




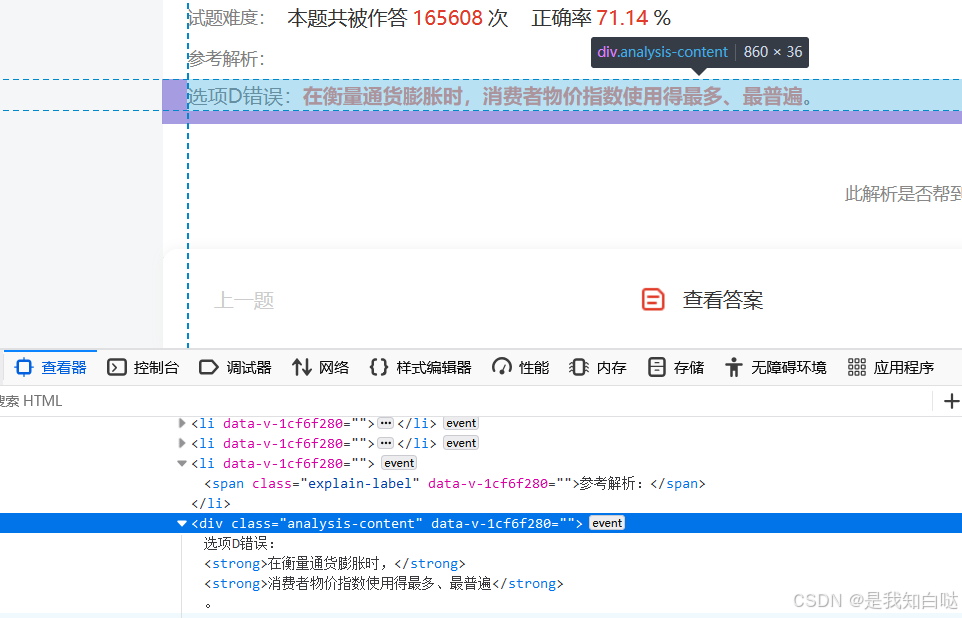
我在提取解析的时候直接选用这段xpath,但是结果只有“选项D错误:”
我们可以看到HTML中,剩下的两句在<strong>标签里
<div data-v-1cf6f280="" class="analysis-content">
选项D错误:
<strong>在衡量通货膨胀时,</strong>
<strong>消费者物价指数使用得最多、最普遍</strong>
。
</div>
只要提取了<div>标签里的所有文本,再拼接,就得到我需要的答案解析了
from bs4 import BeautifulSoup
html = '''
<div data-v-1cf6f280="" class="analysis-content">
选项D错误:
<strong>在衡量通货膨胀时,</strong>
<strong>消费者物价指数使用得最多、最普遍</strong>
。
</div>
'''
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(html, 'html.parser')
# 提取所有文本并拼接
text = soup.div.get_text(separator='', strip=True)
# 打印提取的文本
print(text)
separator = ""用于替换所有换行符和标签之间的分隔符为引号里的内容。strip=True,删除文本两侧多余空格。
运行结果:



















 1716
1716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









