 基于配置的字节流编解码引擎
基于配置的字节流编解码引擎





Boca Codec
📖 简介
Boca Codec 是一个专为 IoT 应用平台设计的二进制报文编解码组件。通过 JSON
格式配置协议解析规则,实现协议解析的配置化管理,包含了编码和解码功能,大幅减少业务开发中报文编解码的开发和维护工作量。
解码(decode):将二进制报文解析为JSON格式的数据,供平台业务系统使用
编码(encode):将平台业务系统的JSON格式数据编码为二进制报文,供设备使用
✨ 核心特性
-
🚀 配置化解析:使用 JSON 配置协议规则,无需编写代码即可完成协议解析
-
📦 多种数据类型支持:支持 BCD、BYTE、BIT、HEX、ASCII、UTF8、UTF16、GBK 等多种协议数据类型
-
🔄 双向编解码:支持上行消息解码(二进制→JSON)和下行消息编码(JSON→二进制)
-
🎯 灵活的节点类型:支持 FIELD、MAP、LIST、CHECK 等多种节点类型,满足复杂协议结构
-
✅ 多种校验方式:支持 BCC(异或校验)、SUM(校验和)、CRC(循环冗余校验)
-
🔧 Spring Boot 集成:开箱即用的 Spring Boot Starter,自动配置规则链加载
-
📊 完善的错误处理:详细的错误码定义,便于问题定位和调试
-
🎨 大端小端支持:支持大端(BIG_END)和小端(LITTLE_END)字节序读取
联系作者
微信:Toonaiveckuu
项目链接
https://github.com/Toonaiveckuu/boca-codec
配置规则文件
在 application.yml 中配置规则文件路径:
iot:
codec:
config:
enable: true
rule-path:
- classpath:rules/protocol-001.json
- classpath:rules/protocol-002.json
使用示例
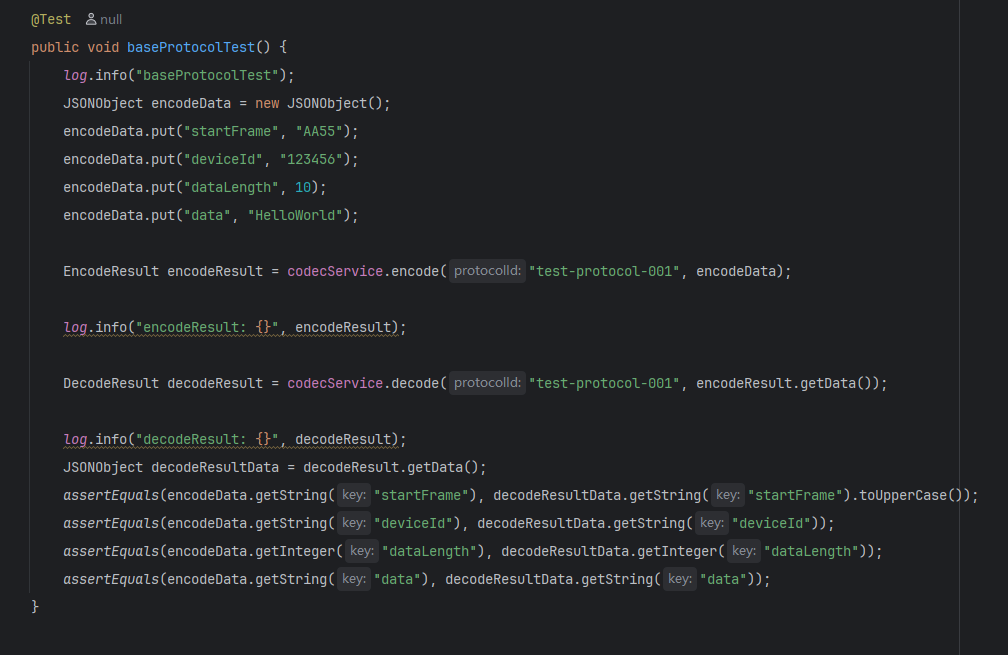
解码示例
@Autowired
private CodecService codecService;
// 解码二进制数据
byte[] binaryData = {0xAA, 0x55, 0x01, 0x02, ...};
DecodeResult result = codecService.decode("protocol-001", binaryData);
if(result.
