




 本文提出了一种名为移位的操作,作为神经网络中空间卷积的替代,以实现零FLOP和零参数。移位操作与逐点卷积相结合,构建了端到端可训练的基于移位的模块,可以在准确性和效率之间进行权衡。通过在ResNet的3x3卷积上应用移位操作,研究显示在CIFAR10和CIFAR100上参数减少了60%,同时提高了准确性。此外,移位操作在ImageNet上展现出参数减少的弹性,并在多个任务(如图像分类、面部验证和样式转移)中取得了出色性能,且参数更少。
本文提出了一种名为移位的操作,作为神经网络中空间卷积的替代,以实现零FLOP和零参数。移位操作与逐点卷积相结合,构建了端到端可训练的基于移位的模块,可以在准确性和效率之间进行权衡。通过在ResNet的3x3卷积上应用移位操作,研究显示在CIFAR10和CIFAR100上参数减少了60%,同时提高了准确性。此外,移位操作在ImageNet上展现出参数减少的弹性,并在多个任务(如图像分类、面部验证和样式转移)中取得了出色性能,且参数更少。
Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
-
摘要
神经网络依靠卷积来聚合空间信息。 但是空间卷积在模型大小和计算方面是昂贵的,两者相对于内核大小都呈平方增长。 在本文中,我们提出了无参数,无FLOP的“移位”操作,以替代空间卷积。 我们融合了移位和逐点卷积,以构建端到端可训练的基于移位的模块,并具有超参数特性,可在准确性和效率之间进行权衡。 为了证明该手术的功效,我们将ResNet的3x3卷积替换为基于班次的模块,以减少60%的参数来提高CI FAR10和CIFAR100的准确性; 我们还展示了该操作在ImageNet上减少参数减少的弹性,胜过ResNet系列成员。 最后,我们展示了移位操作在各个领域的适用性,以更少的分类,面部验证和样式转移参数实现了出色的性能。
-
引言及相关工作
卷积神经网络(CNN)在计算机视觉任务中无处不在,包括图像分类,对象检测,面部识别和样式转换。 这些任务使许多新兴的移动应用程序和物联网(IOT)设备成为可能。 但是,这样的设备具有显着的内存限制,并且对空中更新的大小有所限制(例如100-150MB)。 反过来,这限制了这些应用中使用的CNN的大小。 因此,我们致力于在适用任务上减少CNN模型的尺寸,同时保持准确性。
CNN依靠内核大小为3x3或更大的空间卷积来聚集图像中的空间信息。 但是,空间卷积在计算和模型大小上都非常昂贵,每一个都相对于内核大小呈平方增长。

图1:移位操作后跟1x1卷积的示意图。 移位操作可在空间上调整数据,并且1x1卷积可在通道之间混合信息。
在VGG-16模型[19]中,3x3卷积占1500万个参数,而fc1层(实际上是7x7卷积)占1.02亿个参数。
已经采取了几种策略来减小空间卷积的大小。 ResNet [6]使用“瓶颈模块”,在3x3卷积之前和之后放置两个1x1卷积,从而减少了其输入和输出通道的数量。 尽管如此,在具有机器人细颈模块的ResNet模型中,3x3卷积层仍占所有参数的50%。 SqueezeNet [9]采用“发射模块”,其中3x3卷积和1x1卷积的输出沿通道尺寸连接。 最近的网络,如ResNext [26],MobileNet [7]和Xception [1],都采用组卷积和深度可分离卷积作为标准空间卷积的替代方法。 从理论上讲,深度卷积需要较少的计算。 但是,在实践中很难有效地实现深度卷积,因为它们的算术强度(FLOP与内存访问的比率)太低而无法有效利用硬件。 在[29,1]中也提到了这种缺陷。 ShuffleNet [29]集成了深度方向卷积,点方向群卷积和通道方向混洗,以进一步减少参数和复杂度。 在另一篇著作中,[12]继承了可分离卷积的概念,以冻结空间卷积并仅学习逐点卷积。 这确实减少了可学习的参数数量,但不足以节省FLOP或模型尺寸。
