




无论在什么领域,订单业务都是一个比较复杂且典型的场景,考虑到本文的读者可能来自不同的行业,为了便于大家理解,这里我们选择了商城订单业务中的用户下单场景来演示DDD的编码实践。以此来为读者逐步展开讲述DDD战术设计中的实践形式。
1. 限界上下文拆分
在DDD战术设计前期,我们首先要做的就是限界上下文的拆分。本例中我们选了三个限界上下文:订单上下文、商品上下文和调度上下文,每个上下文可能都对应一个业务系统,他们之间通过远程调用的方式进行交互(实际业务场景会更复杂,可能还会有权益、库存、营销、物流等上下文)
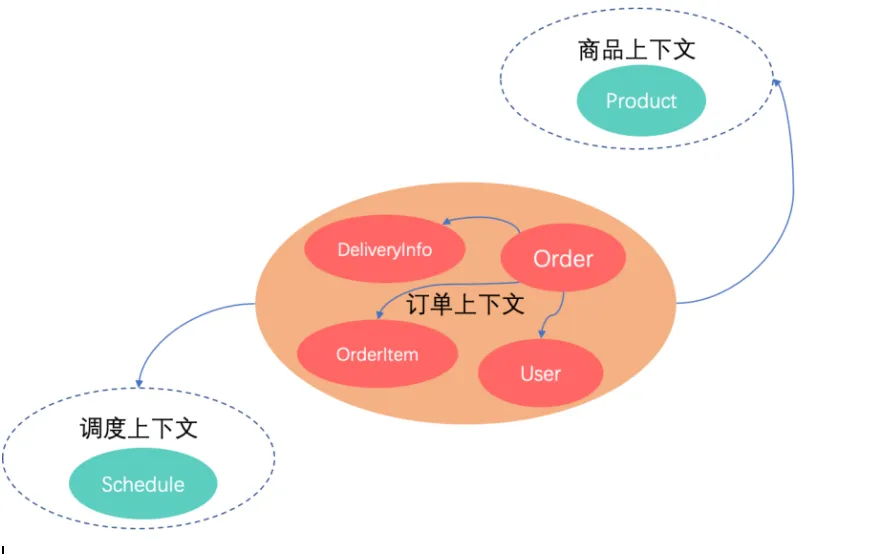
编码原则:业务模型决定数据模型
实践:与传统设计不同,基于DDD战术设计的编码需要自上而下,先设计业务领域模型,再通过领域模型的业务行为去识别和设计最终的数据模型。这种设计是真正面向业务的,而不是把关注点放在技术性的数据模型上。
注:这样做并不是必须的,但从实践上来看,自上而下比自下而上的设计方式更容易编排业务逻辑
画外音:聚合和聚合根
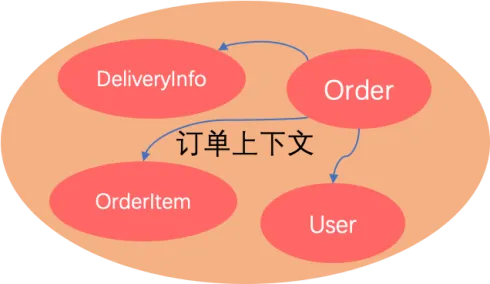
在实践DDD过程中,聚合和聚合根的概念一直都是比较难以理解和设计的,这里为这两个概念做一个通俗的解释:
聚合是由一系列相关的领域模型组合而成,例如订单域:Order(订单) + OrderItem(订单项) +
DeliveryInfo(配送地址)可以组成一个聚合,从订单上下文的角度来说这个聚合逻辑的聚合根就是Order。
Order(订单):一次购物订单
OrderItem(订单项):订单项一:一份鸡翅,订单项二:一杯可乐
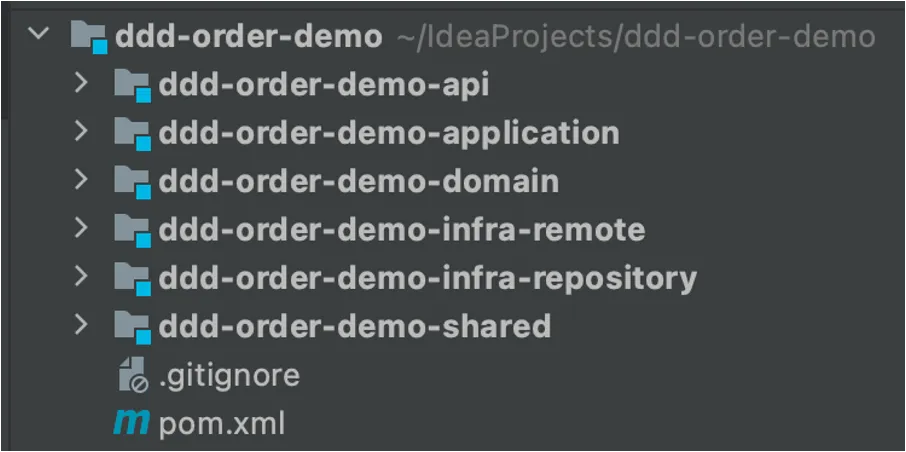
2. 模块及分包
用户界面层
ddd-demo/
├── ddd-order-demo-api ------ 用户界面层-REST
│ ├── src
│ │ └── main
│ │ ├── java
│ │ │ └── cn
│ │ │ └── huolala
│ │ │ └── demo
│ │ │ ├── DemoApiApplication.java ------ starter
│ │ │ └── api
│ │ │ └── controller ------ 客户端接口
│ │ │ ├── UserController.java
│ │ │ └── OrderController.java
│ │ └── resources
│ │ └── application.yml
模块举例:controller、provider、task、mq-consumer
模块分析:
用户界面层是客户端的统一入口,它只用于处理用户展示和用户请求,不会包含业务逻辑。但是,用户界面层也有它自己的逻辑,例如对用户的输入参数进行验证,但这种验证要跟领域层的验证逻辑区分开。比如对必传参数的空值校验,对数值类型参数的类型校验,这些都是用户界面层的职责;但如果要验证某个参数对应的业务数据是否存在,这种验证就应该是领域或业务逻辑的验证。在DDD编程模型中,这两种职责要区分开。
用户界面层的请求和响应参数不在此层中定义,而是定义到了应用服务层,这样做的好处就是少了一次参数模型转换,应用服务层可以直接使用用户界面层的请求和响应参数(不建议把用户界面层的请求和响应模型定义到公共包中(如common包),因为这样做可能造成后期模型的滥用),弊端就是会在一定程度上破坏代码的封装性。
用户界面层的响应实体要在此层中定义并转换,因为为了兼容多个用户界面层,应用服务层只会返回跟业务相关的领域模型,每个用户界面层对应的客户所需要的响应体可能是不同的,这时候每个用户界面层就需要把领域模型转换为不同客户方所需要的模型。(转换器最好也定义到应用服务层,如果定义到用户界面层,当不同客户端需要同一个参数时,在各个客户端对应用户界面层都需要定义相同的转换器)
应用服务层
ddd-demo/
├── ddd-order-demo-application ------ 应用服务层,主要做业务编排,协调领域层做业务聚合
│ ├── src
│ │ └── main
│ │ └── java
│ │ └── cn
│ │ └── huolala
│ │ └── demo
│ │ └── application
│ │ ├── convertor ------ 模型转换器
│ │ │ ├── OrderConvertor.java
│ │ │ └── UserConvertor.java
│ │ ├── pojo
│ │ │ ├── cmd ------ 用户界面层写请求参数
│ │ │ │ ├── OrderChangeItemCmd.java
│ │ │ │ ├── OrderCreateCmd.java
