




文章目录
1.前言
随着物流的愈加发达,比如一家小型跨境电商想跟踪竞争对手的新品上架信息,却因没有技术团队只能手动复制粘贴,物流公司每天要查询上百个包裹的物流状态,人工核对效率极低,说明中小企业在数据获取上的共性难题 —— 缺技术、缺预算,但又急需数据驱动决策
推荐的解决方案: 亮数据平台的 Web Scraper API 快速搭建数据采集流程
零代码快速搭建,无需编程基础,普通人也能在 10 分钟内完成数据采集流程,帮助中小企业用低成本实现数据化运营
2.亮数据Web Scraper API强大的地方
- 不用自己瞎折腾写代码
你不用学那些复杂的编程,不用研究怎么扒网页数据,直接填个网址、选要啥信息(比如价格、评论),点一下就完事了。哪怕你啥技术不懂,跟着步骤点点鼠标也能搞定
- 网站再刁难也不怕
有些网站会封 IP、弹验证码、不让机器扒数据,这工具自带 “隐身术”—— 自动换 IP、帮你过验证码,你不用管这些乱七八糟的,只管等数据就行
- 快慢多少都能搞
想一次性扒 成千上万条数据(比如整个电商平台的商品),它能批量干;想实时看某个页面的最新信息(比如某商品现在多少钱),它也能马上给你结果
- 省时间省精力
自己搞可能研究好几天还弄不明白,用这个几小时就能拿到数据。不用雇技术大佬,不用买服务器维护,花点小钱省大事
总之,就是把 “扒网页数据” 这件麻烦事变得跟 “用外卖软件点饭” 一样简单 —— 你只管说要啥,剩下的它全帮你搞定,因此我还是十分推荐亮数据这个平台的
3.Web Scraper API - 快速入门图文教程
3.1 前提准备
3.1.1 注册账号
传送门:亮数据

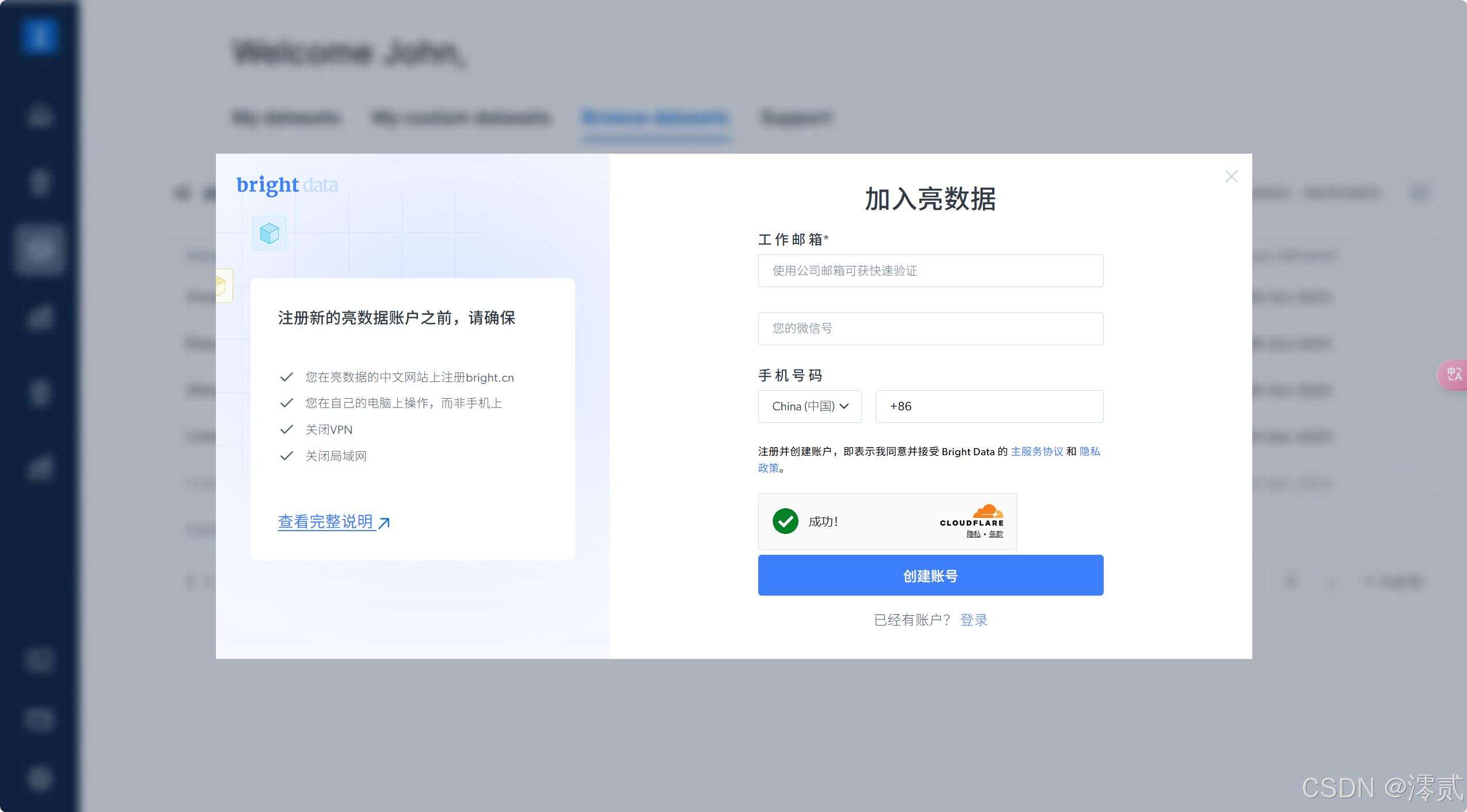
点开链接后,有个免费试用,点击他,自动弹出注册弹窗,填写信息注册一个 Bright Data 帐户(注册→ 2 分钟)
