




 本文介绍了SVM支持向量机的基本原理和优化策略,通过Spark MLlib库展示了如何在大数据场景下应用SVM进行线性分类,并详细解释了SVM的运行步骤,包括数据格式和代码实现。
本文介绍了SVM支持向量机的基本原理和优化策略,通过Spark MLlib库展示了如何在大数据场景下应用SVM进行线性分类,并详细解释了SVM的运行步骤,包括数据格式和代码实现。
支持向量机(support vector machine),简称SVM。简单来讲,它是一种二类分类模型,能够将不同类的样本在样本空间中进行分隔。其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
算法简介
SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开,且使分类间隔最大。SVM的实质就是找出一个能将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离。术语表示为“间隔”(margin)
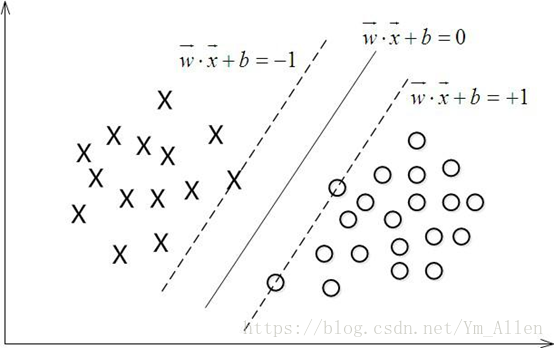
超平面可以用分类函数![]() 表示 ,在进行分类的时候,遇到一个新的数据点x,将x代入f(x) 中,如果f(x)小于0则将x的类别赋为-1,如果f(x)大于0则将x的类别赋为1。
表示 ,在进行分类的时候,遇到一个新的数据点x,将x代入f(x) 中,如果f(x)小于0则将x的类别赋为-1,如果f(x)大于0则将x的类别赋为1。
实现步骤
- 用数学定义要求解的问题
SVM求一个平面S:y=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3244
3244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









