




文章目录
如果你有 C++ 基础,学 Rust 就像从 C++ 的"手动挡"换到 Rust 的"自动挡"——安全性自动化了,但你仍然拥有强大的控制力!💪
一、📌 项目背景:我们要做什么?
想象一个场景:你的公司有一份销售数据的 CSV 文件,包含了客户名称、购买金额、购买日期等信息。老板要求你统计一下每个月的销售总额、平均客单价,还要找出最大的订单
在 C++ 中,你可能需要:
- 手动打开文件
- 手动解析
CSV格式 - 管理动态数组或容器
- 自己处理所有错误情况
而在 Rust 中,我们会用更优雅、更安全的方式完成这一切!✨
二、🎯 项目思路解释
我们的项目分为 4 个核心步骤:
1. 读取文件 → 2. 解析数据 → 3. 数据处理 → 4. 输出统计
具体来说,就是打开 CSV 文件,读取其中的每一行,把每一行文本解析成结构化的数据(类似 C++ 中的结构体),对数据进行分类、求和、平均等操作,以美观的方式输出结果
三、💻 开始编码
第一步:项目初始化和依赖配置
首先,打开 vscode 终端创建一个新的 Rust 项目:
cargo new sales_analyzer
cd sales_analyzer

打开 Cargo.toml 文件,添加我们需要的依赖:
[package]
name = "sales_analyzer"
version = "0.1.0"
edition = "2021"
[dependencies]
csv = "1.3" # CSV 处理库,专门用来读写 CSV 文件
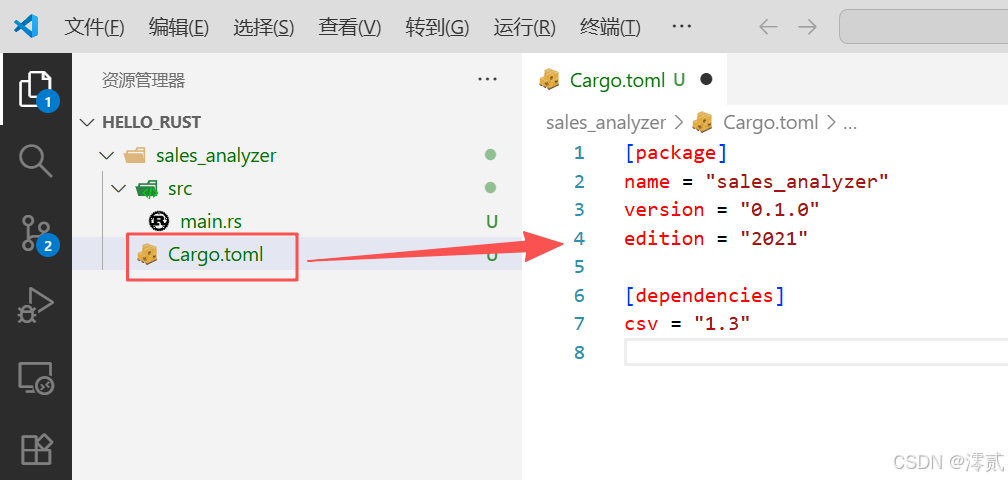
该文件分为 [package] 和 [dependencies] 两个核心配置模块,分别定义项目基础信息和依赖库
- [package] 模块:项目基础配置
name:项目名称,值为sales_analyzer,决定了编译后可执行文件的默认名称version:项目版本edition:指定Rust版本,值为2021,意味着项目将使用Rust 2021版本的语法和特性,2021版是目前主流且稳定的版本
- [dependencies] 模块:项目依赖配置
csv:用于读取、写入和处理CSV格式文件的Rust库,1.3表示兼容1.3.x系列的最新版本,会自动拉取该范围内的最新稳定版
🔥值得注意的是:在
Rust中,依赖管理通过Cargo.toml文件完成,类似于C++中的CMake,但更简洁!