我们的方法是完全避开空间卷积。

图2:(a)空间卷积,(b)深度卷积和(c)移位的图示。 在(c)中,3x3网格表示核尺寸为3的位移矩阵。亮的单元格在该位置表示1,而白色单元格则表示0。
在本文中,我们提出了移位运算(图1)作为空间卷积的替代方法。 移位操作将其输入张量的每个通道沿不同的空间方向移动。 基于移位的模块通过逐点卷积交错移位操作,从而进一步混合了跨通道的空间信息。 与空间卷积不同,移位操作本身需要零个FLOP和零个参数。 与深度卷积相反,可以轻松有效地执行移位操作。
我们的方法与模型压缩[4],张量分解[27]和低位网络[16]正交。 结果,这些技术中的任何一种都可以与我们提出的方法结合使用,以进一步减小模型尺寸。
我们针对基于移位的模块引入了新的超参数“扩展” E,它对应于FLOP /参数与精度之间的权衡。 这使从业人员可以根据特定的设备或应用程序要求选择模型。 然后,使用基于班次的模块,我们提出了一个称为ShiftNet的新体系结构系列。 为了证明这一新操作的有效性,我们在几个任务上评估Shift Net:图像分类,面部验证和样式转换。 ShiftNet使用少得多的参数,即可获得具有竞争力的性能。
-
移位模块和网络设计
我们首先回顾图2所示的标准空间和深度卷积。考虑图2(a)中的空间卷积,其中将张量![]()
![]() 作为输入 。 令
作为输入 。 令![]() 表示高度和宽度,M表示通道尺寸。 空间卷积的核是张量
表示高度和宽度,M表示通道尺寸。 空间卷积的核是张量![]() ,其中
,其中![]() 表示核的空间高度和宽度,N表示过滤器的数量。 为简单起见,我们假设步幅为1,并且输入/输出具有相同的空间尺寸。 然后,空间卷积输出张量
表示核的空间高度和宽度,N表示过滤器的数量。 为简单起见,我们假设步幅为1,并且输入/输出具有相同的空间尺寸。 然后,空间卷积输出张量![]() ,可以将其计算
,可以将其计算
其中![]() 是重新定义的空间索引; k,l和i,j沿空间维度索引,而n,m则索引为通道。 空间卷积所需的参数数量为
是重新定义的空间索引; k,l和i,j沿空间维度索引,而n,m则索引为通道。 空间卷积所需的参数数量为![]() ,计算量为
,计算量为![]() 。 随着内核大小
。 随着内核大小![]() 的增加,我们看到参数数量和计算成本呈二次方增长。
的增加,我们看到参数数量和计算成本呈二次方增长。
空间卷积的一个流行变体是深度卷积[7,1],通常后面是点状卷积(1x1卷积)。 总之,该模块称为深度方向可分离卷积。 如图2(b)所示,深度卷积可从每个通道内的DK×DK补丁聚集空间信息,可以描述为
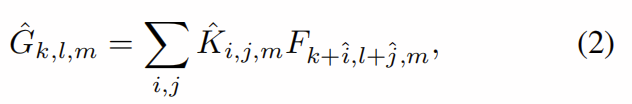
其中![]() 是深度卷积核。 该卷积包括
是深度卷积核。 该卷积包括![]() 个参数和
个参数和![]() 个FLOP。 像在标准空间运算中一样,参数数量和计算成本相对于内核大小
个FLOP。 像在标准空间运算中一样,参数数量和计算成本相对于内核大小![]() 呈二次方增长。 最后,逐点卷积在各个通道上混合信息,从而为我们提供以下输出张量
呈二次方增长。 最后,逐点卷积在各个通道上混合信息,从而为我们提供以下输出张量
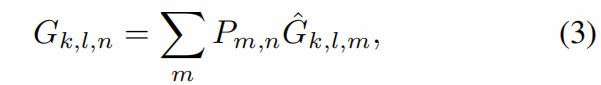
