







目录
鸢尾花数据集的特征变换是指对原始数据集中的特征进行一系列的处理和转换,以适应机器学习模型的输入要求。该数据集原本包含四个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度,这些特征都是数值型的,且以厘米为单位。然而,在实际应用中,原始特征可能无法满足模型的特定需求,因此需要进行特征变换。特征变换可以包括数据规范化、标准化、归一化等操作,旨在消除不同特征之间的量纲差异,提高模型的收敛速度和性能。通过特征变换,可以使数据更加适合机器学习算法的处理,从而提高模型的准确性和稳定性。
在鸢尾花数据集中,特征变换还可以涉及特征选择、特征提取或构造等高级操作。特征选择是根据相关性和重要性筛选出最有价值的特征,以减少模型的复杂度并提高泛化能力。特征提取则是通过统计分析、降维技术(如PCA)等方式生成新的特征,这些新特征能够更全面地反映数据的内在结构和信息。特征构造则是通过特征交叉、组合等方式生成新的特征,以增加模型的表达能力。这些高级的特征变换操作可以进一步提升机器学习模型的性能,使其能够更好地处理复杂的分类任务。在鸢尾花数据集的案例中,虽然原始特征已经足够描述样本,但在实际应用中,特征变换往往是提高模型性能的关键步骤之一。
一、数据集下载
iris.csv(iris数据集、鸢尾花数据集)资源-优快云文库![]() https://download.youkuaiyun.com/download/Z0412_J0103/90215255
https://download.youkuaiyun.com/download/Z0412_J0103/90215255
二、本文代码下载
鸢尾花数据集的特征变换python代码资源-优快云文库![]() https://download.youkuaiyun.com/download/Z0412_J0103/90244752
https://download.youkuaiyun.com/download/Z0412_J0103/90244752
三、特征变换
3.1 定义
特征变换(Feature Transformation)是指在机器学习和数据预处理阶段,对原始数据集中的特征进行一系列数学或统计上的转换和处理,以生成新的特征或改善现有特征的表达形式。这种变换旨在提高数据的质量、增强模型的学习能力,以及优化模型的性能。
3.2 好处
- 改善数据分布:原始数据可能具有不同的量纲、分布不均或存在噪声。特征变换可以通过标准化、归一化、平滑等处理,改善数据的分布特性,使得数据更适合机器学习算法的处理。
- 提高模型性能:某些机器学习算法对数据的尺度、分布或形状敏感。通过特征变换,可以消除这些敏感性,提高模型的收敛速度、准确性和稳定性。例如,线性回归模型在数据标准化后通常会有更好的表现。
- 降低维度:高维数据可能导致计算复杂度高、模型过拟合等问题。特征变换,如主成分分析(PCA)、线性判别分析(LDA)等降维技术,可以在保留数据主要信息的同时,降低数据的维度,从而简化模型、减少计算量并提高泛化能力。
- 增强特征表达能力:原始特征可能无法充分表达数据的内在规律和模式。通过特征变换,可以生成新的特征,这些新特征能够更全面地反映数据的特性,增强模型的表达能力。例如,通过多项式特征变换,可以将线性不可分的数据转换为线性可分的形式。
- 处理非线性关系:许多实际问题中的数据存在非线性关系。特征变换,如核方法(Kernel Methods),可以将原始数据映射到高维空间,使其在高维空间中变得线性可分,从而处理非线性问题。
3.3 数据标准化变换
3.3.1 定义
数据标准化通常指的是将数据按照一定的规则进行转换,使得转换后的数据具有特定的属性,如均值为0,标准差为1。这有助于消除不同特征之间的量纲差异,使得它们在数值上具有可比性。
好处:
- 消除量纲影响,使得不同特征之间可以直接进行比较和计算。
- 提高算法性能,使得机器学习算法更加稳定和高效。
- 避免特征权重偏差,防止某个特征的取值范围远大于其他特征时,在计算距离或权重时占据主导地位。
3.3.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 读取鸢尾花数据集
