




文章目录
1、Spark On YARN 部署模式的运行机制
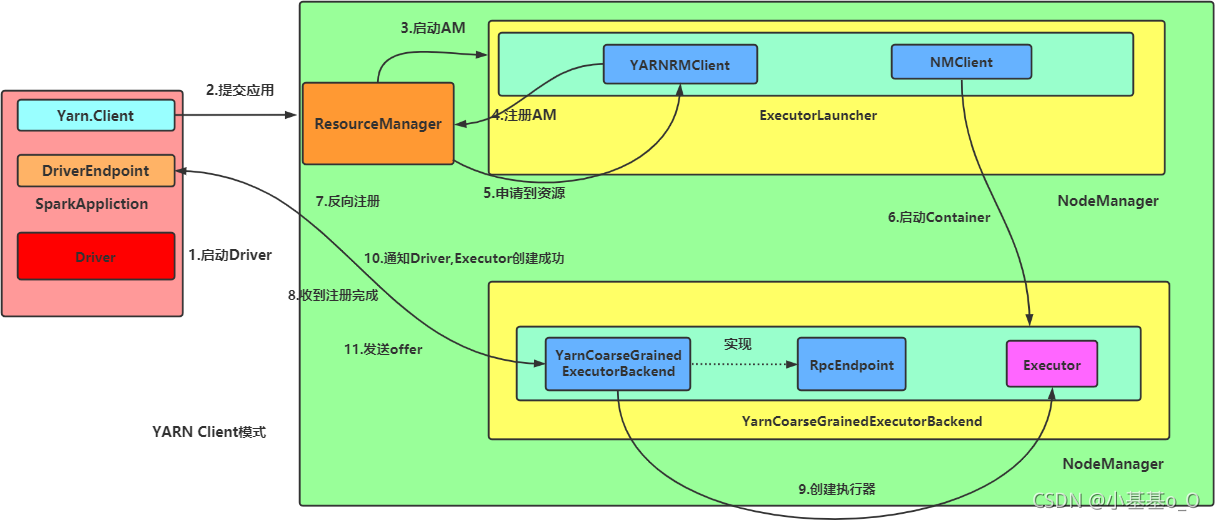
- 任务提交后,启动Driver;
- Driver向集群管理器注册应用程序;
- 集群管理器根据此任务的配置文件分配Executor并启动;
- Driver执行
main函数,跑到行动算子时就反向推算,按宽依赖划分Stage,每一个Stage对应一个TaskSet,TaskSet中有多个Task,查找可用资源Executor进行调度; - 根据本地化原则,Task会被分发到指定的Executor去执行,在任务执行的过程中,Executor也会不断与Driver进行通信,报告任务运行情况。
1.1、Spark On YARN Cluster

spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.0.0.jar \
999
提交Spark任务,并配置
--master yarn和--deploy-mode cluster,然后查看Java进程
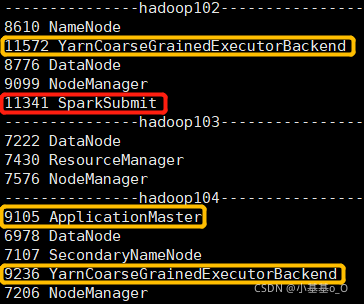
1.2、Spark On YARN Client
spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.0.0.jar \
999
提交Spark任务,并配置
--master yarn,然后查看Java进程
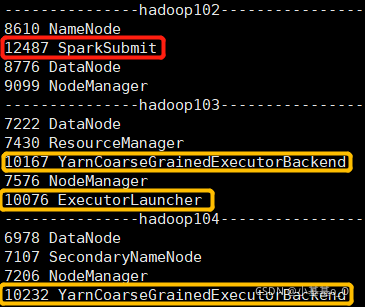
2、任务调度机制
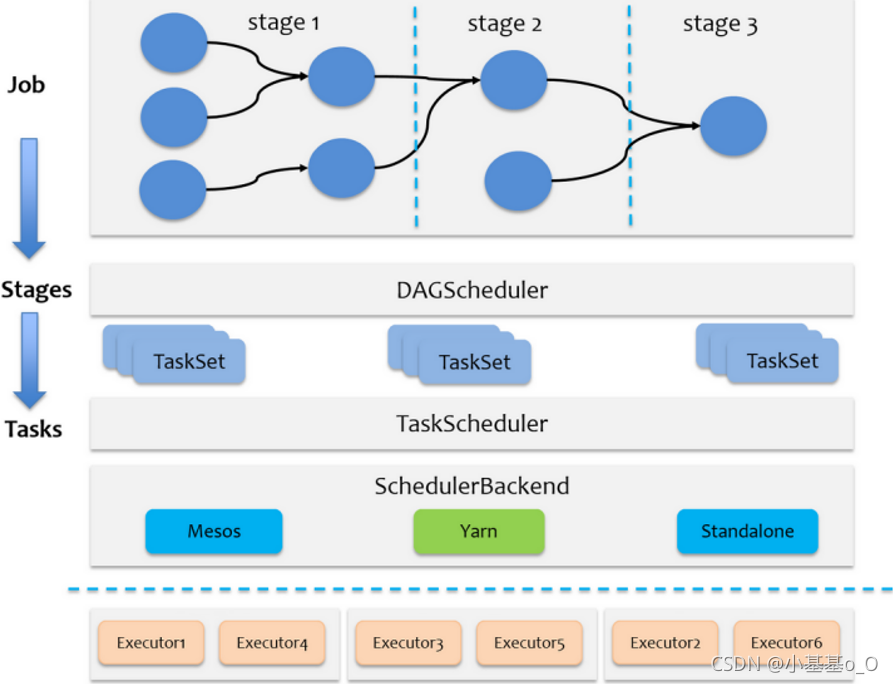
- Job是以行动算子为界
- Stage是Job的子集,以RDD宽依赖为界
- Task是Stage的子集, 分 区 数 = T a s k 数 量 分区数=Task数量 分区数=Task数量
-
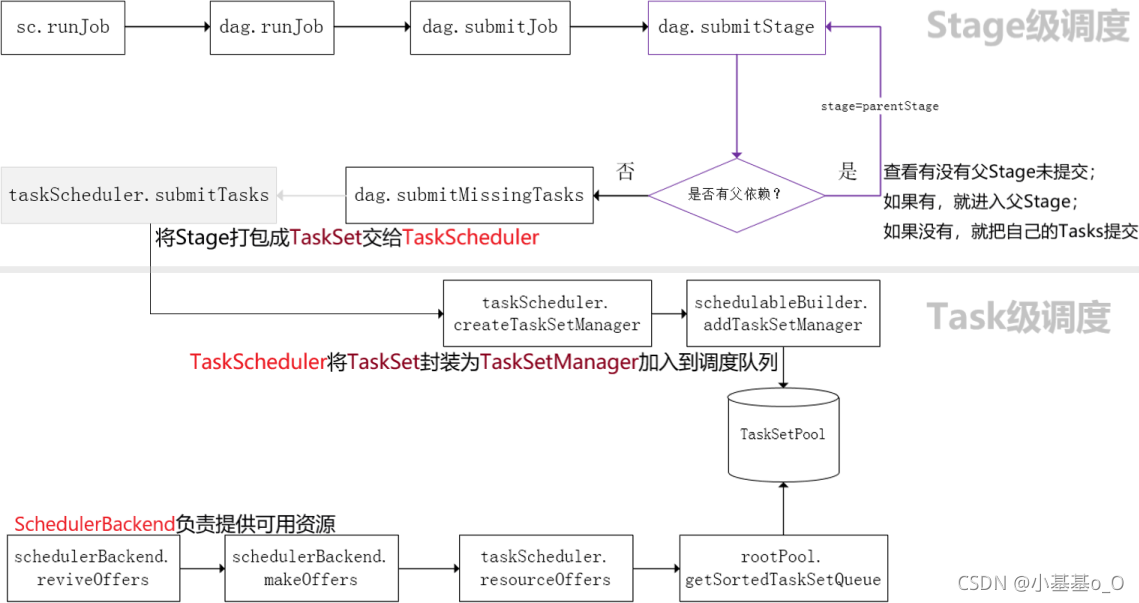
Stage级调度(DAGScheduler)
DAGScheduler负责Stage级的调度,主要是将Job切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度 -
Task级调度(TaskScheduler)
TaskScheduler负责Task级的调度,将TaskSet按照指定的调度策略分发到Executor上执行
调度过程中SchedulerBackend负责提供可用资源
源码解析简化图
3、Shuffle机制
在划分stage时
最后一个stage为ResultStage
前面的stage为ShuffleMapStage,其结束伴随shuffle
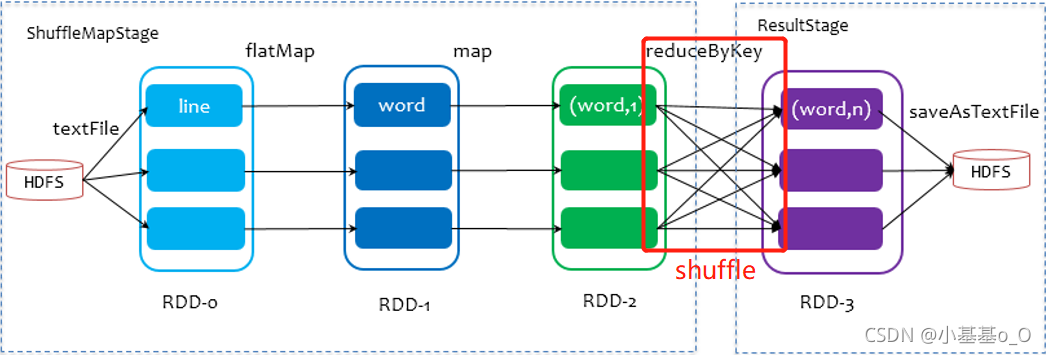
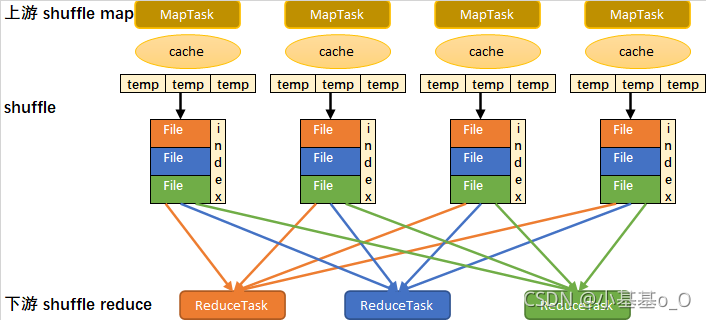
sort-based shuffle流程简化图
1、写入内存缓冲
