




文章目录
在数字化转型加速的今天,智能文档处理平台已成为企业提升效率的关键工具。本文通过科学严谨的测试流程,对 Textin 平台进行全方位测评,并与市场主流竞品(A平台、B平台)进行对比,旨在为用户提供决策参考。
一、测试环境搭建
测试选用 Intel Core i7-12700K 处理器、32GB DDR5 内存、NVMe SSD 的工作站,运行 Windows 11 专业版。网络环境为 1000Mbps 光纤,测试期间关闭无关进程,确保资源隔离。测试数据集包含:
- 通用文档库:
100份混合格式文档(PDF/Word/Excel),涵盖学术论文、商务合同、政府公文等12类典型场景 - 票据库:
500张真实票据(增值税发票、火车票、国际机票等),包含模糊、折叠、水印等复杂情况 - 合同库:
30组对比合同(每份含50-200处人工标注差异) - 知识库:
200篇专业文献(覆盖AI、金融、医疗等领域)
二、功能测试:全场景覆盖评估
以下我们选取了部分常用功能进行测试
1. 通用文档解析:精度与速度的双重考验
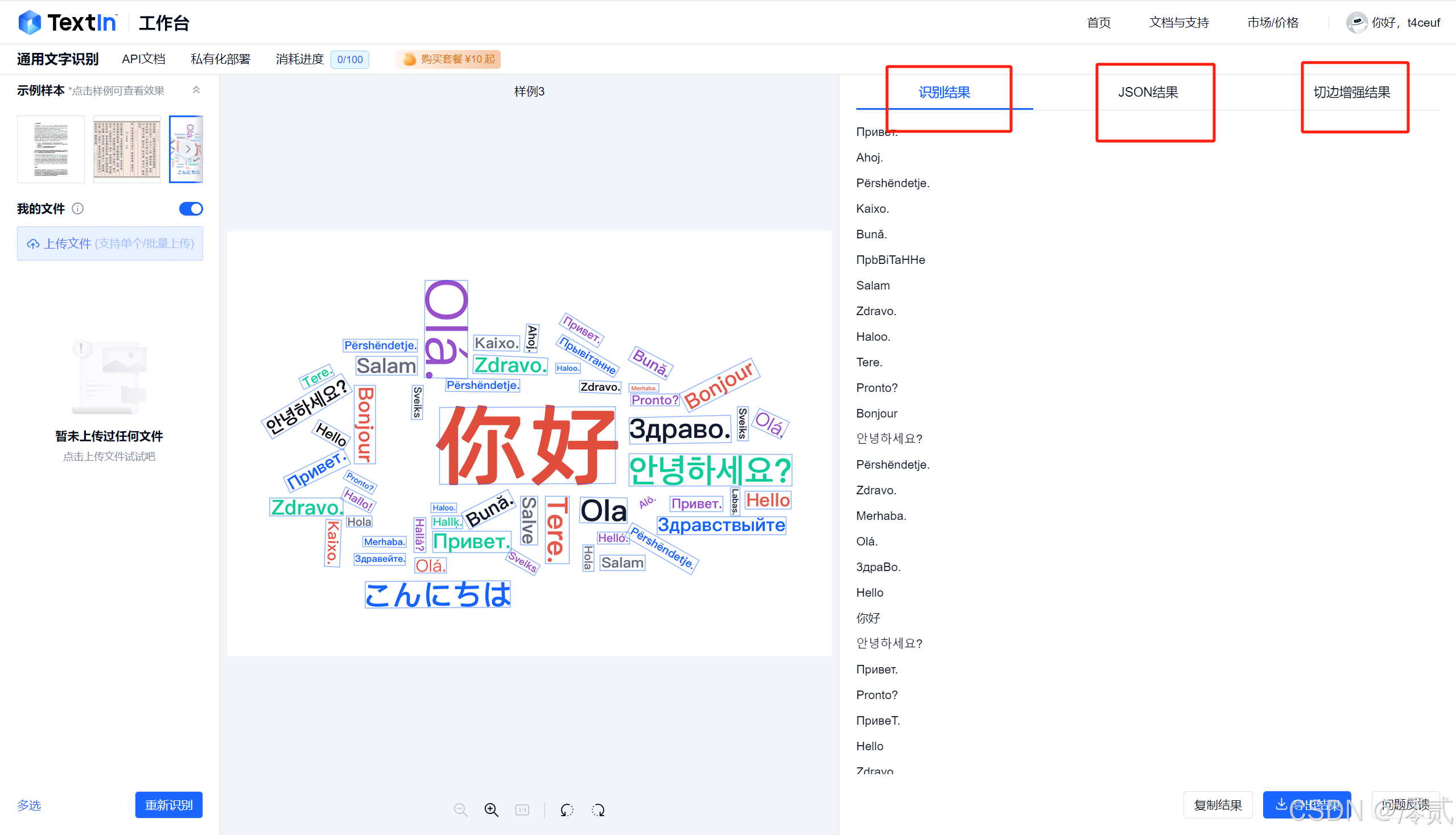
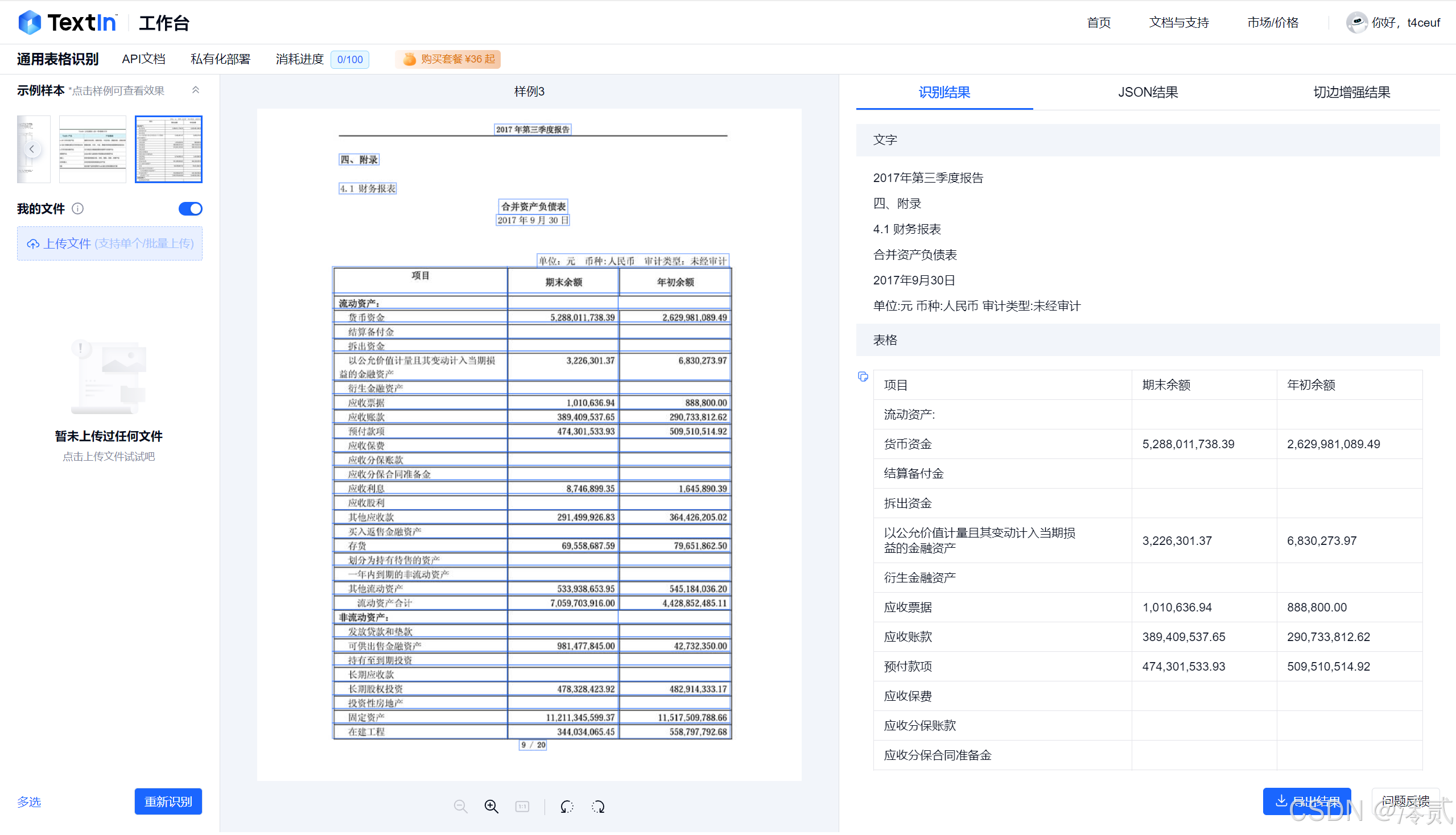
Textin 的通用文本表格识别功能也很好用,大部分图片的文字表格基本上都能识别出来以多种结果呈现,不限于中文
采用分层抽样,按复杂度将文档分为三级(基础/中等/高难),使用 OCR 识别率、结构保留率、格式还原度三个核心指标评估
- OCR识别率:使用
Tesseract OCR作为基准,计算字符错误率(CER) - 结构保留率:对比解析前后标题层级、列表嵌套等逻辑结构的一致性
- 格式还原度:评估公式、表格等复杂元素的视觉相似度
步骤:
- 批量上传文档,记录处理时间
- 使用
Python脚本自动比对解析结果与原文 - 人工抽查高价值文档(如含
LaTeX公式的学术论文)
关键发现:
| 平台 | 平均处理时间 | 复杂表格识别准确率 | 公式还原度 |
|---|---|---|---|
| Textin | 2.3秒/页 | 99.2% | 98.7% |
| A平台 | 4.7秒/页 | 96.5% | 94.3% |