其中![]() 是逐点卷积核。
是逐点卷积核。
理论上,深度卷积需要较少的计算和较少的参数。 然而,实际上,这意味着内存访问支配了计算,从而限制了并行硬件的使用。 对于标准卷积,计算与内存访问之间的比率为
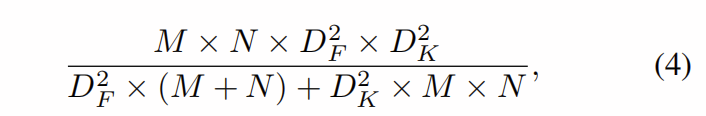
而对于深度卷积,比率为
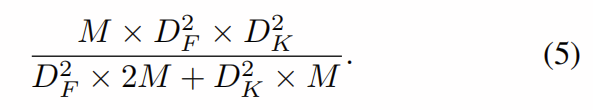
较低的比率意味着在内存访问上花费了更多的时间,而内存访问比FLOP慢了几个数量级,并且消耗了更多的能量。 此缺点意味着I / O绑定设备将无法实现最大的计算效率。
-
移位运算
如图2(c)所示,移位运算可以看作是深度卷积的特殊情况。
具体来说,可以在逻辑上描述为:
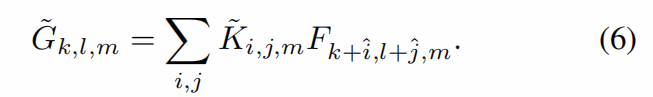
移位运算的核心是张量![]()
![]()
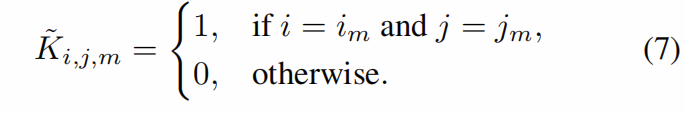
在这里![]() 是与通道相关的索引,这些索引将
是与通道相关的索引,这些索引将![]() 中的值之一分配为1,将其余值分配为0。我们称
中的值之一分配为1,将其余值分配为0。我们称![]() 为移位矩阵。
为移位矩阵。
对于内核大小为![]() 的移位运算,存在
的移位运算,存在![]() 个可能的移位矩阵,每个矩阵对应于一个移位方向。 如果通道大小M不小于
个可能的移位矩阵,每个矩阵对应于一个移位方向。 如果通道大小M不小于![]() ,我们可以构造一个移位矩阵,使每个输出位置(k,l)访问输入中
,我们可以构造一个移位矩阵,使每个输出位置(k,l)访问输入中![]() 窗口内的所有值。 然后,我们可以根据等式应用另一个逐点卷积。 (3)跨渠道交流信息。
窗口内的所有值。 然后,我们可以根据等式应用另一个逐点卷积。 (3)跨渠道交流信息。
与空间和深度卷积不同,移位运算本身不需要参数或浮点运算(FLOP)。 取而代之的是一系列存储器操作,它们在某些方向上调整输入张量的通道。 更复杂的实现可以将移位操作与以下1x1卷积融合在一起,其中1x1卷积直接从缓存中的移位地址获取数据。 通过这种实现,我们可以免费使用移位操作来聚合空间信息。
-
构造移位内核
对于给定的内核大小![]() 和通道大小M,存在
和通道大小M,存在![]() 可能的移位方向,从而使
可能的移位方向,从而使![]() 成为可能的移位内核。 在此状态空间上进行详尽搜索以寻找最佳移位内核非常昂贵。
成为可能的移位内核。 在此状态空间上进行详尽搜索以寻找最佳移位内核非常昂贵。
为了减少状态空间,我们使用一种简单的启发式方法:将M个通道平均划分为![]() 组,其中每组
组,其中每组![]() 通道采用一个移位。 我们将参考所有与班次组班次相同的频道。 其余通道被分配到“中央”组,并且不移位。
通道采用一个移位。 我们将参考所有与班次组班次相同的频道。 其余通道被分配到“中央”组,并且不移位。
但是,要找到最佳排列,即如何将每个通道m映射到移位组,就需要搜索组合大的搜索空间。 为了解决这个问题,我们对移位操作进行了修改,使输入和输出对于通道顺序不变:我们注意到通道移位π为![]() 的移位操作,因此我们可以表示等式。 (6)当
的移位操作,因此我们可以表示等式。 (6)当![]() 时。 我们将移位操作的输入和输出置换为
时。 我们将移位操作的输入和输出置换为
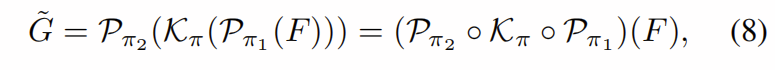
其中![]() 是置换算子,而◦表示算子组成。 但是,置换算子是离散的,因此难以优化。 结果,我们将输入F处理到等式。 (8)由点卷积