第二步:定义数据结构
打开 src/main.rs,首先定义一个结构体来表示销售记录:
// 这个结构体用来存储单条销售记录
// 类似于 C++ 中的 struct,但有更多的特性
#[derive(Debug, Clone)] // 自动生成调试打印和克隆功能
struct SalesRecord {
customer_name: String, // 客户名称
purchase_amount: f64, // 购买金额(浮点数)
purchase_date: String, // 购买日期,格式为 "2024-11-01"
}
// 这个结构体用来存储统计结果
#[derive(Debug)]
struct MonthlySales {
month: String, // 月份,格式为 "2024-11"
total_amount: f64, // 该月总销售额
transaction_count: usize, // 该月交易笔数
average_order_value: f64, // 该月平均客单价
max_order: f64, // 该月最大订单金额
}
为什么是这样? 🤔
在 Rust 中,
#[derive(Debug, Clone)]是一个"属性宏"(类似编译指令),这叫特征派生
为 SalesRecord 派生的 Debug 和 Clone 特性,是 Rust 中高效开发的常见做法,且选择贴合场景
-
#[derive(Debug)]: 自动生成调试打印逻辑,无需手动实现,后续可通过
println!("{:?}", record)快速打印结构体内容,方便开发阶段调试数据 -
#[derive(Clone)]: 自动生成克隆方法,允许通过
record.clone()复制SalesRecord实例。由于SalesRecord包含String(所有权类型),克隆能避免所有权转移导致的 “使用已移动值” 错误,尤其适合在处理多条记录(如批量统计)时复用数据 -
未多余派生: 未为
MonthlySales派生Clone,因统计结果通常是一次性的,复用场景少,避免不必要的性能开销
第三步:核心数据处理函数
现在编写真正的数据处理逻辑。这是项目的心脏部分:
use std::collections::HashMap;
// 这个函数用来读取 CSV 文件并解析所有数据
// 参数:文件路径
// 返回:一个向量,包含所有的销售记录
fn load_sales_data(file_path: &str) -> Result<Vec<SalesRecord>, Box<dyn std::error::Error>> {
let mut records = Vec::new(); // 创建一个动态数组,类似 C++ 的 vector
// 打开 CSV 文件
// Result<> 是 Rust 的错误处理方式,类似 C++ 的异常,但更优雅
let file = std::fs::File::open(file_path)?;
// 使用 csv 库创建一个 reader
// `?` 操作符是 Rust 的"糖":如果出错就直接返回,如果成功就继续
let mut reader = csv::Reader::from_reader(file);
// 遍历 CSV 中的每一行(跳过表头)
for result in reader.records() {
// 处理可能的读取错误
let record = result?;
// 从当前行提取三个字段
// get() 方法返回 Option,需要用 ok_or() 转换为 Result