2、缓冲满后,溢写到临时文件
3、所有临时文件合并成一个数据文件,并创建一个索引文件
4、一个MapTask生成一个数据文件和一个索引文件
5、sort-based shuffle生成文件总数:MapTask数量 x 2
6、ReduceTask根据索引文件从数据文件读取数据
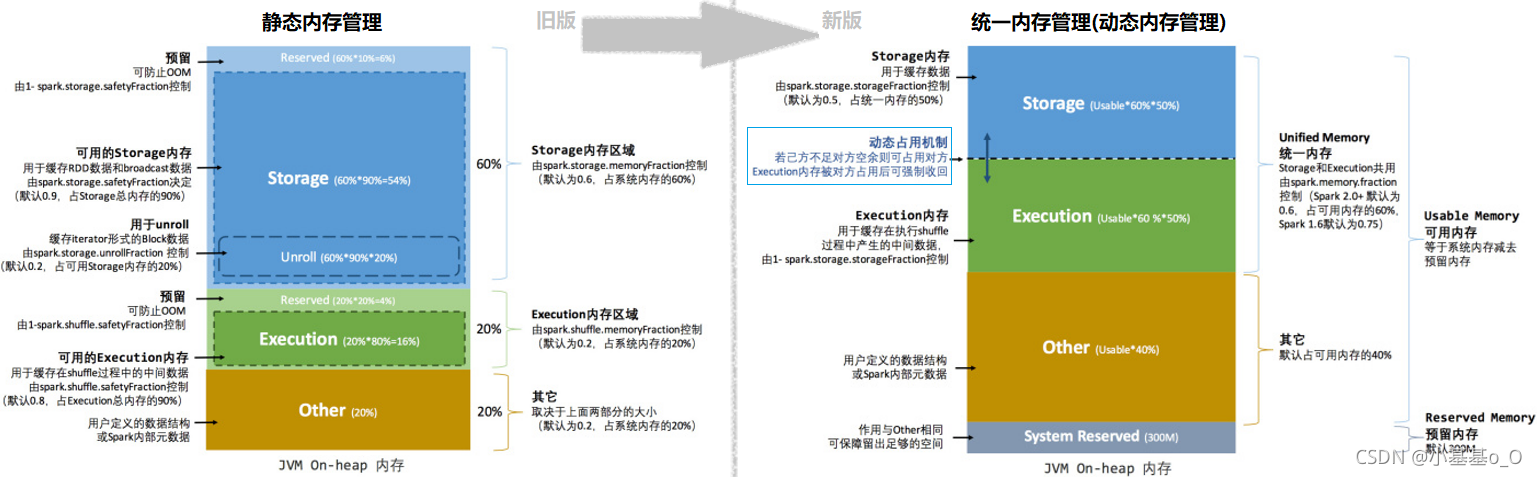
4、内存管理
堆内(On-heap)和堆外(Off-heap)内存
Executor的内存管理建立在JVM的内存管理之上
Spark引入了堆外内存,使之可以直接在工作节点的系统内存中开辟空间来使用
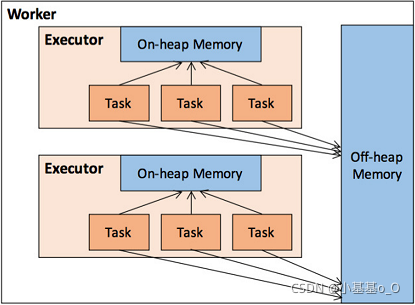
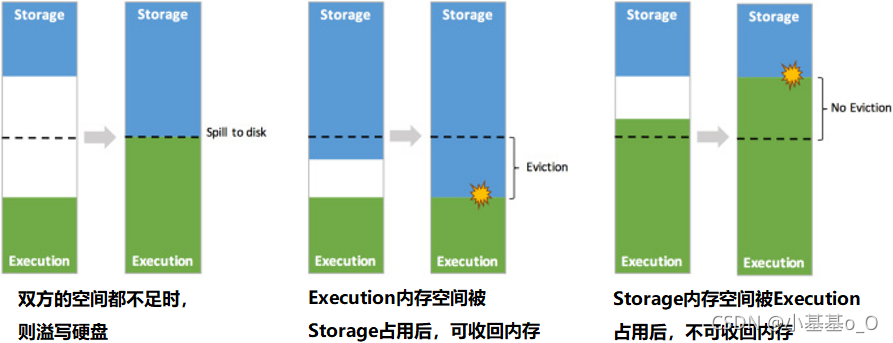
内存空间分配
动态占用机制
5、并行度
- 并行度:所有Executor可以同时执行的Task数量
- 每个Executor的一个Core同时只能执行一个Task
- 最 大 并 行 度 = E x e c u t o r 数 量 × 每 个 E x e c u t o r 的 C o r e 数 量 最大并行度 = Executor数量 \times 每个Executor的Core数量 最大并行度=Executor数量×每个Executor的Core数量
spark-submit \
--class a.b.c.PageViewPreHour \
--master yarn
--deploy-mode cluster
--driver-memory 8g \
--num-executors 40 \
--executor-memory 10g \
--executor-cores 2 \
/home/yellow/spark_jar/real_time.jar \
spark-submit参数 | 参数值 | 说明 |
|---|---|---|
--driver-memory | 8g | Driver内存 |
--num-executors | 40 | Executor数量 |
--executor-memory | 10g | 每个Executor的内存大小 |
--executor-cores | 2 | 每个Executor的CPU core数量 |
-
E x e c u t o r 总 内 存 = E x e c u t o r 数 量 × 每 个 E x e c u t o r 内 存 = 400 G Executor总内存 = Executor数量 \times 每个Executor内存 = 400G Executor总内存=Executor数量×每个Executor内存=400G
E x e c u t o r 总 核 心 数 = E x e c u t o r 数 量 × 每 个 E x e c u t o r 核 心 数 = 80 Executor总核心数 = Executor数量 \times 每个Executor核心数 = 80 Executor总核心数=Executor数量×每个Executor核心数=80