是置换算子,而◦表示算子组成。 但是,置换算子是离散的,因此难以优化。 结果,我们将输入F处理到等式。 (8)由点卷积![]() 。
。
我们使用![]() 对输出
对输出![]() 重复该过程。 最终表达式可以写成
重复该过程。 最终表达式可以写成
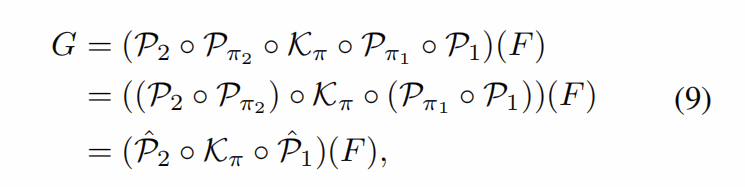
在最后一步成立的地方,因为存在从所有![]() 到所有
到所有![]() 的双射,因为置换算子
的双射,因为置换算子![]() 在构造上是双射的。 结果,直接学习
在构造上是双射的。 结果,直接学习![]() 和
和![]() 就足够了。 因此,该增加的变速操作等式。 (9)可以接受端到端随机梯度下降的训练,而无需考虑通道顺序。
就足够了。 因此,该增加的变速操作等式。 (9)可以接受端到端随机梯度下降的训练,而无需考虑通道顺序。
只要将移位操作夹在两个点式卷积之间,移位的不同排列是等效的。 因此,在为每个移位方向固定通道数之后,我们可以为移位内核选择任意排列.
-
基于班次的模块
首先,我们将模块定义为执行单个功能的图层的集合,例如 ResNet的瓶颈模块或SqueezeNet的火灾模块。 然后,我们将一个组定义为重复模块的集合.
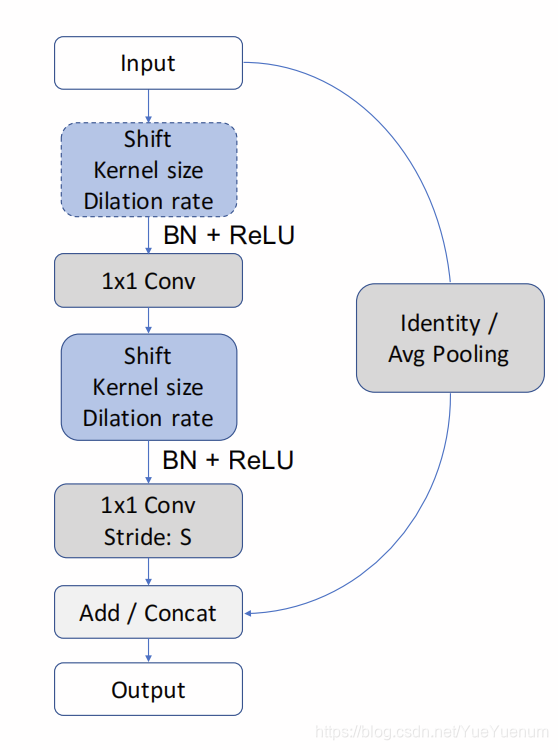
图3:Conv-Shift-Conv CSC模块和Shift-Conv-Shift-Conv(![]() )模块的图示。
)模块的图示。
基于前几节的分析,我们提出了一个使用移位操作的模块,如图3所示。输入张量首先通过逐点卷积进行处理。
然后,我们执行移位操作以重新分配空间信息。 最后,我们应用另一组逐点卷积来混合跨通道的信息。 两组点卷积之前都进行了批量归一化和非线性激活函数(ReLU)。 遵循ShuffleNet [29],当输入和输出的形状相同时,我们使用加性残差连接;当对空间进行下采样并对输出通道加倍时,我们使用平均年龄池和串联连接。 我们将其称为Conv-Shift-Conv或CSC模块。 该模块的一种变体包括在第一次点式卷积之前的另一个移位操作; 我们将其称为Shift Conv-Shift-Conv或![]() 模块。 这使设计人员可以进一步增加模块的接收范围。
模块。 这使设计人员可以进一步增加模块的接收范围。
与空间卷积一样,移位模块由控制其行为的几个因素来参数化。 我们使用移位操作的内核大小来控制CSC模块的接收场。 类似于膨胀卷积,“膨胀位移”以空间间隔对数据采样,我们将其定义为膨胀率D。CSC模块的步幅定义为第二个点式卷积的步幅,因此 在下采样之前的移位操作中会混合空间信息。 与ResNet中使用的瓶颈模块类似,我们使用“扩展率” E来控制中间张量的通道大小。 使用瓶颈模块,中间的3x3卷积在计算上非常昂贵,从而迫使中间通道的尺寸变小。
但是,移位操作允许调整内核大小![]() ,而不会影响参数大小和FLOP。 因此,我们可以使用移位模块来允许更大的中间通道大小,在此可以从附近位置收集足够的信息。
,而不会影响参数大小和FLOP。 因此,我们可以使用移位模块来允许更大的中间通道大小,在此可以从附近位置收集足够的信息。
-
实验
我们首先评估移位模块替换卷积层的能力,然后调整超参数E以观察模型精度,模型大小和计算之间的折衷。 然后,我们构建了一系列基于班次的网络,并研究了它们在许多不同应用中的性能。
-
操作