🔥注意: 亮数据平台对登录有要求限制
- 在亮数据的中文网站上注册
bright.cn - 在自己的电脑上操作,而非手机上
- 关闭
VPN - 关闭局域网
实在还无法解决的可以查看官方登录解决文档
3.1.2 获取API密钥
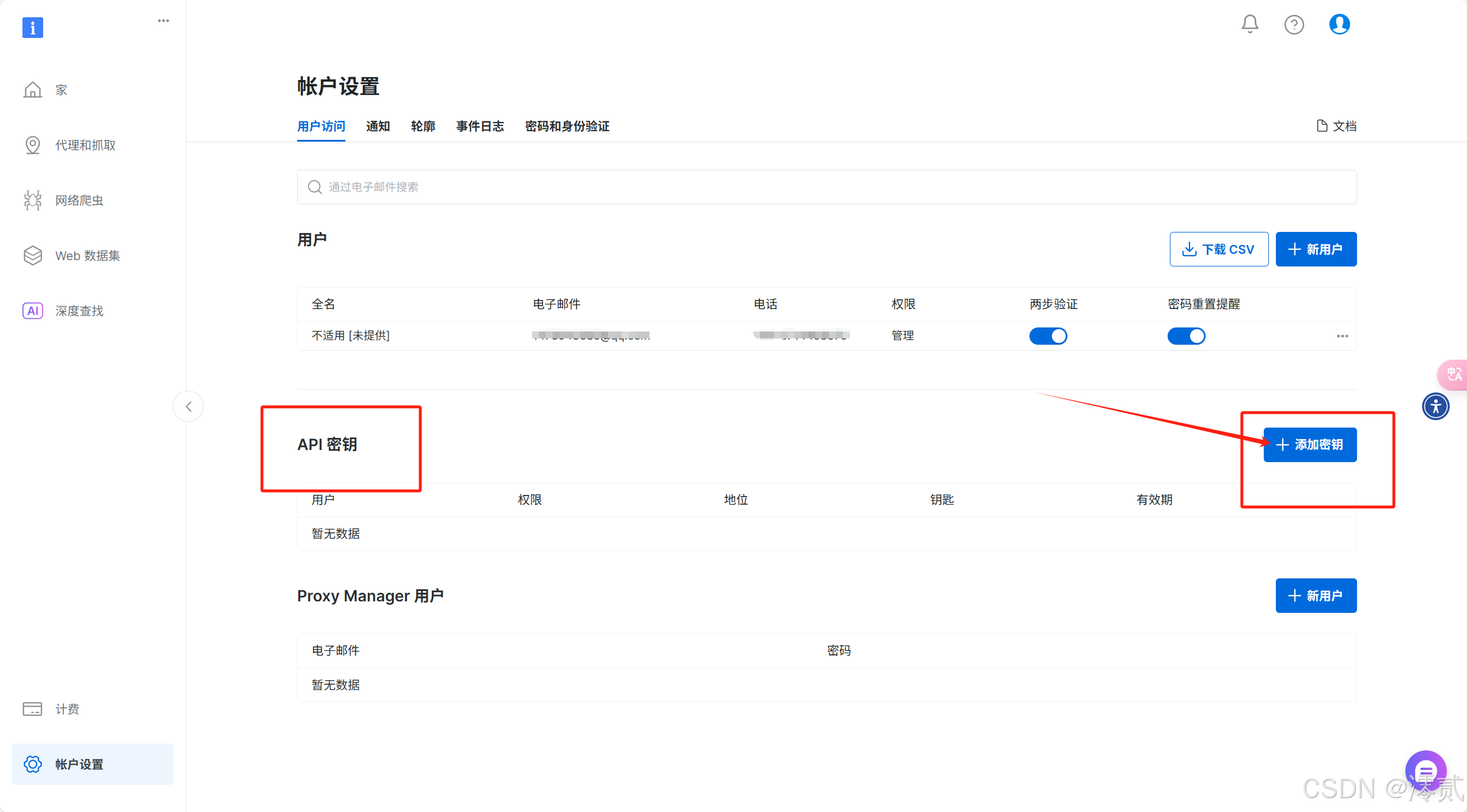
点击链接进入 API 密钥获取界面,可能会弹出让你再次登录的界面,登陆即可
单击 API 密钥部分右上角的添加 API 密钥按钮
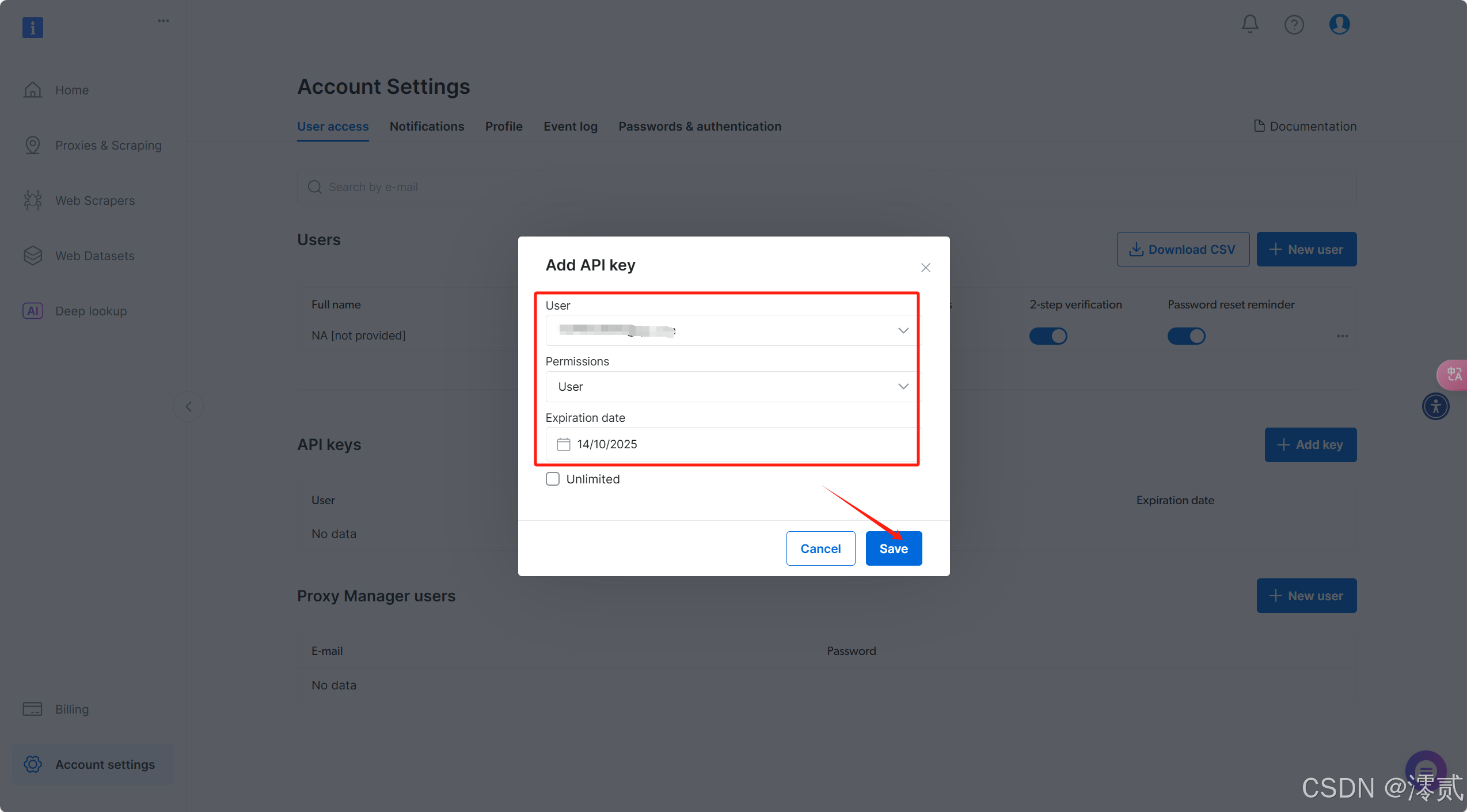
配置您的用户、权限和 API 密钥到期日期(或“无限制”),然后单击保存
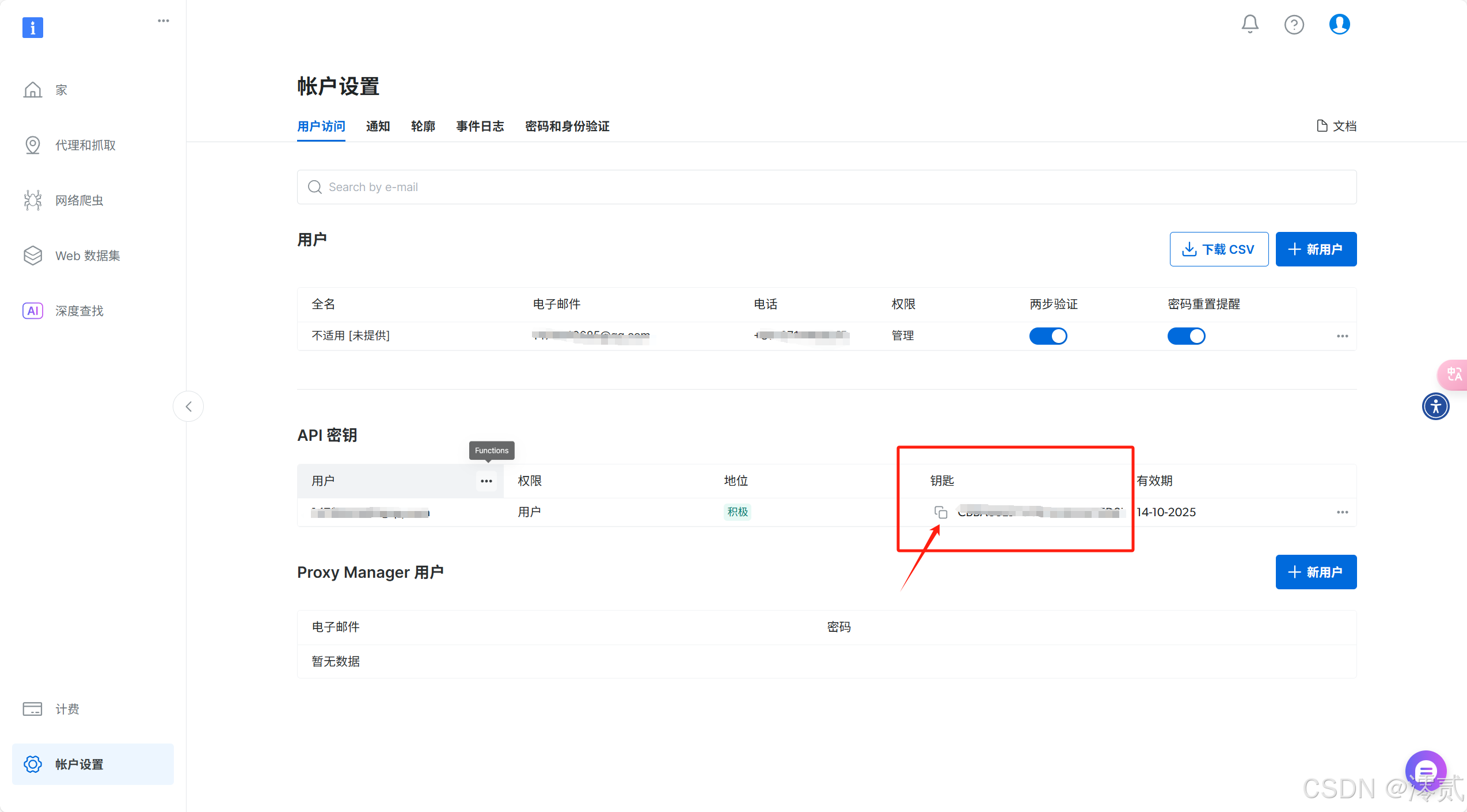
然后就会的得到 API 密钥,将其复制下来保存好,后面会用到
