




 博客探讨了在InnoDB存储引擎中,聚集索引与普通索引对查询效率的影响。通过示例说明了当使用普通索引进行查询时,需要通过主键二次查找,而全量搜索聚集索引可能更快。文章还提到了索引结构,强调了优化查询路径对于提高数据库性能的重要性。
博客探讨了在InnoDB存储引擎中,聚集索引与普通索引对查询效率的影响。通过示例说明了当使用普通索引进行查询时,需要通过主键二次查找,而全量搜索聚集索引可能更快。文章还提到了索引结构,强调了优化查询路径对于提高数据库性能的重要性。
表结构与数据
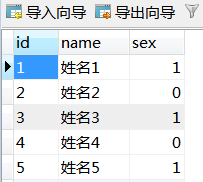
id为主键,id为奇数sex=1,id为偶数sex=0
sex=0,50000条数据;sex=1,50000条数据
CREATE TABLE `people` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`sex` tinyint(1) unsigned DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_initData`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<=100000 DO
INSERT INTO people(name, sex) VALUES(CONCAT('姓名',i),0);
SET i = i+1;
END WHILE;
END
CALL proc_initData();
UPDATE people SET sex = 1 WHERE MOD(id,2) = 1;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