选择和超参数使用ResNet,我们将3x3卷积层与CSC模块并列使用,方法是将所有ResNet的基本模块(两个3x3卷积层)替换为CSC,制成“ ShiftResNet”。 对于ResNet和ShiftRes Net,我们使用两个Tesla K80 GPU,批处理大小为128,起始学习率为0.1,在进行32k和48k迭代后衰减10倍,如[6]所示。 在这些实验中,我们使用ResNet的CIFAR10版本:具有16个3x3滤镜的卷积层。 3组具有输出通道16、32、64的基本模块; 以及最终的全连接层。 基本模块包含两个3x3卷积层,其后是批处理范数和ReLU,并带有残余连接。 使用ShiftResNet,每个组包含几个CSC模块。 我们使用三种ResNet模型:在ResNet20中,每个组包含3个基本模块。 对于ResNet56,每个包含5,对于ResNet110,每个包含7。通过切换超参数E(CSC模块第一组1x1卷积中的滤波器数量),我们可以将“ ShiftResNet”中的参数数量减少近 如表1所示,精确度为3倍。表5总结了所有E和ResNet模型的CIFAR10和CIFAR100结果。
接下来,我们比较参数减少的不同策略。 对于某些E,我们降低了ResNet的参数以使其与ShiftResNet的参数匹配,分别表示为ResNet-E和ShiftResNet-E。 我们使用两个单独的方法:1)在模块上:减少每个模块的第一个3x3卷积层中的过滤器数量; 2)明智的做法:将每个模块的输入和输出通道减少相同的因子。 如表2所示,在CIFAR100上,卷积层对参数减少的适应性较差,而移位模块的保留精度比两个相同大小的经过减少的ResNet模型都高8%。 在表3中,我们很明智地发现ImageNet上的弹性得到了改善,因为ShiftResNet可以通过减少数百万个参数来实现更高的准确性。
表4显示,当两个参数使用的参数减少1.5倍时,ShiftResNet始终优于ResNet。 然后,表5包含所有结果。 图4显示了在使用不同层数∈{20,56,110}的两个{ResNet,ShiftResNet}模型中,CIFAR100精度与超参数E∈{∈1、3、6、9}的参数数量之间的权衡。 图5检验了同一组可能的模型和超参数,但在CIFAR100精度和FLOP数量之间。 这两个图都表明ShiftResNet模型在精度和参数/ FLOP之间提供了出色的折衷方案。
表1:在CIFAR-100上具有固定精度的移位VS卷积参数

-
ShiftNet
即使ImageNet分类不是我们的主要目标,为了进一步研究班次操作的有效性,我们使用图3中所示的建议CSC模块来设计一类称为Shift Net的有效模型,并给出其分类 性能与标准基准相比,可以与最新的小型模型进行比较。
表2:具有固定参数的位移VS卷积的降低弹性

表3:IMAGENET上的VS与卷积的还原弹性
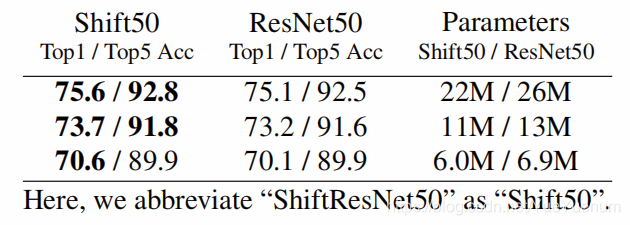
表4:具有1.5个较少参数的跨模型性能
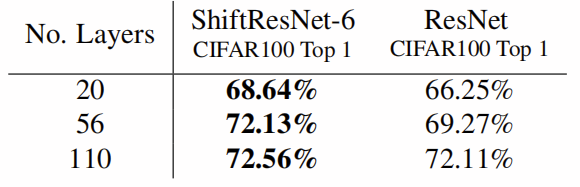
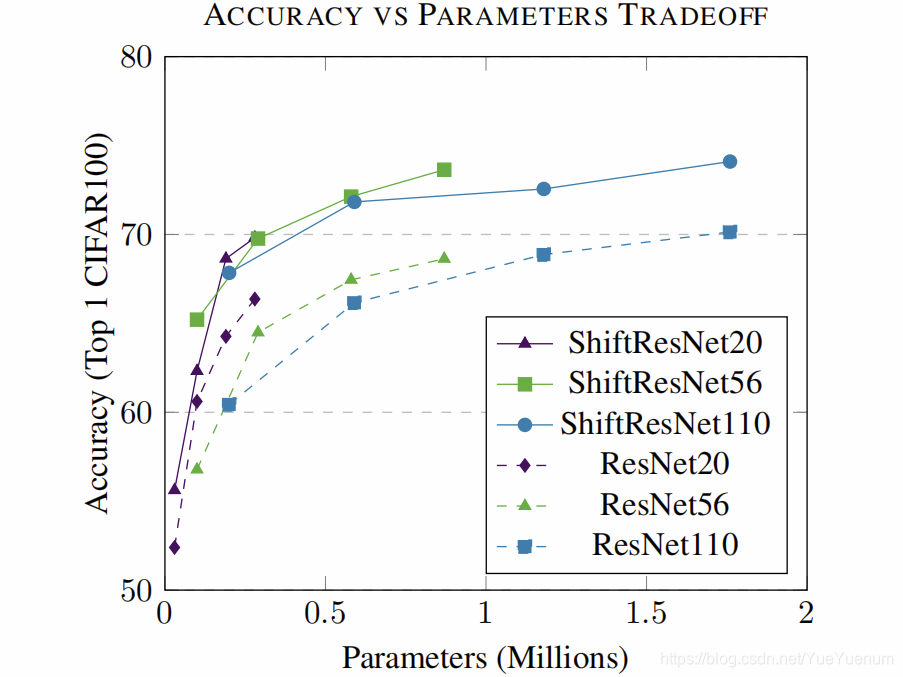
图4:此图显示ShiftResNet家族成员比其对应的ResNet家族成员明显更有效。 左上角的折衷曲线更有效,每个参数的精度更高。 对于ResNet,我们采用模块精度和净精度降低结果之间的两个精度中的较大者。
由于外部存储器访问比单次算术运算消耗的能量多1000倍[5]
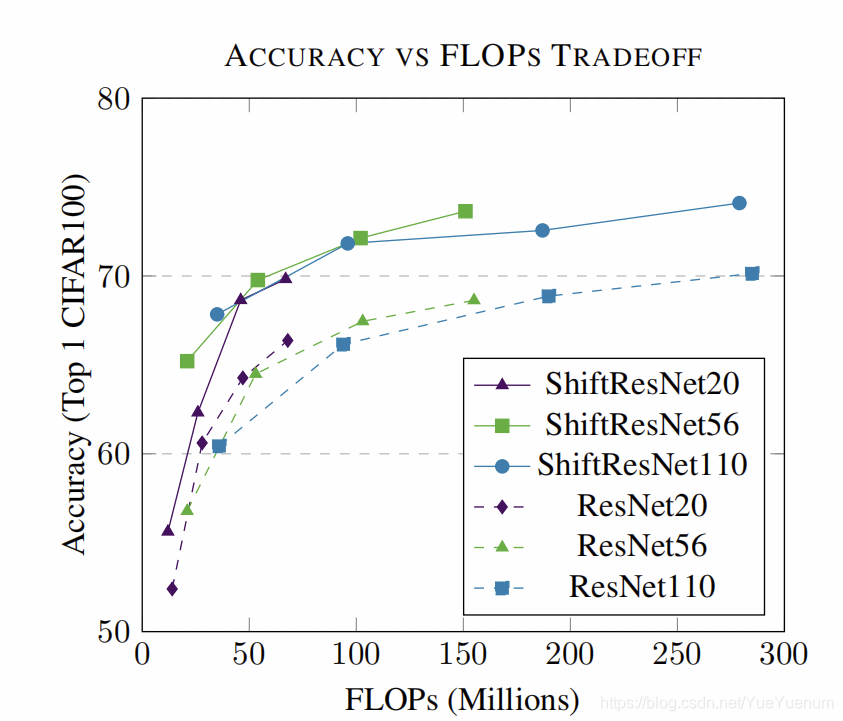
图5:最左上角的权衡曲线效率更高,每个FLOP的精度更高。 该图显示,在FLOP中,ShiftResNet比ResNet更有效。