getSuccess()){
JSONObject data = result.getData();
String deviceId = result.getDeviceId();
// 处理解码后的数据
}else{
ErrorInfo error = result.getError();
// 处理错误信息
}
编码示例
@Autowired
private CodecService codecService;
// 编码 JSON 数据为二进制
JSONObject data = new JSONObject();
data.
put("deviceId","123456");
data.
put("commandCode","00");
data.
put("deviceType",1);
EncodeResult result = codecService.encode("protocol-001", data);
if(result.
getSuccess()){
byte[] binaryData = result.getData();
// 发送二进制数据到设备
}else{
ErrorInfo error = result.getError();
// 处理错误信息
}
📁 项目结构
boca-codec/
├── boca-codec-core/ # 核心库(编解码引擎)
│ ├── pom.xml
│ └── src/
│ ├── main/
│ │ ├── java/com/boca/codec/
│ │ │ ├── constant/ # 常量定义(枚举类)
│ │ │ ├── core/ # 核心编解码实现
│ │ │ ├── exception/ # 异常定义
│ │ │ ├── node/ # 节点类型定义
│ │ │ ├── rule/ # 规则链和规则引擎
│ │ │ ├── service/ # 服务层(CodecService)
│ │ │ └── utils/ # 工具类
│ │ └── scala/com/boca/codec/utils/
│ │ └── SCodecUtils.scala # Scala 工具类(封装 scodec 库)
├── boca-codec-example/ # 示例与测试模块
│ ├── pom.xml
│ └── src/
│ ├── main/resources/archetype-resources/...
│ └── test/
│ ├── java/com/sdsat/codec/... # 示例单元 & 集成测试
│ └── resources/ # 示例协议、规则配置
├── pom.xml # 根聚合 POM(同时管理子模块)
└── README.md # 项目文档
子模块说明:
-
boca-codec-core:核心依赖,面向业务系统提供编解码能力。生产环境只需引入该模块。 -
boca-codec-example:示例与测试集合,内置协议样例、集成测试和临时配置,方便快速验证与二次开发。
开发提示:
-
项目采用 Java + Scala 混合开发,Scala 仅用于 BitVector 工具层。
-
boca-codec-core已配置scala-maven-plugin,Maven 会自动处理 Scala 源码编译,无需手动操作。 -
示例协议与测试资源集中放在
boca-codec-example/src/test/resources,方便扩展或自定义规则。
🔧 构建项目
# 克隆项目
git clone https://github.com/your-username/boca-codec.git
cd boca-codec
# 安装核心模块
mvn clean install -pl boca-codec-core -am
# 运行示例与测试
mvn test -pl boca-codec-example
# 打包(同时构建所有模块)
mvn clean package
📝 规则配置说明
协议解析规则使用 JSON 格式配置,详细说明请参考下方文档。
基础规则链示例:
{
"description": "基础测试协议规则链(FIELD和CHECK节点)",
"protocolId": "test-protocol-001",
"version": "1.0",
"deviceIdNodeName": "deviceId",
"firstNodeName": "startFrame",
"rules": {
"startFrame": {
"description": "起始域(FIELD节点示例)",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BCD",
"businessDataType": "STRING",
"defaultValue": "AA55",
"adjustment": 0,
"nextNodeName": "deviceId"
},
"deviceId": {
"description": "设备ID",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 3,
"readOrder": "BIG_END",
"protocolDataType": "BCD",
"businessDataType": "STRING",
"defaultValue": "",
"adjustment": 0,
"nextNodeName": "dataLength"
},
"dataLength": {
"description": "数据长度",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0,
"adjustment": 0,
"nextNodeName": "data"
},
"data": {
"description": "数据内容",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 10,
"readOrder": "BIG_END",
"protocolDataType": "ASCII",