│ │ │ │ └── co ------ cmd的子结构
│ │ │ │ └── OrderCreateProductItemCO.java
│ │ │ └── query ------ 用户界面层读请求参数
│ │ │ │ ├── UserQuery.java
│ │ │ │ └── qo ------ query的子结构
│ │ │ └── response ------ 用户界面层的响应模型
│ │ │ ├── OrderResponse.java
│ │ │ └── UserResponse.java
│ │ └── service ------ 应用服务层service,业务编排
│ │ ├── OrderService.java
│ │ └── UserService.java
模块分析:
为了减少模型转换带来的额外工作量,我们把用户界面层的请求和响应模型定义到了应用服务层(cn.huolala.demo.application.pojo),并把读写请求分离开,以便后期可以扩展CQRS架构模型。
在应用服务层,除了必要的参数模型外,就是我们传统三层架构所熟知的service
应用服务层不同于传统的业务逻辑层,它是非常轻量的,应用服务本身不处理业务逻辑,它是领域模型的直接客户,主要职责是用来协调领域模型做业务编排,此外,应用服务层也是表达用例和用户故事的主要手段。
领域层
ddd-demo/
├── ddd-order-demo-domain ------ 领域层,承载当前限界上下文的所有业务逻辑
│ ├── src
│ │ ├── main
│ │ │ ├── java
│ │ │ │ └── cn
│ │ │ │ └── huolala
│ │ │ │ └── demo
│ │ │ │ └── domain
│ │ │ │ ├── convertor
│ │ │ │ ├── infra ------ 基础设施相关接口
│ │ │ │ │ ├── mq ------ 基础设施-消息事件
│ │ │ │ │ │ └── OrderMessageProducer.java
│ │ │ │ │ ├── remote ------ 基础设施-远程调用
│ │ │ │ │ │ ├── IProductRemoteService.java
│ │ │ │ │ │ └── IScheduleRemoteService.java
│ │ │ │ │ └── repository ------ 基础设施-资源库
│ │ │ │ │ ├── IDeliveryAddressRepository.java
│ │ │ │ │ ├── IOrderRepository.java
│ │ │ │ │ └── IUserRepository.java
│ │ │ │ ├── model ------ 领域模型
│ │ │ │ │ ├── order ------ 子域-核心域
│ │ │ │ │ │ ├── DeliveryInfo.java
│ │ │ │ │ │ ├── LockInventoryResponse.java
│ │ │ │ │ │ ├── Order.java ------ 实体
│ │ │ │ │ │ ├── OrderDomainEvent.java
│ │ │ │ │ │ ├── OrderEvent.java
│ │ │ │ │ │ ├── OrderEventTypeEnum.java
│ │ │ │ │ │ ├── OrderItem.java
│ │ │ │ │ │ ├── OrderStateEnum.java
│ │ │ │ │ ├── product ------ 子域
│ │ │ │ │ │ └── Product.java
│ │ │ │ │ └── user ------ 子域
│ │ │ │ │ ├── User.java
│ │ │ │ │ └── UserStateEnum.java
│ │ │ │ └── service ------ 领域服务
│ │ │ │ ├── OrderDomainService.java
│ │ │ │ └── ProductDomainService.java
模块分析:
领域层是整个架构的核心业务层,它不依赖其他任何的外部组件,领域层的职责就是通过领域实体和领域服务来聚合业务逻辑;领域服务并不是必须的,如果业务逻辑都可以用领域实体来完成,这个时候就不需要领域服务;那领域服务主要是做那些事情的呢?
不属于单个聚合根的业务,需要用领域服务去协调多个聚合完成业务逻辑
静态方法(在实践中,也可以为静态方法单独定义工具类,例如静态的验证器validator,静态的模型转换器convertor)
调用其他外部服务(如RPC)处理业务的,在拿到外部模型后,可能需要在领域服务中做业务校验或领域模型转换