设计ShiftNet的主要目的是优化pa的数量。从而减少内存占用。 除了对能源效率的一般要求外,ShiftNet的主要目标是移动和IOT应用程序,其中内存占用量(甚至比FLOP更大)是主要限制因素。 在这些应用程序领域中,可以将小型模型打包在移动和IOT应用程序中,这些应用程序在100-150MB的限制范围内进行移动无线更新。 简而言之,我们ShiftNets的设计目标是通过更少的参数获得具有竞争力的准确性。
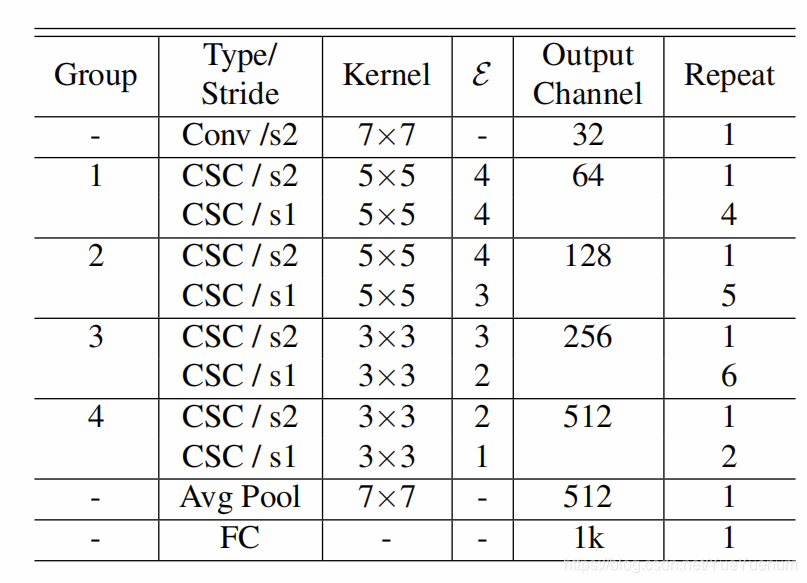
表6中描述了ShiftNet体系结构。由于参数大小不会随移位内核的大小而增长,因此在较早的模块中,我们将内核大小设置为5。 我们调整扩展参数E以缩放每个CSC模块中的参数大小。 我们将表6中描述的架构称为ShiftNet-A。 对于ShiftNet-B,我们将所有CSC模块中的通道数量减少2。 然后,我们使用组{1、2、3、4}中的{1、4、4、3}个CSC模块(通道大小为{32、64、128、256},E = 1和 所有模块的内核大小均为3。 我们将此浅层模型命名为ShiftNet-C。 我们使用128万张图像在ImageNet 2012分类数据集[17]上训练了三个ShiftNet变量,并评估了50K张图像的验证集。 我们采用[1]建议的数据扩充和[6]建议的权重初始化。 我们使用Intel Caffe [10]在64个Intel KNL实例上训练了90个时代的模型,批处理大小为2048,初始学习率为0.8,学习率每30个时代衰减10个。
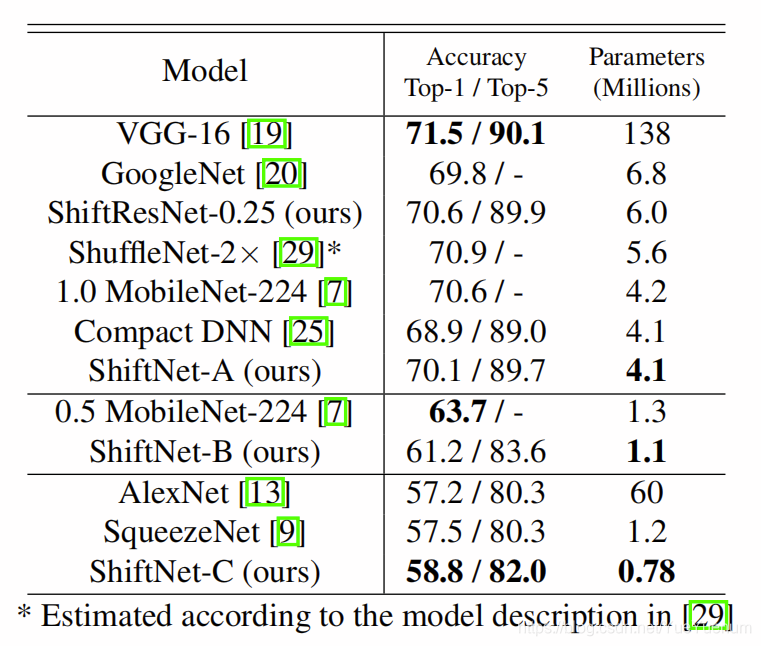
在表7中,我们显示了ShiftNet和其他最新模型的分类准确性和参数数量。
表5:使用CIFAR10和CIFAR100进行的移位操作分析
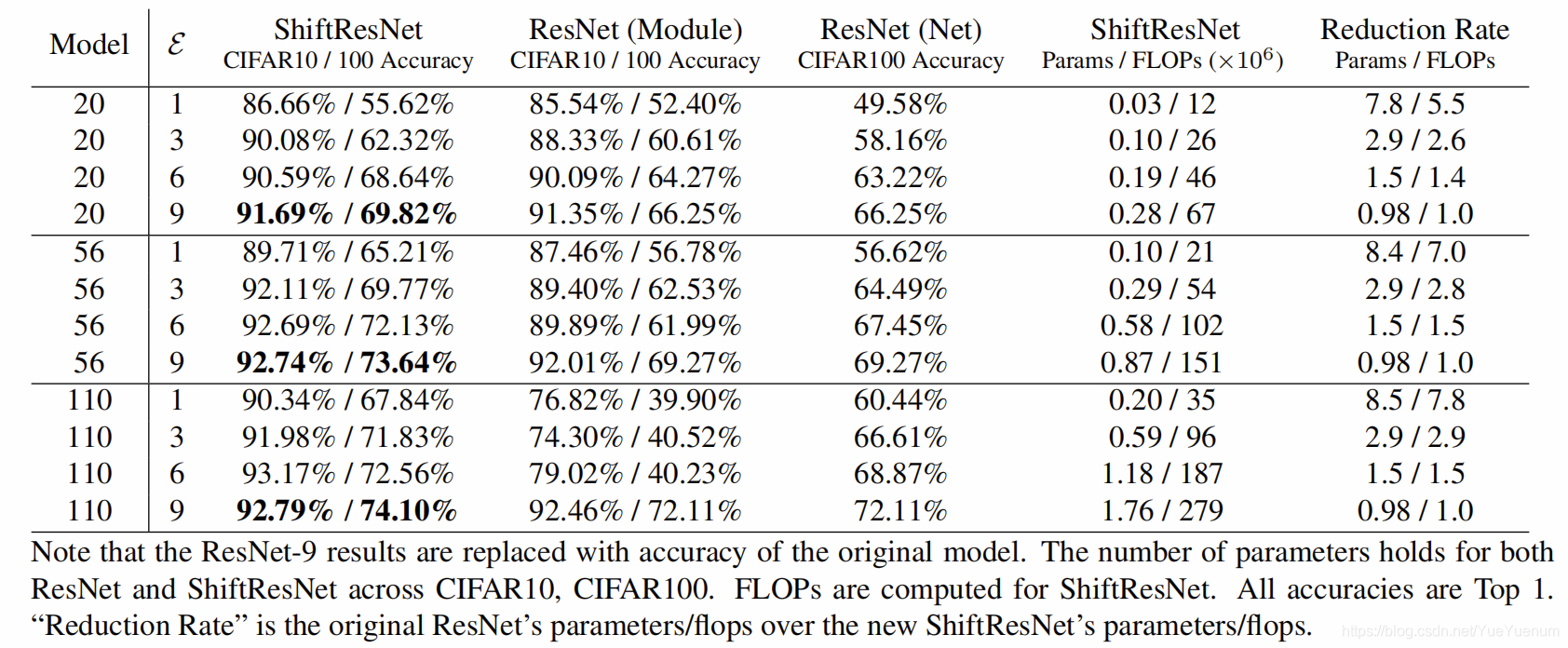
请注意,ResNet-9结果已替换为原始模型的准确性。 在CIFAR10,CIFAR100中,ResNet和ShiftResNet的参数数量均保持不变。 针对ShiftResNet计算FLOP。 所有精度均为前1名。
“降低率”是原始ResNet的参数/触发器,高于新ShiftResNet的参数/触发器。
表6:SHIFTNET体系结构
具有相似的准确度。 在第一组中,ShiftNet A比VGG-16小34倍,而前1名的准确性下降仅为1.4%。 ShiftNet-B的top-1精度比MobileNet-B差2.5%,但它使用的参数更少。 我们将ShiftNet-C与SqueezeNet和AlexNet进行了比较,并且使用SqueezeNet参数数量的2/3可以达到更好的准确性,并且比AlexNet小77倍。
-
人脸嵌入
我们将继续研究针对不同应用的移位操作。 人脸验证和识别在移动设备上正变得越来越流行。 两种功能都依赖于人脸嵌入,目的是学习从人脸图像到Eu clidean空间中紧凑嵌入的映射,通过嵌入距离可以直接测量人脸相似性。
表7:IMAGENET上的SHIFTNET结果
一旦生成了空间,就可以通过具有特征嵌入功能的标准机器学习方法轻松完成各种面部学习任务,例如面部识别和验证。
移动设备的计算资源有限,因此创建用于面部嵌入的小型神经网络是移动部署的必要步骤。
FaceNet [18]是一种最先进的人脸嵌入方法。 最初的FaceNet基于Inception-Resnet v1 [21],其中包含2850万个参数,因此很难在移动设备上进行部署。 我们从上一节中提出了一个基于ShiftNet-C的新模型ShiftFaceNet,该模型仅包含78万个参数。