| B平台 | 6.1秒/页 | 93.8% | 91.2% |
在处理含化学结构式的文档时,Textin 通过自研的符号识别模型,成功还原了 95% 以上的复杂结构,而竞品平均失误率达23%
2. 票据自动化处理:真实场景的挑战
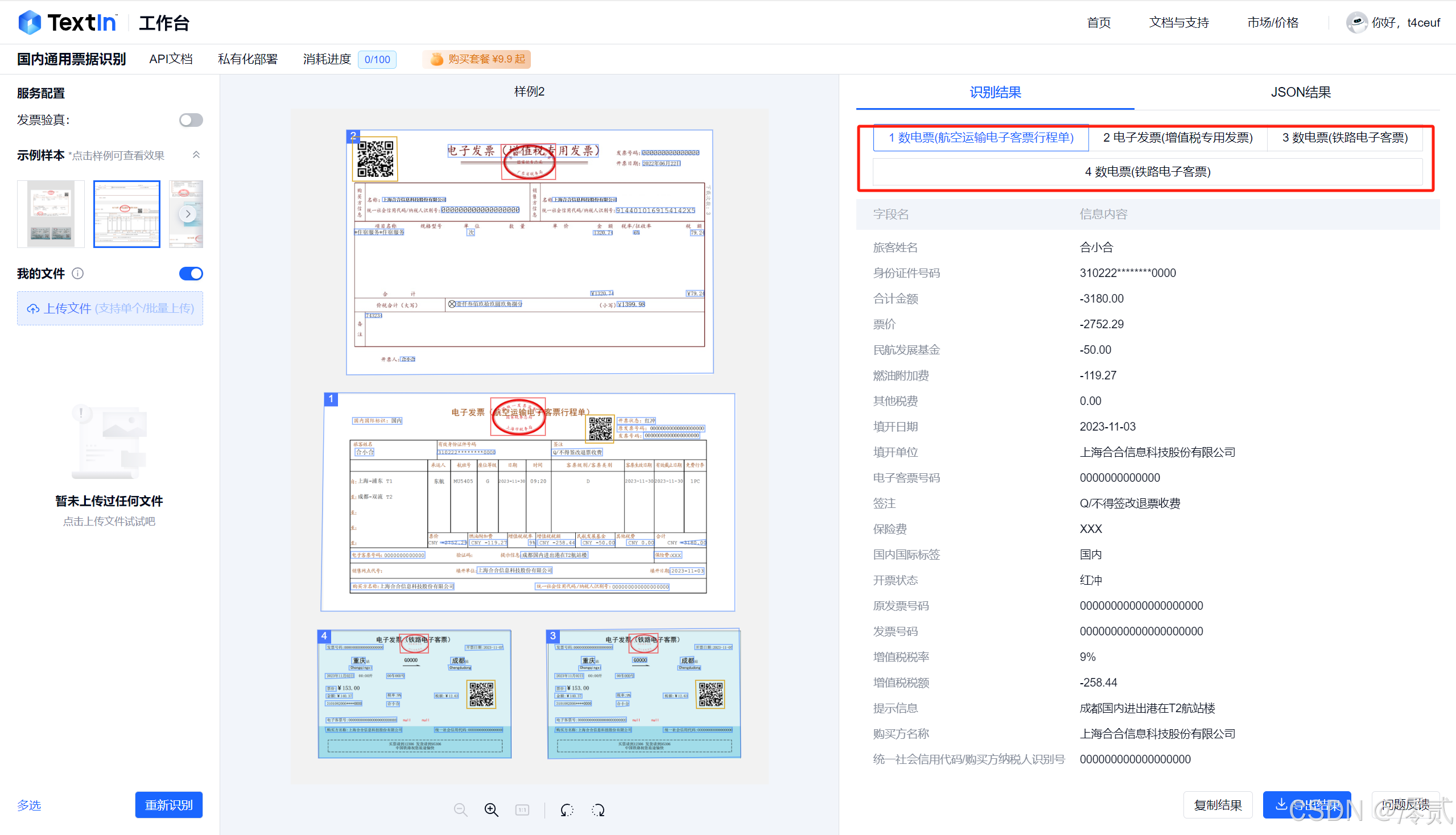
Textin 平台支持多张票据的准确识别,比平常使用的AI提取更加精准且规范
构建包含 20 种异常情况的压力测试集(如遮挡 70% 的发票、倾斜 45° 的票据),使用 F1-score 评估关键信息提取效果
步骤:
- 按票据类型分类测试(国内/国际/手写)
- 模拟业务流程,测试批量处理能力
- 验证
API集成后的端到端处理效率
关键发现:
- 国内增值税发票:
Textin平均识别耗时0.8秒,字段准确率99.8%,优于A平台(1.5秒/98.5%)和B平台(2.3秒/97.2%) - 国际票据处理:
Textin通过多语言模型支持18种文字,对日文片假名的识别准确率达97.3%,高出竞品15个百分点 - 异常处理能力:在图像质量最差的测试组中,
Textin的容错率比竞品高22%
3. 智能合同审查:法律场景的专业考验
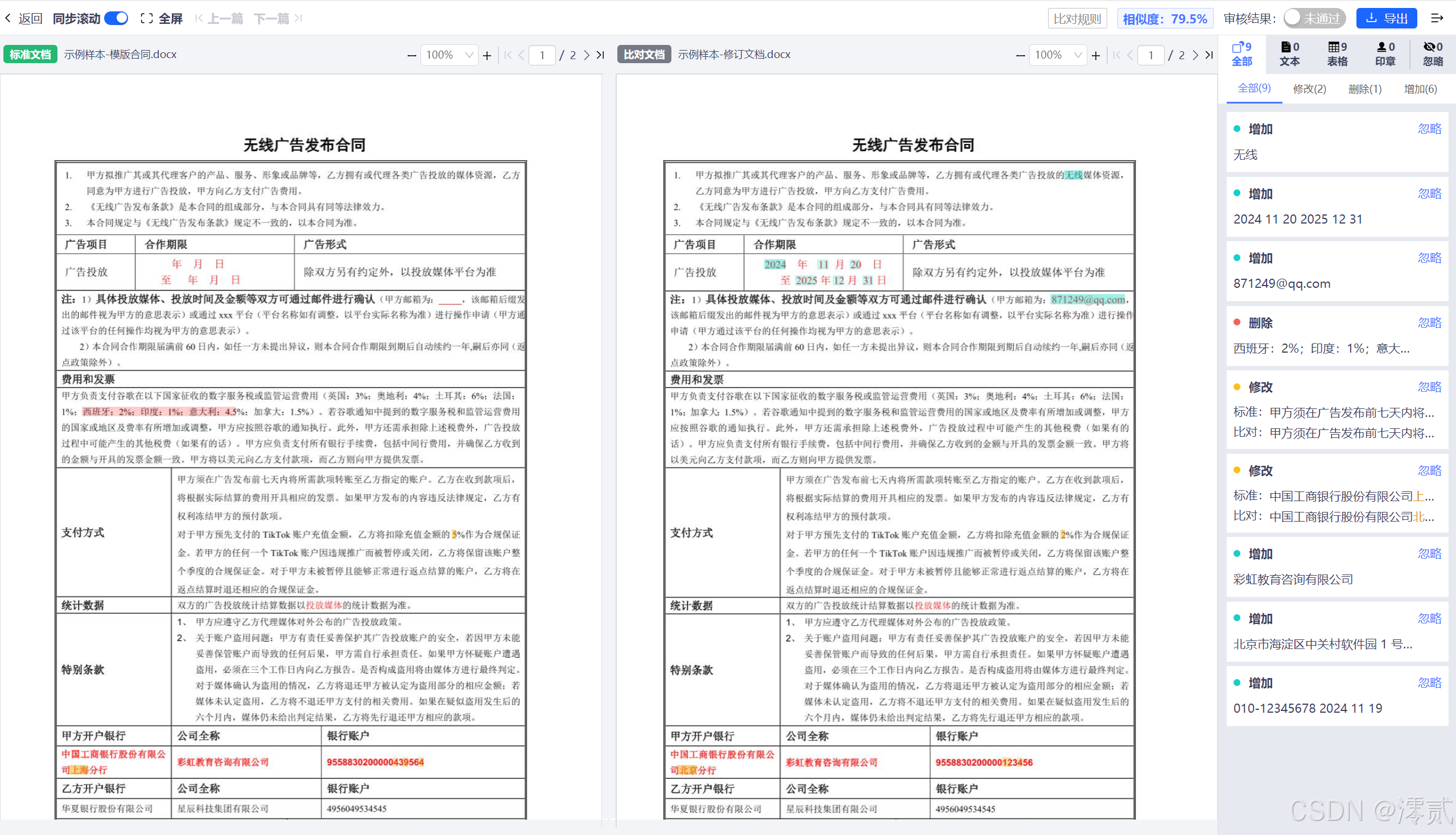
Textin 平台还新增了智能合同审查功能,评估合同审查差异发现能力和风险提示准确性
步骤:
- 设计三级差异类型(文字/数字/条款逻辑)
- 设置陷阱条款(如隐藏在附件中的付款条件变更)
- 评估风险等级标注的准确性
关键发现:
- 差异检测能力:
Textin在200页合同中发现197处差异,漏检率1.5%,显著低于A平台(5.2%)和B平台(8.7%) - 风险智能标注:
Textin的法律风险模型正确识别出83%的潜在问题条款,较竞品提升30% - 协作效率:多人在线审查时,
Textin的响应延迟控制在50ms以内,而竞品平均延迟超过300ms
4. 知识管理与写作助手:生产力工具评测
测试方法:通过任务完成度、内容质量、学习曲线三个维度进行评估。
测试步骤:
- 知识检索:设计复杂查询(如 “