核心数与内存(G)配比 1 : 5 1:5 1:5 -
最 大 并 行 度 = E x e c u t o r 总 核 心 数 = 80 最大并行度 = Executor总核心数 = 80 最大并行度=Executor总核心数=80
如果RDD有160个分区(一个分区对应一个Task),就需要两轮计算
如果RDD有50个分区,那么计算时只用了50个Core,其余30个Core空转(资源浪费) -
并行度调优
并行度过高会导致资源浪费,并行度过低会导致效率低下
通常建议 总核数设置为Task数量的 1 2 \frac{1}{2} 21或 1 3 \frac{1}{3} 31
没有推荐 1 : 1 1:1 1:1,是因为有的Task快 有的Task慢,快的Task完成后会造成Core空闲
不过,在实时计算的场景下,可设成 1 : 1 1:1 1:1,这样效率高
6、附录
6.1、相关单词
| en | 🔉 | cn |
|---|---|---|
| RPC | Remote Procedure Call | 远程过程调用 |
| spill | spɪl | v. (使)溢出;n. 溢出液 |
| eviction | ɪˈvɪkʃn | n. 逐出;收回 |
6.2、源码截取
查看源码需要先导入依赖并下载对应源码
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
6.2.1、SparkOnYARNCluster
spark-submit --master yarn --deploy-mode cluster …
-----------------------------------
第一部分: 客户端和YARN通信
org.apache.spark.deploy.SparkSubmit.main
-- submit.doSubmit(args)
--super.doSubmit(args)
// 解析spark-submit后传入的参数,加载spark默认的参数
-- val appArgs = parseArguments(args)
--submit(appArgs, uninitLog)
--doRunMain()
//运行spark-submit 提交的主类 中的main方法
--runMain(args, uninitLog)
// 如果deployMode == CLIENT,此时childMainClass=自己提交的全类名
// 如果deployMode == CLUSTER,是YARN集群 childMainClass=org.apache.spark.deploy.yarn.YarnClusterApplication
--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
//创建childMainClass的Class类型
--mainClass = Utils.classForName(childMainClass)