Iris = pd.read_csv("D:/iris.csv")
iris = Iris.drop(["Id", "Species"], axis = 1)
print(iris.head(3))
# 数据标准化转化
data_scale1 = preprocessing.scale(iris, with_mean = True, with_std = False)
data_scale2 = preprocessing.scale(iris, with_mean = True, with_std = True)
data_scale3 = preprocessing.StandardScaler(with_mean = True, with_std = True).fit_transform(iris)
labs = iris.columns.values
plt.figure(figsize = (15,10))
plt.subplot(2,2,1)
plt.boxplot(iris.values, notch = True, labels = labs)
plt.grid()
plt.title("原数据")
plt.subplot(2,2,2)
plt.boxplot(data_scale1, notch = True, labels = labs)
plt.grid()
plt.title("with_mean = True, with_std = False")
plt.subplot(2,2,3)
plt.boxplot(data_scale2, notch = True, labels = labs)
plt.grid()
plt.title("with_mean = True, with_std = True")
plt.subplot(2,2,4)
plt.boxplot(data_scale3, notch = True, labels = labs)
plt.grid()
plt.title("with_mean = True, with_std = True")
plt.subplots_adjust(wspace = 0.1)
plt.show()
3.3.3 代码解析
- 数据标准化:
data_scale3 = preprocessing.StandardScaler(with_mean=True,with_std=True).fit_transform(iris)StandardScaler是scikit-learn中用于数据标准化的类。with_mean=True表示在标准化过程中会减去均值(默认行为,此参数其实可以省略)。with_std=True表示在标准化过程中会除以标准差(同样是默认行为,此参数也可以省略)。fit_transform(iris)方法首先计算iris数据集的均值和标准差,然后使用这些参数将数据集标准化,使得每个特征的均值为0,标准差为1。data_scale3是标准化后的数据。
- 获取数据集的特征标签:
labs = iris.columns.values- 这行代码假设
iris是一个pandas的DataFrame对象。 .columns.values获取数据集中所有特征的名称,并将它们存储在labs变量中。
- 这行代码假设
- 绘制箱线图:
plt.boxplot(iris.values, notch=True, labels=labs)plt.boxplot是matplotlib库中用于绘制箱线图的函数。iris.values获取iris数据集中的数值数据(即特征值),不包括索引或行标签。notch=True表示箱线图的箱体将有一个缺口,这通常用于表示对中位数置信区间的估计。labels=labs为箱线图的每个箱体设置标签,这些标签是之前从iris数据集中获取的特征名称。
3.3.4 结果展示
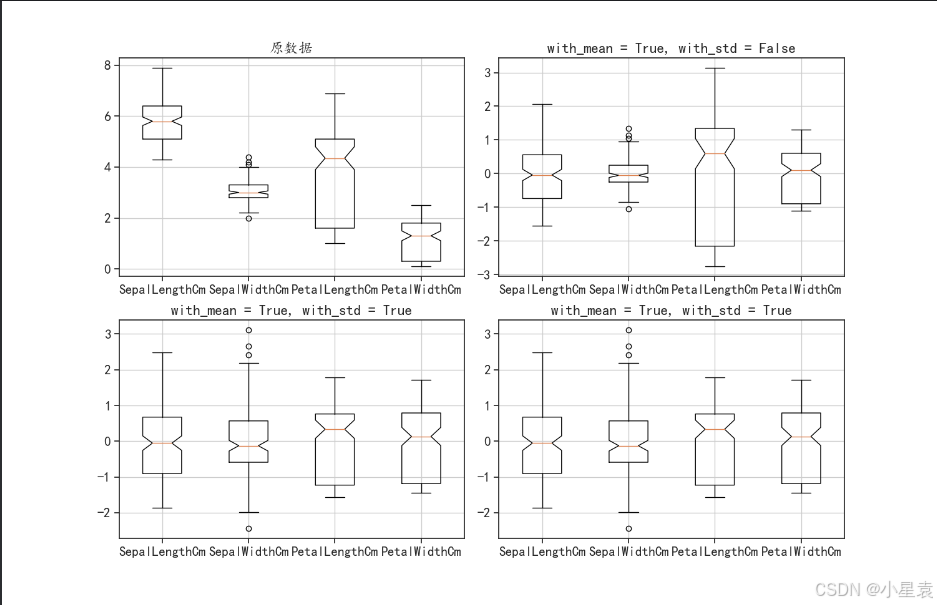
3.4 min-max标准化变换
3.4.1 定义
Min-Max标准化是一种线性变换方法,用于将数据缩放到一个固定区间(通常是[0,1])。它通过公式 x_new = (x - x_min) / (x_max - x_min) 实现,其中 x_min 和 x_max 分别为原始数据的最小值和最大值。
