个礼貌性的延迟,是专业爬虫的必备素养
对于该项目,你还能尝试把这些抓取到的数据(Vec<Book>)存到数据库,下去自己尝试一下吧!😁



















 1282
1282




 到【灌水乐园】发言
到【灌水乐园】发言