--val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
//如果是cluster 模式,此时运行下一行
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
new JavaMainApplication(mainClass)
}
-- app.start(childArgs.toArray, sparkConf)
// YarnClusterApplication.start() Client是可以和yarn进行通信的一个客户端
--new Client(new ClientArguments(args), conf, null).run()
--this.appId = submitApplication()
// 提交应用程序到YARN上,获取YARN的返回值
-- val newApp = yarnClient.createApplication()
//确定app保存临时数据的作业目录,通常是在hdfs中的/tmp目录中生成一个子目录
-- val appStagingBaseDir = sparkConf.get(STAGING_DIR)
//确保YARN有足够的资源运行当前app的AM
//当集群资源不足时就会阻塞,塞到超时就会FAILD
-- verifyClusterResources(newAppResponse)
-- val containerContext = createContainerLaunchContext(newAppResponse)
//AM是YARN提供的一个接口
//任何的应用程序如果希望提交APP到YARN,实现AM的接口
// MR写的app就由MR实现AM
// Spark写的App就由Spark实现AM
--val amClass =
if (isClusterMode) {
//集群模式AM的全类名是org.apache.spark.deploy.yarn.ApplicationMaster
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
-- val appContext = createApplicationSubmissionContext(newApp, containerContext)
//提交运行AM
-- yarnClient.submitApplication(appContext)
----------------------------------------
第二部分 AM启动
ApplicationMaster.main
--master.run()
--if (isClusterMode) {
//如果是Cluster模式就在AM中运行Driver
--runDriver()
} else {
runExecutorLauncher()
}
// 启动一个线程,运行用户自己编写的app应用程序的main方法