好处:
- 将数据映射到统一的尺度上,便于比较和计算。
- 适用于需要将数据限制在特定区间内的场景。
3.4.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 读取鸢尾花数据集
Iris = pd.read_csv("D:/iris.csv")
iris = Iris.drop(["Id", "Species"], axis = 1)
print(iris.head(3))
# min-max标准化变换
data_min1 = preprocessing.MinMaxScaler(feature_range = (0, 1)).fit_transform(iris)
data_min2 = preprocessing.MinMaxScaler(feature_range = (1, 10)).fit_transform(iris)
labs = iris.columns.values
plt.figure(figsize = (25,10))
plt.subplot(1, 3, 1)
plt.boxplot(iris.values, notch = True, labels = labs)
plt.grid()
plt.title("原数据")
plt.subplot(1, 3, 2)
plt.boxplot(data_min1, notch = True, labels = labs)
plt.grid()
plt.title("feature_range = (0, 1)")
plt.subplot(1, 3, 3)
plt.boxplot(data_min2, notch = True, labels = labs)
plt.grid()
plt.title("feature_range = (1, 10)")
plt.subplots_adjust(wspace = 0.1)
plt.show()3.4.3 代码解析
data_min1 = preprocessing.MinMaxScaler(feature_range = (0, 1)).fit_transform(iris)
MinMaxScaler是scikit-learn中用于min-max标准化的类。它将所有特征缩放到给定的最小值和最大值之间,默认是0到1。feature_range=(0, 1)参数指定了缩放的范围,这里设置为0到1,意味着标准化后的数据将落在这个区间内。fit_transform(iris)方法首先计算iris数据集中每个特征的最小值和最大值,然后使用这些参数将数据集进行min-max标准化。fit部分计算参数(最小值和最大值),transform部分应用这些参数进行转换。data_min1是标准化后的数据,它是一个二维数组(或稀疏矩阵),其中包含了缩放后的特征值。
3.4.4 结果展示
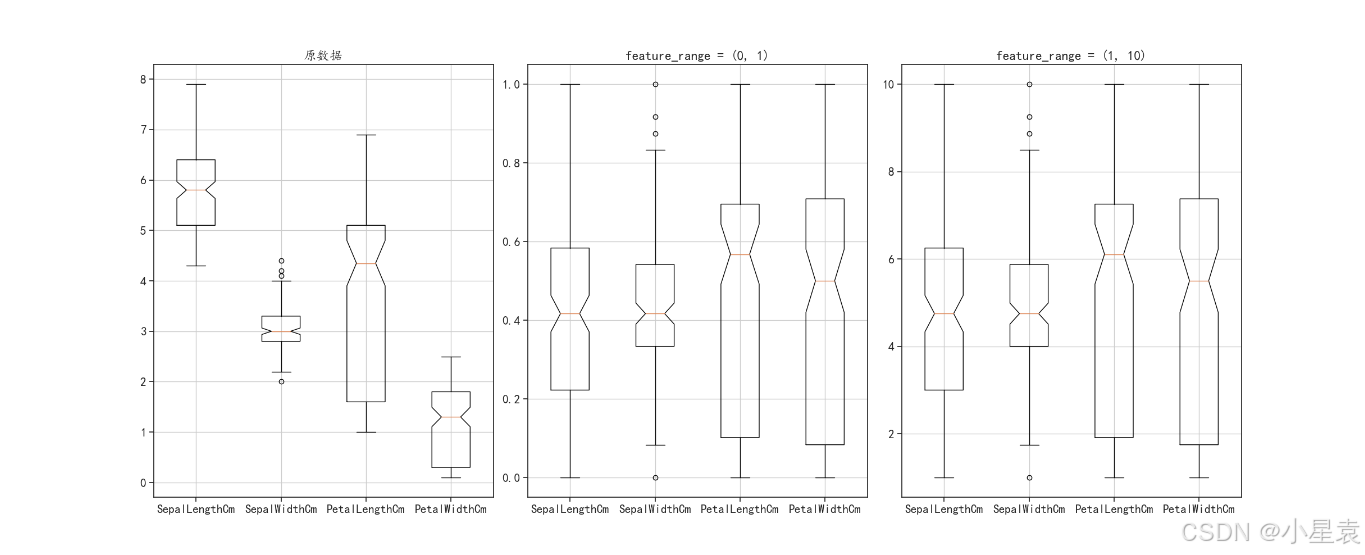
3.5 MaxAbsScaler标准化变换
3.5.1 定义
MaxAbsScaler将数据缩放到最大绝对值为1。这种变换对于已经中心化的数据或稀疏数据特别有效。
好处:
- 保持数据的稀疏性,这对于某些机器学习算法(如Lasso回归)来说非常重要。
- 使数据具有统一的尺度,提高算法的准确性。
3.5.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 读取鸢尾花数据集
Iris = pd.read_csv("D:/iris.csv")
iris = Iris.drop(["Id", "Species"], axis = 1)
print(iris.head(3))
# MaxAbsScaler变换
maxabs = preprocessing.MaxAbsScaler().fit_transform(iris)
labs = iris.columns.values
plt.figure(figsize = (15,6))
plt.subplot(1, 2, 1)
plt.boxplot(iris.values, notch = True, labels = labs)
