




 本文介绍Transformer网络中间层可视化的两种常用方法:AttentionRollout和AttentionFlow。这两种方法通过对每一层的token attentions递归计算,考虑残差连接及注意力权重的影响,帮助理解信息流。文章还讨论了如何计算从输入层到高层的嵌入方式。
本文介绍Transformer网络中间层可视化的两种常用方法:AttentionRollout和AttentionFlow。这两种方法通过对每一层的token attentions递归计算,考虑残差连接及注意力权重的影响,帮助理解信息流。文章还讨论了如何计算从输入层到高层的嵌入方式。
最近需要对Transformer网络的中间层进行可视化,便于分析网络,在此记录一些常用到的概念。
常用到的方法主要是Attention Rollout和Attention Flow,这两种方法都对网络中每一层的token attentions进行递归计算,主要的不同在于假设低层的attention weights如何影响到高层的信息流,以及是否计算token attentions之间的相关性。
为了计算信息从输入层传播到高层的嵌入方式,关键是考虑模型中残差连接以及attention权重。在一个Transformer块中,self-attention和前向网络都被残差连接包裹,也就是将这些模块的输入添加到输出中。当仅使用attention weights来近似Transformers中的信息流时,就忽略了残差连接。但是残差连接连接了不同层的对应位置,所以在计算attention rollout和attention flow时,用额外的权重来表示残差连接。给定一个有残差连接的attention模块,将层的值计算为
,其中
是attention矩阵,因此有
。所以,为了解释残差连接,给attention矩阵增加一个单位矩阵,并且对新矩阵的权重重新规范化。最后生成由残差连接更新的原始矩阵
。
此外,分析单个attention head需要考虑输入在通过Transformer块中位置级的前向网络后,各个heads之间混合的信息。使用Attention Rollout和Attention Flow能够单独分析每个attention head中的信息,但是为了简便,一般在所有的attention heads上平均每一层的attention来进行分析。
Attention rollout
给定一个L层的Transformer,希望计算从层所有位置到
层(其中
)所有位置的attention。在attention图中,从
层位置k的结点v到
层中位置m的结点u的路径是一系列连接这两个结点的边。如果将每条边的权重视为两个节点之间传输信息的比例,那么可以将路径中所有边的权重相乘来计算结点v中有多少信息通过该路径传播到了结点u。为了计算从
层到
层的attentions,在下面所有层中递归地乘以attention矩阵。
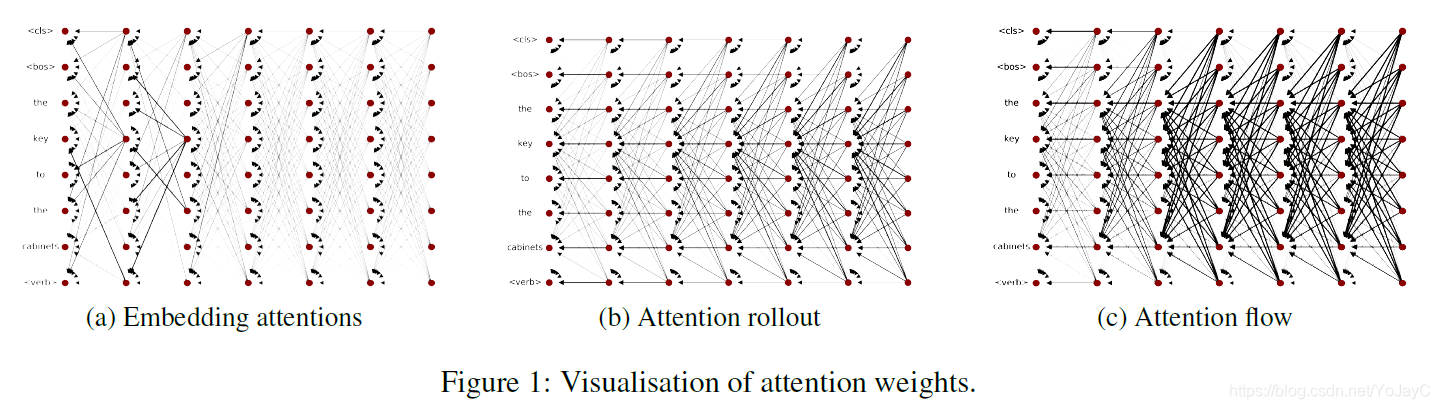
在计算公式中是attention rollout,A是原始的attention,相乘操作是矩阵乘法。在该公式下,设置j=0来计算输入的attention值。
参考:
[1] Quantifying Attention Flow in Transformers


















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