--userClassThread = startUserApplication()
//等待用户自己编写的app的main方法运行结束后,获取用户自己创建的SparkContext
--val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
// 向RM回报,AM已经启动成功了
--registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
// 创建一个可以向RM申请资源的对象,申请资源启动Executor
-- createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
//allocator: YarnAllocator 作用就是向RM申请Container,决定获取到COntainer后,使用Container干什么
--allocator = client.createAllocator()
--allocator.allocateResources()
//发送申请请求
-- val allocateResponse = amClient.allocate(progressIndicator)
//从YARN的响应中获取已经分配的Container
--val allocatedContainers = allocateResponse.getAllocatedContainers()
//处理申请到的Container
-- handleAllocatedContainers(allocatedContainers.asScala)
//在Container中运行进程
-- runAllocatedContainers(containersToUse)
//每个Container都会创建一个ExecutorRunnable,交给线程池运行
--new ExecutorRunnable.run
-- nmClient = NMClient.createNMClient()
nmClient.init(conf)
nmClient.start()
//准备容器中的启动进程
startContainer()
--org.apache.spark.executor.YarnCoarseGrainedExecutorBackend 容器中启动的进程
--val commands = prepareCommand()
6.2.2、SparkOnYARNClient
spark-submit --master yarn …
-----------------------------------
第一部分: 客户端和YARN通信
org.apache.spark.deploy.SparkSubmit.main
-- submit.doSubmit(args)
--super.doSubmit(args)
// 解析spark-submit后传入的参数,加载spark默认的参数