let customer_name = record.get(0).ok_or("缺少客户名称")?;
let amount_str = record.get(1).ok_or("缺少购买金额")?;
let date = record.get(2).ok_or("缺少购买日期")?;
// 将金额字符串转换为浮点数
// parse() 返回 Result,用 ? 处理错误
let amount: f64 = amount_str.parse()?;
// 创建新的 SalesRecord 并添加到向量中
records.push(SalesRecord {
customer_name: customer_name.to_string(), // to_string() 是类似 C++ 的隐式转换
purchase_amount: amount,
purchase_date: date.to_string(),
});
}
Ok(records) // 返回成功结果和数据
}
// 这个函数用来计算按月份统计的销售数据
// 参数:销售记录列表
// 返回:按月份统计的结果
fn calculate_monthly_stats(records: Vec<SalesRecord>) -> HashMap<String, MonthlySales> {
// HashMap 类似 C++ 的 map,用于快速查找
let mut monthly_stats: HashMap<String, MonthlySales> = HashMap::new();
// 遍历每一条销售记录
for record in records {
// 从日期字符串中提取月份
// 例如从 "2024-11-15" 提取 "2024-11"
let month = &record.purchase_date[0..7];
// 获取或创建该月份的统计数据
// entry() 返回一个"入口",allow_entry() 获取或创建
let entry = monthly_stats
.entry(month.to_string())
.or_insert(MonthlySales {
month: month.to_string(),
total_amount: 0.0,
transaction_count: 0,
average_order_value: 0.0,
max_order: 0.0,
});
// 更新该月份的统计数据
entry.total_amount += record.purchase_amount; // 累加总额
entry.transaction_count += 1; // 交易数加一
// 更新最大订单
// max() 是标准库的比较函数
entry.max_order = entry.max_order.max(record.purchase_amount);
}
// 计算平均值
for stats in monthly_stats.values_mut() { // values_mut() 获取可变引用
if stats.transaction_count > 0 {
// 平均值 = 总额 / 交易数
stats.average_order_value = stats.total_amount / stats.transaction_count as f64;
}
}
monthly_stats
}
这两段 Rust 代码实现了销售数据的加载与月度统计功能
load_sales_data:CSV 数据解析
核心逻辑:
 打开
打开 CSV 文件

逐行读取 → 解析字段 → 转换为 SalesRecord 结构体 → 收集为向量返回
