







一、向量化的实现及原理
· 对于 ,可以直接调用numpy对其实现点积运算。
· 当然,也可以通过torch将其定义为张量实现向量间的运算。

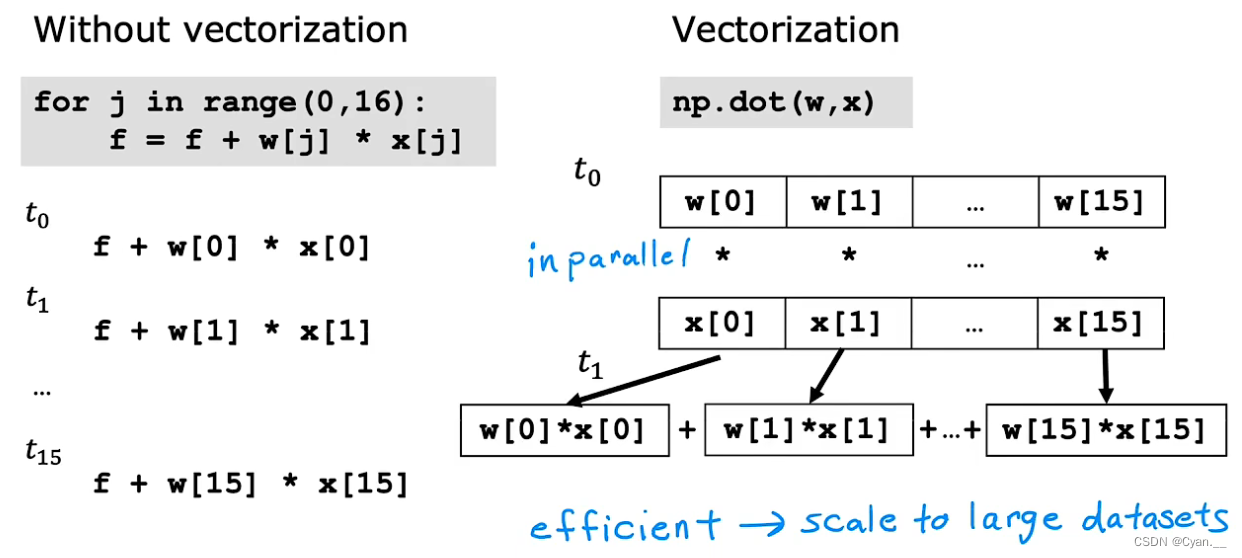
向量化的好处:当n很大时,通过对 向量化可以大大节省运行时间。
· 原理:当使用for循环对元素一个个进行乘积运算时,计算机是一步一步求解这些数的结果的。而当我们使用向量化点积运算时,计算机时一步将所有数同时执行乘积运算并存放最终结果的。因此它更高效更直接,在训练大型数据集与应用数据库时非常有效。
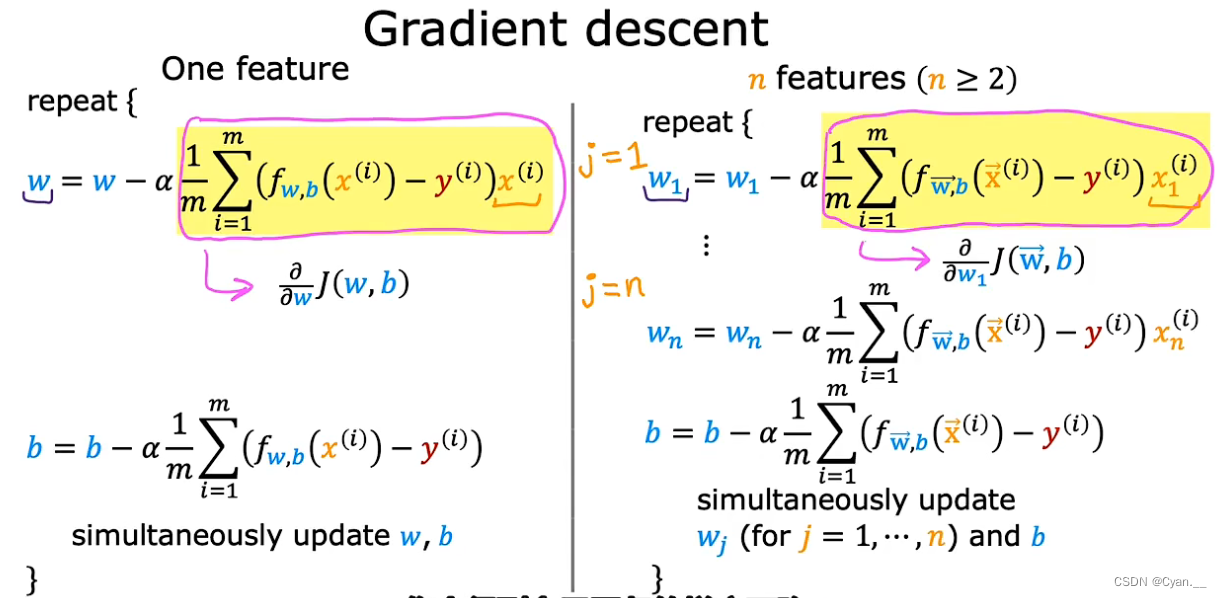
同理,我们可以采用向量化的方式进行多元线性回归模型的梯度下降算法。
二、特征缩放
· 作用:可以使梯度下降算法运行得更快。