🔥注意: 生成 API 密钥后,确保将其保存到本地安全位置,因为它只会显示一次!
3.2 选择目标站点
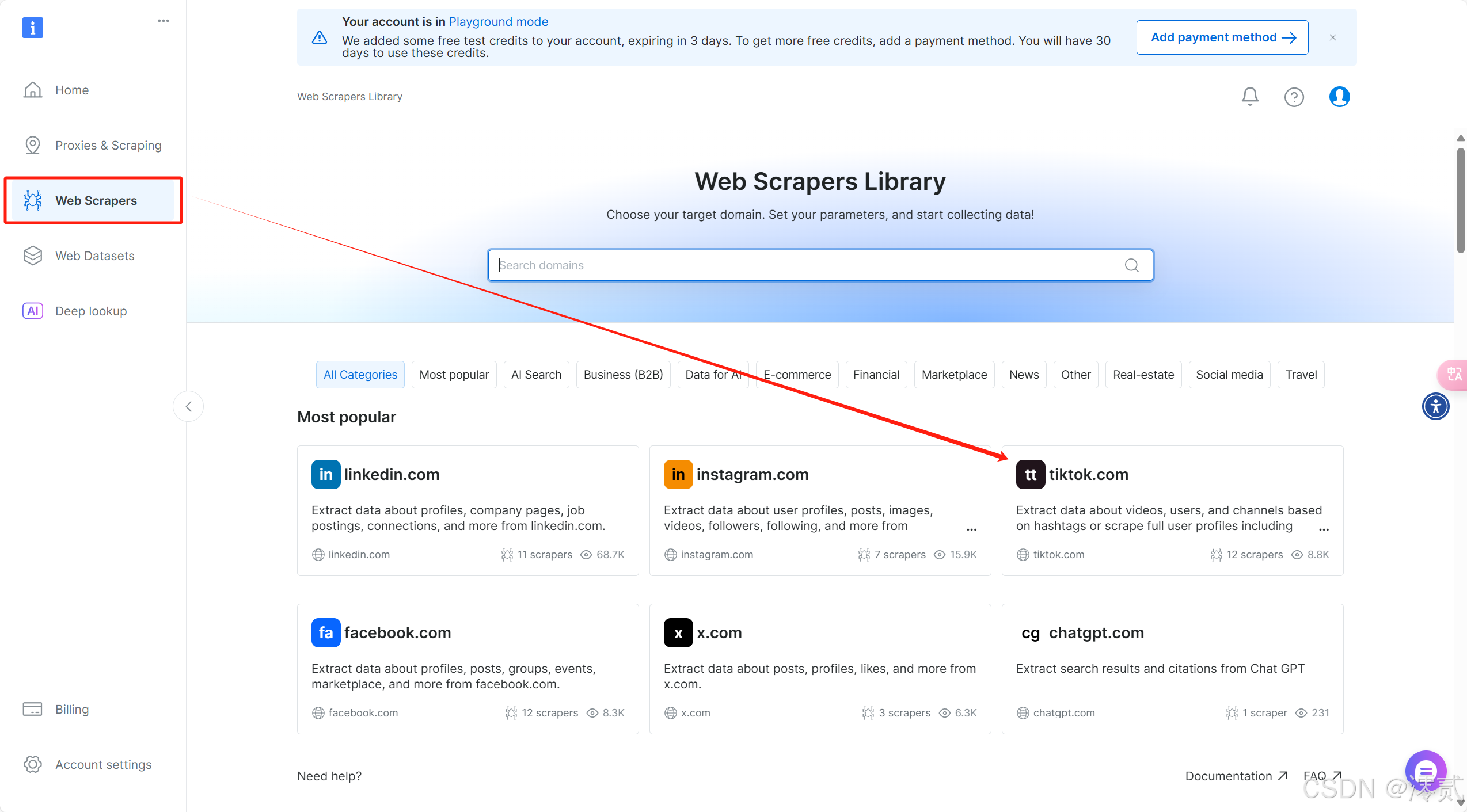
传送门:Scraper库
点击链接转到 Scraper 库,点击 Web Scrapers ,进入数据采集集市,在这里你能看到各种网站的 API 数据采集器,选取符合你需求的站点,后面就以 Tiktok 为例讲下采集器的使用
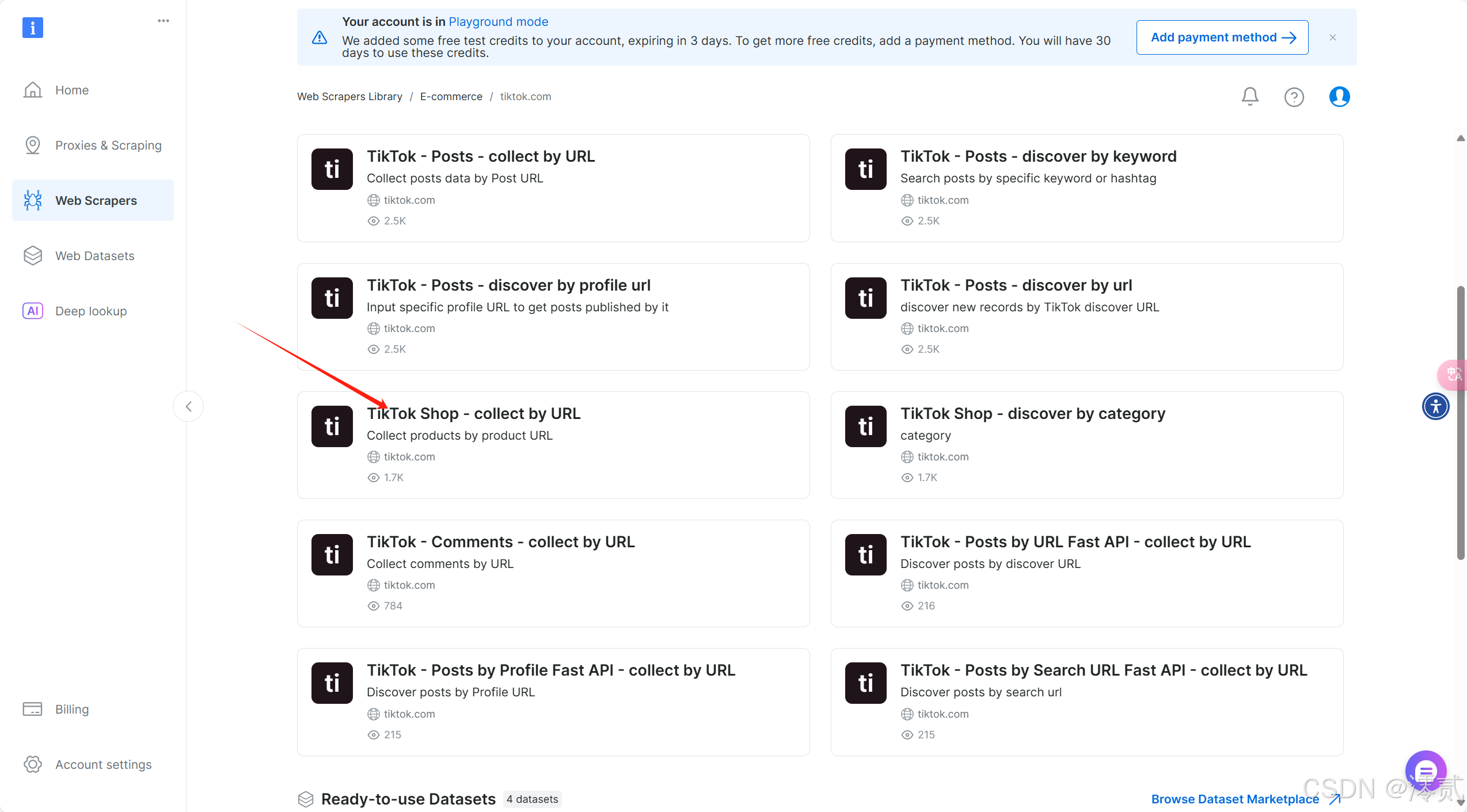
进去之后,会看到很多关于 Tiktok 数据的收集,比如帖子收集,商品数据收集,还可以分为 网址(URL)收集 或 关键字收集,这里我们以 Tiktok Shop - collect by URL 为例
然后选择 Scraper API 收集,点击下一步
3.3 配置数据收集相关