cn.huolala.demo.domain.model包中定义了当前限界上下文所需要的所有领域模型(包括了非当前上下文),这些模型在DDD中也称为实体,它们都是充血模型,业务的聚合都由它们(cn.huolala.demo.domain.model.order.Order) + 领域服务(如cn.huolala.demo.domain.service.OrderDomainService)来实现。
我们会在领域层中定义基础设施接口
(包cn.huolala.demo.domain.infra),以此来实现基础设施的依赖倒置。这里的做法是把基础设施做了进一步的拆分(例如资源库repository、远程服务调用remote、消息事件mq);还有一种比较好的实践:不对基础设施做进一步的区分,把所有的基础设施都视为资源,只定义资源库接口,这样的好处是在修改技术组件时,业务逻辑层可以做到0改动。
注:还有另外一种分包方式,就是把跟领域模型相关的所有基础设施放到一个包中,好处是可以使业务模型更加稳定,弊端是会破坏组件的封装性。
基础设施层
ddd-demo/
├── ddd-order-demo-infra-remote ------ 基础设施层-远程服务调用;访问外部限界上下文
│ ├── pom.xml
│ ├── src
│ │ └── main
│ │ └── java
│ │ └── cn
│ │ └── huolala
│ │ └── demo
│ │ └── remote
│ │ ├── client ------ 外部服务接口定义(REST)
│ │ │ ├── ProductApiClient.java
│ │ │ ├── ScheduleApiClient.java
│ │ │ ├── request ------ 外部服务调用请求参数
│ │ │ │ ├── BaseRemoteRequest.java
│ │ │ │ └── LockInventoryRequest.java
│ │ │ └── response ------ 外部服务调用响应体
│ │ │ ├── BaseRemoteResponse.java
│ │ │ └── ResponseMessageEnum.java
│ │ ├── convertor ------ 转换器,用于外部请求参数或响应体与领域模型的转换
│ │ │ └── OrderConvertor.java
│ │ ├── service ------ 防腐层,实现了领域层Remote接口,所有外部服务的调用入口
│ │ │ ├── ProductRemoteService.java
│ │ │ └── ScheduleRemoteService.java
├── ddd-order-demo-infra-repository ------ 基础设施层-资源库;数据模型与持久化相关
│ ├── pom.xml
│ ├── src
│ │ └── main
│ │ ├── java
│ │ │ └── cn
│ │ │ └── huolala
│ │ │ └── demo
│ │ │ ├── convertor ------ 转换器,用于数据模型和领域模型的转换
│ │ │ │ ├── DeliveryAddressConvertor.java
│ │ │ │ ├── OrderConvertor.java
│ │ │ │ ├── OrderItemConvertor.java
│ │ │ ├── entity ------ 数据模型
│ │ │ │ ├── DeliveryAddressEntity.java
│ │ │ │ ├── OrderEntity.java
│ │ │ │ ├── OrderItemEntity.java
│ │ │ └── repository ------ 资源库
│ │ │ ├── DeliveryAddressRepository.java
│ │ │ ├── OrderRepository.java
│ │ │ ├── OrderRepositoryES.java
│ │ │ └── mapper
│ │ │ ├── DeliveryAddressMapper.java
│ │ │ ├── OrderItemMapper.java
│ │ │ ├── OrderMapper.java
模块分析:
不管是数据持久化、缓存、事件、RPC、REST,只要是与数据和资源有关的内容,都可以是基础设施的范畴。基础设施层隐藏了技术实现细节,使我们更加关注业务代码,减少了技术实现细节对业务代码的侵入性。
如果是倾向于架构模式清晰,可以为不同的资源获取方式定义不同的组件(本篇示例的做法);如果更加倾向业务模型的稳定性,则可以为所有的基础设施只定义一个组件层级(也就是只有一个infra模块)。