"businessDataType": "STRING",
"defaultValue": "",
"adjustment": 0,
"nextNodeName": "check"
},
"check": {
"description": "校验位(CHECK节点示例)",
"nodeType": "CHECK",
"analyticalUnit": "BYTE",
"length": 1,
"checkType": "SUM",
"startIndexFromTop": 0,
"endIndexFromCheck": -1
}
}
}
完整的规则链示例:
{
"description": "完整测试协议规则链(包含所有节点类型)",
"protocolId": "test-protocol-complete",
"version": "1.0",
"deviceIdNodeName": "deviceId",
"firstNodeName": "startFrame",
"rules": {
"startFrame": {
"description": "起始域(FIELD节点示例)",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BCD",
"businessDataType": "STRING",
"defaultValue": "AA55",
"adjustment": 0,
"nextNodeName": "deviceId"
},
"deviceId": {
"description": "设备ID",
"nodeType": "FIELD",
"analyticalUnit": "BIT",
"length": 13,
"protocolDataType": "BIT",
"businessDataType": "STRING",
"fillLength": true,
"defaultValue": "",
"adjustment": 0,
"nextNodeName": "commandCode"
},
"commandCode": {
"description": "业务码(用于MAP节点参考)",
"nodeType": "FIELD",
"analyticalUnit": "BIT",
"length": 3,
"protocolDataType": "BIT",
"businessDataType": "INT",
"defaultValue": 0,
"adjustment": 0,
"nextNodeName": "businessMap"
},
"businessMap": {
"description": "业务映射(MAP节点示例)",
"nodeType": "MAP",
"analyticalUnit": "BYTE",
"keySourceNodeName": "commandCode",
"ruleLinks": {
"1": {
"description": "业务类型1",
"firstNodeName": "type1Field",
"rules": {
"type1Field": {
"description": "类型1字段",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0
}
}
},
"2": {
"description": "业务类型2",
"firstNodeName": "type2Field",
"rules": {
"type2Field": {
"description": "类型2字段",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0
}
}
}
},
"nextNodeName": "itemCount"
},
"itemCount": {
"description": "列表项数量(用于LIST节点参考)",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 1,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0,
"adjustment": 0,
"nextNodeName": "itemList"
},
"itemList": {
"description": "列表数据(LIST节点示例)",
"nodeType": "LIST",
"analyticalUnit": "BYTE",
"cycleSourceNodeName": "itemCount",
"adjustment": 0,
"ruleLink": {
"description": "列表项规则链",
"firstNodeName": "itemId",
"rules": {
"itemId": {
"description": "列表项ID",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 1,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0,
"adjustment": 0,
"nextNodeName": "itemValue"
},
"itemValue": {
"description": "列表项值",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0
}
}
},
"nextNodeName": "paddingField"
},
"paddingField": {
"description": "填充字段(PADDING节点示例)",
"nodeType": "PADDING",
"analyticalUnit": "BYTE",
"length": 4,
"nextNodeName": "includeField"
},
"includeField": {
"description": "引用字段(INCLUDE节点示例)",
"nodeType": "INCLUDE",
"ruleName": "test-include-sub",
