



本文转载自机器之心。
屠榜各大 CV 任务的微软 Swin Transformer,近日开源了代码和预训练模型。
自 2017 年 6 月谷歌提出 Transformer 以来,它便逐渐成为了自然语言处理领域的主流模型。最近一段时间,Transformer 更是开启了自己的跨界之旅,开始在计算机视觉领域大展身手,涌现出了多个基于 Transformer 的新模型,如谷歌用于图像分类的 ViT 以及复旦、牛津、腾讯等机构的 SETR 等。由此,「Transformer 是万能的吗?」也一度成为机器学习社区的热门话题。
不久前,微软亚研的研究者提出了一种通过移动窗口(shifted windows)计算的分层视觉 Transformer,他们称之为 Swin Transformer。相比之前的 ViT 模型,Swin Transformer 做出了以下两点改进:其一,引入 CNN 中常用的层次化构建方式构建分层 Transformer;其二,引入局部性(locality)思想,对无重合的窗口区域内进行自注意力计算。

论文链接:https://arxiv.org/pdf/2103.14030.pdf
首先来看 Swin Transformer 的整体工作流,下图 3a 为 Swin Transformer 的整体架构,图 3b 为两个连续的 Swin Transformer 块。
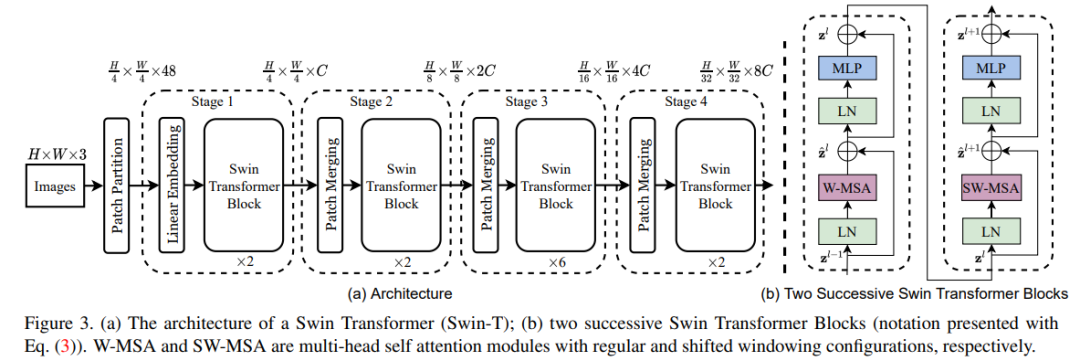
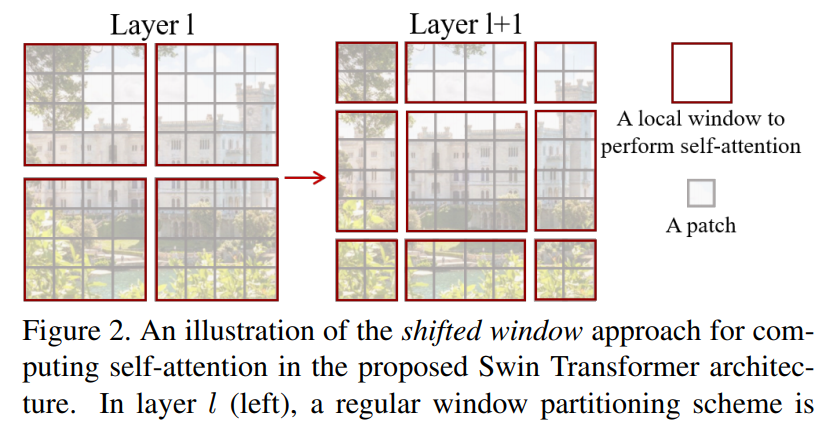
该研究的亮点在于利用移动窗口对分层 Transformer 的表征进行计算。通过将自注意力计算限制在不重叠的局部串口,同时允许跨窗口连接。这种分层结构可以灵活地在不同尺度上建模,并具有图像大小的线性计算复杂度。下图 2 为在 Swin Transformer 架构中利用移动窗口计算自注意力的工作流:
模型本身具有的特性使其在一系列视觉任务上都实现了颇具竞争力的性能表现。其中,在 ImageNet-1K 数据集上实现了 86.4% 的图像分类准确率、在 COCO test-dev 数据集上实现了 58.7% 的目标检测 box AP 和 51.1% 的 mask AP。目前,在 COCO minival 和 COCO test-dev 两个数据集上,Swin-L(Swin Transformer 的变体)在目标检测和实例分割任务中均实现了 SOTA。