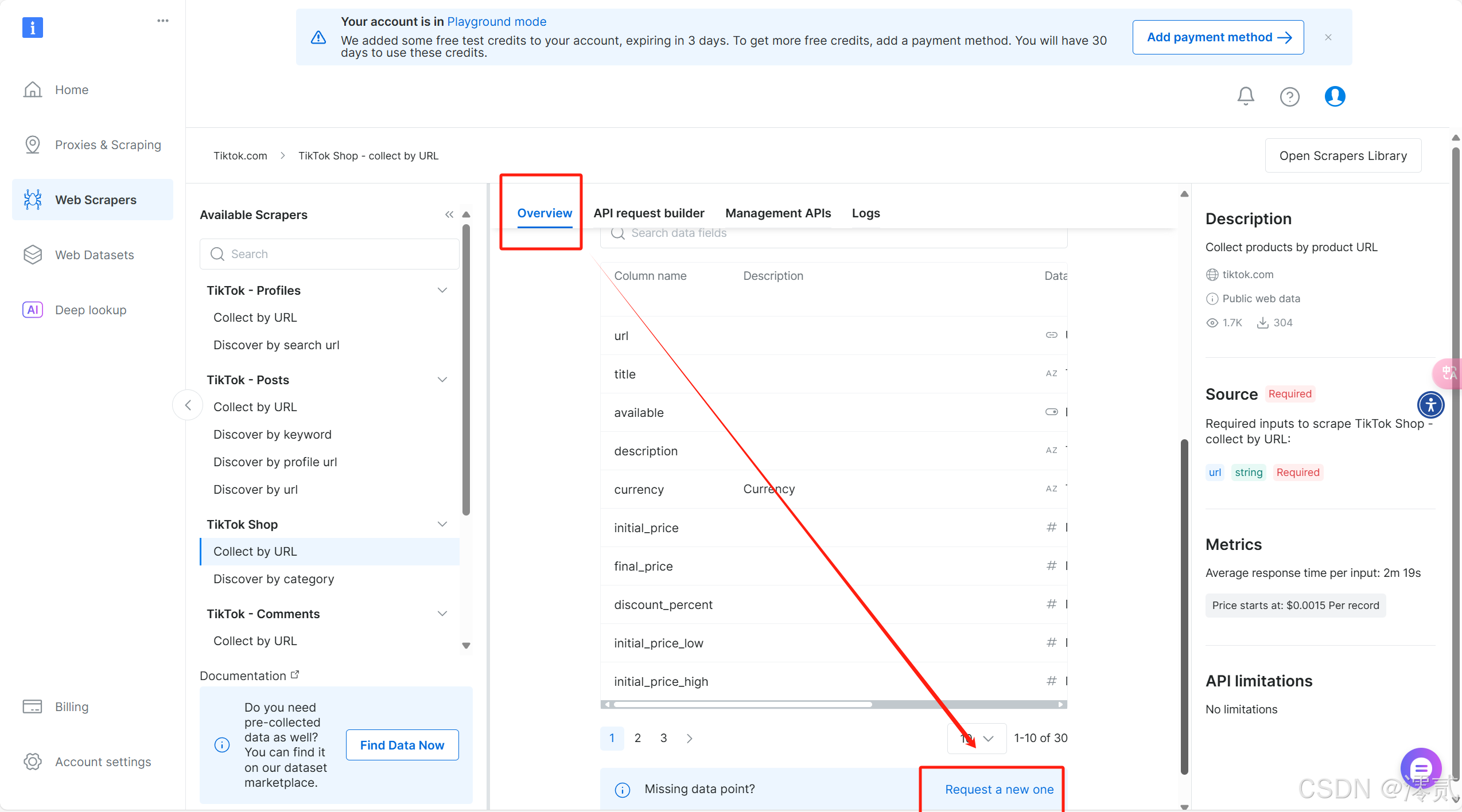
在 Overview 部分划到最下面的 Dictionary,可以查看商品数据收集的相关信息,如果还有想要添加的可以点击下面的 Request a new one
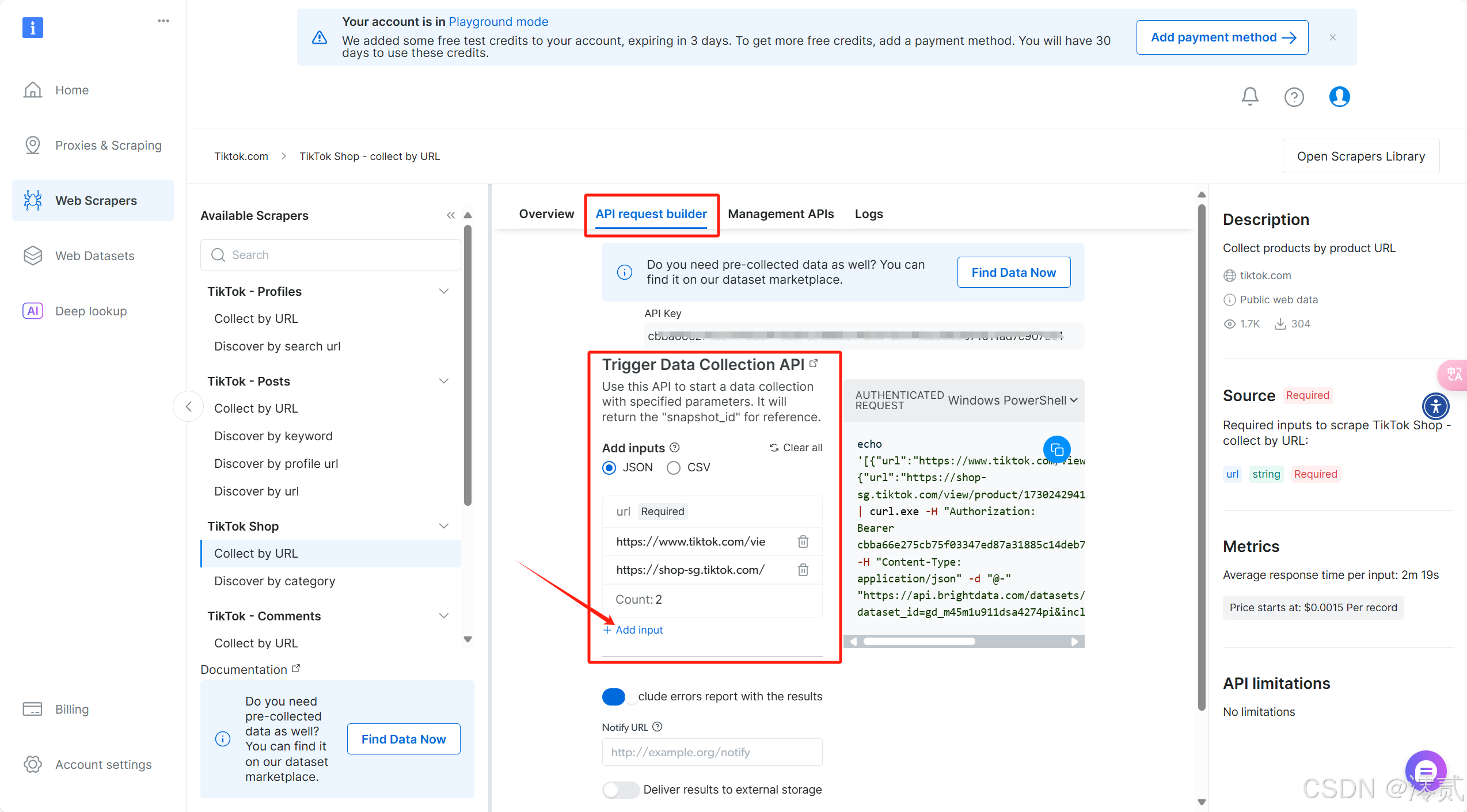
点击 API request builder 部分,在 Trigger Data Collection API 这里添加你想收集数据的 Tiktok 商品网页,注意是有数量限制的,具体以实际为准
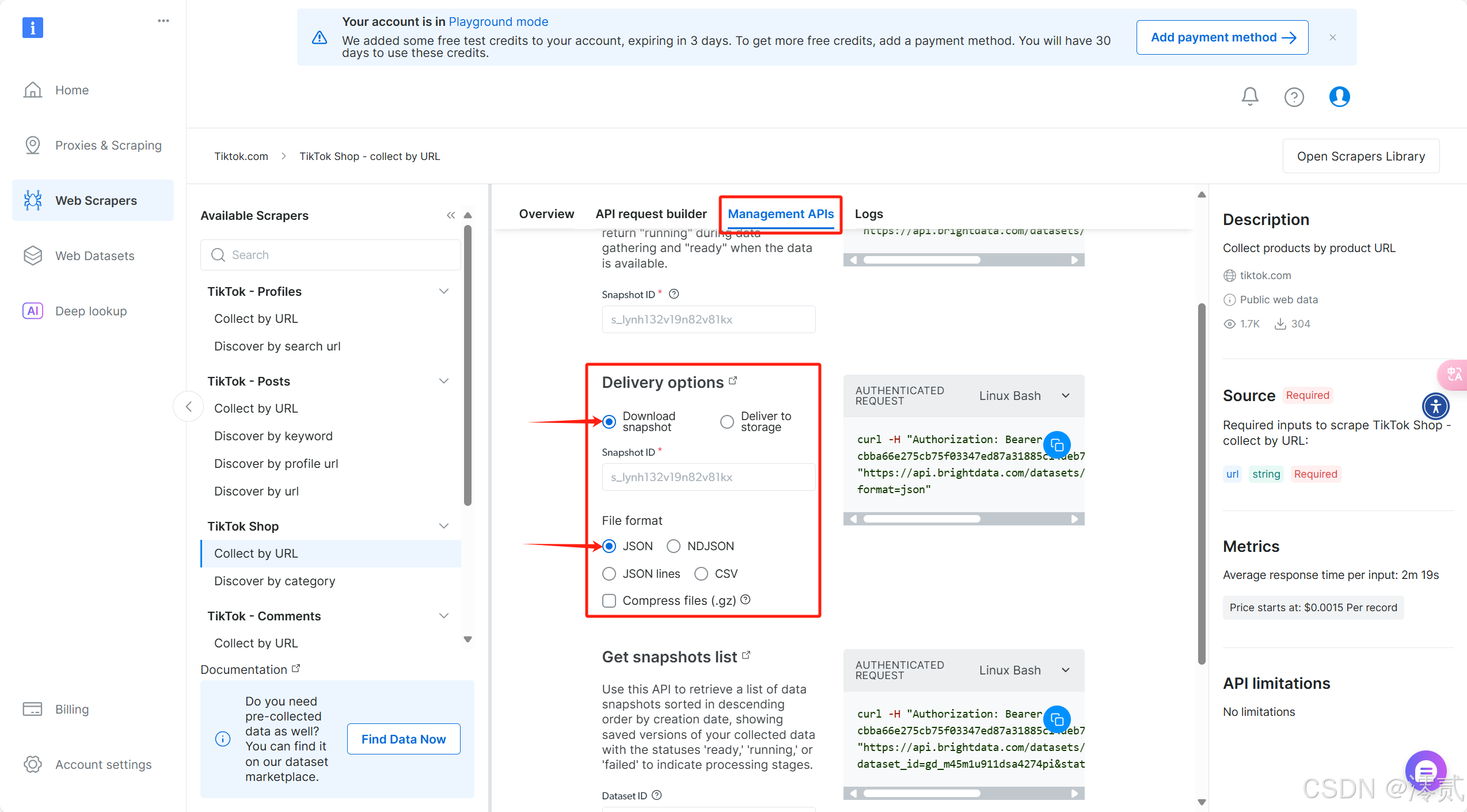
点击 Management APIs 部分,在 Delivery options 进行配送选项的配置
Download snapshot:数据临时存储下载Deliver to storage:发送到阿里,谷歌的等云存储
