 基于标签和上下文的推荐系统算法解析
基于标签和上下文的推荐系统算法解析





【推荐系统实战(三)】利用用户标签数据、利用上下文信息
利用用户标签数据
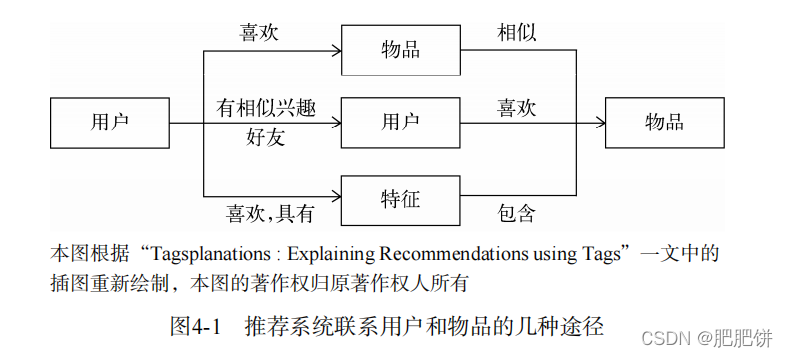
如图4-1所示,第一种方式是利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,这就是前面提到的基于物品的算法。第二种方式是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,这是前面提到的基于用户的算法。除了这两种方法,第三种重要的方式是通过一些特征(feature)联系用户和物品,给用户推荐那些具有用户喜欢的特征的物品。这里的特征有不同的表现方式,比如可以表现为物品的属性集合(比如对于图书,属性集合包括作者、出版社、主题和关键词等),也可以表现为隐语义向量(latent factor vector),这可以通过前面提出的隐语义模型习得到。本章将讨论一种重要的特征表现方式——标签。
根据给物品打标签的人的不同,标签应用一般分为两种:一种是让作者或者专家给物品打标签;另一种是让普通用户给物品打标签,也就是UGC(User Generated Content,用户生成的内容)的标签应用。UGC的标签系统是一种表示用户兴趣和物品语义的重要方式。当一个用户对一个物品打上一个标签,这个标签一方面描述了用户的兴趣,另一方面则表示了物品的语义,从而将用户和物品联系了起来。因此本章主要讨论UGC的标签应用,研究用户给物品打标签的行为,探讨如何通过分析这种行为给用户进行个性化推荐。
如

标签系统中的推荐问题
打标签作为一种重要的用户行为,蕴含了很多用户兴趣信息,因此深入研究和利用用户打标
签的行为可以很好地指导我们改进个性化推荐系统的推荐质量。同时,标签的表示形式非常简单,
便于很多算法处理。
标签系统中的推荐问题主要有以下两个。
- 如何利用用户打标签的行为为其推荐物品(基于标签的推荐)?
- 如何在用户给物品打标签时为其推荐适合该物品的标签(标签推荐)?
为了研究上面的两个问题,我们首先需要解答下面3个问题。 - 用户为什么要打标签?
- 用户怎么打标签?
- 用户打什么样的标签?
基于标签的推荐系统
用户用标签来描述对物品的看法,因此标签是联系用户和物品的纽带,也是反应用户兴趣的重要数据源,如何利用用户的标签数据提高个性化推荐结果的质量是推荐系统研究的重要课题。
一个用户标签行为的数据集一般由一个三元组的集合表示,其中记录(u, i, b) 表示用户u给物品i打上了标签b。当然,用户的真实标签行为数据远远比三元组表示的要复杂,比如用户打标签的时间、用户的属性数据、物品的属性数据等。但是本章为了集中讨论标签数据,只考虑上面定义的三元组形式的数据,即用户的每一次打标签行为都用一个三元组(用户、物品、标签)表示。
本章将采用两个不同的数据集评测基于标签的物品推荐算法。一个是Delicious数据集,另一
个是CiteULike数据集。Delicious数据集中包含用户对网页的标签记录。它每一行由4部分组成,
即时间、用户ID、网页URL、标签。本章只抽取了其中用户对一些著名博客网站网页(Wordpress、
BlogSpot、TechCrunch)的标签记录。
对于用户u,令R(u)为给用户u的长度为N的推荐列表,里面包含我们认为用户会打标签的物品。令T(u)是测试集中用户u实际上打过标签的物品集合。然后,我们利用准确率(precision)和召回率(recall)评测个性化推荐算法的精度。
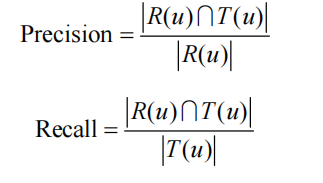
为了全面评测个性化推荐的性能,我们同时评测了推荐结果的覆盖率(coverage)、多样性
(diversity)和新颖度。
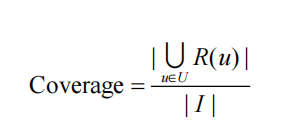
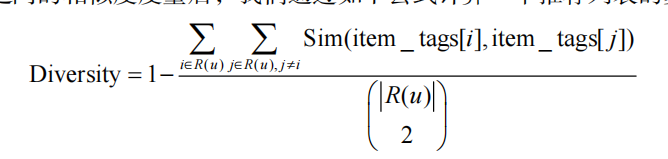
一个简单的算法
这个算法的描述如下所示。
- 统计每个用户最常用的标签。
- 对于每个标签,统计被打过这个标签次数最多的物品。
- 对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这
个用户。
对于上面的算法,用户u对物品i的兴趣公式如下:
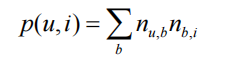
这里,B(u)是用户u打过的标签集合,B(i)是物品i被打过的标签集合, n u , b n_{u,b} nu,b是用户u打过标签b
的次数, n b , i n_{b,i} <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