举个例子:某项业务发展到一定规模后,需要对服务进行拆分,如果是传统分层架构模型,势必要在业务代码中修改或替换模型代码;如果我们使用了依赖倒置的六边形插件架构,我们就可以做到完全不修改业务代码:领域层定义的资源库接口不变,在基础设施层直接把原来数据库的实现改为远程调用的实现,业务代码0改动。之所以可以这么做,就是因为我们从架构层面限制了技术模型和业务模型的耦合关系,并对基础设施层应用了依赖倒置,领域层不会关心基础设施是由什么技术实现的,只需要给领域层所需要的领域模型就可以了。这正符合了整洁架构的依赖关系原则:外层的变更不应该影响内层的代码。
示例中把数据库资源和远程服务资源分为两个基础设施组件还有一个特殊的原因:数据库资源在当前上下文是可以随意操作的,也就是增删改查,而且数据模型之间也会有复杂的关联关系,这种关系需要在领域层映射成领域实体的业务关系,所以领域模型和数据模型本质上就是不同的(也就是数据-对象的阻抗失调,如果使用JPA,则可以减小这种阻抗失调的影响);但是对于外部上下文的资源,我们多数是读操作,而且外部上下文返回的数据模型不会轻易修改,所以我们也可以把外部上下文的数据模型直接当做领域模型来使用,这样也避免了额外的一次模型转换。
DDD架构模型的分包规则符合最大复用和最小闭包原则,各层模型分包独立,互不影响。
例如:作为用户界面层,controller和provider返回的模型可能会是不一致,所以我们把具体的返回模型包装在在各自的层级中,应用服务层只负责输出领域模型,由各个用户界面层决定把领域模型转换为各自返回给客户的模型。
3. 示例:用户下单场景
类调用链
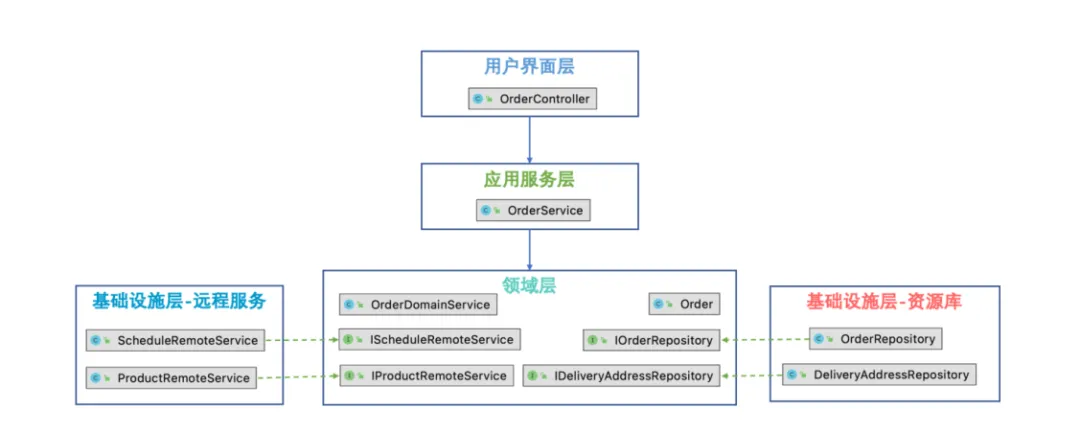
用户界面层-OrderController
@RestController
@RequestMapping("/order")
public class OrderController {
@Resource
OrderService orderService;
@PostMapping(name = "/create")
public OrderResponse create(OrderCreateCmd cmd) {
return OrderConvertor.convertToResponse(orderService.createOrder(cmd));
}
}
代码解释:用户界面层作为用户请求的入口,是没有任何业务相关逻的,它对参数进行基础的验证后(本例的参数校验通过参数注解的方式实现),把用户请求交给应用服务层去处理,然后接收应用服务层返回的领域模型,转换为用户需要的返回模型。
应用服务层-OrderService
@Transactional(rollbackFor = Exception.class)
public Order createOrder(OrderCreateCmd cmd) {
String orderNo = UUID.randomUUID().toString();
//从资源库获取用户
Optional<User> userOptional = userRepository.findById(cmd.getUserId());
User user = userOptional.orElseThrow(() -> new DemoBusinessException("用户不存在"));
//把参数转换为领域模型,可以定义convertor来进行转换
List<OrderItem> orderItemList = makeOrderItems(cmd.getProductItems(), orderNo);
//商品域-检查库存,product和OrderItem属于两个域,且使用了外部product服务,所以使用领域服务
orderDomainService.checkInventoryAndAssembleOrderItems(orderItemList);
//配送地址
Optional<DeliveryAddress> deliveryInfoOptional = deliveryAddressRepository.findById(cmd.getDeliveryAddressId());
DeliveryAddress deliveryAddress = deliveryInfoOptional.orElseThrow(() -> new DemoBusinessException("配送信息不存在"));
//创建订单,最好的方式是使用工厂
Order order = Order.create(orderNo, deliveryAddress, orderItemList, user.getUserId());
