




-
前期准备
配置JDK,Scala,Hadoop,Spark运行环境,安装IDEA。
PS:注意spark、Scala、Hadoop之间的版本对应关系,否则可能会报错。
-
在IDEA中用sbt构建Scala工程
IDEA中点击File->new->Project
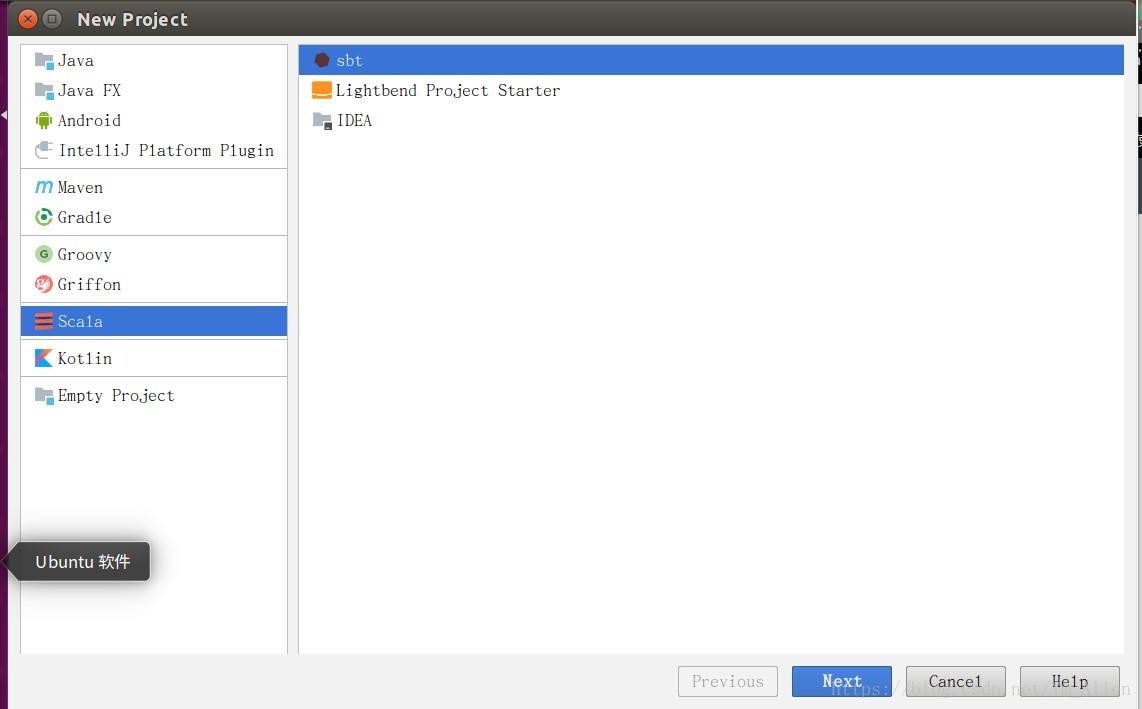
之后填写项目名称,存储路径,选择JDK版本,Sbt版本,Scala版本
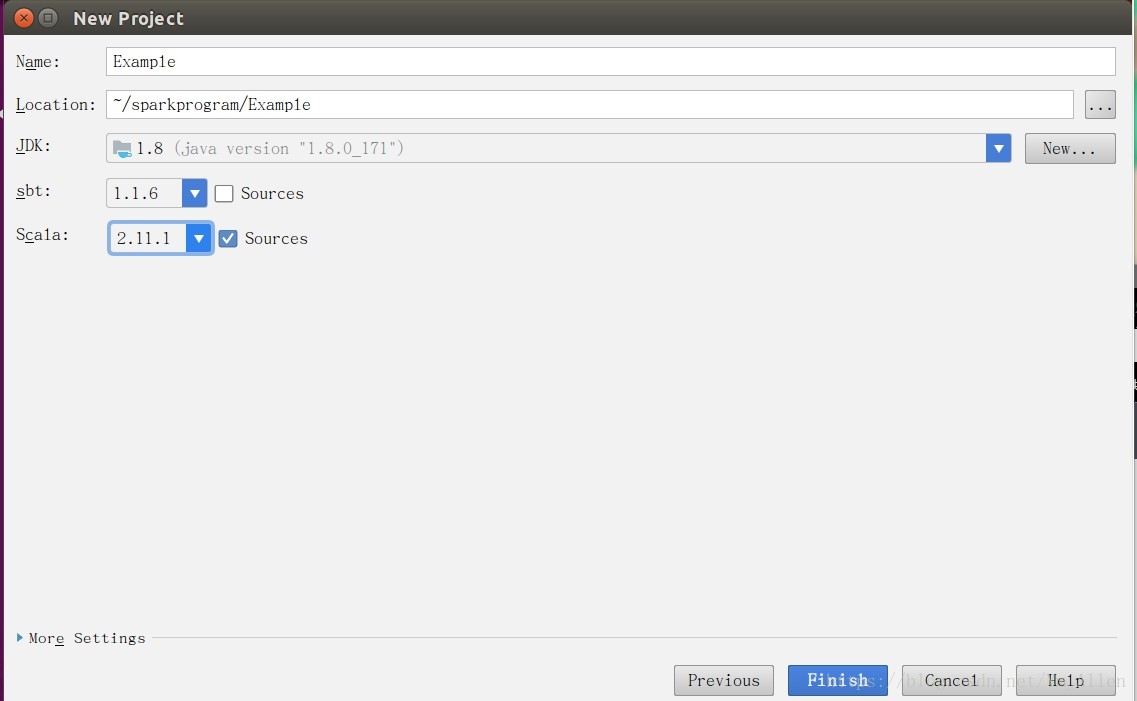
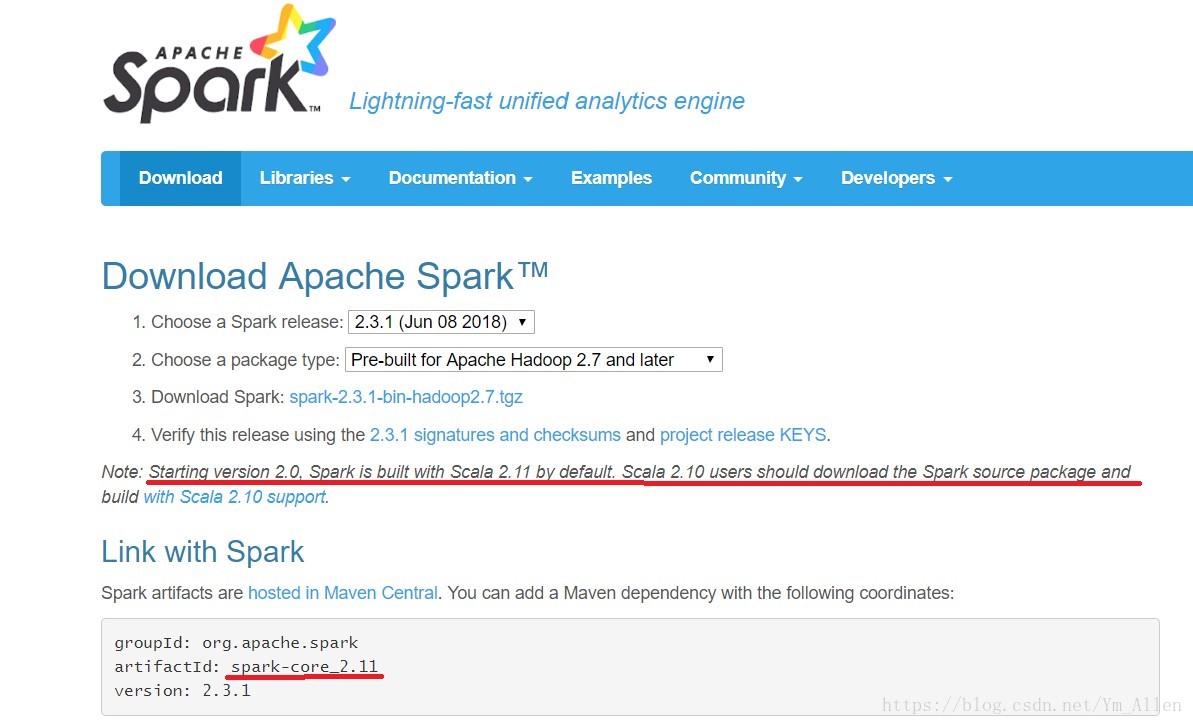
其中Scala版本必须与Spark编译使用的版本一致,可以通过Spark官网查询Scala版本
构建完成后的目录如下
 本文介绍了如何配置Spark、Scala、Hadoop环境,使用IDEA创建Scala工程,添加Spark依赖,编写WordCount实例,打包成jar,并在Spark集群上运行。关键步骤包括匹配版本、构建sbt项目、添加依赖、打包jar以及启动和提交Spark作业。
本文介绍了如何配置Spark、Scala、Hadoop环境,使用IDEA创建Scala工程,添加Spark依赖,编写WordCount实例,打包成jar,并在Spark集群上运行。关键步骤包括匹配版本、构建sbt项目、添加依赖、打包jar以及启动和提交Spark作业。
配置JDK,Scala,Hadoop,Spark运行环境,安装IDEA。
PS:注意spark、Scala、Hadoop之间的版本对应关系,否则可能会报错。
IDEA中点击File->new->Project
之后填写项目名称,存储路径,选择JDK版本,Sbt版本,Scala版本
其中Scala版本必须与Spark编译使用的版本一致,可以通过Spark官网查询Scala版本
构建完成后的目录如下

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 416
416