"nextNodeName": "check"
},
"check": {
"description": "校验位(CHECK节点示例)",
"nodeType": "CHECK",
"analyticalUnit": "BYTE",
"length": 1,
"checkType": "SUM",
"startIndexFromTop": 0,
"endIndexFromCheck": -1
}
}
}
引用规则链示例
{
"description": "被引用的子规则链(用于INCLUDE节点测试)",
"protocolId": "test-include-sub",
"version": "1.0",
"firstNodeName": "subField1",
"rules": {
"subField1": {
"description": "子字段1",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0,
"adjustment": 0,
"nextNodeName": "subField2"
},
"subField2": {
"description": "子字段2",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BYTE",
"businessDataType": "INT",
"defaultValue": 0
}
}
}
相关概念介绍
RuleLink
RuleLink 是本编解码组件中核心的协议解析结构,英文称为“规则链”。它的主要作用是:将协议的各个解析步骤通过节点(Node)形式进行有序串联,按照设定的次序和条件执行,从而实现复杂协议格式的灵活、可配置解析和编码。
作用
-
解耦协议描述与编解码实现:业务只需通过 JSON 配置协议规则链,无需关注底层解析流程。
-
可视化、可维护:通过规则链,协议结构一目了然,方便后续维护和扩展。
-
灵活支持复杂协议:通过多种节点类型(如 FIELD、CHECK、INCLUDE、MAP、LIST、PADDING 等),支持嵌套、校验、条件分支、自定义逻辑等复杂解析场景。
-
高复用性:子规则链可通过 INCLUDE 节点复用,减少重复配置。
工作方式
-
加载阶段:系统启动时,将 JSON 配置文件解析成内存中的规则链对象(RuleLink 实例)。
-
链式解析:每条协议数据(如一帧报文)按规则链首节点(
firstNodeName)开始,依次或按条件跳转到下一个节点,直至链尾。 -
节点处理:每个节点根据配置类型(如字段提取、校验、嵌入子链、条件判断等)执行特定操作,生成或转换相应业务数据。
-
数据转换:支持多种协议数据类型(BYTE、BCD、HEX、BIT、ASCII、UTF8等)和业务数据类型(STRING、INT、LONG等)之间的自动转换。
-
校验与分支:CHECK/JUDGE/INCLUDE等特殊节点可实现校验和分支解析,满足校验和、硬编码检查、多级嵌套等协议需求。
-
输出版/编码版:同一规则链可既用于解码(binary to json),也用于编码(json to binary),保证报文读写一致性。
典型节点类型示例
-
FIELD:普通字段节点,提取并转换报文片段。 -
CHECK:校验节点,如和校验、CRC 校验。 -
INCLUDE:引用/嵌入其他子规则链,实现复用与分层。 -
LIST:列表节点,根据某变量决定是否进行多条规则集合的解析。 -
MAP:映射节点,用于描述重复解析的规则集合。 -
PADDING:填充节点,用于协议中的补齐、占位等需求。
节点类型详解
所有节点类型都继承自 Node 基类,包含以下公共属性:
| 属性名 | 类型 | 必填 | 说明 |
|------------------|--------|----|-----------------------------------------------------------|
| description | String | 否 | 节点描述信息,用于文档说明 |
| nodeType | String | 是 | 节点类型,可选值:FIELD、CHECK、MAP、LIST、INCLUDE、PADDING |
| analyticalUnit | String | 是* | 解析单位,可选值:BYTE(字节)、BIT(位)。部分节点类型(如 INCLUDE)可不填 |
| nextNodeName | String | 否 | 下一个节点的名称,用于链式连接。如果为空或不存在,表示当前节点为链尾 |
FIELD 节点
作用:最基础的字段节点,用于提取并转换报文中的字段数据。支持多种协议数据类型和业务数据类型之间的转换。
配置示例:
{
"nodeName": {
"description": "字段描述",
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"readOrder": "BIG_END",
"protocolDataType": "BCD",
"businessDataType": "STRING",
"defaultValue": "AA55",
"adjustment": 0,
"fillLength": false,
"decodeFormula": null,
"afterDecodeFunction": null,
"lengthSourceNodeName": null,
"nextNodeName": "nextNode"
}
}
参数说明:
| 参数名 | 类型 | 必填 | 说明 |
|------------------------|---------|----|----------------------------------------------------------------------------------------|
| length | Integer | 是* | 字段长度(单位由 analyticalUnit 决定)。如果设置了 lengthSourceNodeName,则此参数可选 |