文件格式我这里是 JSON,一般这个就行了,具体以实际需求为准
3.4 数据抓取运行
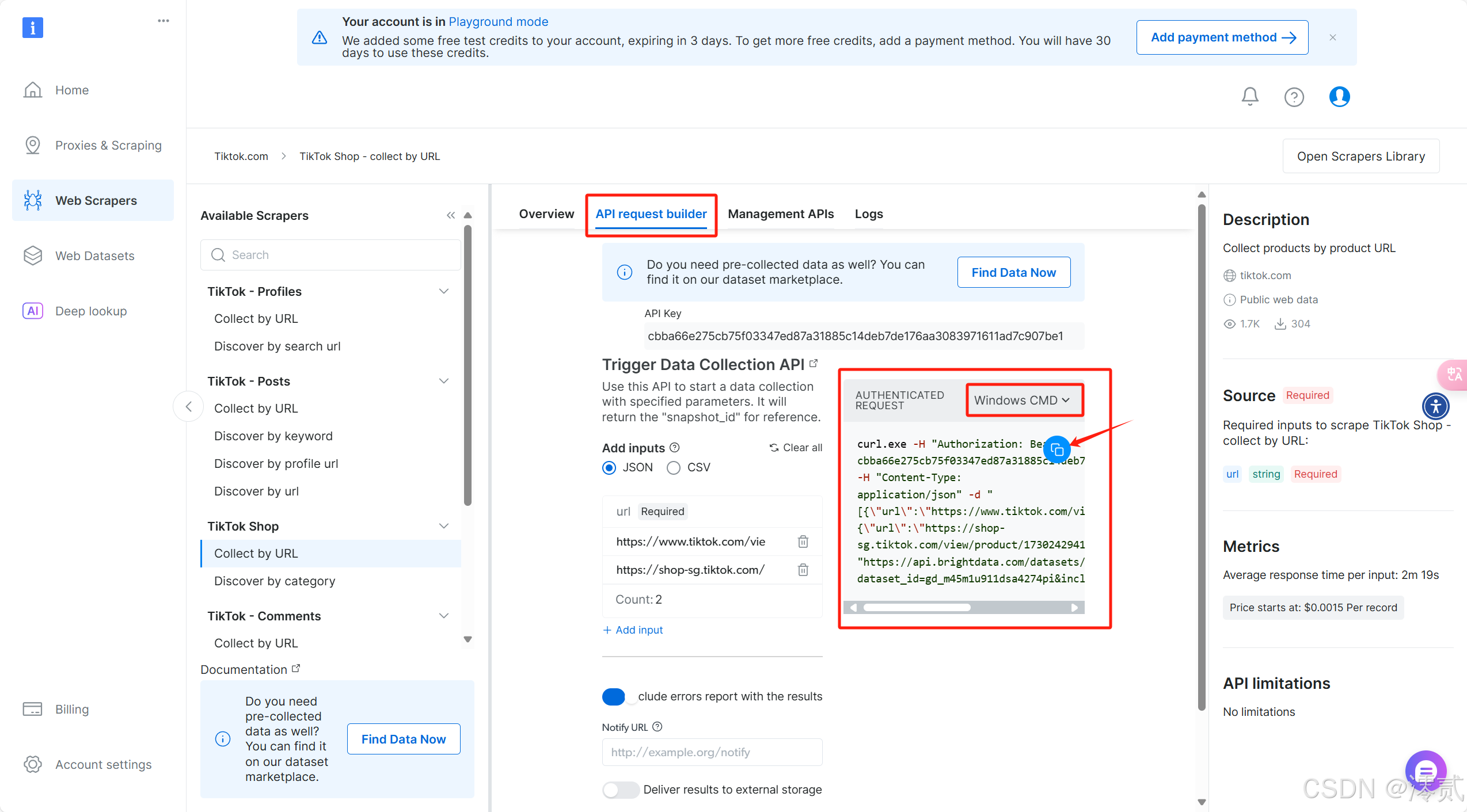
回到 API request builder 部分,复制右边配置好的命令行代码,选择 Windows CMD 进行本地运行
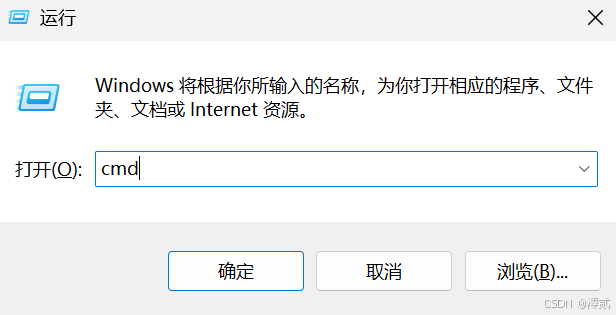
win + R 调出命令窗口,输入 cmd,打开命令行交互界面后粘贴刚才复制的命令行代码
🔥注意:
-H "Authorization: Bearer 你的API密钥"
Bearer 后面需要填写你刚才配置好的 API 密钥
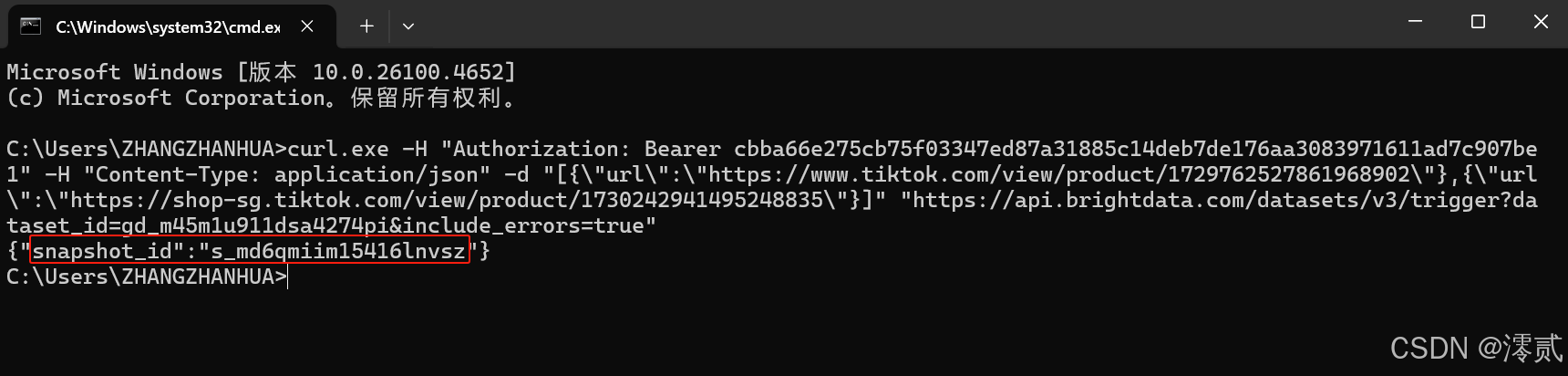
ENTER 键运行后,显示出 snapshot_id 字样,说明数据已经抓取成功并临时存储了,复制这一串 id 保存起来