-- val appArgs = parseArguments(args)
--submit(appArgs, uninitLog)
--doRunMain()
//运行spark-submit 提交的主类 中的main方法
--runMain(args, uninitLog)
// 如果deployMode == CLIENT,此时childMainClass=自己提交的全类名
// 如果deployMode == CLUSTER,是YARN集群 childMainClass=org.apache.spark.deploy.yarn.YarnClusterApplication
--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
//创建childMainClass的Class类型
--mainClass = Utils.classForName(childMainClass)
--val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
//如果是client 模式,此时运行下一行
new JavaMainApplication(mainClass)
}
//JavaMainApplication.start
-- app.start(childArgs.toArray, sparkConf)
//获取用户编写的 app类的main
-- val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
//执行main方法,Driver启动
--mainMethod.invoke(null, args)
------------------------------------------------------------------------
第二部分: WordCount.main
SparkContext sc=new SparkContext
SparkContext的重要组件:
private var _taskScheduler: TaskScheduler = _ //负责Task的调度
private var _dagScheduler: DAGScheduler = _ // Job中DAG Stage的切分
private var _env: SparkEnv = _ // RpcEnv(通信环境) BlockManager(存数据)
--------------
_taskScheduler = ts
_taskScheduler.start()
//YarnClientSchedulerBackend.start()
--backend.start()
-- client = new Client(args, conf, sc.env.rpcEnv)
//提交应用程序到YARN
-- bindToYarn(client.submitApplication(), None)
//参考cluster模式
...