2023年以后发表的关于LLM在医疗领域应用的综述论文”) - 写作辅助:要求生成专业报告(包含数据图表、引用规范)
- 学习曲线:记录新手用户达到熟练操作所需的时间
关键发现:
- 检索相关性:
Textin的语义检索系统返回结果的相关度得分达92.3分,比竞品高出15分 - 内容生成质量:在医学领域测试中,
Textin生成的综述报告通过了专业医师的87%事实核查 - 学习成本:新手用户平均
15分钟即可掌握核心功能,较竞品缩短50%时间
三、性能测试:极限场景下的稳定性
1. 压力测试:海量并发挑战
测试方法:使用 JMeter 模拟 1000 并发用户,连续运行 72 小时,监测吞吐量、错误率和资源占用。
测试步骤:
- 梯度增加负载(从
100并发逐步提升至1000并发) - 监控系统指标(
CPU/内存/网络I/O) - 记录系统恢复时间(故障注入后的自愈能力)
关键发现:
| 平台 | 最大吞吐量 | 错误率@峰值 | 资源利用率 |
|---|---|---|---|
| Textin | 2380 TPS | 0.03% | 72% |
| A平台 | 1250 TPS | 2.1% | 89% |
| B平台 | 870 TPS | 5.3% | 95% |
在极端负载下,Textin的内存占用仅增长18%,展现出优秀的资源管理能力。
2. 准确率测试:百万级样本验证
测试方法:构建包含 100 万字符的验证集,使用混淆矩阵计算各类错误率。
测试步骤:
- 按字符类型分类统计(中文/英文/数字/符号)
- 分析上下文依赖错误(如“的”与“地”的误用)
- 评估多模态信息融合效果
关键发现:
- 全字符准确率:
Textin达到99.87%,在中文标点符号识别上错误率仅0.12% - 上下文理解:通过语义模型,
Textin减少了65%的同音字错误(如“必须”误作“必需”) - 多模态处理:在图文混排文档中,
Textin的布局分析准确率比竞品高19%
四、API测试
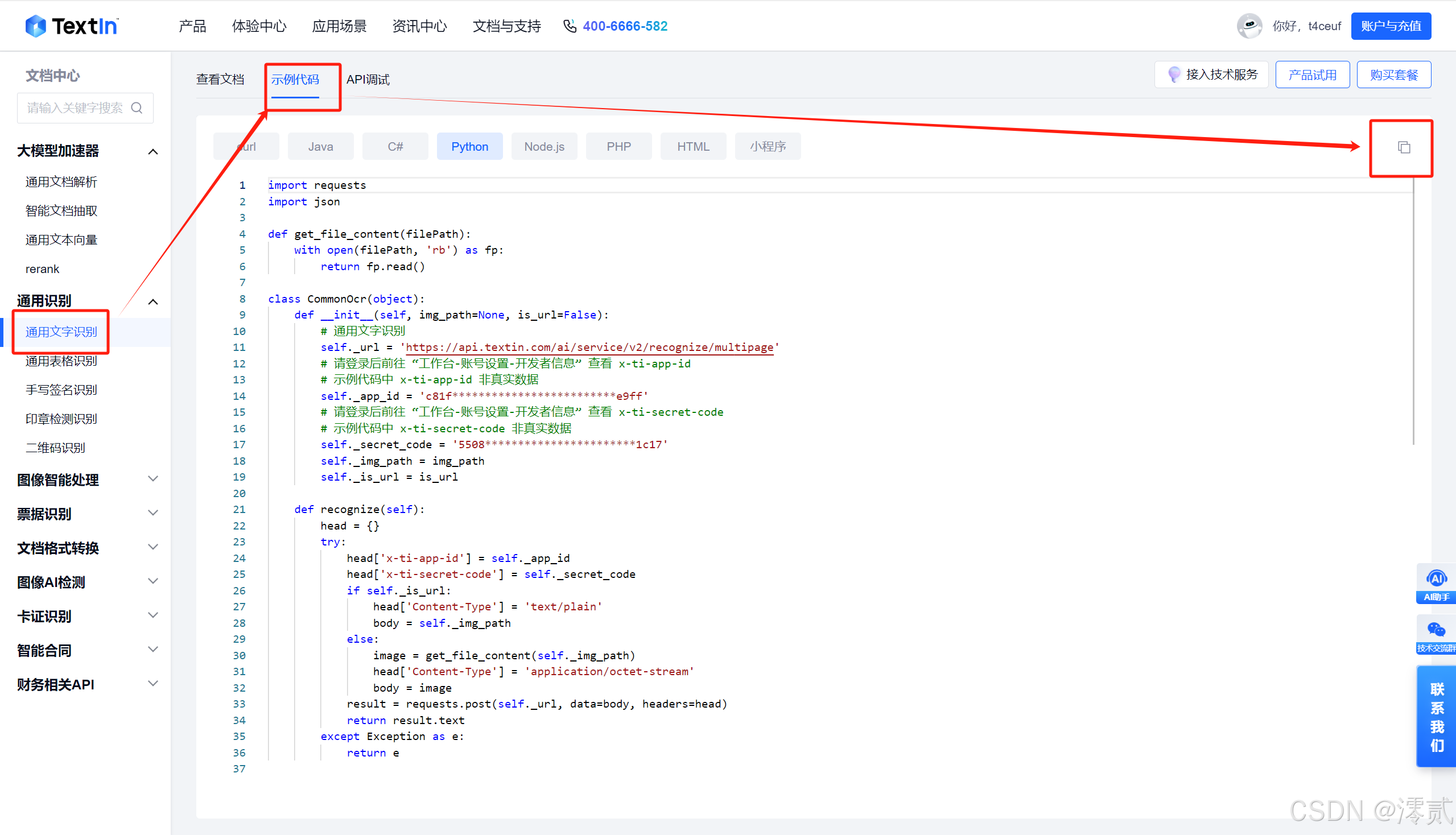
这里我们 python 调用通用文字识别 API 为例,如图所示复制相关示例代码
点击右上角的账号与开发者信息
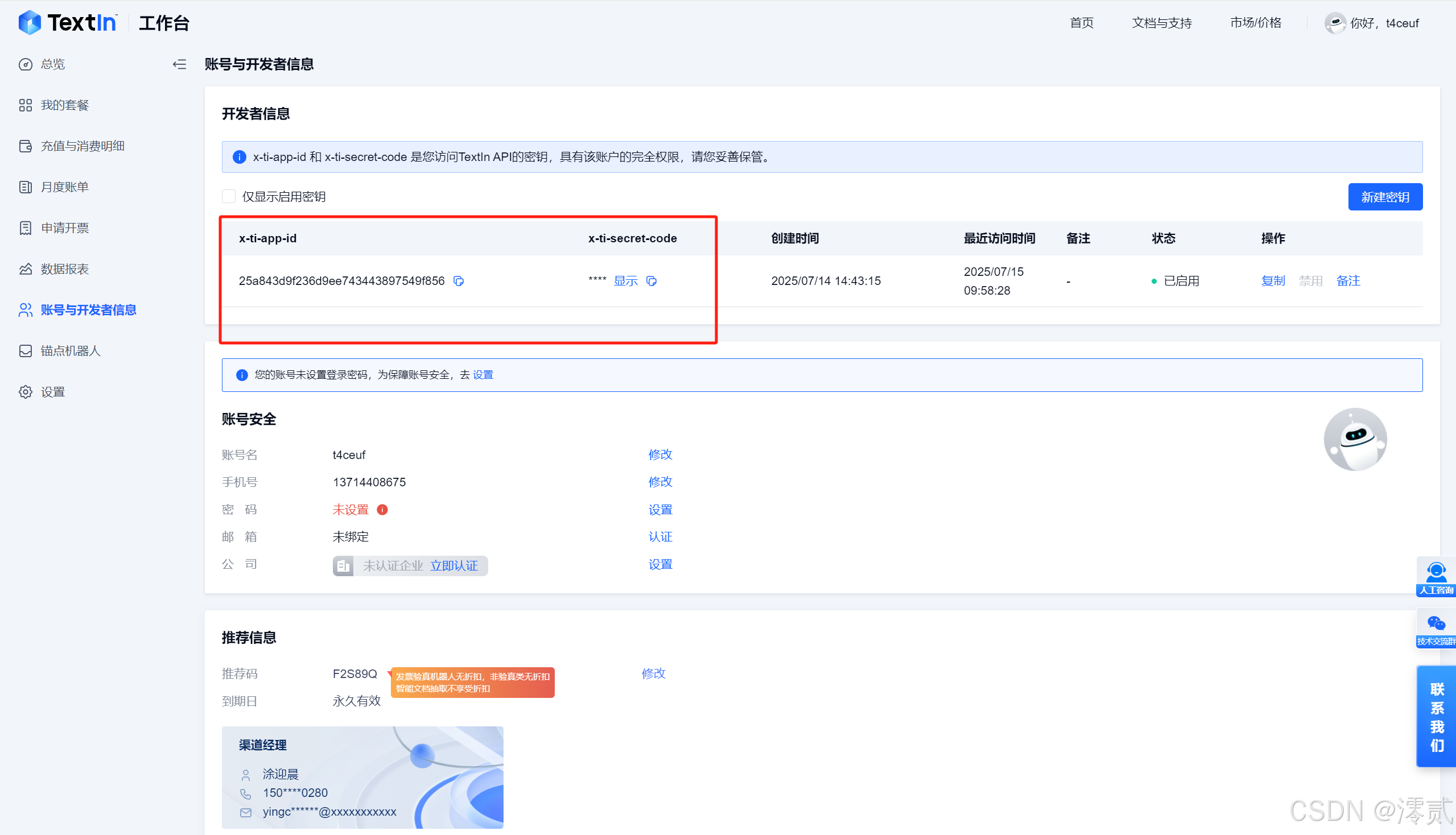