plt.grid()
plt.title("原数据")
plt.subplot(1, 2, 2)
plt.boxplot(maxabs, notch = True, labels = labs)
plt.grid()
plt.title("MaxAbsScaler")
plt.show()3.5.3 代码解析
maxabs = preprocessing.MaxAbsScaler().fit_transform(iris)
preprocessing:这是scikit-learn库中负责数据预处理的模块。它提供了多种方法,用于标准化、归一化、编码标签等。
MaxAbsScaler:这是preprocessing模块中的一个类,用于缩放数据,使得每个特征的最大绝对值变为1。换句话说,它将每个特征的值除以该特征的最大绝对值,从而得到新的特征值。这种方法保留了数据的稀疏性(即零值不会改变),并且对于具有不同量纲的特征特别有用,因为它将所有特征缩放到相同的尺度上。
.fit_transform(iris):这个方法是MaxAbsScaler类的一个组合方法,它首先调用.fit()方法来计算数据iris中每个特征的最大绝对值,然后调用.transform()方法将这些特征值除以它们各自的最大绝对值,从而得到缩放后的数据。iris是一个数据集,通常指的是鸢尾花数据集,它是一个常用的多变量数据集,用于机器学习和统计学中的分类问题。
.fit(iris):计算iris数据集中每个特征的最大绝对值。.transform(iris):使用.fit()方法中找到的最大绝对值来缩放iris数据集中的每个特征。
maxabs:这是缩放后的数据集的变量名。执行这行代码后,maxabs将包含iris数据集经过MaxAbsScaler缩放后的版本。
3.5.4 结果展示
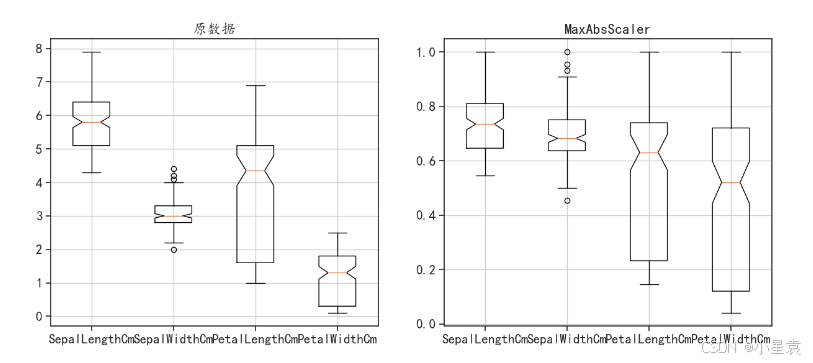
3.6 变换后数据分布
3.6.1 定义
变换后数据分布指的是经过特征变换后,数据在特征空间中的分布形态。
好处:
- 改善数据的分布特性,使其更符合机器学习算法的假设和要求。
- 提高模型的准确性和泛化能力。
3.6.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 读取鸢尾花数据集
Iris = pd.read_csv("D:/iris.csv")
iris = Iris.drop(["Id", "Species"], axis = 1)
print(iris.head(3))
# 变换后
data_robs = preprocessing.RobustScaler(with_centering = True, with_scaling = True).fit_transform(iris)
data_scale2 = preprocessing.scale(iris, with_mean = True, with_std = True)
labs = iris.columns.values
plt.figure(figsize = (30, 10))
plt.subplot(1, 3, 1)
plt.boxplot(iris.values, notch = True, labels = labs)
plt.grid()
plt.title("原数据")
plt.subplot(1, 3, 2)
plt.boxplot(data_scale2, notch = True, labels = labs)
plt.grid()
plt.title("Scale")
plt.subplot(1, 3, 3)
plt.boxplot(data_robs, notch = True, labels = labs)
plt.grid()
plt.title("Robust")
plt.subplots_adjust(wspace = 0.07)
plt.show()
3.6.3 代码解析
data_robs = preprocessing.RobustScaler(with_centering = True, with_scaling = True).fit_transform(iris)