--在容器中运行的AM的全类名: org.apache.spark.deploy.yarn.ExecutorLauncher
-----------------------------
第二部分:启动AM
org.apache.spark.deploy.yarn.ExecutorLauncher.main
//ExecutorLauncher 是对AM的封装,也是AM的实现
ApplicationMaster.main(args)
-- --master.run()
if (isClusterMode) {
--runDriver()
} else {
//client模式运行
runExecutorLauncher() //申请Container启动Executor
}
----------------------------------------------------------------------------
// YarnClusterApplication.start() Client是可以和yarn进行通信的一个客户端
--new Client(new ClientArguments(args), conf, null).run()
--this.appId = submitApplication()
// 提交应用程序到YARN上,获取YARN的返回值
-- val newApp = yarnClient.createApplication()
//确定app保存临时数据的作业目录,通常是在hdfs中的/tmp目录中生成一个子目录
-- val appStagingBaseDir = sparkConf.get(STAGING_DIR)
//确保YARN有足够的资源运行当前app的 AM
// 如果集群资源不足,此时会阻塞,一直阻塞到超时,会FAILD
-- verifyClusterResources(newAppResponse)
-- val containerContext = createContainerLaunchContext(newAppResponse)
// 确定AM的主类名
// AM是YARN提供的一个接口
// 任何的应用程序如果希望提交APP到YARN,实现AM的接口
// MR写的app,MR实现AM
// spark写的App,spark实现AM
--val amClass =
if (isClusterMode) {
//集群模式AM的全类名是org.apache.spark.deploy.yarn.ApplicationMaster
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
-- val appContext = createApplicationSubmissionContext(newApp, containerContext)
//提交运行AM
-- yarnClient.submitApplication(appContext)
6.2.3、Executor启动之反向注册
org.apache.spark.executor.YarnCoarseGrainedExecutorBackend 本身就是一个通信端点
//RpcEndpointRef:某个通信端点的引用
var driver: Option[RpcEndpointRef] = None
------------------
第一部分: YarnCoarseGrainedExecutorBackend进程启动
--YarnCoarseGrainedExecutorBackend.main
-- CoarseGrainedExecutorBackend.run(backendArgs, createFn)
//向Driver请求spark的配置信息
--val executorConf = new SparkConf
// 当前进程在网络中有一个通信的别名称为Executor
-- env.rpcEnv.setupEndpoint("Executor",
backendCreateFn(env.rpcEnv, arguments, env, cfg.resourceProfile))
//阻塞,一直运行,除非Driver发送停止命令
--env.rpcEnv.awaitTermination()
constructor -> onStart -> receive* -> onStop
--------------------------------------
第二部分: YarnCoarseGrainedExecutorBackend进程向Driver发送注册请求
onStart
// ref:RpcEndpointRef 代表Driver的通信端点引用(电话号)
// 向Driver发RegisterExecutor消息,请求答复一个Boolean的值
-- ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls,
extractAttributes, _resources, resourceProfile.id))
}(ThreadUtils.sameThread).onComplete {
case Success(_) =>
//成功,自己给自己发 RegisteredExecutor消息
self.send(RegisteredExecutor)
//失败,进程就退出
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
-------------------------------------
第三部分: Driver处理注册请求
DriverEndPoint.receiveAndReply
--case RegisterExecutor
// 判断是否已经注册过了,如果注册过了,回复失败;判断是否拉黑,拉黑,注册失败
// 否则注册,注册完成后,回复true
context.reply(true)
----------------------------------------
第四部分: YarnCoarseGrainedExecutorBackend 注册成功后
YarnCoarseGrainedExecutorBackend.receive
-- case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
// Spark的计算者,维护了一个线程池,用来计算各种Task
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false,
resources = _resources)
// 给Driver发LaunchedExecutor消息
driver.get.send(LaunchedExecutor(executorId))
-----------------------------------------------------
第五部分: Driver处理LaunchedExecutor请求