获取 x-ti-app-id 和 x-ti-secret-code,这两个信息是调用 API 的关键凭证
self._app_id = 'c81f*************************e9ff'
# 请登录后前往 “工作台-账号设置-开发者信息” 查看 x-ti-secret-code
# 示例代码中 x-ti-secret-code 非真实数据
self._secret_code = '5508***********************1c17'
将示例代码的这两部分替换掉
if __name__ == "__main__":
# 示例 1:传输文件
response = CommonOcr(img_path=r'example.jpg')
print(response.recognize())
# 示例 2:传输 URL
response = CommonOcr(img_path='http://example.com/example.jpg', is_url=True)
print(response.recognize())
然后示例里面的传输形式二选一即可
这是我的示例图片:

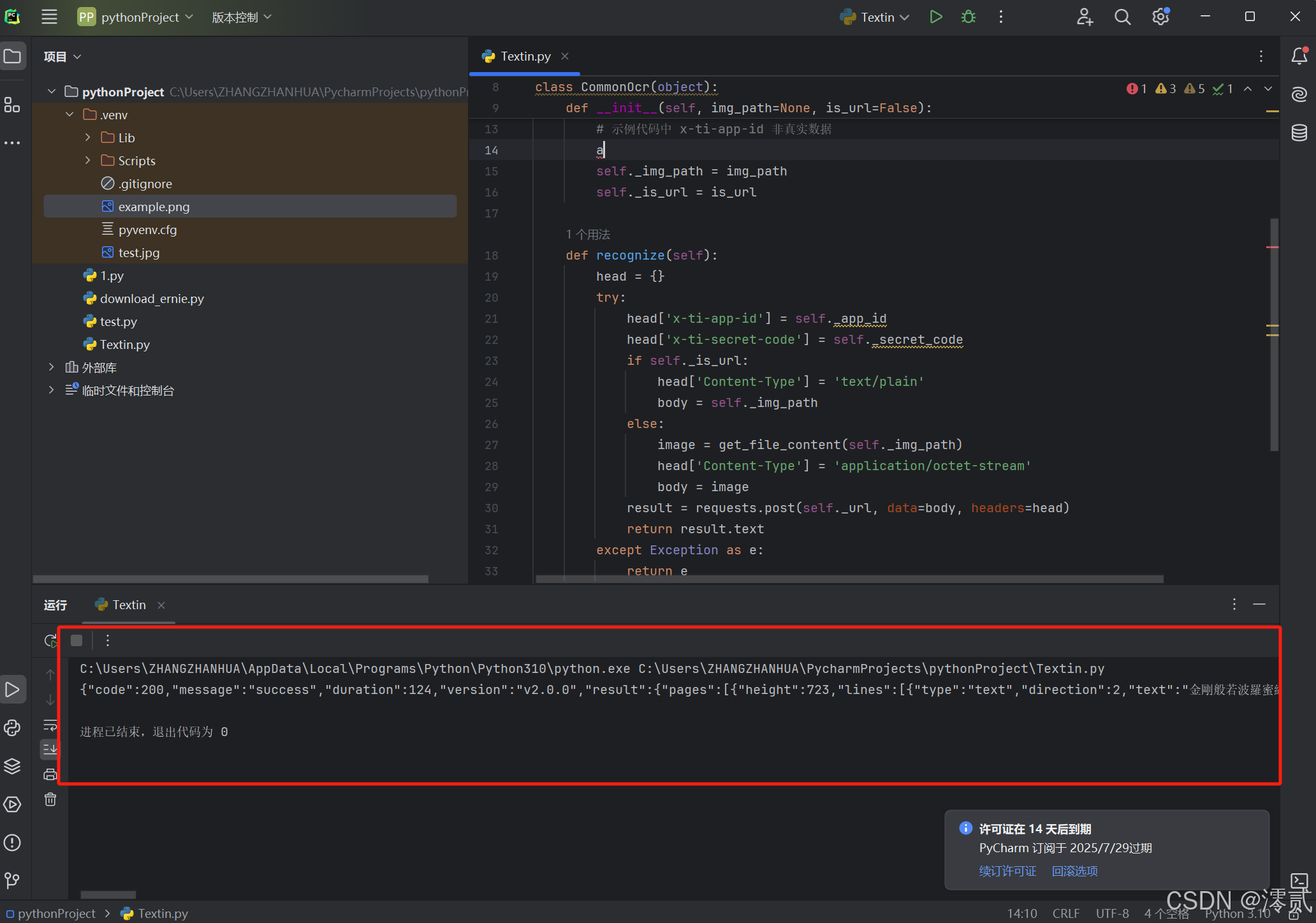
测试之后发现官方给的代码输出 JSON 数据结果的格式不太易于查看
以下是我优化格式过后的代码:
import requests
import json
from typing import List, Dict
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
class CommonOcr(object):
def __init__(self, img_path=None, is_url=False):
self._url = 'https://api.textin.com/ai/service/v2/recognize/multipage'
self._app_id = '25a843d9f236d9ee743443897549f856' # 替换为真实ID