3.6.4 结果展示
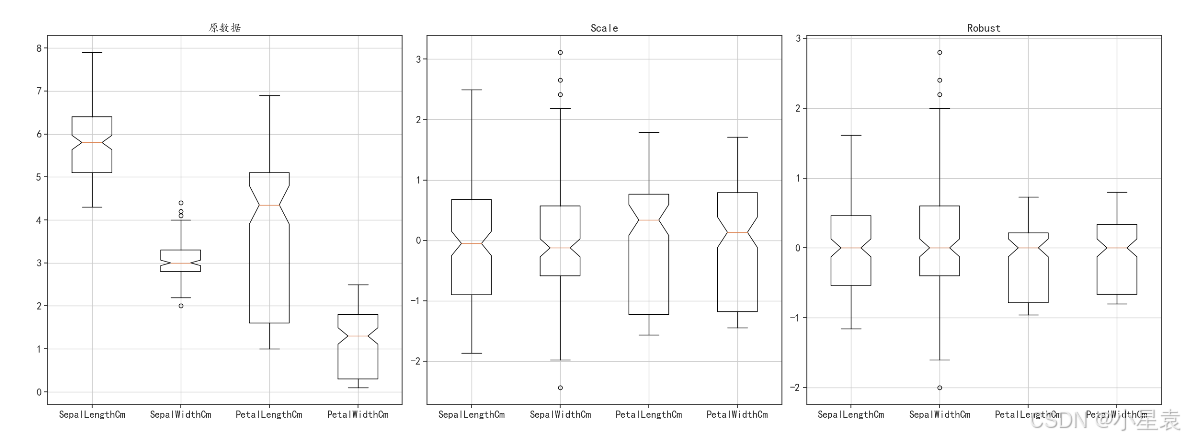
3.7 正则化变换
3.7.1 定义
正则化变换不是直接对数据特征进行变换,而是对模型的系数或参数进行约束,以防止模型过拟合。它通过在损失函数中添加正则化项(如L1范数或L2范数)来实现。
好处:
- 提高模型的泛化能力,防止过拟合。
- 通过简化模型来减少计算复杂度。
3.7.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 读取鸢尾花数据集
Iris = pd.read_csv("D:/iris.csv")
iris = Iris.drop(["Id", "Species"], axis = 1)
print(iris.head(3))
# 正则化约束
normL1 = preprocessing.normalize(iris, norm = "l1", axis = 0)
normL2 = preprocessing.normalize(iris, norm = "l2", axis = 0)
labs = iris.columns.values
plt.figure(figsize = (15, 8))
plt.subplot(1, 2, 1)
plt.boxplot(normL1, notch = True, labels = labs)
plt.grid()
plt.title("L1")
plt.subplot(1, 2, 2)
plt.boxplot(normL2, notch = True, labels = labs)
plt.grid()
plt.title("L2")
plt.subplots_adjust(wspace = 0.15)
plt.show()3.7.3 代码解析
normL1 = preprocessing.normalize(iris, norm = "l1", axis = 0)
normalize是scikit-learn中用于归一化数据的函数。它可以将数据按行或列进行归一化,使得每行或每列的元素之和(或其他指定的范数)等于1。norm="l1"参数指定了使用L1范数进行归一化。L1范数是指向量中所有元素的绝对值之和。axis=0参数指定了归一化的轴。axis=0意味着按列进行归一化,即每一列的元素将被归一化,使得该列的元素之和为1。然而,在大多数情况下,对于特征归一化,我们可能希望按行进行归一化(即每个样本的特征向量被归一化),这通常通过将axis设置为1来实现。
3.7.4 结果展示
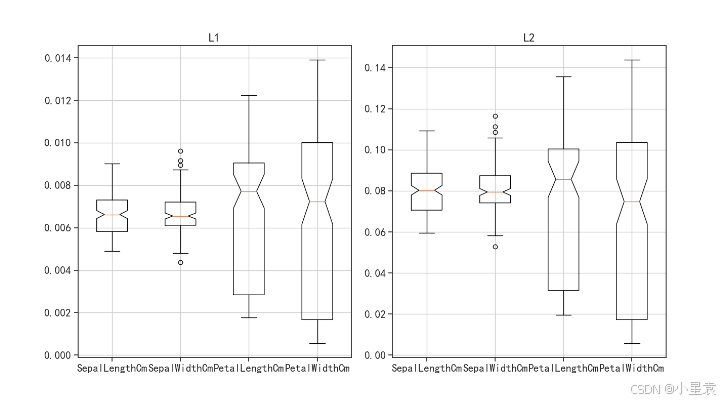
3.8 范数约束变换
3.8.1 定义
范数约束变换是对数据的特征向量进行约束,使其满足特定的范数条件。范数是一种度量向量大小的方式,在深度学习和机器学习中具有广泛的应用。
好处:
- 控制模型的复杂度,避免过拟合。
- 提高模型的稳定性和准确性。
- 在优化过程中,范数约束有助于加快收敛速度。
3.8.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 读取鸢尾花数据集
Iris = pd.read_csv("D:/iris.csv")
iris = Iris.drop(["Id", "Species"], axis = 1)
print(iris.head(3))
# 范数约束
data_normL1 = preprocessing.normalize(iris, norm = "l1", axis = 1)
data_normL2 = preprocessing.normalize(iris, norm = "l2", axis = 1)
labs = iris.columns.values
plt.figure(figsize = (15, 7))
plt.subplot(1, 2, 1)
plt.boxplot(data_normL1, notch = True, labels = labs)
plt.grid()
plt.title("L1")
plt.subplot(1, 2, 2)