| lengthSourceNodeName | String | 否 | 动态长度参考节点名称。参考节点的解析值将作为当前节点的长度值。注意:参考节点必须是 FIELD 类型,业务数据类型必须为数值型,且必须在当前节点之前配置 |
| readOrder | String | 否 | 字节读取顺序,可选值:BIG_END(大端序)、LITTLE_END(小端序)。默认 BIG_END |
| protocolDataType | String | 是 | 协议数据类型,可选值:BCD、BYTE、C_BYTE、C_BIT、BIT、HEX、ASCII、UTF8、UTF16、GBK |
| businessDataType | String | 是 | 业务数据类型,可选值:STRING、INT、LONG、FLOAT |
| defaultValue | Object | 否 | 默认值。当解码时数据为空或编码时字段缺失时使用 |
| adjustment | Integer | 否 | 调整量。解码后的值会加上此调整量,编码前会减去此调整量 |
| fillLength | Boolean | 否 | 是否需要补位。编码时使用,当 analyticalUnit 为 BIT 时,在左侧补0BIT,当为BYTE时,在左侧补0字节 |
| decodeFormula | String | 否 | 解码值的运算公式。支持加减乘除余及大中小括号,%s 为占位符(可以有多个),表示当前字段的值。解码阶段,协议数据转换后的业务数据(不包括默认值)会经过此公式运算后再输出 |
| afterDecodeFunction | String | 否 | 全部解码后的计算公式。使用 JavaScript 函数表达式,可以访问所有已解析的字段值 |
使用场景:
-
提取固定长度的字段(如起始域、设备ID、命令码等)
-
提取动态长度的字段(通过
lengthSourceNodeName引用长度字段) -
数据类型转换(如 BCD 码转字符串、字节转整数等)
-
数值调整(如温度值需要减去 40 的偏移量)
CHECK 节点
作用:校验节点,用于验证报文的完整性。支持多种校验算法(BCC 异或校验、SUM 校验和、CRC 循环冗余校验)。
配置示例:
{
"check": {
"description": "校验位",
"nodeType": "CHECK",
"analyticalUnit": "BYTE",
"length": 1,
"checkType": "SUM",
"startIndexFromTop": 0,
"endIndexFromCheck": -1,
"nextNodeName": null
}
}
参数说明:
| 参数名 | 类型 | 必填 | 说明 |
|---------------------|---------|----|-----------------------------------------------------------------|
| length | Integer | 是 | 校验位长度(单位由 analyticalUnit 决定) |
| checkType | String | 是 | 校验类型,可选值:BCC(异或校验)、SUM(校验和)、CRC(循环冗余校验) |
| startIndexFromTop | Integer | 是 | 校验计算的起始位置。0 表示从报文开头开始计算 |
| endIndexFromCheck | Integer | 是 | 校验计算的截止位置。-1 表示到校验位之前(不包含校验位本身),0 表示到校验位之前,正数表示从校验位向前偏移的字节数 |
| insertLocation | Integer | 否 | 插入位置。编码时,如果校验位不在报文末尾,可通过此参数指定插入位置 |
使用场景:
-
报文完整性校验(防止数据传输错误)
-
多种校验算法支持(满足不同设备厂商的协议要求)
-
灵活的校验范围配置(支持从任意位置开始计算校验值)
MAP 节点
作用:映射节点,用于根据某个字段的值(如命令码)选择不同的解析规则链。实现条件分支解析。
配置示例:
{
"businessMap": {
"description": "业务映射",
"nodeType": "MAP",
"analyticalUnit": "BYTE",
"keySourceNodeName": "commandCode",
"ruleLinks": {
"1": {
"description": "业务类型1",
"firstNodeName": "type1Field",
"rules": {
"type1Field": {
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"protocolDataType": "BYTE",
"businessDataType": "INT"
}
}
},
"2": {
"description": "业务类型2",
"firstNodeName": "type2Field",
"rules": {
"type2Field": {
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"protocolDataType": "BYTE",
"businessDataType": "INT"
}
}
}
},
"nextNodeName": "nextNode"
}
}
参数说明:
| 参数名 | 类型 | 必填 | 说明 |
|---------------------|--------------|----|-------------------------------------------------------------------|
| keySourceNodeName | String/Array | 是 | 参考节点名称(单个)或参考节点名称数组(多个)。多个参考节点时,会将它们的解析值组合成 key。该 key 将用于查找对应的规则链 |
| ruleLinks | Object | 是 | 规则链映射表。key 为参考节点的可能取值(字符串形式),value 为对应的子规则链配置 |
使用场景:
-