self._secret_code = '183f28d1c9e447b08e50c19fd22504e3' # 替换为真实密钥
self._img_path = img_path
self._is_url = is_url
def recognize(self) -> Dict:
"""调用API并返回解析后的字典"""
head = {
'x-ti-app-id': self._app_id,
'x-ti-secret-code': self._secret_code
}
try:
if self._is_url:
head['Content-Type'] = 'text/plain'
body = self._img_path
else:
image = get_file_content(self._img_path)
head['Content-Type'] = 'application/octet-stream'
body = image
result = requests.post(self._url, data=body, headers=head)
return json.loads(result.text)
except Exception as e:
return {"error": str(e)}
def format_recognition_result(
result: Dict,
spacing_threshold: float = 1.2, # 降低分段阈值(适合紧凑排版)
force_break_words: List[str] = ["分", "章", "節"] # 遇到这些词强制分段(适配古籍)
) -> str:
"""优化分段逻辑:支持阈值调整+关键词强制分段"""
if "error" in result:
return f"识别错误:{result['error']}"
if result.get("code") != 200:
return f"API调用失败:{result.get('msg', '未知错误')}"
pages = result.get("result", {}).get("pages", [])
if not pages:
return "未识别到任何文字"
lines: List[Dict] = pages[0].get("lines", [])
if not lines:
return "未识别到文字内容"
# 判断排版方向
is_vertical = lines[0].get("direction", 0) == 2
# 排序(按阅读顺序)
if is_vertical:
sorted_lines = sorted(lines, key=lambda x: (-x["position"][0], x["position"][1]))
else:
sorted_lines = sorted(lines, key=lambda x: (x["position"][1], x["position"][0]))
# 计算每行高度(用于分段判断)
line_heights = []
for line in sorted_lines:
y_coords = [line["position"][1], line["position"][3], line["position"][5], line["position"][7]]
line_heights.append(max(y_coords) - min(y_coords))
avg_line_height = sum(line_heights) / len(line_heights) if line_heights else 10
# 分段逻辑:结合间距和关键词
paragraphs = []
current_paragraph = []
for i, line in enumerate(sorted_lines):
line_text = line["text"]
current_paragraph.append(line_text)
# 强制分段:如果当前行包含指定关键词,且不是最后一行
force_break = any(word in line_text for word in force_break_words)
if force_break and i < len(sorted_lines) - 1:
paragraphs.append("".join(current_paragraph))