//调度域-锁定库存,用到了远程服务,所以放到了领域服务
orderDomainService.lockInventory(order);
//创建订单
orderRepository.createOrder(order);
//发布订单创建事件
orderMessageProducer.publish(order, OrderEventTypeEnum.INIT);
//返回领域模型,由用户界面层决定转为什么样的模型, 从架构层面限制模型滥用和模型滥转
return order;
}
代码解释:
-
应用服务层是很轻量的,它不做任何业务逻辑的处理,通过协调实体和资源库来达成业务结果,而具体的业务逻辑在聚合根中实现。
-
因为有跨多个子域的操作,
order、product、OrderItem等,且使用了外部服务(商品上下文和调度上下文),所以我们使用了orderDomainService领域服务 -
应用服务层统一返回的是领域对象,由用户接口层决定转为什么样的模型(因为用户界面层可能有多个,对应着不同的客户端,不同的客户端锁需要的数据模型可能不同),从架构层面限制模型滥用和模型滥转。
在上面代码逻辑中,对商品进行库存校验和锁定库存时都使用到了订单领域服务进行业务编排(OrderDomainService.checkInventoryAndAssembleOrderItems和OrderDomainService.lockInventory),具体实现如下:
领域服务 - OrderDomainService:
/**
* 检查库存,组装订单项
* @param orderItems
* @return
*/
public void checkInventoryAndAssembleOrderItems(List<OrderItem> orderItems) {
if (CollectionUtils.isEmpty(orderItems)) {
throw new DemoBusinessException("未选择商品");
}
//从商品服务获取商品信息
List<Long> productIds = orderItems.stream().map(OrderItem::getProductId).collect( Collectors.toList());
List<Product> productList = productRemoteService.getProductInfos(productIds);
if (CollectionUtils.isEmpty(productList)) {
throw new DemoBusinessException("未查询到商品信息");
}
Map<Long, Product> productMap = productList.stream().collect(Collectors.toMap(Product::getProductId, p -> p));
//库存校验
for (OrderItem item : orderItems) {
Product product = productMap.get(item.getProductId());
if (product == null)
throw new DemoBusinessException("商品[" + item.getProductName() + "]不存在");
if (product.getInventoryCount() < item.getCount())
throw new DemoBusinessException("商品[" + product.getProductName() + "]库存不足");
//组装订单项信息
item.setPrice(product.getPrice());
item.setProductName(product.getProductName());
}
}
/**
* 锁定库存
*
* @param order
*/
public void lockInventory(Order order) {
Optional<LockInventoryResponse> lockInventoryDTOOptional = scheduleRemoteService.lockInventory(order);
LockInventoryResponse lockInventoryResponse = lockInventoryDTOOptional.orElseThrow(() -> new DemoBusinessException("库存锁定失败"));
if (lockInventoryResponse.getLockEndTime().before(new Date())) {