按照[15],我们通过结合softmax损失和中心损失[23]来训练FaceNet和ShiftFaceNet。我们在三个用于人脸验证的数据集上评估提出的方法
表8:SHIFT-FACENET VS FACENET的脸部验证准确性[18]
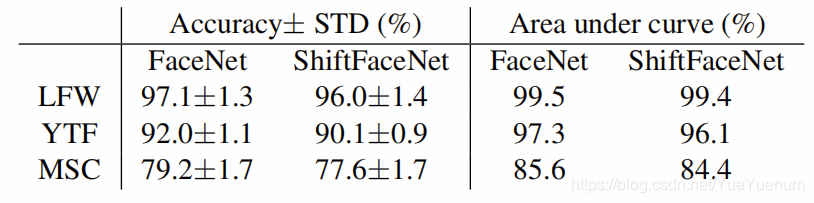
表9:SHIFT-FACENET VS FACENET的面部验证参数[18]
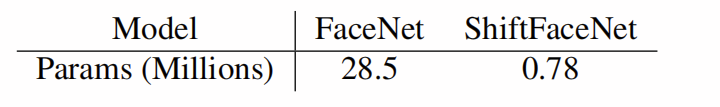
验证:给定一对脸部图像,选择距离阈值以对属于相同或不同实体的两个图像进行分类。 LFW数据集[8]由13323张网络照片和6000张脸对组成。 YTF数据集[24]包含3,425个和5,000个视频对,用于视频级人脸验证。 MS-Celeb-1M数据集(MSC)[3]包含用于99,892个实体的8,456,240张图像。 在我们的实验中,我们从MSC中随机选择10,000个实体作为我们的训练集,以学习嵌入空间。 我们测试了LFW中的6,000对,YTF中的5,000对以及MSC随机生成的100,000对(不包括训练集)。
在预处理步骤中,我们使用多任务CNN检测并对齐所有面孔[28]。 按照[18],两个视频之间的相似度被计算为100个随机帧对的平均相似度,每个视频对一个。 结果显示在表8中。原始FaceNet和我们建议的ShiftFaceNet的参数大小显示在表9中。使用ShiftFaceNet,我们可以将参数大小减少35倍,而在上述三个方面,精度最多降低2% 验证基准。
-
样式转移
艺术样式转移是移动设备上的另一个流行应用程序。 这是一个图像转换任务,目标是将一个图像的内容与另一个图像的样式结合在一起。 尽管这是一个不确定的问题,没有明确的量化指标,但成功的样式转换要求网络同时捕获内容和样式图像的微小纹理和整体语义。
按照[2,11],我们使用感知损失函数来训练样式转换器。 在我们的实验中,我们使用在ImageNet上预训练的VGG16网络来生成感知损失。 由Johnson等人训练的原始网络。
[11]由三个下采样卷积层,五个残差模块和三个上采样卷积层组成。 所有非残积卷积后跟有实例标准化层[22]。 在我们的实验中,我们将除第一个和最后一个卷积层以外的所有层都移位,然后再移位1x1卷积。 我们使用先前报告的数据在COCO [14]数据集上训练网络
表10:样式转移:移位VS卷积
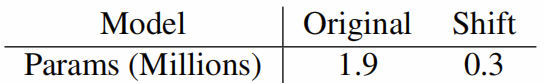
超参数设置![]() 。 通过用移位代替卷积,我们可以将参数数量总体上减少6倍,而图像质量的下降却最小。 由原始和基于偏移的变压器网络生成的风格化图像示例可在图6中找到。
。 通过用移位代替卷积,我们可以将参数数量总体上减少6倍,而图像质量的下降却最小。 由原始和基于偏移的变压器网络生成的风格化图像示例可在图6中找到。
-
讨论
在我们的实验中,我们证明了移位运算可以替代空间卷积。 我们的班次组的构建很简单:我们为每个班次分配固定数量的渠道。 但是,此分配在很大程度上是不知情的。 在本节中,我们将进一步探讨形式分配和潜在的改进。
理想的信道分配至少应具有以下2个属性:1)同一换档组中的功能不应有多余。 我们可以通过检查班次组中通道激活之间的相关性来衡量冗余度。 2)每个移位特征对输出的贡献均应不小。 我们可以通过![]() (即CSC模块中第二个点向卷积内核的第m行的l2范数)来测量channel-m对输出的贡献。
(即CSC模块中第二个点向卷积内核的第m行的l2范数)来测量channel-m对输出的贡献。