plt.boxplot(data_normL2, notch = True, labels = labs)
plt.grid()
plt.title("L2")
plt.subplots_adjust(wspace = 0.15)
plt.show()
3.8.3 代码解析
data_normL1 = preprocessing.normalize(iris, norm = "l1", axis = 1)
preprocessing:这是scikit-learn库中负责数据预处理的模块,提供了多种数据预处理的方法。
normalize:这是preprocessing模块中的一个函数,用于对数据进行归一化处理。归一化是指将数据按比例缩放,使之落入一个小的特定区间,比如[0, 1]或[-1, 1]。这个函数可以执行L1或L2范数的归一化。
iris:这是要进行归一化处理的数据集,通常指的是鸢尾花数据集,它是一个常用的多变量数据集,用于机器学习和统计学中的分类问题。
norm = "l1":这个参数指定了归一化的类型。在这里,它设置为"l1",意味着将执行L1范数的归一化。L1范数归一化是将每个样本的特征值除以该样本所有特征值的绝对值之和,从而使每个样本的特征值之和为1(对于非零特征)。
axis = 1:这个参数指定了归一化是沿着哪个轴进行的。axis = 1意味着归一化是沿着样本的特征轴进行的,即每个样本(行)将独立地被归一化。这是处理多维数据集时的常见做法,特别是当数据集以样本为行、特征为列的形式组织时。
3.8.4 结果展示
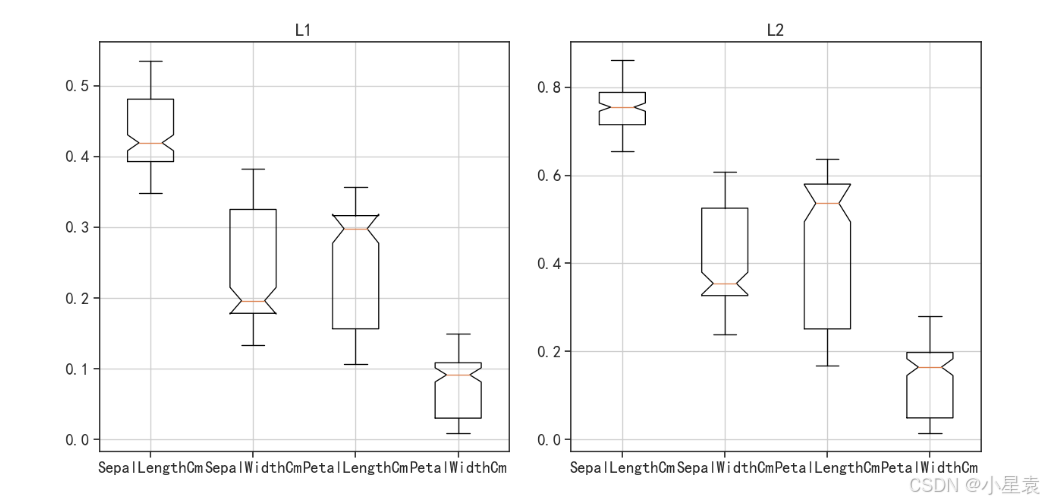
3.9 对数变换
3.9.1 定义
对数变换是一种数据处理方法,通常表示为x=logₐN,其中a为底数(a>0且a≠1),N为原始数据。
好处:
- 降低数据尺度:对数变换能将原始数据的幅度大幅缩小,使数据更集中在较小范围内,从而减小数据的波动性。
- 减小数据偏度:对数变换能有效处理偏态分布的数据,特别是右偏分布(正偏态),将其转换为更接近正态分布的形式。
- 稳定方差:对数变换可以减小数据的方差,使数据波动更稳定,有利于后续建模和分析。
- 线性化关系:对数变换有时能将非线性关系转换为线性关系,便于使用线性模型进行分析。
- 弹性估计:在经济学等领域,对数变换后的回归系数可以直接解释为弹性,即解释变量变化1%时,被解释变量变化的百分比。
- 数据压缩:对数变换可以压缩极大或极小的数值,便于处理和视觉呈现。
3.9.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 数据对换
np.random.seed(12)
x = 1 + np.random.poisson(lam = 1.5, size = 5000) + np.random.rand(5000)
lnx = np.log(x)
plt.figure(figsize = (14,8))
plt.subplot(1, 2, 1)
plt.hist(x, bins = 50)
plt.title("原数据")
plt.subplot(1, 2, 2)
plt.hist(lnx, bins = 50)
plt.title("变换后")
plt.show()3.9.3 代码解析
x = 1 + np.random.poisson(lam = 1.5, size = 5000) + np.random.rand(5000)
np.random.poisson是NumPy库中用于生成泊松分布随机数的函数。lam = 1.5指定了泊松分布的λ参数(lambda),即平均发生率或期望值。在这个例子中,λ被设置为1.5。size = 5000指定了要生成的随机数的数量。这里,将生成5000个泊松分布的随机数。np.random.rand(5000):
np.random.rand是NumPy库中用于生成均匀分布的随机数的函数,这些随机数的范围在[0, 1)之间。5000指定了要生成的随机数的数量。这里,将生成5000个均匀分布的随机数。x = 1 + ...:
- 这部分代码将上述两个生成的随机数序列相加,并且给每个结果加上1。