throw new DemoBusinessException("库存锁定失败");
}
order.setLockInventoryEndTime(lockInventoryResponse.getLockEndTime());
}
代码解释:因为这些逻辑都涉及了对两个域的操作(订单-商品、订单-调度) ,并且使用了远程服务调用,所以这里我们需要使用领域服务去协调聚合逻辑。
问:为什么检查库存的逻辑放到了订单领域服务,而不是商品领域服务?
一是因为这段逻辑属于是对订单的聚合逻辑,二是商品域属于另外一个限界上下文,我们一般不会为非当前上下文的领域建立领域服务(除非有很强的复用价值,例如通用子域)。
聚合根-Order:
//……省略其他方法
/**
* 创建订单
* @param orderNo
* @param deliveryAddress
* @param orderItemList
* @param userId
* @return
*/
public static Order create(String orderNo, DeliveryAddress deliveryAddress, List<OrderItem> orderItemList, Long userId) {
Order order = new Order();
order.setOrderNo(orderNo);
order.setDeliveryAddress(deliveryAddress);
order.setOrderItemList(orderItemList);
order.setUserId(userId);
order.initialize();
return order;
}
//订单状态初始化
public void initialize() {
this.setStatus(OrderStateEnum.INIT.getValue());
this.setOrderTime(new Date());
calculateTotalPrice();
}
public void setTotalPrice(Long totalPrice) {
if (Objects.isNull(totalPrice) || totalPrice < 0)
throw new DemoBusinessException("Illegal totalPrice");
this.totalPrice = totalPrice;
}
public void setOrderNo(String orderNo) {
if (StringUtils.isBlank(orderNo))
throw new DemoBusinessException("orderNo can not be null");
this.orderNo = orderNo;
}
//……省略其他方法
代码解释:
在第一节中,我们讨论了聚合和聚合根的区别,聚合根也是DDD编程模型和传统编程模型之间的一个重要区别。在DDD中,模型不仅仅是数据的载体(即“贫血模型”),而是具有行为的实体(即“充血模型”)。通过聚合多个模型,聚合根能够实现复杂的业务逻辑,而不仅仅作为传输对象。(考虑到改造的复杂性,读者也可以选择不使使用充血模型,把业务逻辑交由领域服务来实现,也就是“DDD-Lite”)
在传统的贫血模型中,我们习惯使用构造方法来完成对象的创建,但是构造方法不能有效的表达通用语言(new order和 create order的语义区别),所以我们这里使用聚合根来创建对象。其实复杂对象的创建最好是由工厂来实现,但是引入工厂的概念会带来额外的复杂性,为了简化框架,我们这里的做法是不再单独抽象工厂,而是让聚合根去承担了工厂的职责。这样做也是合理的,因为聚合根本身就承载了多个领域对象。
我们在给对象赋值时,把操作委派给对象自身对应的setter方法,这样的好处就是保证了对象的自封装性。使创建对象这一操作更加安全。自封装性使验证变的更加简单,一次编写,随处可用(但要注意对象传输时的序列化时的问题,如setter对json的序列化的影响,这里也体现了领域对象不适合做传输对象的原因)。
基础设施(远程调用)-productRemoteService
public class ProductRemoteService implements IProductRemoteService {
@Resource
ProductApiClient productApiClient;
@Override
public List<Product> getProductInfos(List<Long> productIds) {