DriverEndPoint.receive
-- case LaunchedExecutor(executorId) =>
executorDataMap.get(executorId).foreach { data =>
data.freeCores = data.totalCores
}
//Driver向Executor发送工作任务(Task)
makeOffers(executorId)
//从调度池中,根据TaskSet的优先级,调度其中的Task。
// 按照轮流发送的原则将Task调度到哦所有的Executor,保证负载均衡。
//调度应该发往次Executor的Task
--scheduler.resourceOffers(workOffers)
-- launchTasks(taskDescs)
-- val serializedTask = TaskDescription.encode(task)
//为要发送的Executor打个招呼,发送Task
--executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
--------------------------------------------------
第六部分: Executor收到Task
-- case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
// 反序列化得到Task的描述(TaskDescription)
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
taskResources(taskDesc.taskId) = taskDesc.resources
//启动Task的运算
executor.launchTask(this, taskDesc)
//创建一个Task运行的线程
-- val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
// 启动线程
threadPool.execute(tr)
--TaskRunner.run()
//构造可以运行的Task对象
--task = ser.deserialize[Task[Any]]
//运行Task获取结果
-- val res = task.run()
// ShuffleMapTask 或 ResultTask
--runTask(context)
}
6.2.4、任务调度
--------------
RDD.collect
--val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
//判断是否存在闭包,闭包变量是否可以序列化
-- val cleanedFunc = clean(func)
-- dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
-- val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// event处理循环,放入一个事件 JobSubmitted
// eventProcessLoop = new DAGSchedulerEventProcessLoop
-- eventProcessLoop.post(JobSubmitted())
--EventLoop.onReceive(event)
-- doOnReceive(event)
--case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
----------------------
dagScheduler.handleJobSubmitted
// Job的最后一个阶段
--var finalStage: ResultStage = null
-- finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
//递归依次从后往前找,将ResultStage的所有祖先ShuffleMapStage都创建完毕,最后才创建最后一个Stage
--val parents = getOrCreateParentStages(rdd, jobId)
--val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
// ResultStage创建完毕后,才会生成Job
-- val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
//提交ResultStage
--submitStage(finalStage)
//查看当前阶段有没有未提交的父阶段,按照父阶段的ID排序
--val missing = getMissingParentStages(stage).sortBy(_.id)
//如果父阶段未提交,按照顺序依次提交,最后提交自己
--if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
// 根据Stage类型创建对应的Task,创建时,根据当前Stage要计算的分区数确定
// 如何知道每一个Stage要计算的partition的数量?取决于Stage最后一个RDD的分区数
--val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
//将每个Stage的task放入调度池,通知Driver去调度
//TaskSet:包含了一个Stage所有的Tasks, 一个Task的集合
--taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
//TaskSetManager: 追踪每一个TaskSet中所有Task的运行情况,在它们失败时重启。通过延迟调度
//处理位置敏感的调度,调度每个Task
--val manager = createTaskSetManager(taskSet, maxTaskFailures)
//将TaskSetManager加入调度池(FIFO | FAIR),不同的调度池,会决定不同的TaskSet被调度的优先级
-- schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
-- backend.reviveOffers()
//给Driver发消息,告诉Driver有新的TaskSetManager入池了,可以开始发送了
-- driverEndpoint.send(ReviveOffers)
-- case ReviveOffers =>
makeOffers()


















 139
139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