根据命令码选择不同的数据格式解析
-
根据设备类型选择不同的协议结构
-
实现协议的条件分支逻辑
注意事项:
-
keySourceNodeName指定的节点必须在 MAP 节点之前配置 -
ruleLinks中的 key 必须是字符串类型(即使参考节点是数值类型) -
如果参考节点的值在
ruleLinks中找不到对应的 key,解析会失败
LIST 节点
作用:列表节点,用于解析重复出现的报文结构。根据某个字段的值(如列表项数量)决定循环解析的次数。
配置示例:
{
"itemList": {
"description": "列表数据",
"nodeType": "LIST",
"analyticalUnit": "BYTE",
"cycleSourceNodeName": "itemCount",
"cycleDefaultValue": 0,
"adjustment": 0,
"ruleLink": {
"description": "列表项规则链",
"firstNodeName": "itemId",
"rules": {
"itemId": {
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 1,
"protocolDataType": "BYTE",
"businessDataType": "INT",
"nextNodeName": "itemValue"
},
"itemValue": {
"nodeType": "FIELD",
"analyticalUnit": "BYTE",
"length": 2,
"protocolDataType": "BYTE",
"businessDataType": "INT"
}
}
},
"nextNodeName": "nextNode"
}
}
参数说明:
| 参数名 | 类型 | 必填 | 说明 |
|-----------------------|---------|----|---------------------------------------------------------|
| cycleSourceNodeName | String | 是* | 循环周期参考节点名称。该节点的解析值将作为循环次数。如果未设置,则使用 cycleDefaultValue |
| cycleDefaultValue | Integer | 否 | 默认循环周期。当 cycleSourceNodeName 未设置或解析失败时使用 |
| adjustment | Integer | 否 | 调整量。循环次数 = 参考节点值 + 调整量 |
| ruleLink | Object | 是 | 列表项的规则链配置。包含 firstNodeName 和 rules,定义单个列表项的解析规则 |
使用场景:
-
解析可变长度的数据列表(如传感器数据列表、设备状态列表等)
-
根据数量字段动态解析多个相同结构的数据项
-
支持嵌套列表(列表项中可以包含其他复杂节点)
注意事项:
-
cycleSourceNodeName指定的节点必须在 LIST 节点之前配置 -
循环次数 = 参考节点值 +
adjustment,如果结果小于等于 0,则不进行循环解析 -
列表项规则链中的节点名称在当前规则链中必须唯一
INCLUDE 节点
作用:引用节点,用于引用其他已定义的规则链。实现规则链的复用和分层组织。
配置示例:
{
"includeField": {
"description": "引用字段",
"nodeType": "INCLUDE",
"ruleName": "test-include-sub",
"nextNodeName": "nextNode"
}
}
参数说明:
| 参数名 | 类型 | 必填 | 说明 |
|------------|--------|----|---------------------------------------|
| ruleName | String | 是 | 被引用的规则链的 protocolId。该规则链必须在配置文件中已定义 |
使用场景:
-
复用公共的协议片段(如公共的头部结构、尾部结构等)
-
分层组织复杂协议(将协议拆分为多个子规则链,通过 INCLUDE 组合)
-
减少重复配置,提高可维护性
注意事项:
-
被引用的规则链必须在配置文件中先定义(可以在同一个文件或其他配置文件中)
-
被引用的规则链不能形成循环引用(A 引用 B,B 引用 A)
-
INCLUDE 节点会将被引用规则链的所有节点嵌入到当前规则链中
PADDING 节点
作用:填充节点,用于在报文中插入固定长度的填充数据。常用于协议对齐、占位等需求。
配置示例:
{
"paddingField": {
"description": "填充字段",
"nodeType": "PADDING",
"analyticalUnit": "BYTE",
"length": 4,
"contentUnit": "00",
"nextNodeName": "nextNode"
}
}
参数说明:
| 参数名 | 类型 | 必填 | 说明 |
|---------------|---------|----|------------------------------------|
| length | Integer | 是 | 填充长度(单位由 analyticalUnit 决定) |
| contentUnit | String | 否 | 填充内容。如果未设置,默认填充 0x00(字节)或 0(位) |
使用场景:
-
协议对齐(将数据对齐到固定字节边界)
-
占位符(为未来扩展预留空间)
-
固定长度填充(满足某些设备对报文长度的要求)
注意事项:
-
PADDING 节点在解码时会跳过指定长度的数据,不产生业务数据
-
PADDING 节点在编码时会插入指定长度的填充数据
-
contentUnit可以是十六进制字符串(如"FF")或二进制字符串(如"11111111")


















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











