



 PFNet是2021年CVPR会议上提出的一种用于伪装对象分割的深度学习模型。该模型借鉴捕食过程,通过定位模块(PM)初步定位目标,随后聚焦模块(FM)细化分割,有效减少假阳性(FP)和假阴性(FN)干扰。实验表明,PFNet能在多个数据集上取得优秀性能,并能以72FPS的速度实时运行。
PFNet是2021年CVPR会议上提出的一种用于伪装对象分割的深度学习模型。该模型借鉴捕食过程,通过定位模块(PM)初步定位目标,随后聚焦模块(FM)细化分割,有效减少假阳性(FP)和假阴性(FN)干扰。实验表明,PFNet能在多个数据集上取得优秀性能,并能以72FPS的速度实时运行。
前言
PFNet来自于CVPR2021的一篇论文(Camouflaged Object Segmentation with Distraction Mining),用于完成伪装对象分割任务。PFNet即定位和聚焦网络,包含两个关键模块:定位模块(PM)和聚焦模块(FM),其设计模仿了自然界中的捕食过程,通过PM先从全局定位猎物的大致位置,再由FM确定猎物的细节信息。实验中,PFNet能够以72FPS的速度实时运行,并且在CHAMELEON、CAMO和COD10K数据集上的效果优于先前效果顶尖的模型。
PFNet的总体结构如下所示:

1. PFNet整体架构
整体架构如上图所示:输入一张RGB三通道彩色图像,先将其送入ResNet-50的backbone提取多尺度特征,然后将四个尺度的特征分别通过四个卷积层进行通道缩减。在最深层特征上使用定位模块PM来粗略定位潜在目标,然后再逐层通过聚焦模块FM细化分割结果,消除FP(假阳)和FN(假阴)的干扰,最终经过上采样后得到预测分割结果。
2. 定位模块(PM)
定位模块PM的结构如下。在输入深层特征
F
F
F后,经过通道注意力模块和空间注意力模块,捕捉通道和空间位置上的远距离依赖关系。假设输入特征图
F
∈
R
C
×
H
×
W
F \in \mathbb R^{C \times H \times W}
F∈RC×H×W,
C
C
C代表输入特征图通道数目,
H
H
H表示特征图高度,
W
W
W表示特征图宽度。首先对
F
F
F进行reshape获得Q、K、V,其中
Q
,
K
,
V
∈
R
C
×
N
{Q, K, V} \in \mathbb R^{C \times N}
Q,K,V∈RC×N,
N
=
H
×
W
N=H \times W
N=H×W为像素数量。对Q和K的转置使用矩阵乘法和softmax归一化计算通道注意力图
X
∈
R
C
×
C
X \in \mathbb R^{C \times C}
X∈RC×C:
x
i
j
=
e
x
p
(
Q
i
:
⋅
K
j
:
)
∑
j
=
1
C
e
x
p
(
Q
i
:
⋅
K
j
:
)
x_{ij}=\frac{exp(Q_{i:} \cdot K_{j:})}{\sum_{j=1}^{C} exp(Q_{i:} \cdot K_{j:})}
xij=∑j=1Cexp(Qi:⋅Kj:)exp(Qi:⋅Kj:)
其中,
Q
i
:
Q_{i:}
Qi:表示矩阵Q的第i行,
x
i
j
x_{ij}
xij表示第j个通道对第i个通道的影响。然后将
x
i
j
x_{ij}
xij与V矩阵进行矩阵乘法,并将结果reshape成
R
C
×
H
×
W
\mathbb R^{C \times H \times W}
RC×H×W。为了增强容错能力,将结果乘以可学习的尺度参数
γ
\gamma
γ,得到最终输出
F
′
∈
R
C
×
H
×
W
F^{'} \in \mathbb R^{C \times H \times W}
F′∈RC×H×W:
F
i
:
′
=
γ
∑
j
=
1
C
(
x
i
j
V
j
:
)
+
F
i
:
F^{'}_{i:}=\gamma \sum_{j=1}^{C}(x_{ij}V_{j:})+F_{i:}
Fi:′=γj=1∑C(xijVj:)+Fi:
将通道注意力模块的输出特征
F
′
F^{'}
F′作为输入,输入到空间注意力模块中。首先使用三个
1
×
1
1\times1
1×1的卷积层得到
Q
′
Q^{'}
Q′,
K
′
K^{'}
K′,
V
′
V^{'}
V′,其中
{
Q
′
,
K
′
}
∈
R
C
8
×
N
\lbrace Q^{'},K^{'} \rbrace \in \mathbb R^{\frac{C}{8} \times N}
{Q′,K′}∈R8C×N,
V
′
∈
R
C
×
N
V^{'} \in \mathbb R^{C \times N}
V′∈RC×N,对
Q
′
Q^{'}
Q′和
K
′
K^{'}
K′的转置使用矩阵乘法,并进行softmax归一化生成空间注意力图
X
′
∈
R
N
×
N
X^{'}\in \mathbb R^{N \times N}
X′∈RN×N:
x
i
j
′
=
e
x
p
(
Q
:
i
′
⋅
K
:
j
′
)
∑
j
=
1
C
e
x
p
(
Q
:
i
′
⋅
K
:
j
′
)
x_{ij}^{'}=\frac{exp(Q_{:i}^{'} \cdot K_{:j}^{'})}{\sum_{j=1}^{C} exp(Q_{:i}^{'} \cdot K_{:j}^{'})}
xij′=∑j=1Cexp(Q:i′⋅K:j′)exp(Q:i′⋅K:j′)
对
V
′
V^{'}
V′和
X
′
X^{'}
X′的转置使用矩阵乘法,将结果reshape为
R
C
×
H
×
W
\mathbb R^{C \times H \times W}
RC×H×W,最终输出表示为:
F
:
i
′
′
=
γ
′
∑
j
=
1
N
(
V
:
j
′
x
j
i
′
)
+
F
:
i
′
F^{''}_{:i}=\gamma^{'} \sum_{j=1}^{N}(V_{:j}^{'}x_{ji}^{'})+F_{:i}^{'}
F:i′′=γ′j=1∑N(V:j′xji′)+F:i′
最后对
F
′
′
F^{''}
F′′进行
7
×
7
7\times7
7×7的卷积,得到目标初始位置图。
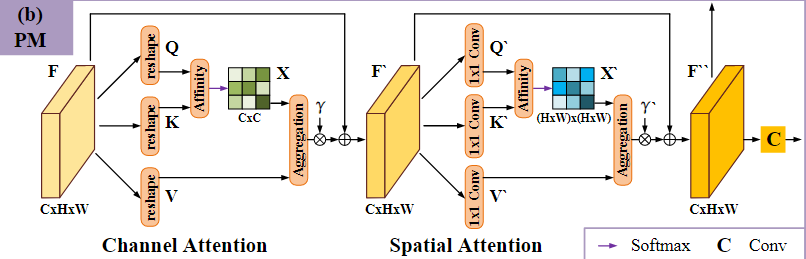
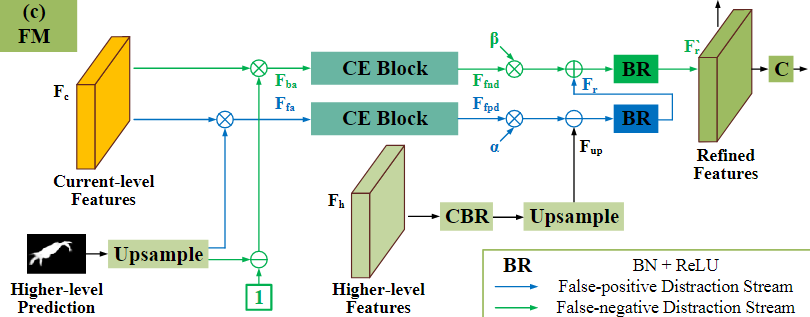
3. 聚焦模块(FM)
由于伪装对象通常与背景具有相似的外观,因此初始预测中会有FP假阳和FN假阴预测。设计使用FM聚焦模块发现和删除这些错误预测。FM模块的结构如下所示。
与之前学习的反向注意力相似,首先对高一层的预测进行上采样,并使用sigmoid进行归一化,将归一化结果与反向结果分别乘以当前尺度的特征图,分别得到前景注意特征
F
f
a
F_{fa}
Ffa和背景注意特征
F
b
a
F_{ba}
Fba,并行输入CE(context exploration)模块,分别发现FP假阳和FN假阴干扰。
CE模块如下图所示。由四个分支组成,每个分支包含一个
3
×
3
3\times 3
3×3卷积用于减少通道数目,一个
k
i
×
k
i
k_i \times k_i
ki×ki卷积用于局部特征提取,一个
3
×
3
3 \times 3
3×3、膨胀因子
r
i
r_i
ri的膨胀卷积用于上下文感知。然后所有四个分支的输出通过
3
×
3
3\times 3
3×3卷积连接和融合。通过这样的设计,CE块获得了在大范围范围内感知丰富上下文的能力,因此可以用于上下文推理和分心发现。

在发现FP和FN干扰后,通过以下方式消除干扰:
F
u
p
=
U
(
C
B
R
(
F
h
)
)
,
F
r
=
B
R
(
F
u
p
−
α
F
f
p
d
)
,
F
r
′
=
B
R
(
F
r
+
β
F
f
n
d
)
,
F_{up}=U(CBR(F_h)),\\ F_r=BR(F_{up}-\alpha F_{fpd}),\\ F_r^{'}=BR(F_r+\beta F_{fnd}),
Fup=U(CBR(Fh)),Fr=BR(Fup−αFfpd),Fr′=BR(Fr+βFfnd),
其中,
F
h
F_h
Fh代表输入的高阶特征,
F
r
′
F_r^{'}
Fr′代表输出的细化特征,在这里,我们使用元素减法操作来抑制模糊背景(即假阳性干扰),并使用元素加法操作来增加缺失的前景(即假阴性干扰)。最后,在精细特征
F
r
′
F_r^{'}
Fr′上加卷积层,得到更精确的预测图。

















 2246
2246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