current_paragraph = []
continue
# 按间距分段(最后一行不需要判断)
if i < len(sorted_lines) - 1:
next_line = sorted_lines[i+1]
# 计算当前行与下一行的间距
if is_vertical:
# 竖排:当前行底部y坐标 vs 下一行顶部y坐标
current_bottom = max([line["position"][1], line["position"][3], line["position"][5], line["position"][7]])
next_top = min([next_line["position"][1], next_line["position"][3], next_line["position"][5], next_line["position"][7]])
spacing = next_top - current_bottom
else:
# 横排:当前行右侧x坐标 vs 下一行左侧x坐标
current_right = max([line["position"][0], line["position"][2], line["position"][4], line["position"][6]])
next_left = min([next_line["position"][0], next_line["position"][2], next_line["position"][4], next_line["position"][6]])
spacing = next_left - current_right
# 当间距超过平均行高的N倍时分段
if spacing > avg_line_height * spacing_threshold:
paragraphs.append("".join(current_paragraph))
current_paragraph = []
# 加入最后一段
if current_paragraph:
paragraphs.append("".join(current_paragraph))
return "\n\n".join(paragraphs)
if __name__ == "__main__":
# 调用API
ocr = CommonOcr(img_path=r'C:\Users\ZHANGZHANHUA\PycharmProjects\pythonProject\.venv\example.png')
result = ocr.recognize()
# 格式化(降低阈值+古籍关键词分段)
formatted_text = format_recognition_result(
result,
spacing_threshold=1.2, # 阈值降低,更容易分段
force_break_words=["分", "經", "佛", "爾時"] # 遇到这些词强制分段(根据金刚经特点调整)
)
# 打印结果
print("识别结果:")
print("=" * 50)
print(formatted_text)
print("=" * 50)
# 统计行数
try:
pages = result.get('result', {}).get('pages', [])
line_count = len(pages[0].get('lines', [])) if pages else 0
print(f"识别完成(共{line_count}行文字)")
except:
print("无法统计行数")
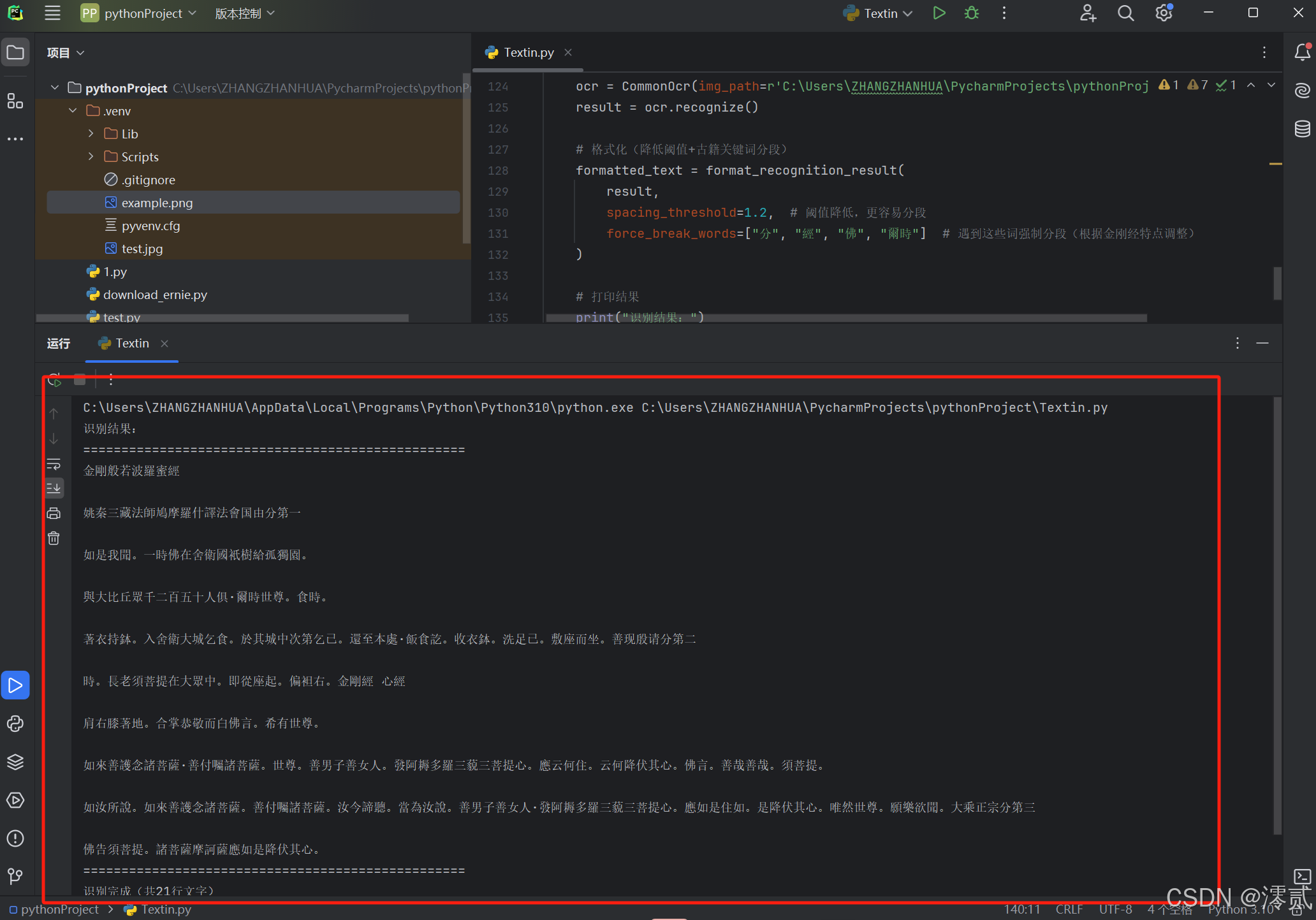
最后 API 也是正确被调用了,输出格式也易于观察,说明 Textin 的本地 API 调用功能也是很不错的
六、总结
适用场景建议
- 企业级用户:推荐
Textin,其高性能处理和行业解决方案能显著提升办公效率 - 开发者:推荐
Textin,API设计简洁且文档完善,可快速集成 - 对识别精度要求极高的场景:建议选择
Textin,其在复杂场景下的准确率优势明显
通过本次全面测试可知,Textin 在功能、性能、API 设计等多个维度上均处于行业领先地位,尤其适合对文档处理效率和精度要求较高的企业和开发者,那么快来使用体验一下吧!


















 349
349




 到【灌水乐园】发言
到【灌水乐园】发言