BaseRemoteResponse<List<Product>> response = productApiClient.getProductInfos(productIds);
if (response == null || response.failed()) {
log.error("getProductInfos error,request:{},response:{}", productIds, response);
return Collections.emptyList();
}
return response.getData();
}
}
代码解释:本例中我们用的是openfeign来实现远程调用,我们把远程调用模块作为基础设施来实现,也是为了后期更好的扩展,比如我现在是http实现,后期要改RPC,也可以不修改业务代码,只修改基础设施层,就可以完成优化和扩展。
基础设施(资源库)- OrderRepository:
@Repository
public class OrderRepository implements IOrderRepository {
@Resource
OrderMapper orderMapper;
@Resource
OrderItemMapper orderItemMapper;
@Resource
private RedisTemplate<String, Object> redisTemplate;
@Resource
private ElasticsearchTemplate<OrderEntityES, Long> orderESTemplate;
public Optional<Order> findById(long orderId) {
return Optional.ofNullable(OrderConvertor.convertToDO(elasticsearchTemplate.getById(orderId,OrderEntity.class)));
}
/**
* 创建订单
* @param order
*/
@Override
public void createOrder(Order order) {
//保存订单
OrderEntity orderEntity = OrderConvertor.convertToEntity(order);
orderMapper.insert(orderEntity);
order.setOrderId(orderEntity.getId());
//保存订单项
List<OrderItem> orderItemList = order.getOrderItemList();
orderItemList.forEach(orderItem -> {
orderItem.setOrderId(orderEntity.getId());
orderItemMapper.insert(OrderItemConvertor.INSTANCT.convertToEntity(orderItem));
});
}
}
代码解释:
相对于传统的dao层,资源库的职责更广,在本例中,我们可以在资源库里操作任何的基础存储单元(数据库、redis、elastic search等),这样做的好处就如咱们介绍六边形架构的时候说的一样:不管存储单元如何更换,都不会影响到核心的业务逻辑代码。
我们并没有为订单和订单项都单独创建一个资源库,因为我在创建订单的时候肯定也要同步去保存订单项的,所以我们只为订单这个聚合分配了一个资源库,这也是DDD推荐的标准做法,这样可以保证逻辑的内聚性,防止逻辑分散在领域层。如果我们使用hibernate的cascade(级联)注解的话,这个内聚性会的体现更强。
模型转换问题:我们可以看到,资源库接收到的都是领域模型,输出的也是领域模型,这样的好处就是,我们对业务领域层完全隐藏了技术实现细节,不管你的表结构怎么变,存储组件怎么更换,都不会影响到领域层的业务逻辑,因为领域层压根就不关注数据模型(OrderEntity)。从架构层面上来说,我们应用了依赖倒置,领域层也根本就不能使用基础设施层的数据模型(OrderEntity)。
4. 小结
在前文中,我们花了较长的篇幅,通过一个典型的业务场景——商城用户下单场景,为大家详细演示了DDD战术设计的架构、模块以及编码实践。通过这个具体示例,希望能够帮助读者更好地理解DDD在实际业务中的应用,并为后续内容的讲解打下基础。
接下来,将分享在货拉拉CRM系统中进行DDD战术设计改造的实践经验,介绍货拉拉是如何结合实际业务需求,将DDD的理念和方法落地实施。

















 169万+
169万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