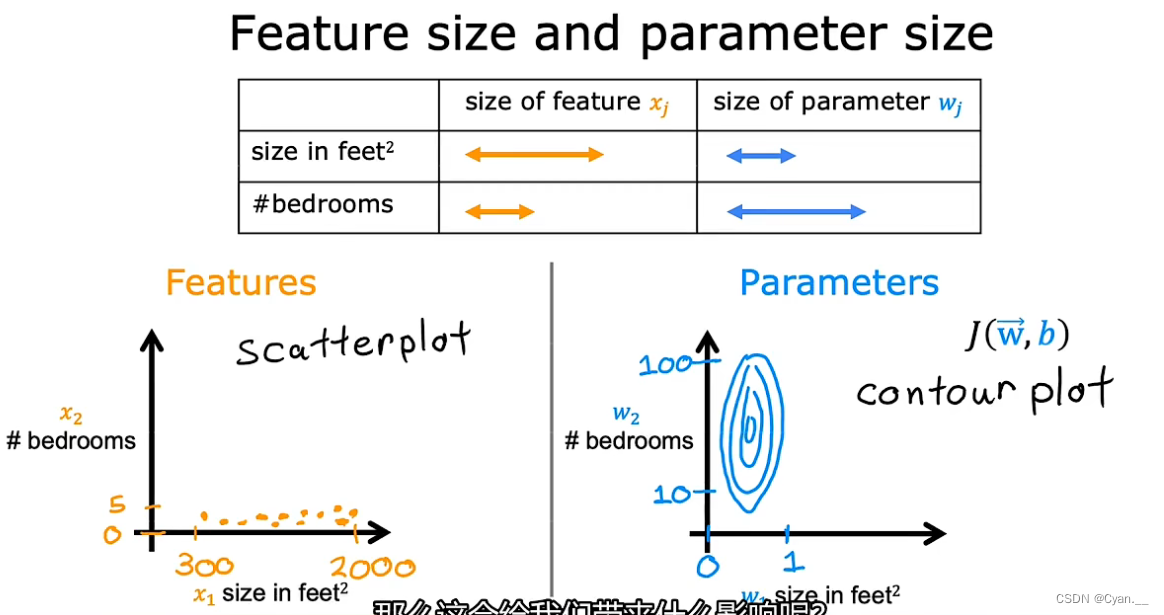
· 当模型具有多个特征值,且特征值的取值范围差异很显著时,参数 的取值也应有所不同。
特征值的取值范围较大时,模型参数 应该尽可能更小;反之当特征值的取值范围较小时,模型参数
应该尽可能更大。否则,模型的预测值波动范围会较大,导致无法较准确地进行预测。
· 原理:会产生这一作用的原因是,由于特征值取值范围的差异造成不同参数 作用于不同特征值时所造成的结果存在显著差异。对于取值范围较大的特征值,可能
略有轻微改变便会引起结果有较大差异。这使得成本函数对不同的
呈现出不同的改变效果。
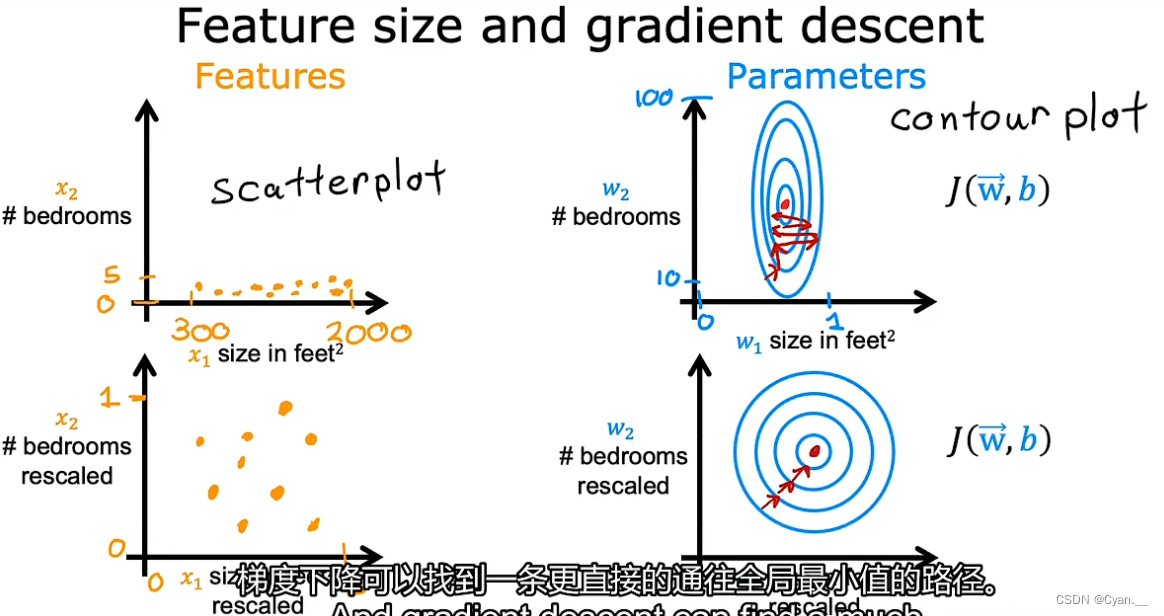
这时,损失(成本)函数的等高线表示图又高又瘦,梯度下降算法会左右横跳来回寻找很多次以找到最小值点。
· 特征缩放:对特征数据进行一些转换,使得特征值的取值范围尽可能逼近。