- 首先,泊松分布的随机数序列和均匀分布的随机数序列逐元素相加。由于两个序列都有5000个元素,所以相加的结果也是一个5000个元素的数组。
- 然后,每个元素的值都增加了1。
3.9.4 结果展示
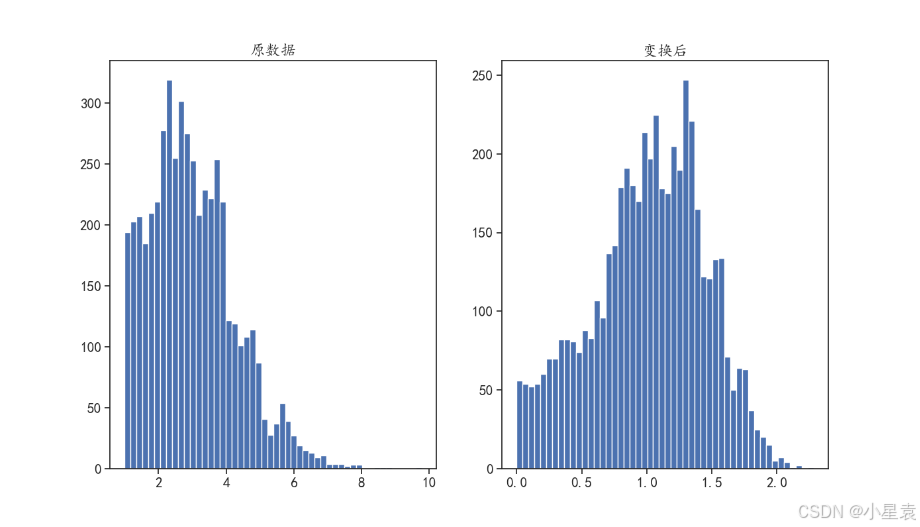
3.10 Box - Cox 变换
3.10.1 定义
Box-Cox变换是一种数据变换方法,通过引入一个参数λ,并根据数据本身估计该参数,从而确定应采取的数据变换形式。Box-Cox变换可以使数据更接近正态分布,同时满足线性、正态性、独立性以及方差齐性的要求。
好处:
- 改善数据正态性:Box-Cox变换可以明显改善数据的正态性、对称性和方差相等性。
- 优化模型拟合:变换后的数据有利于线性模型的拟合,以及分析出特征的相关性。
- 减小误差:Box-Cox变换可以一定程度上减小不可观测的误差和预测变量的相关性。
3.10.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# Box - Cox 变换
from scipy.stats import boxcox
np.random.seed(12)
x = 1 + np.random.poisson(lam = 1.5, size = 5000) + np.random.rand(5000)
bx1 = boxcox(x, lmbda = 0)
bx2 = boxcox(x, lmbda = 0.5)
bx3 = boxcox(x, lmbda = 2)
bx4 = boxcox(x, lmbda = -1)
plt.figure(figsize = (8,8))
plt.subplot(2, 2, 1)
plt.hist(bx1, bins = 50)
plt.title("$ln(x)$")
plt.subplot(2, 2, 2)
plt.hist(bx2, bins = 50)
plt.title("$sqrt(x)$")
plt.subplot(2, 2, 3)
plt.hist(bx3, bins = 50)
plt.title("$x^2$")
plt.subplot(2, 2, 4)
plt.hist(bx4, bins = 50)
plt.title("$1/x$")
plt.subplots_adjust(hspace = 0.4)
plt.show()3.10.3 代码解析
bx1 = boxcox(x, lmbda = 0)
boxcox: 这是SciPy库中scipy.stats模块的一个函数,用于执行Box-Cox变换。
x: 这是你要变换的原始数据数组。在你之前的代码中,x是一个包含5000个元素的数组,每个元素是由泊松分布随机数、均匀分布随机数和1相加得到的。
lmbda = 0: 这是Box-Cox变换中的一个参数,通常表示为λ(lambda)。在Box-Cox变换中,λ的值决定了变换的具体形式。当λ=0时,Box-Cox变换实际上变成了Yeo-Johnson变换的一个特例,该变换能够处理包含零或负值的数据(尽管在你的情况下,由于x是由泊松分布和均匀分布相加得到的,所以它可能不包含零或负值)。然而,当数据全部为正且λ=0时,Box-Cox变换实际上等价于对数变换(加上一个常数以确保结果为正),但这里有一个重要的区别:Box-Cox变换在λ=0时不是通过对数计算得到的,而是通过极限形式得到的,它避免了在λ=0时对数未定义的问题。但在实践中,如果数据全部为正且你希望应用对数变换,直接应用对数可能更简单且效果相当。
bx1: 这是变换后的数据数组。boxcox函数将返回变换后的数据以及用于变换的λ值(如果你没有提供lmbda参数或提供了None,则函数会尝试找到一个最优的λ值;但在这个例子中,你显式地设置了lmbda=0)。
3.10.4 结果展示
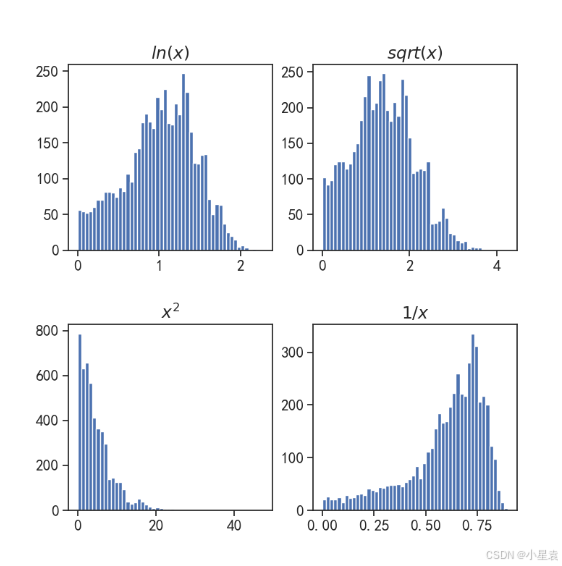
3.11 正态变换
3.11.1 定义
正态变换是指将数据转换为满足正态分布特性的过程。正态分布在统计学中是最常见的概率分布之一,能够很好地描述许多自然现象的数据集。
好处:
- 满足统计假设:许多统计方法和模型都基于正态分布的假设,通过正态变换可以使数据满足这些假设,从而提高分析结果的准确性和可靠性。