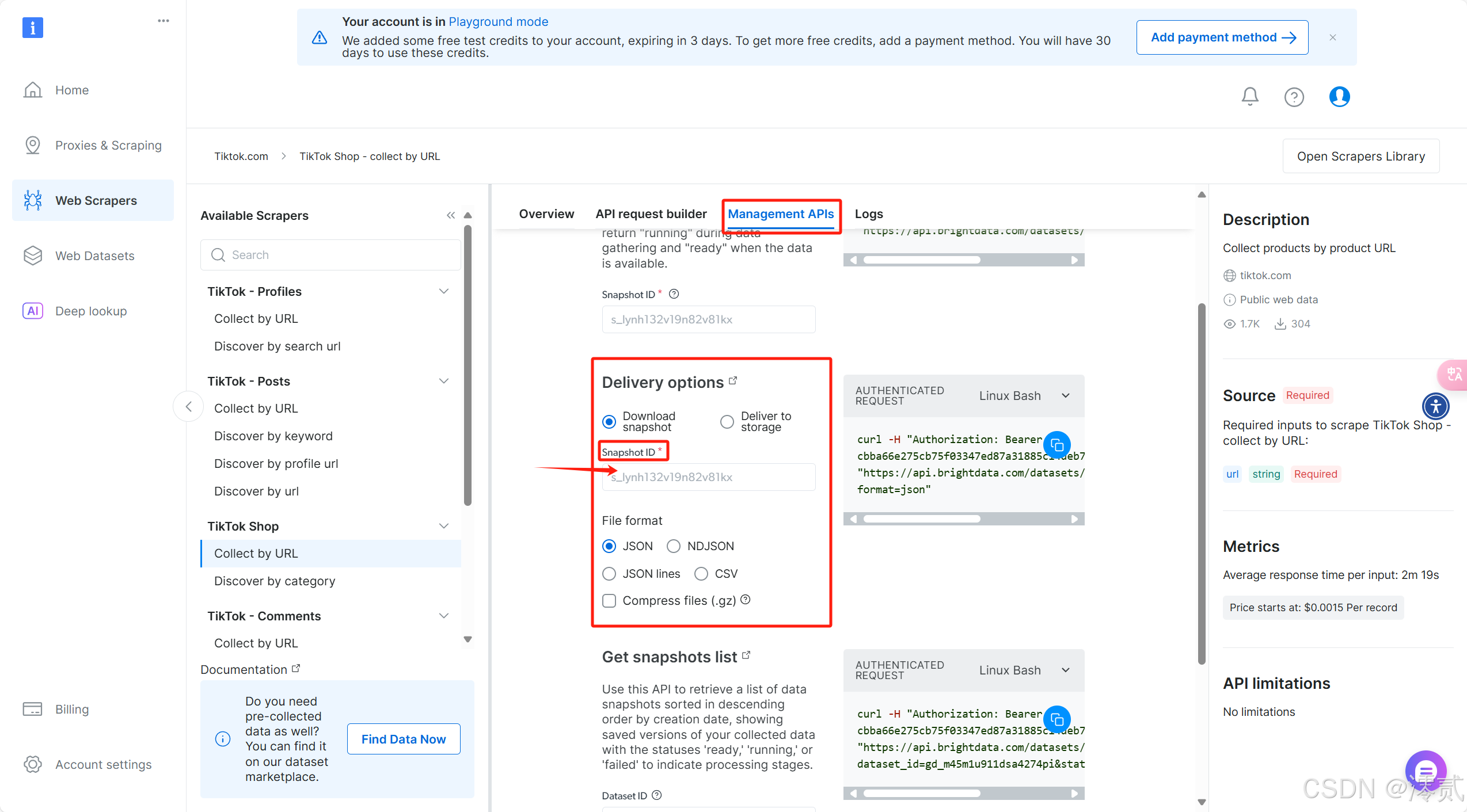
回到 Management APIs 部分,在 Delivery options 的 Snapshot ID 这里填入刚刚获取到的id
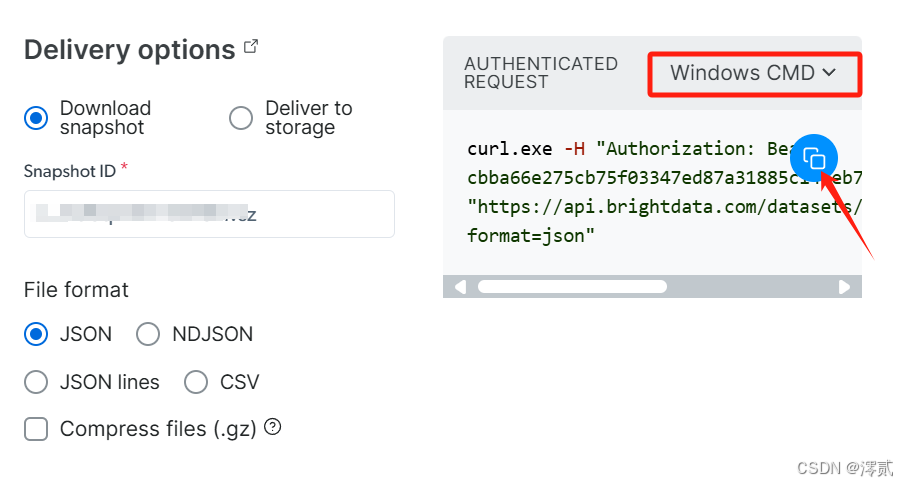
复制该页面右边的命令行代码,等待 1 分钟数据集快照处理,按上面的方法再次运行
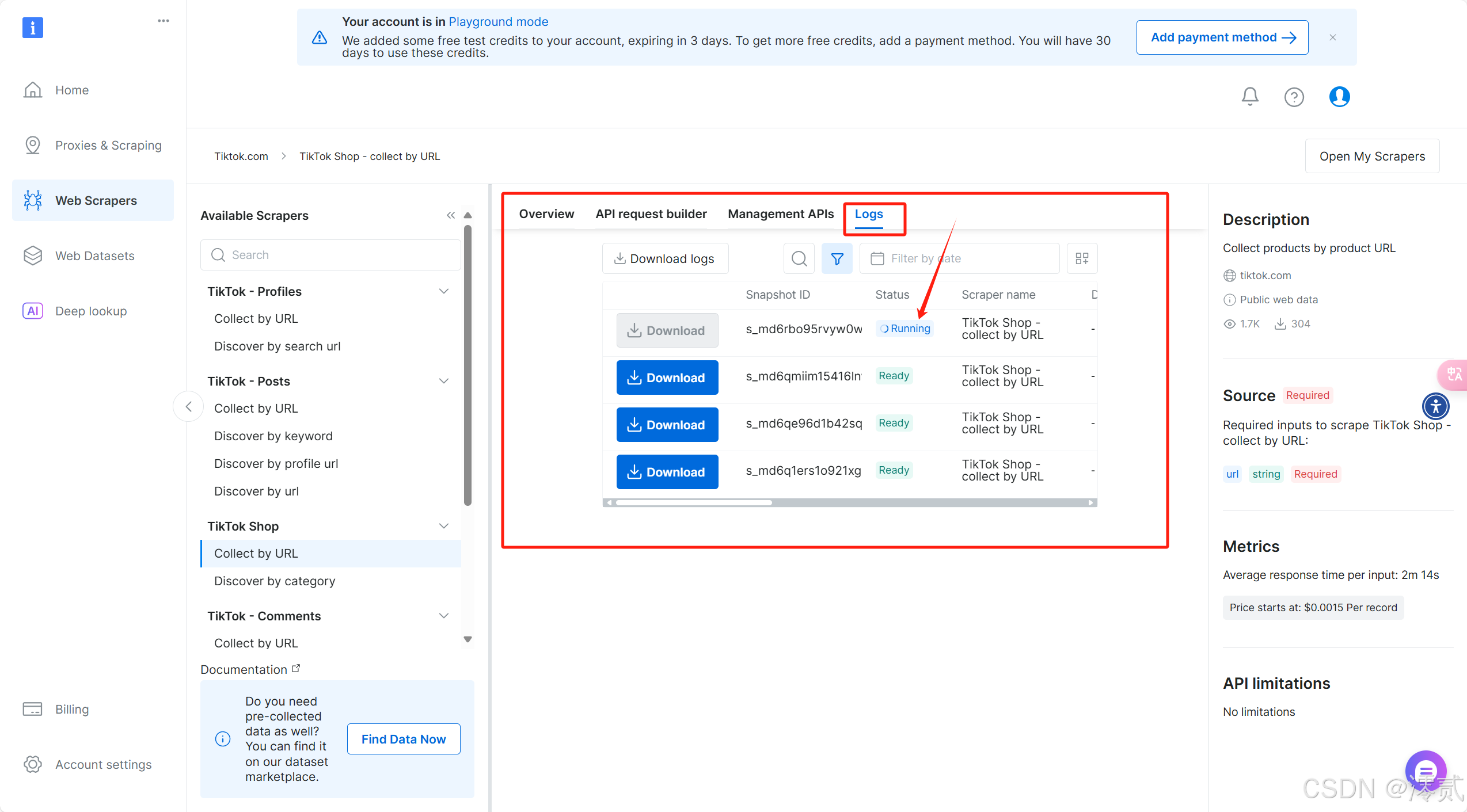
注意需要在 Logs 部分查看你的 id 是否处于 Ready 状态,才能进行数据收集,Running 状态下需要等待一会儿
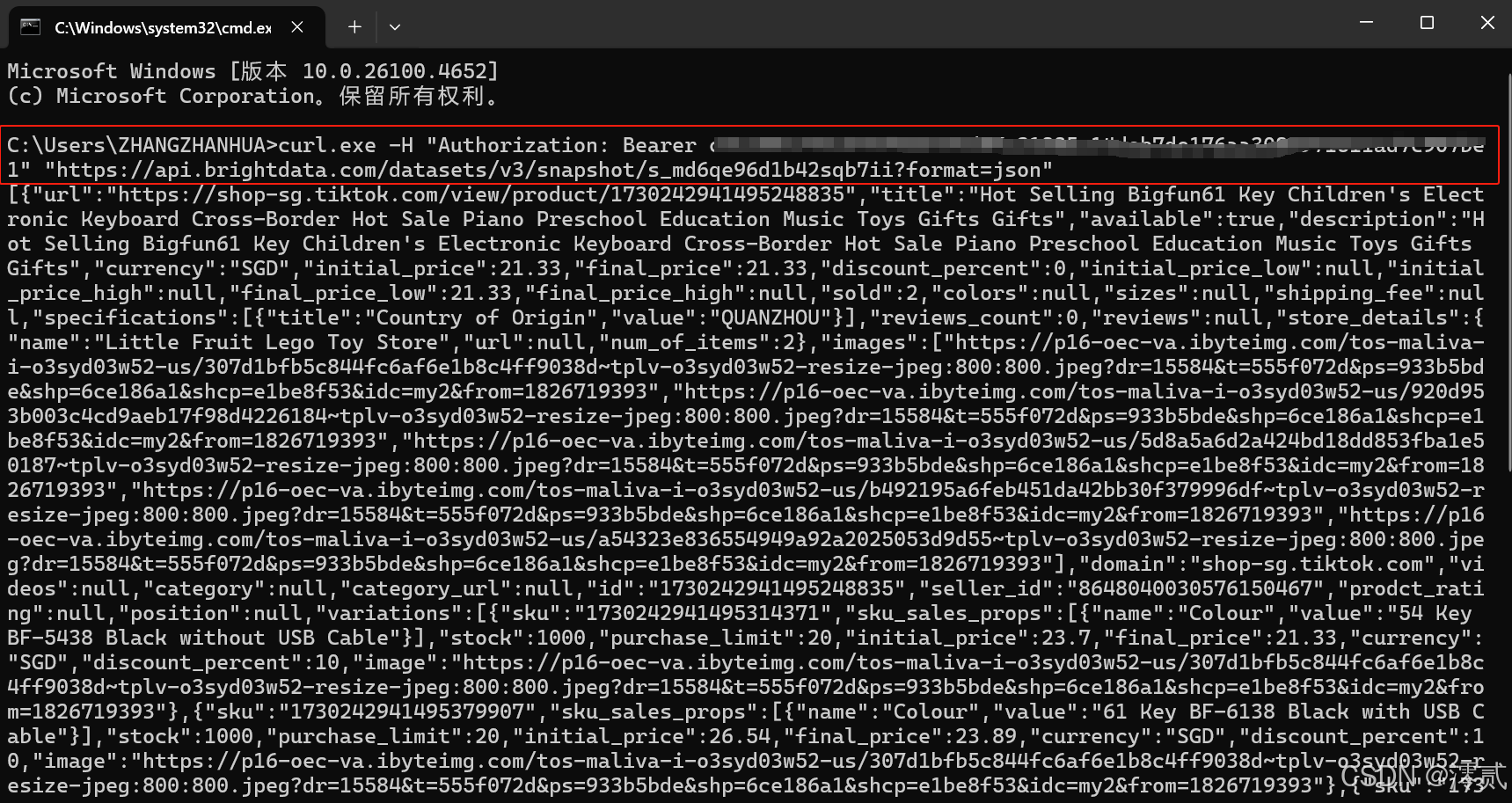
下面生成的一大堆数据集就是网页上爬取下来的商品信息,是不是操作很简单呢?想要可视化的数据的话可以让 AI 帮你整理
以上是简便的数据收集方法,如果需要频繁大量调用的话建议还是使用 python,方法和上面都是一样的,这里不再过多赘述
4.总结
Web Scraper API 抓取数据的过程不需要自己手动写代码,它帮助我们完成了在云上向 Tiktok 发出 http 数据请求;模拟登陆、配置 IP 代理、动态访问、识别验证码、破解加密数据等 ;解析获取的 HTML,提取重要的字段,输出为 json 格式的过程。
相较于自己动手写代码爬虫,还需要不断调试的麻烦,这种一键抓取的方式大大降低了上手的门槛,零基础小白也能轻松使用!
快来立即注册并免费试用 Web Scraper API 吧!( •̀ ω •́ )✧


















 3100
3100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