这使得损失(成本)函数的等高线表示图更趋近于圆形,梯度下降便可以更容易地找到一条更直接的通往全局最小值的路径。
· 实现特征缩放:
1. 除最大值法:将特征值的取值范围除以其最大值,保证多个特征值的取值都在[0,1]区间内。
2. 均值归一化:缩至[-1,1]区间内。
(1) 先取一类中所有特征值的平均数,记作 ,然后取每一个特征值,减去
并除以区间长度。
(2) 例:对于[300,2000]的特征数据 ,可以采用以下公式以将其缩至[-1,1]:
3. Z分数归一法:
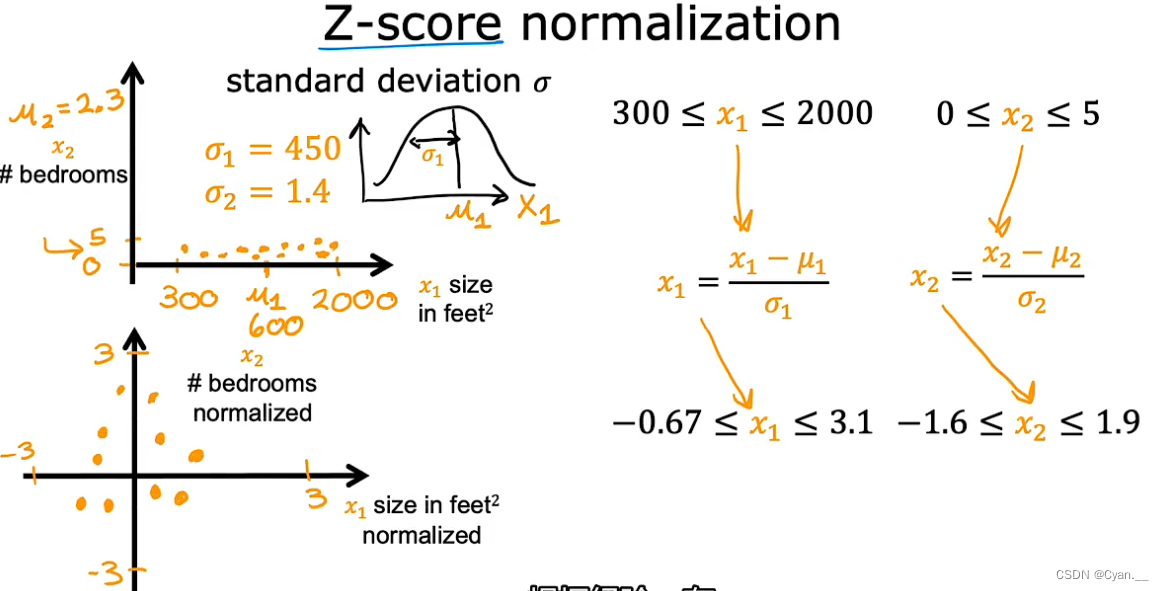
常见地,我们习惯将特征值的范围统一到[-1,1]的区间左右。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