- 提高模型性能:正态变换可以改善数据的统计特性,使模型更容易拟合数据,从而提高模型的预测性能。
- 简化计算:在一些统计方法中,如极大似然估计等,正态变换可以简化计算过程。
3.11.2 代码
# 图像中文显示问题
import matplotlib
import matplotlib.pyplot as plt
from sklearn import preprocessing
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns
sns.set(font = "Kaiti", style = "ticks", font_scale = 1.4)
import pandas as pd
import numpy as np
# 正态变换
x = 1 + np.random.poisson(lam = 1.5, size = 5000) + np.random.rand(5000)
qtn = preprocessing.QuantileTransformer(output_distribution = "normal", random_state = 0)
qtnx = qtn.fit_transform(x.reshape(5000, 1))
plt.figure(figsize = (10, 6))
plt.subplot(1, 2, 1)
plt.hist(x, bins = 50)
plt.title("原数据")
plt.subplot(1, 2, 2)
plt.hist(qtnx, bins = 50)
plt.title("变换后")
plt.show()3.11.3 代码解析
qtn = preprocessing.QuantileTransformer(output_distribution = "normal", random_state = 0)
preprocessing.QuantileTransformer: 这是从sklearn.preprocessing模块导入的QuantileTransformer类。
output_distribution="normal": 这个参数指定了变换后的数据应该遵循的分布类型。在本例中,我们选择了正态分布。这意味着QuantileTransformer将会调整输入数据的分位数,使其与标准正态分布的分位数相匹配。
random_state=0: 这个参数用于确保结果的可重复性。通过设置一个固定的随机状态,我们可以保证每次运行代码时得到的结果都是相同的。这对于实验和模型评估非常重要。
qtnx = qtn.fit_transform(x.reshape(5000, 1))
qtn.fit_transform: 这个方法首先调用fit来计算输入数据的分位数,然后调用transform来应用这些分位数映射到指定的输出分布上。在这个例子中,我们同时执行了这两个步骤,以节省代码和计算时间。
x.reshape(5000, 1): 由于QuantileTransformer期望输入数据是二维的(通常是样本数×特征数的形状),而x可能是一个一维数组(包含5000个元素),因此我们使用reshape方法将其转换为二维数组。这里的形状(5000, 1)表示有5000个样本,每个样本有1个特征。
qtnx: 这是变换后的数据。它将是一个二维数组,形状为(5000, 1),包含了与原始数据x相对应但已经映射到正态分布分位数的值。
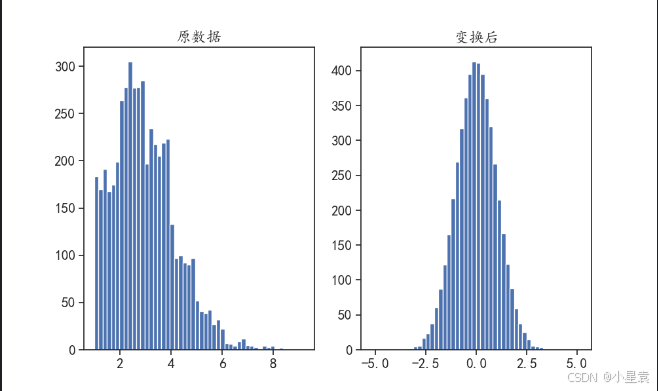
3.11.4 结果展示

上一篇文章:Python实现鸢尾花连续变量和分类变量的可视化分析(超详细教程)-优快云博客![]() https://blog.youkuaiyun.com/Z0412_J0103/article/details/145025213下一篇文章:
https://blog.youkuaiyun.com/Z0412_J0103/article/details/145025213下一篇文章:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