- 细节处理:
- 用
csv库处理CSV格式,避免手动解析逗号分隔符的繁琐 - 严格的错误检查:文件打开失败、行读取失败、字段缺失(如
get(0).ok_or(...))、金额格式错误(parse())均通过?操作符返回Result,确保异常情况不被忽略 - 类型转换明确:将 CSV 中的字符串字段(客户名、日期)转为
String,金额字符串转为f64,与SalesRecord结构体字段类型匹配
- 用
calculate_monthly_stats:月度统计计算
核心逻辑:

按月份分组

累加总额/交易数 → 记录最大订单
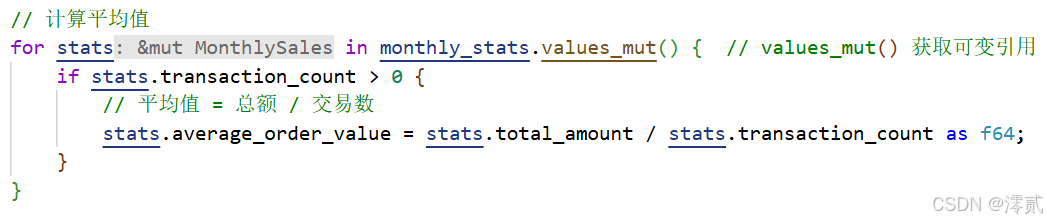
计算平均客单价
- 细节处理:
- 用
HashMap按月份(如“2024-11”)高效分组,entry.or_insert简化“存在则更新,不存在则创建”的逻辑 - 分两步计算:先累加基础数据(总额、笔数、最大订单),再统一计算平均客单价,避免重复判断(比每笔记录都计算平均值更高效)
- 类型安全:
transaction_count是usize,转换为f64时显式用as f64,符合 Rust 强类型要求
- 用
🔥值得注意的是: Rust 的相较 C++ 的设计亮点在于
-
错误处理优雅:
- 函数返回
Result类型,将所有可能的错误(IO 错误、CSV 解析错误、格式转换错误)统一包装为Box<dyn Error>,调用方可以通过?或match灵活处理,比 C++ 异常更显式、可控。 - 用
ok_or将Option(record.get(0)的返回值)转换为Result,统一错误处理链路,避免嵌套if let导致的代码臃肿。
- 函数返回
-
容器使用合理:
Vec<SalesRecord>存储所有记录,动态扩容适合不确定数据量的场景,与 CSV 行数动态变化匹配。HashMap<String, MonthlySales>按月份键值对分组,平均 O(1) 的插入/查询效率,适合按维度统计的需求,比数组(需提前知道所有月份)更灵活。
-
内存与所有权管理:
- 字符串处理:通过
to_string()复制 CSV 行中的字符串切片(&str),确保SalesRecord拥有字段的所有权(避免悬垂引用)。 - 可变引用:
values_mut()获取HashMap中值的可变引用,直接修改统计数据,避免不必要的克隆。
- 字符串处理:通过
Rust vs C++ 小对比:
- C++:
std::map<std::string, MonthlySales>需要手动处理并发问题- Rust:
HashMap编译时就确保了内存安全,不用担心数据竞争!🔒
第四步:主函数 - 把一切连接起来
fn main() {
println!("🎯 销售数据分析工具启动!");
println!("================================\n");
// 指定 CSV 文件路径
let file_path = "./src/sales_data.csv";
// 调用数据加载函数
// match 语句用来处理 Result 类型(成功或失败)
match load_sales_data(file_path) {
Ok(records) => {
println!("✅ 成功读取 {} 条销售记录!\n", records.len());
// 调用统计函数计算月度数据
let monthly_stats = calculate_monthly_stats(records);
// 按月份排序并输出结果