-
班次中的通道相关性
我们从训练有素的ShiftResnet20模型中分析一个CSC模块,该模块具有16个输入/输出通道和9的扩展。 我们首先按班次对渠道进行分组。 假设每个班次包含c个频道。 我们将c通道的激活视为随机变量![]() 。 我们将来自CIFAR100的验证图像输入网络,并在CSC模块中记录中间激活,以估计相关矩阵
。 我们将来自CIFAR100的验证图像输入网络,并在CSC模块中记录中间激活,以估计相关矩阵![]() ,其中一些如图8所示。我们使用通道之间的相关作为代理 用于测量冗余。 例如,如果两个通道之间的相关性高于阈值,则可以删除一个通道。 在图8中,候选对可能来自于第一矩阵中稍微偏心的亮绿色像素。
,其中一些如图8所示。我们使用通道之间的相关作为代理 用于测量冗余。 例如,如果两个通道之间的相关性高于阈值,则可以删除一个通道。 在图8中,候选对可能来自于第一矩阵中稍微偏心的亮绿色像素。
-
标准化的渠道贡献
我们从上一节中分析了相同的CSC模块。 考虑第m个通道对模块输出的贡献,我们将点积卷积核的第m个行的范数作为![]() 近似为“贡献”。 我们在给定的CSC模块中计算所有144个通道的贡献,对其归一化并在图7中进行绘制。请注意,位移贡献是各向异性的,并且最大的贡献落在一个交叉点上,在该交叉点上,水平信息得到了强调。
近似为“贡献”。 我们在给定的CSC模块中计算所有144个通道的贡献,对其归一化并在图7中进行绘制。请注意,位移贡献是各向异性的,并且最大的贡献落在一个交叉点上,在该交叉点上,水平信息得到了强调。

图6:使用SHIFTNET的样式转移结果
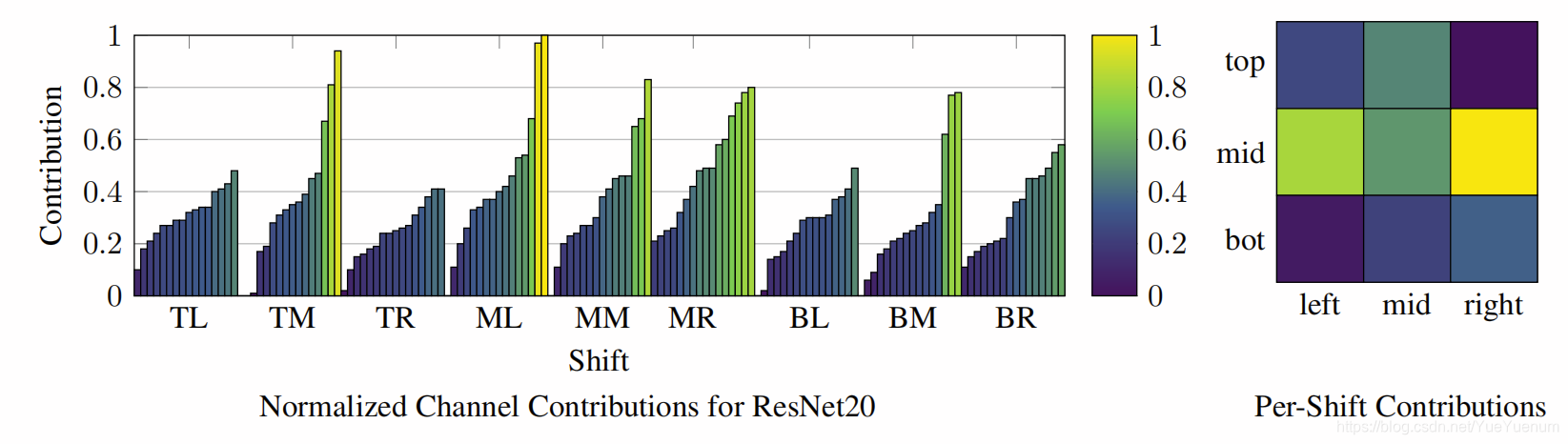
图7:左图:我们绘制归一化渠道贡献。 沿水平轴,我们将通道分为9组,每组16个(每班一组),B =底部,M =中,T =顶部,R =右侧,L =左侧。 右:对于每个班次模式,我们将其贡献的总和标准化为相同的比例。 两个图共享相同的颜色图,其中黄色的幅度最大
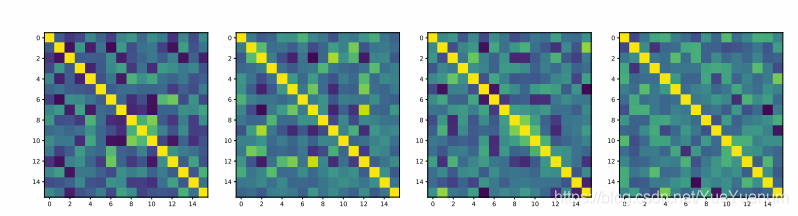
图8:每个移位组中的示例通道相关矩阵
这表明,更好的试探法在班次之间分配通道可能会产生具有更高的每FLOP和每参数精度的神经网络。
-
结论
我们提出了移位运算,零FLOP,零参数,易于实现的卷积替代方案,以进行空间信息聚合。 首先,我们使用移位运算和逐点卷积构造端到端可训练模块。 为了证明其有效性和鲁棒性,我们用移位模块替换了ResNet的卷积,以适应各种模型尺寸的约束,在相同数量的参数/ FLOP的情况下,其精度提高了8%,而在三分之一的参数/中,恢复了精度。 襟翼。 然后,我们构建基于移位的神经网络家族。 在具有约400万个参数的神经网络中,我们在许多任务(分类,面部验证和样式转换)上均具有竞争优势。 将来,我们计划将ShiftNets应用于需要大接收域的任务,而这些接收域对于卷积(例如4K图像分割)来说是非常昂贵的。
致谢
这项工作得到了DARPA PER FECT计划HR0011-12-2-0016奖的部分支持,并与ASPIRE Lab赞助商Intel以及实验室分支机构HP,华为,Nvidia和SK Hynix一起获得了支持。 这项工作还得到了宝马,英特尔和三星全球研究组织的个人礼物的部分赞助。 我们感谢于斐(Fisher Yu),王欣(Vin Wang)的宝贵讨论。 感谢Kostadin Ilov提供的系统帮助。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