此外,在 ADE20K val 和 ADE20K 数据集上,Swin-L 也在语义分割任务中实现了 SOTA。
开源代码和预训练模型
Swin Transformer 论文公开没多久之后,微软官方于近日在 GitHub 上开源了代码和预训练模型,涵盖图像分类、目标检测以及语义分割任务。上线仅仅两天,该项目已收获 2100星。
项目地址:https://github.com/microsoft/Swin-Transformer
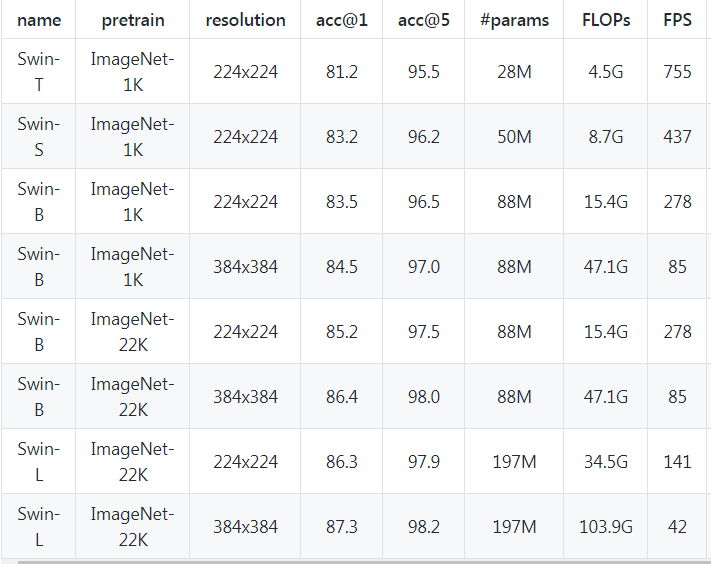
首先图像分类任务,Swin-T、Swin-S、Swin-B 和 Swin-L 变体模型在 ImageNet-1K 和 ImageNet-22K 数据集上的准确率结果如下:
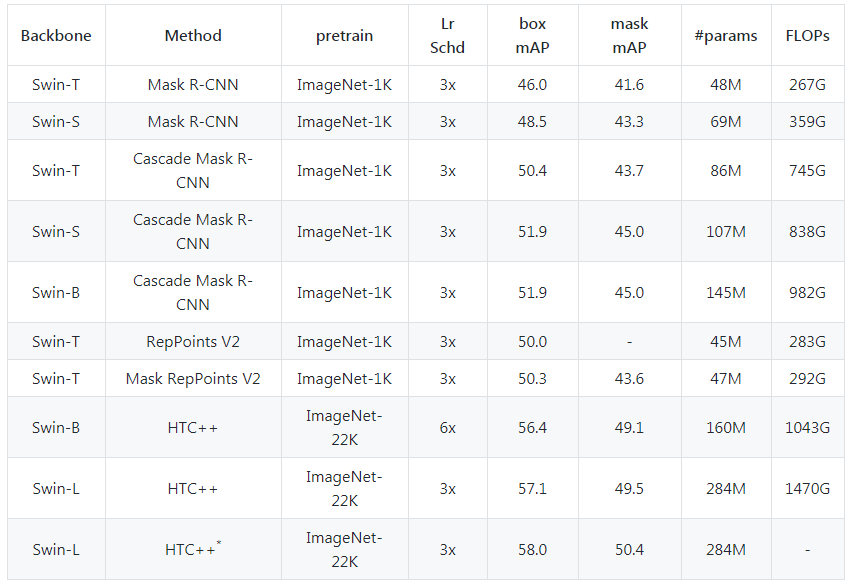
其次目标检测任务:Swin-T、Swin-S、Swin-B 和 Swin-L 变体模型在 COCO 目标检测(2017 val)数据集上的结果如下:
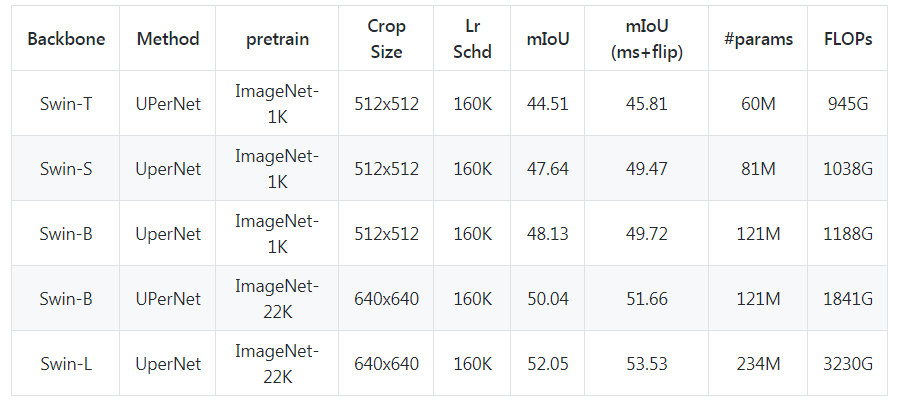
最后语义分割任务:Swin-T、Swin-S、Swin-B 和 Swin-L 变体模型在 ADE20K 语义分割(val)数据集上的结果如下。目前,Swin-L 取得了 53.50% 的 SOTA 验证 mIoU 分数。
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近3000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