let mut months: Vec<_> = monthly_stats.keys().collect();
months.sort(); // 排序月份
println!("📊 按月份统计结果:");
println!("================================");
for month in months {
let stats = &monthly_stats[month];
// 输出格式化的统计结果
println!("📅 {}年{}月", &month[0..4], &month[5..7]);
println!(" 💰 总销售额: ¥{:.2}", stats.total_amount);
println!(" 📈 交易笔数: {}", stats.transaction_count);
println!(" 📊 平均客单价: ¥{:.2}", stats.average_order_value);
println!(" 🏆 最大订单: ¥{:.2}", stats.max_order);
println!("--------------------------------");
}
}
Err(e) => {
// 如果出错,打印错误信息
eprintln!("❌ 错误:{}", e);
}
}
}
四、📋 测试数据准备
在目录src下创建一个 sales_data.csv 文件:
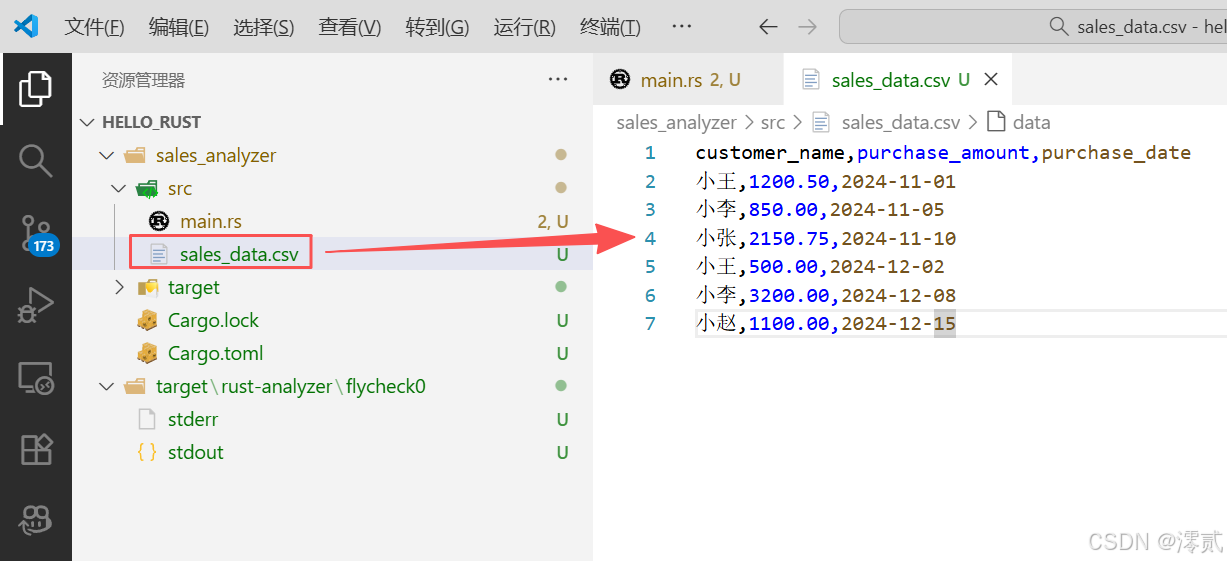
注意是和 main.rs 同级的文件
customer_name,purchase_amount,purchase_date
小王,1200.50,2024-11-01
小李,850.00,2024-11-05
小张,2150.75,2024-11-10
小王,500.00,2024-12-02
小李,3200.00,2024-12-08
小赵,1100.00,2024-12-15
五、🎬 运行程序
cargo run --release
cargo run 运行程序并以 release 版本发布,输出应该是这样的:
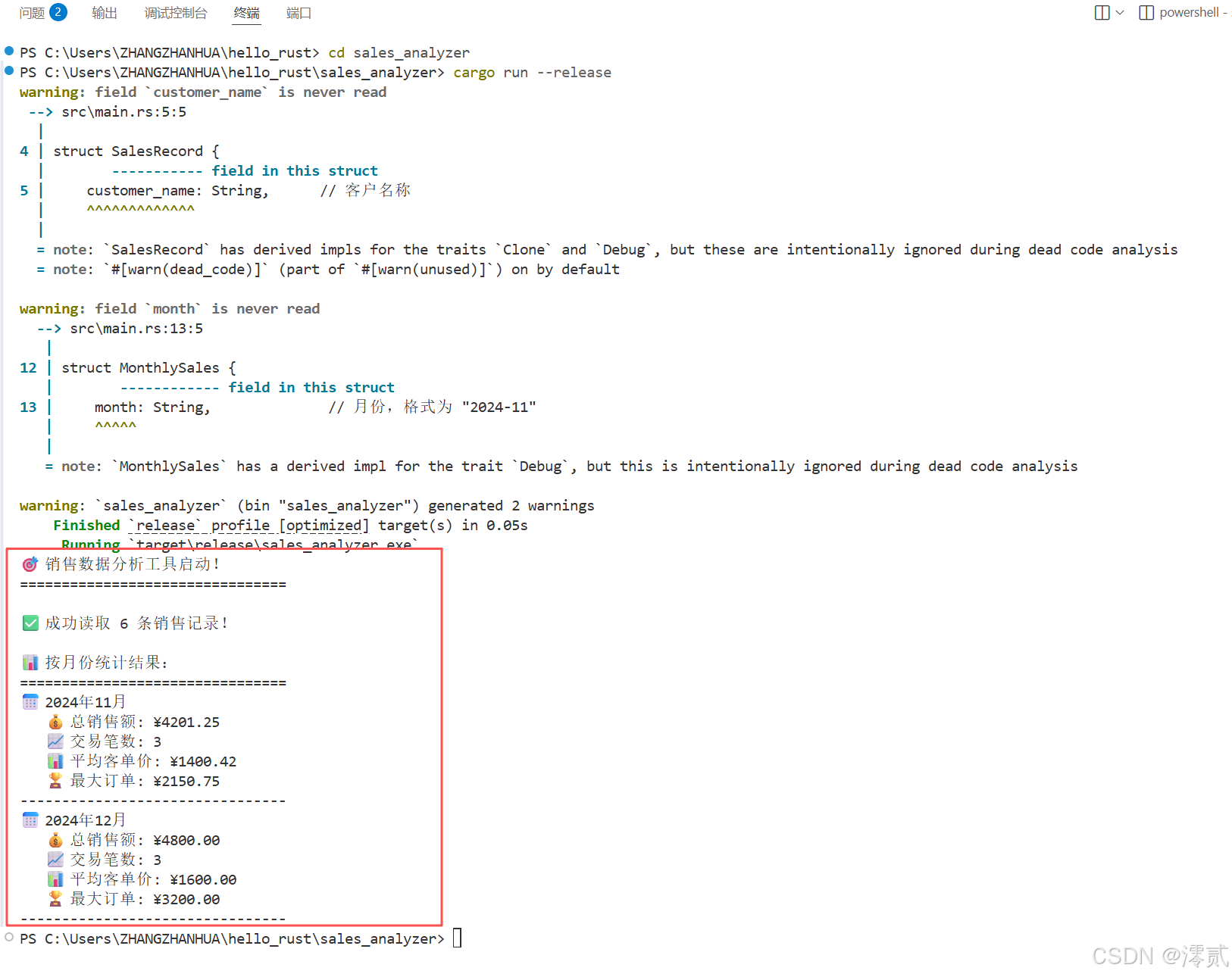
可以看到统计结果确实是和给出的数据一致,是不是很简单呢?
这个 warning 可以不用管,代码中的警告主要是因为 customer_name(在 SalesRecord 中)和 month(在 MonthlySales 中)字段被定义但未被使用,因为 Rust 符合零成本抽象和最小化冗余的设计理念
六、🎓 Rust vs C++
| 概念 | 说明 | C++ 类比 |
|---|---|---|
| 所有权 | 每个值只有一个所有者 | 智能指针 unique_ptr |
| 借用 | 通过 & 借用不转移所有权 | 引用 |
| Result | 显式错误处理 | try-catch |
| Match | 模式匹配 | switch-case 但更强大 |
| Vec | 动态数组 | std::vector |
七、✨ 总结与扩展
通过这个项目,你已经学到了:
- ✅ 文件 I/O 操作
- ✅ 数据结构设计
- ✅ 迭代和集合处理
- ✅ 错误处理
- ✅ Rust 的安全性哲学
后续可以扩展的方向:🚀
- 支持更多的数据格式(
JSON、Parquet) - 导出为可视化图表
- 添加数据过滤功能
- 使用并发处理大文件
Rust 虽然看起来严格,但这正是它的魔力所在——它让你写出既安全又高效的代码!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









